1. 前言
普里姆算法(Prim's Algorithm)是一种用于寻找加权无向图中的最小生成树(Minimum Spanning Tree, MST)的贪心算法。
最小生成树是指对于一个给定的无向图,连接所有顶点且边的总权重最小的生成树。
2. 算法步骤
1. 初始化:
- 选择任意一个顶点作为起始点,这个顶点被加入到生成树中。
- 创建一个集合用来存储已添加到生成树中的顶点。
- 创建一个优先队列(通常使用最小堆实现),用来存放未加入生成树的顶点及其与已加入顶点之间的边的权重。
2. 迭代:
- 在每一步中,从未加入生成树的顶点中找到与已加入顶点相连的边中权重最小的边,并将其添加到生成树中。
- 将这条边所连接的新顶点加入到已加入生成树的顶点集合中。
- 更新优先队列,包括新加入顶点的所有邻接顶点及其边的权重。
3. 终止条件:
- 当所有的顶点都被加入到生成树中时,算法结束。
Prim算法的思路与前文写的迪杰斯特拉算法几乎一致。
只需要更改这部分代码:
e.linked.dist = e.weight;
3. 主要代码
顶点图:

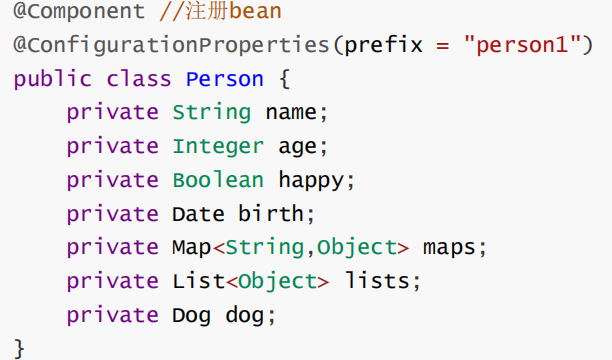
public class Prim {
public static void main(String[] args) {
Vertex v1 = new Vertex("1");
Vertex v2 = new Vertex("2");
Vertex v3 = new Vertex("3");
Vertex v4 = new Vertex("4");
Vertex v5 = new Vertex("5");
Vertex v6 = new Vertex("6");
Vertex v7 = new Vertex("7");
v1.edges = new ArrayList<>();
v1.edges.add(new Edge(v2, 2));
v1.edges.add(new Edge(v3, 4));
v1.edges.add(new Edge(v4, 1));
v2.edges = new ArrayList<>();
v2.edges.add(new Edge(v1, 2));
v2.edges.add(new Edge(v4, 3));
v1.edges.add(new Edge(v5, 10));
v3.edges = new ArrayList<>();
v3.edges.add(new Edge(v1, 4));
v3.edges.add(new Edge(v4, 2));
v3.edges.add(new Edge(v6, 5));
v4.edges = new ArrayList<>();
v4.edges.add(new Edge(v1, 1));
v4.edges.add(new Edge(v2, 3));
v4.edges.add(new Edge(v3, 2));
v4.edges.add(new Edge(v5, 7));
v4.edges.add(new Edge(v6, 8));
v4.edges.add(new Edge(v7, 4));
v5.edges = new ArrayList<>();
v5.edges.add(new Edge(v2, 10));
v5.edges.add(new Edge(v4, 7));
v5.edges.add(new Edge(v7, 6));
v6.edges = new ArrayList<>();
v6.edges.add(new Edge(v3, 5));
v6.edges.add(new Edge(v4, 8));
v6.edges.add(new Edge(v7, 1));
v7.edges = new ArrayList<>();
v7.edges.add(new Edge(v4, 4));
v7.edges.add(new Edge(v5, 6));
v7.edges.add(new Edge(v6, 1));
List<Vertex> graph = new ArrayList<>();
graph.add(v1);
graph.add(v2);
graph.add(v3);
graph.add(v4);
graph.add(v5);
graph.add(v6);
graph.add(v7);
prim(graph, v1);
}
public static void prim(List<Vertex> list, Vertex v) {
List<Vertex> graph = new ArrayList<>(list);
// 将初始顶点v的dist值设置为0
v.dist = 0;
while (!graph.isEmpty()) {
// 第3步:每次选择最小的临时距离的未访问节点作为当前节点
Vertex i = ChooseMinDistVertex(graph);
UpdateNeighboursDist(i);
graph.remove(i);
// 表示已经被处理完了
i.visited = true;
}
// 打印最短路径中,一个顶点的前一个顶点是谁
for (Vertex i : list) {
System.out.println("v" + i.name + " <- " + (i.prev != null ? "v" + i.prev.name : null));
}
}
private static Vertex ChooseMinDistVertex(List<Vertex> list) {
int min = 0;
int dist = list.get(min).dist;
for (int i = 0; i < list.size(); i++) {
if (dist > list.get(i).dist) {
min = i;
dist = list.get(i).dist;
}
}
return list.get(min);
}
private static void UpdateNeighboursDist(Vertex v) {
// 对于当前顶点,遍历其所有未访问的顶点
for (Edge e : v.edges) {
if (!e.linked.visited) {
if (v.dist + e.weight < e.linked.dist) {
// 只需要更改这部分
e.linked.dist = e.weight;
e.linked.prev = v;
}
}
}
}
}
输出结果:
v1 <- null
v2 <- v1
v3 <- v4
v4 <- v1
v5 <- v4
v6 <- v3
v7 <- v44. 总结:
普里姆算法的时间复杂度取决于使用的数据结构。如果使用简单的数组或列表来实现优先队列,则时间复杂度为O(E * V),其中E是边的数量,V是顶点的数量。但如果使用二叉堆作为优先队列,则时间复杂度可以降低至O((V+E) * log(V)),这在稠密图中更为有效。