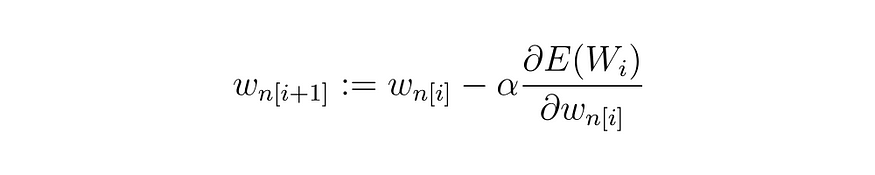经典的影像生成方法-GAN
- GAN
- Discriminator
- Generator
- 还需要加入额外信息么
- GAN可以加在其他模型上面
- 我们可以用影像生成模型做什么?
前面讲过VAE和Flow-based以及diffusion Model ,今天讲最后一种经典的生成方法GAN。
GAN
前面讲的几种模型都是用加入额外资讯的方式,来补充文字叙述所缺失内容,让模型依据这个生成的noise生成图片,但是GAN跟这些的生成方式不太一样。
GAN的模型是这样的:
Discriminator
这个Discriminator,它负责根据输入的描述和对应的图片进行评价,如果符合就给高分,跟之前讲过的CLIP模型处理方式是一样的,

当然它要学习低分的情况,要不然它永远只会答高分了,在CLIP模型中,它是打乱图片和描述,clip模型就给低分。
而在GAN这里不太一样。GAN是把一个生成模型生成的图片,只要是它生成的,就给低分,直到生成模型能骗过Discriminator,让它误以为这是真实的图片,然后打高分,说白了,就是直到生成模型生成的图片能够把Discriminator骗到让他误以为这是原本真实的图片和描述。下面再来讲生成模型:

Generator

Generator 负责根据描述的输入,生成图片,这些生成的图片和描述输入给Discriminator后,Discriminator进行打分,Generator就是根据这个分数不断的调整参数,直到能够骗过它,让Discriminator打出高分。
在这个训练过程与其他模型有何不同?
Generator的生成并没有一个确切的正确答案,它要做的就是让另外一个模型打出高分,仅此而已,不需要根据真实的图片进行比对。实际上在训练过程中,Discriminator和Generator的训练是交替进行的。Discriminator 不断的让自己变厉害,Generator也不断的调整自己,Discriminator不断的提高识别能力,Generator不断的提升生成能力。
还需要加入额外信息么
其他三个模型在生成图片的时候都需要加入额外的信息来生成图片,那么GAN还需要么?
答案是不需要。虽然现在大部分论文中仍有加入额外信息的习惯,但是实践以后发现,即使没有,生成的效果也很不错。
GAN可以加在其他模型上面
实际上GAN是可以作为外挂,挂在其他模型上面,以加强其他模型的能力的,比如VAE+GAN,Flow+GAN , Diffusion+GAN
我们可以用影像生成模型做什么?
讲了这么多模型,我们可以用它做什么呢?有没有可能人类与模型做一些更深入的互动呢?
现在已经有人在做了,比如Genie,它可以输入图片,然后输入一个动作,从而生成下一张图片,进入下一个场景,然后人可以继续输入动作,继续操作,就像玩游戏的一幕幕一样,无限下去:

你可能也发现这部分训练的难度就在于影像可以获得,但是影像中对应的动作,我们并不清楚,这个就跟我们讲VAE的模型是同样的道理,我们可以做一个模型,用来获取这个可能的动作是什么:

这个动作抽取的模型就是用来抽取这个画面我们可能进行的操作,然后再去生成图片,我们最终的目标就是生成的图片跟输入的下一个画面是一致的,这是跟VAE一样的原理的
有了这样的模型,我们可以跟环境做更加深入的互动。比如输入一段影片,输入操作,它就会不断的变换场景,而这种场景是根据你的输入随时可以切换的。就像是赛车游戏,我们不再局限于设定好的道路,而是随处拍到的照片都可以了。