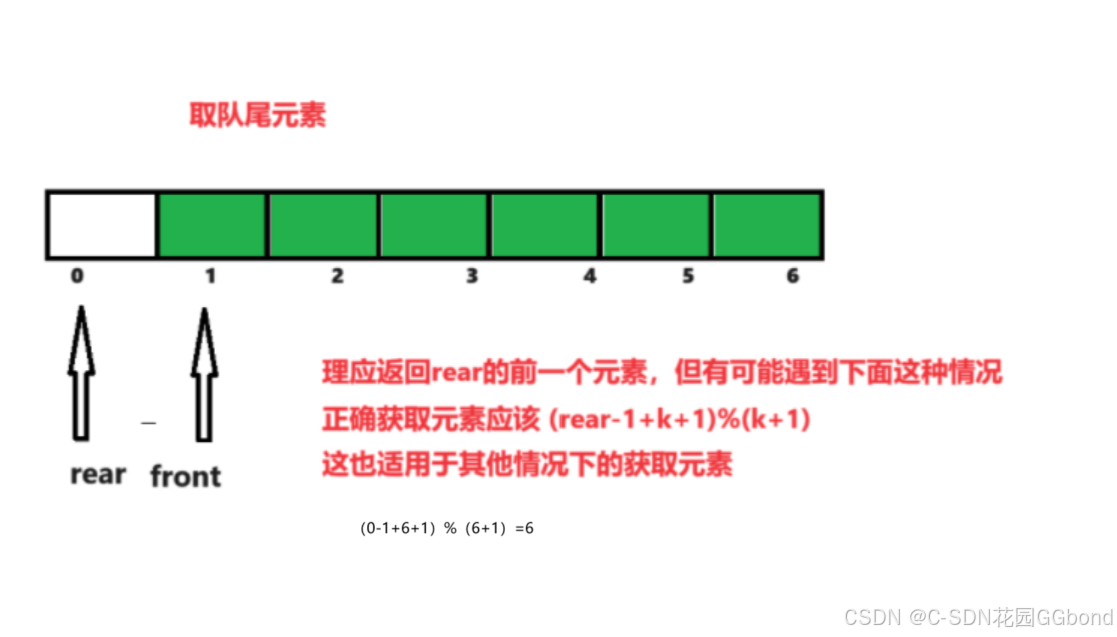
我的课程笔记,欢迎关注:https://github.com/BBuf/how-to-optim-algorithm-in-cuda/tree/master/cuda-mode
CUDA-MODE课程笔记 第6课: 如何优化PyTorch中的优化器
课程内容

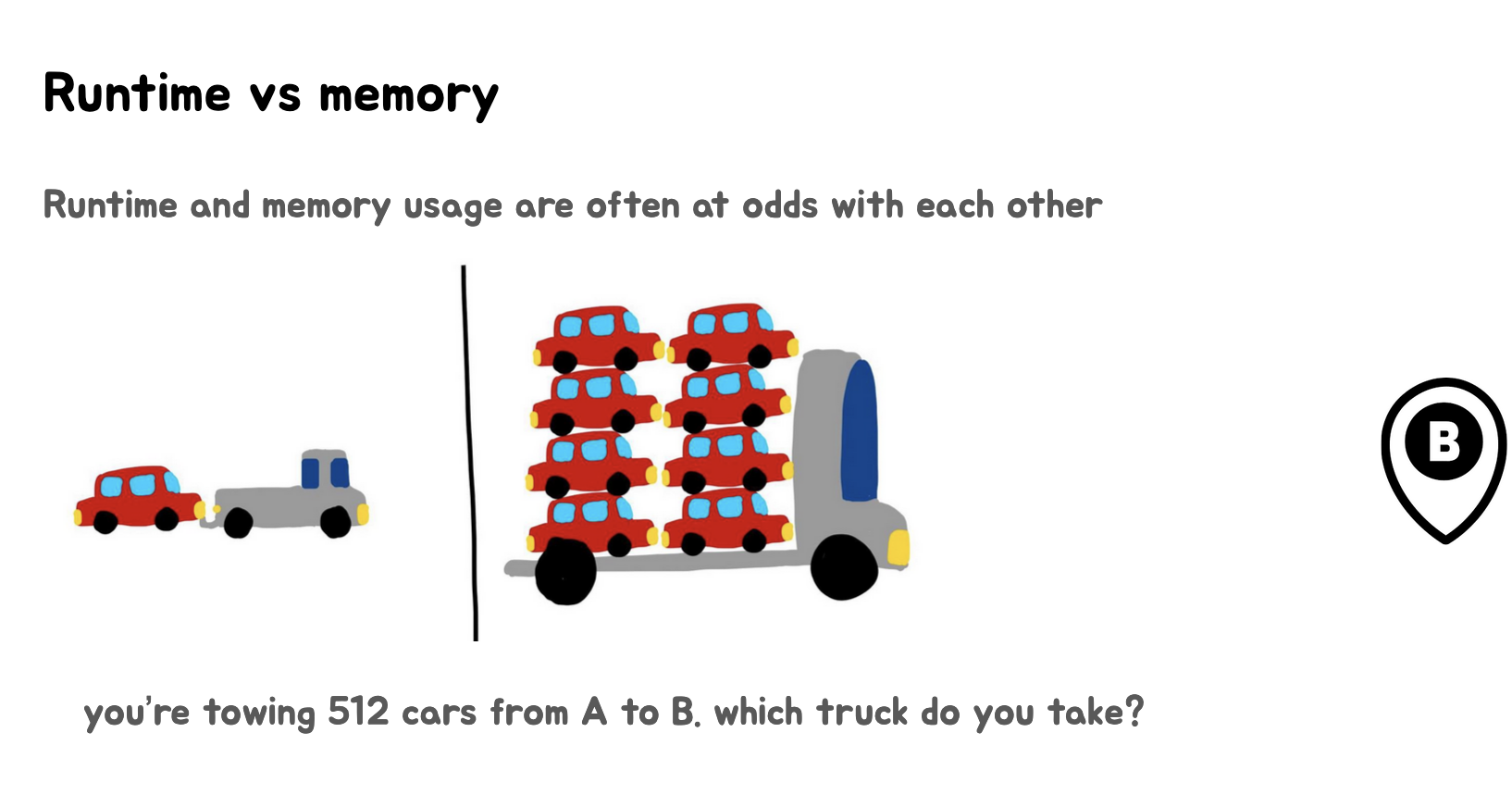
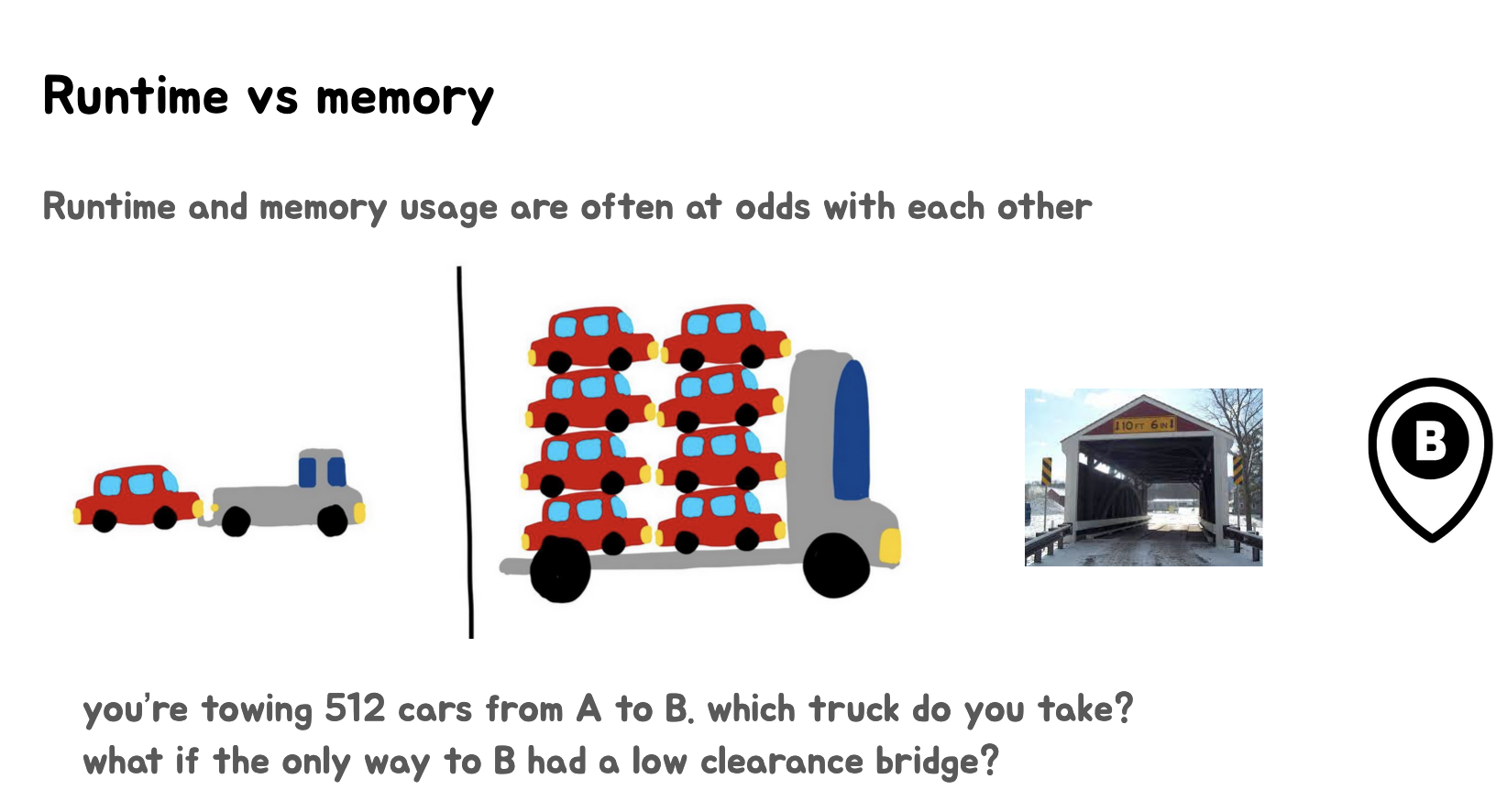
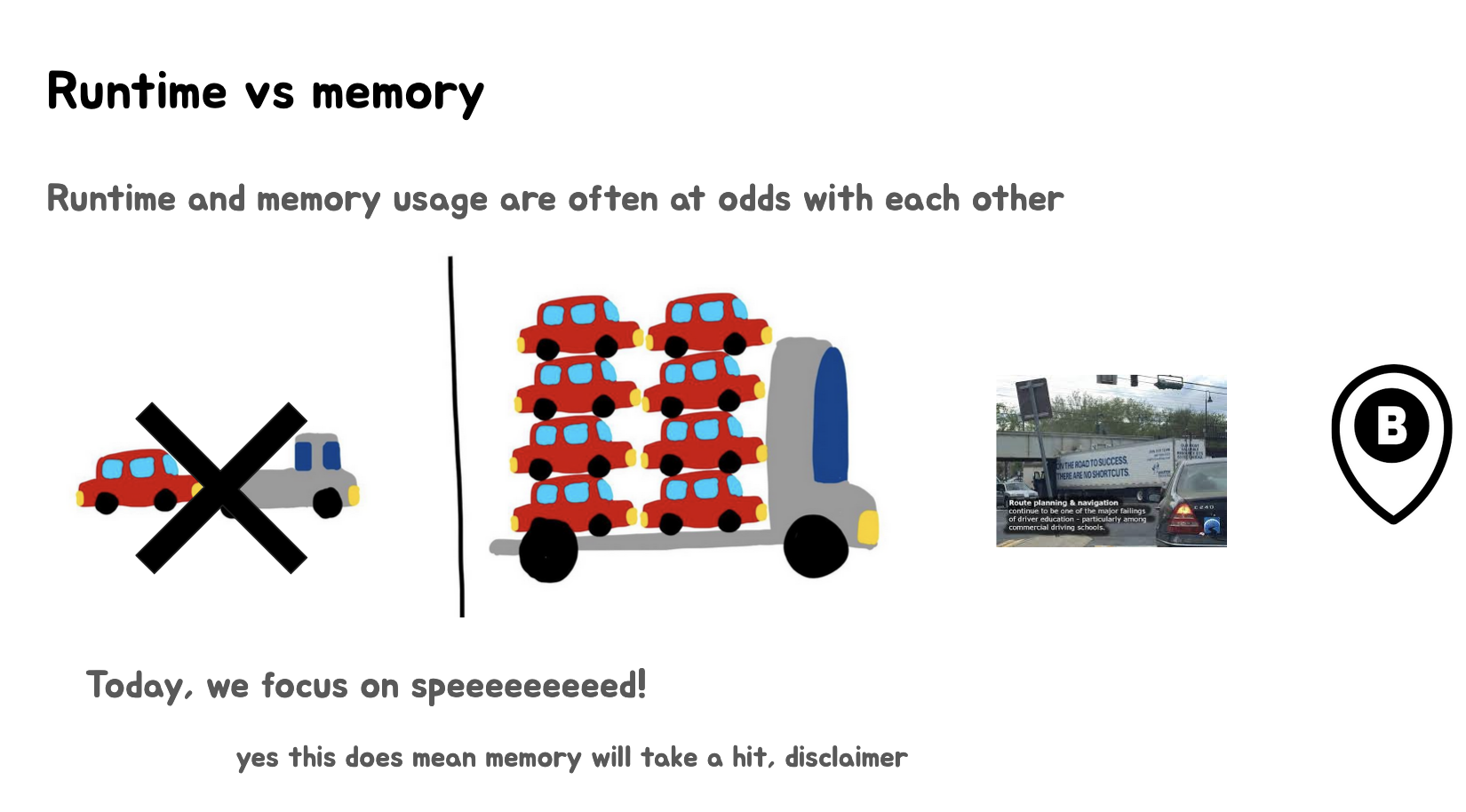
上面三张Slides讲述了运行时间(runtime)和内存使用(memory usage)之间的权衡关系。
第一张Slides:
- 介绍了运行时间和内存使用通常是相互矛盾的。
- 展示了两种运输车辆:一辆小卡车(代表低内存使用但速度慢)和一辆大卡车(代表高内存使用但速度快)。
- 提出了一个问题:如果要运送512辆车,应该选择哪种卡车?
第二张Slides:
- 在第一张图的基础上增加了一个新的限制条件:途中有一座低通桥。
- 这代表了在某些情况下,我们可能无法简单地选择高内存使用的方案(大卡车),因为存在硬件或系统限制。
第三张Slides:
- 明确表示"今天我们专注于速度!"
- 显示了小卡车被划掉,表明选择了大卡车(高内存使用但速度快的方案)。
- 同时提醒"这确实意味着内存会受到影响,免责声明"。


这张Slides展示了一个naive的优化器实现,核心要点是假设有M个参数,对于每个参数有N个操作,那么遍历所有参数并处理完共需要M * N个操作。

这张Slides介绍了一种称为"horizontally fused optimizer"(水平融合优化器)的优化方法,可以把naive的优化器实现中的for循环fuse掉。

这张Slides介绍了实际上我们可以把整个优化器的操作fuse成一个cuda kernel。
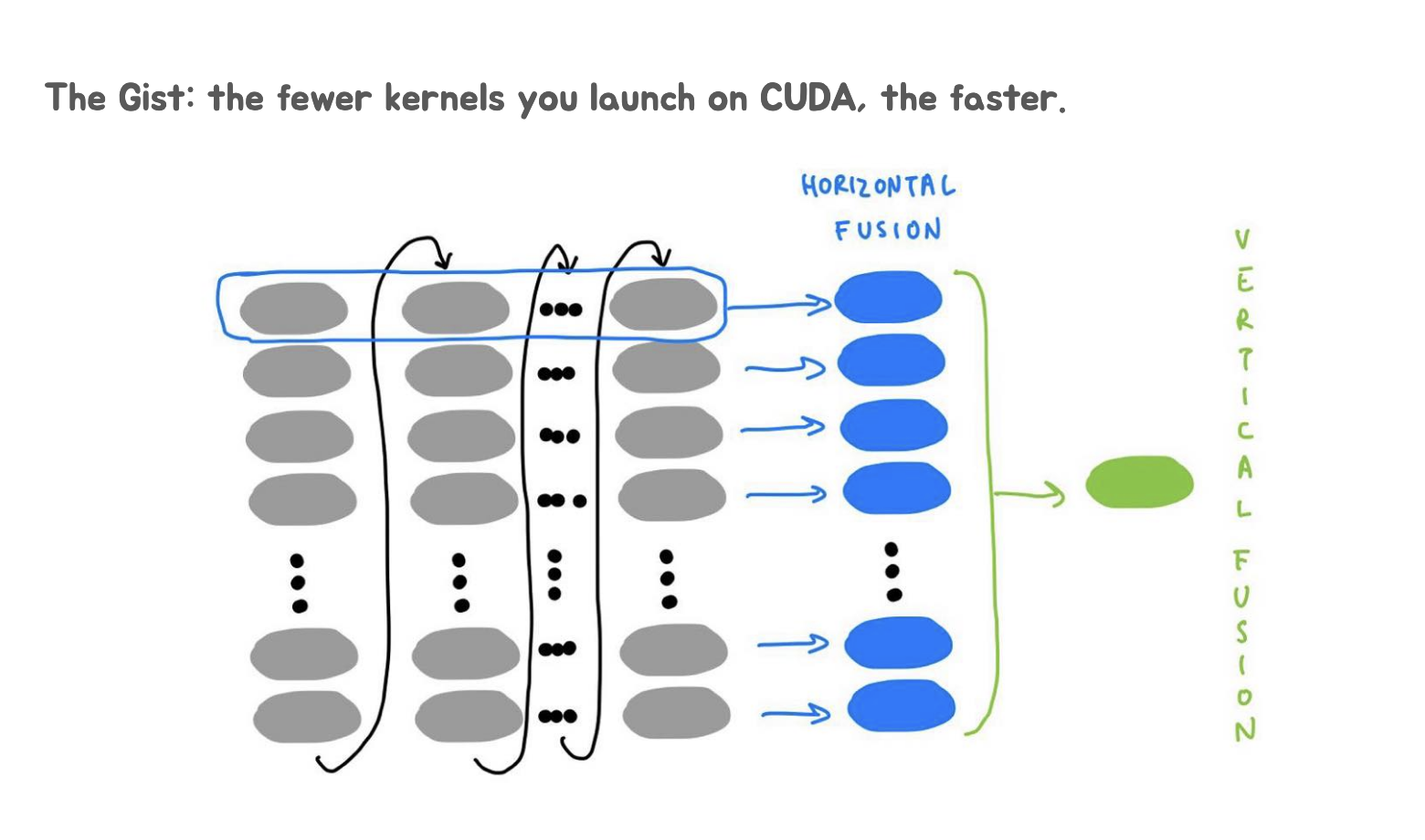
这张Slides传达的核心信息是:在CUDA编程中,通过减少kernel启动的次数可以提高程序的执行效率。这是因为每次启动CUDAkernel都会有一定的开销,如果能够将多个操作合并到更少的kernel中,就可以减少这些开销,从而提高整体性能。水平融合和垂直融合是实现这一目标的两种主要策略:水平融合合并了相似的并行操作;垂直融合则进一步合并了不同的计算步骤。



上面倒数第二张Slides类比了线粒体是细胞的能量工厂,而multi_tensor_apply是高速优化器的"动力卡车"。展示了一辆装载多辆小汽车的大卡车,暗示multi_tensor_apply可以同时处理多个张量。说明multi_tensor_apply允许我们对张量列表进行操作,而不是单个张量。
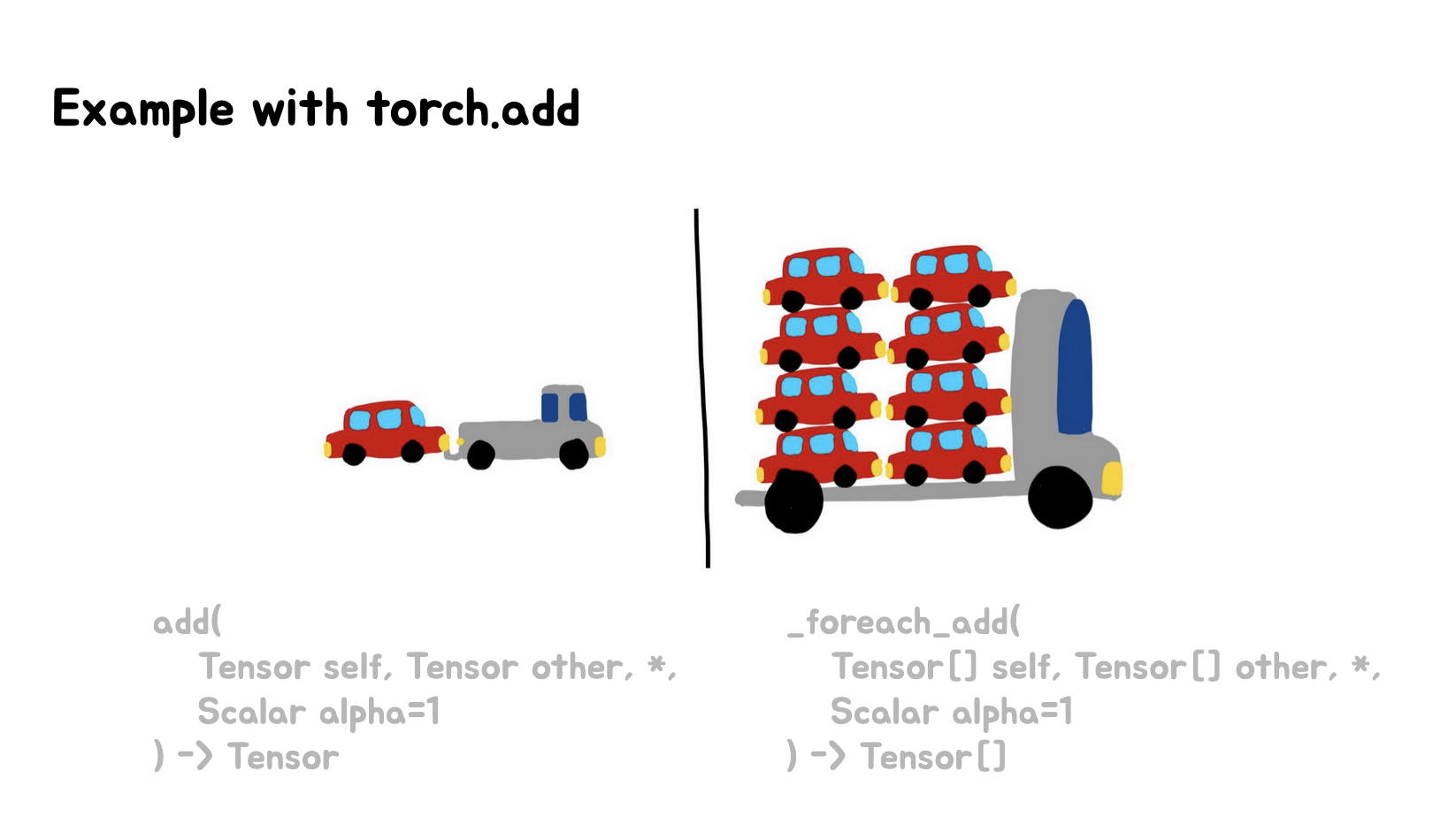
上面最后一张Slides,对比了普通的torch.add操作(左侧小车+小卡车)和_foreach_add操作(右侧大卡车装载多辆小车)。






上面的一系列Slides在讨论如何在CUDA中实现一个用于多个张量的add操作(_foreach_add)时输入应该怎么如何传递。
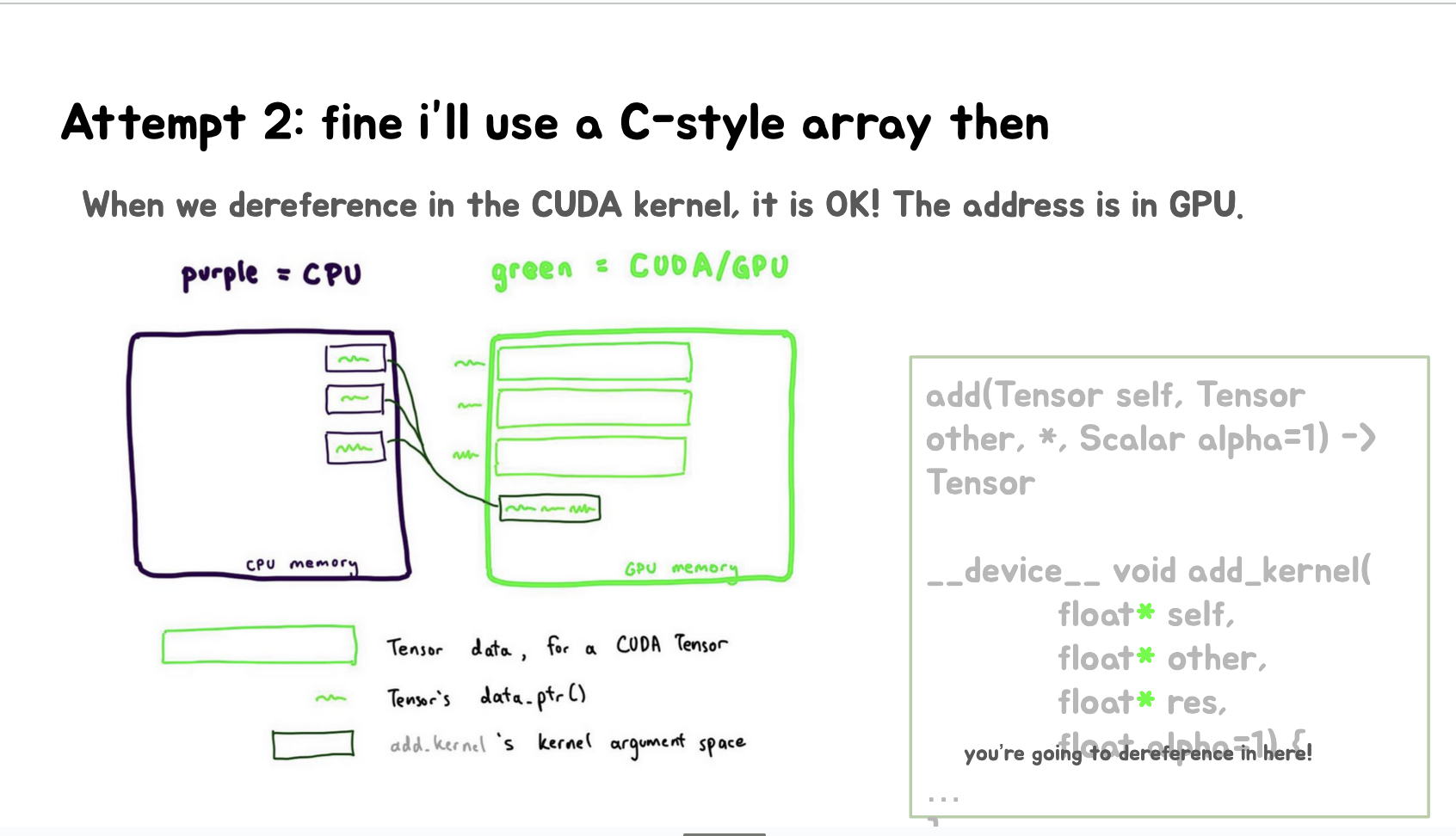
上面第一张Slides展示了普通的add操作和_foreach_add操作的函数签名。提供了一个普通add操作的CUDA kernel签名,假设使用float类型的Tensors,引出问题:应该怎么给_foreach_add操作的CUDA kernel写签名?
第二张和第三张Slides尝试使用std::vector<float*>来实现_foreach_add_kernel,这种方法不行,因为CUDA不识别std::vector。
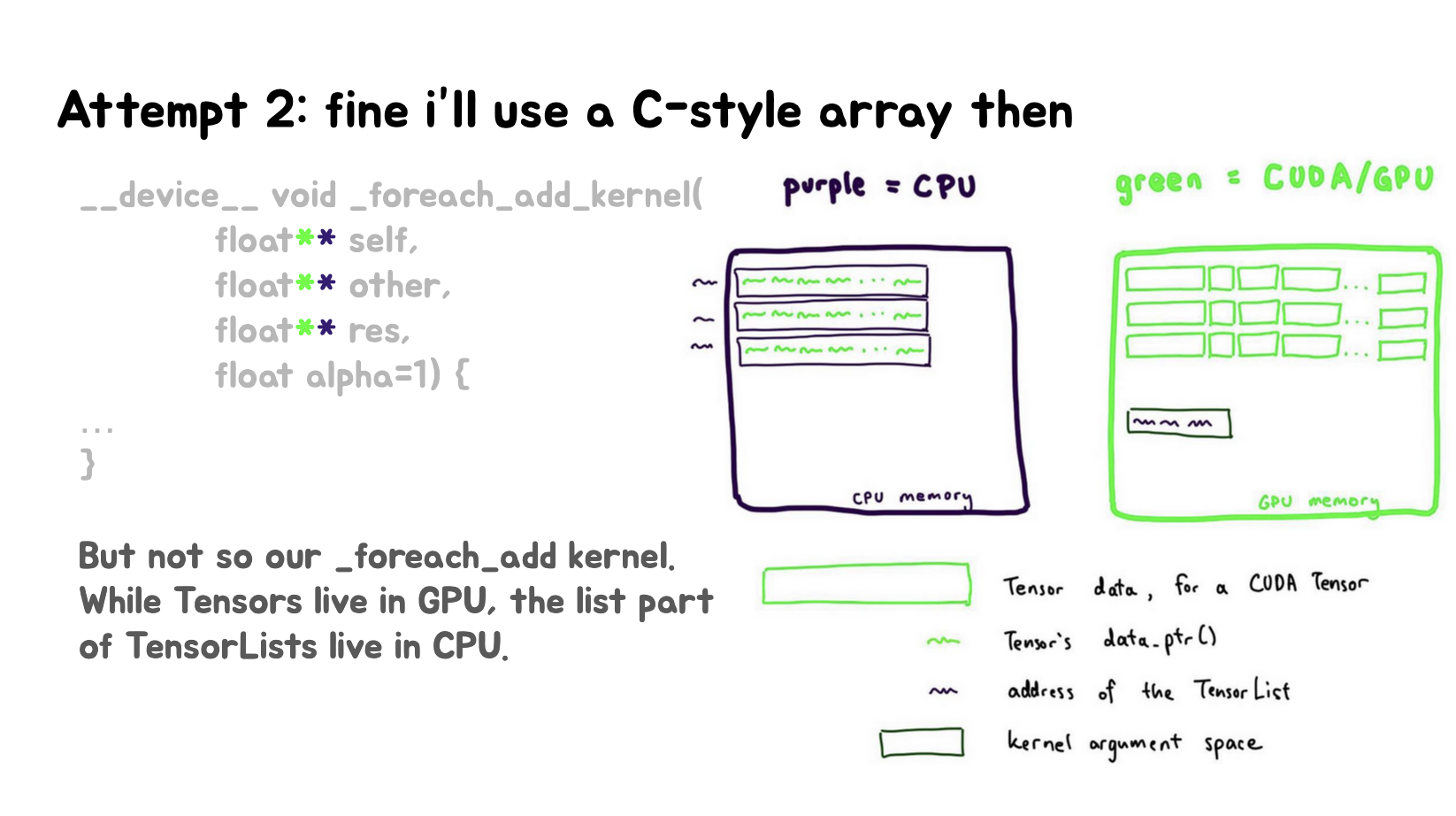
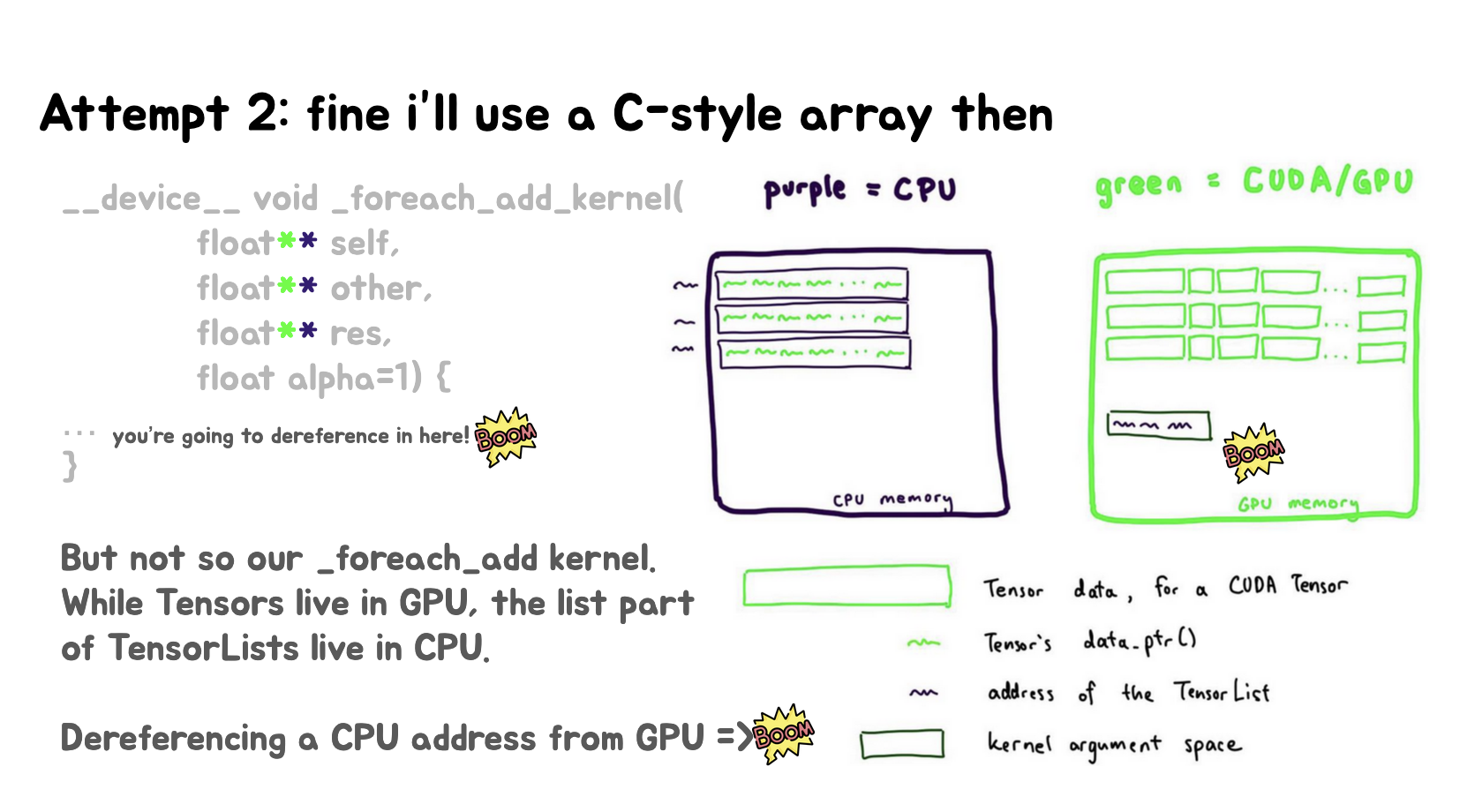
第四张和第五张Slides尝试使用C风格的数组(float**)来实现_foreach_add_kernel,结论:这种方法也不行,会导致非法内存访问(IMA),因为外层指针*是CPU地址。
Slides里面还画了一些示意图用于解释这个问题。

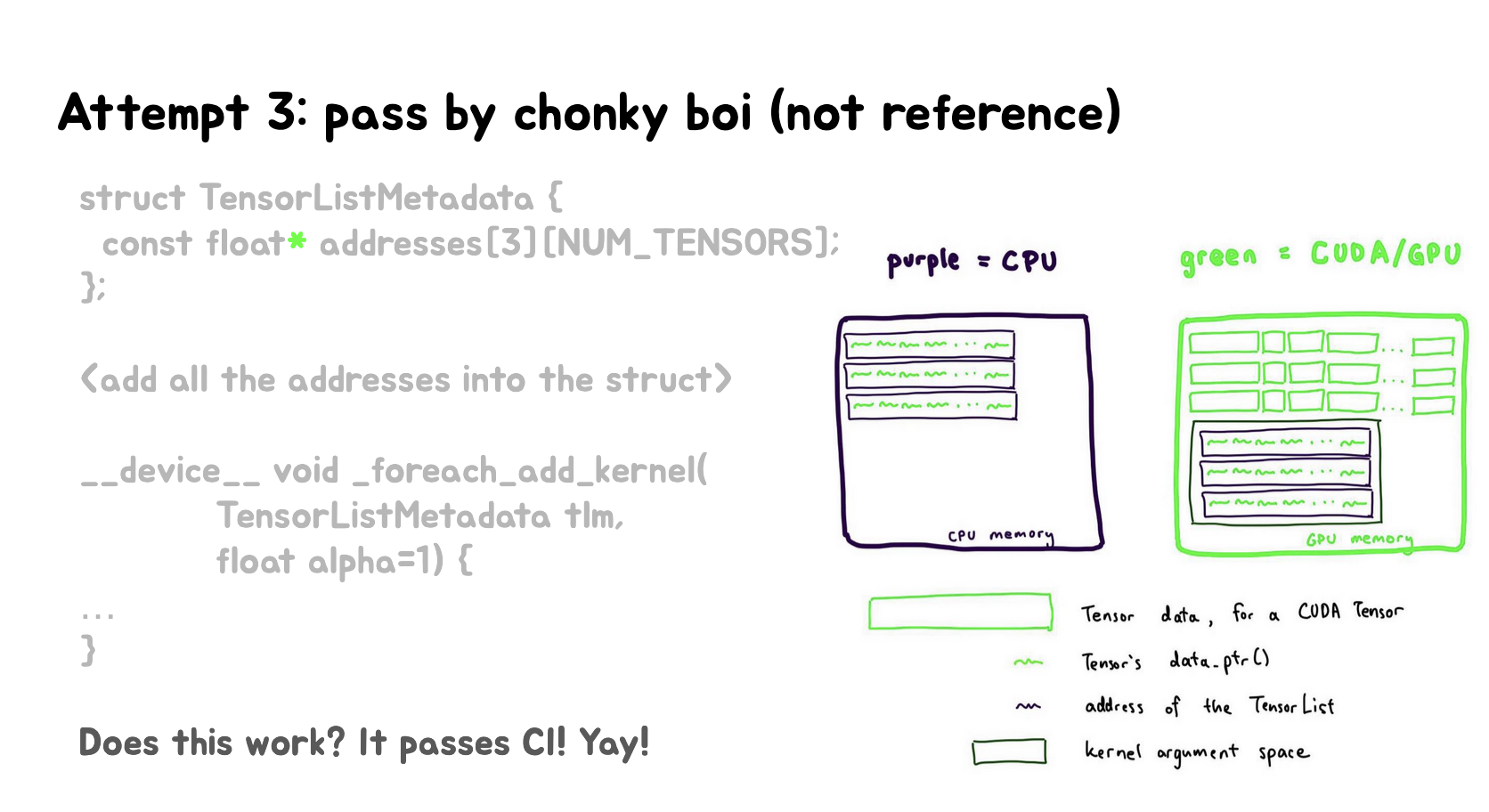
这两张Slides讲解了在CUDA中实现多张量操作(specifically _foreach_add)的第三种尝试方法,称为"pass by chonky boi"(通过大块数据传递)。
- 方法描述:
- 创建一个名为TensorListMetadata的结构体,用于存储多个张量的地址信息。
- 结构体包含一个二维数组
addresses[3][NUM_TENSORS],用于存储三组张量(可能是输入、输出和中间结果)的地址。
- 内存布局说明:
- 紫色框代表CPU内存,绿色框代表GPU/CUDA内存。
- 在GPU内存中,张量数据和kernel参数空间被分开存储。
- 张量的数据指针(data_ptr())和张量列表的地址都存储在GPU内存中。
- 结果:
- 这种方法成功通过了编译(“It passes CI! Yay!”)。
- 它解决了之前尝试中遇到的问题,如std::vector不被CUDA支持,以及直接使用指针数组导致的非法内存访问。


这里说明的是尝试上面的大块数据传递方式之后作者碰到了CUDA中的非法内存访问。问题似乎与张量列表的大小(N)有关。在N=423和N=424之间存在一个临界点,可能与CUDA的内存管理或某些硬件限制有关。
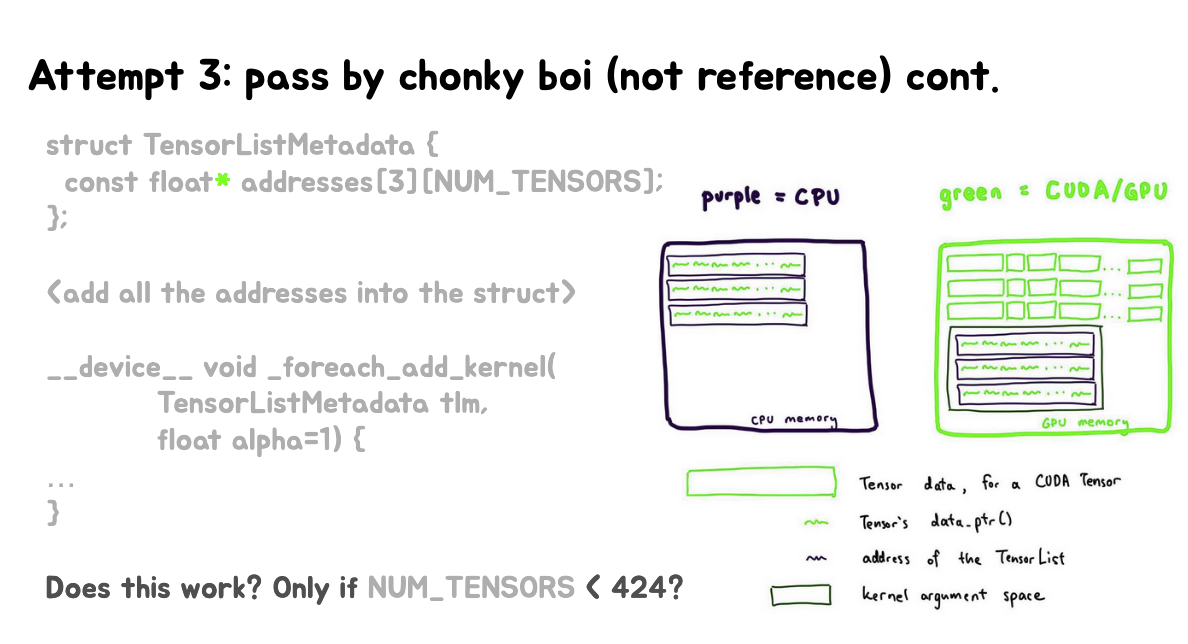
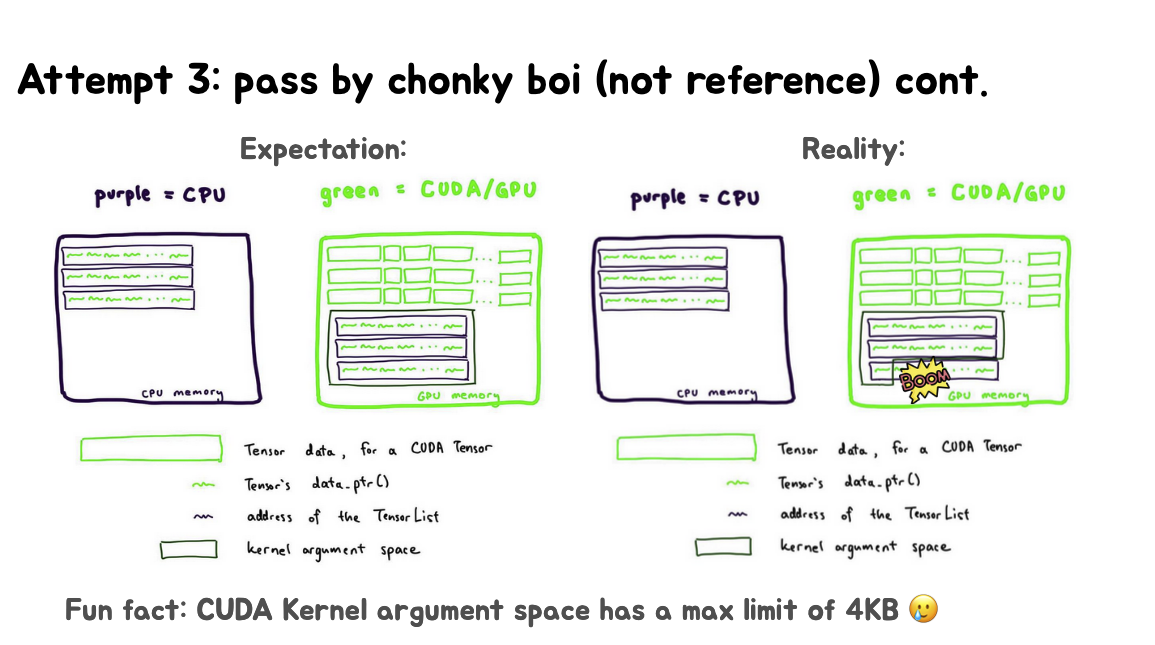
这里继续说明了当尝试传递大量数据(在这里是张量地址)作为kernel参数时,可能会超出CUDAkernel参数空间的4KB限制,导致程序失败。这就解释了为什么只有当NUM_TENSORS小于某个特定值(这里提到424)时,代码才能正常工作。
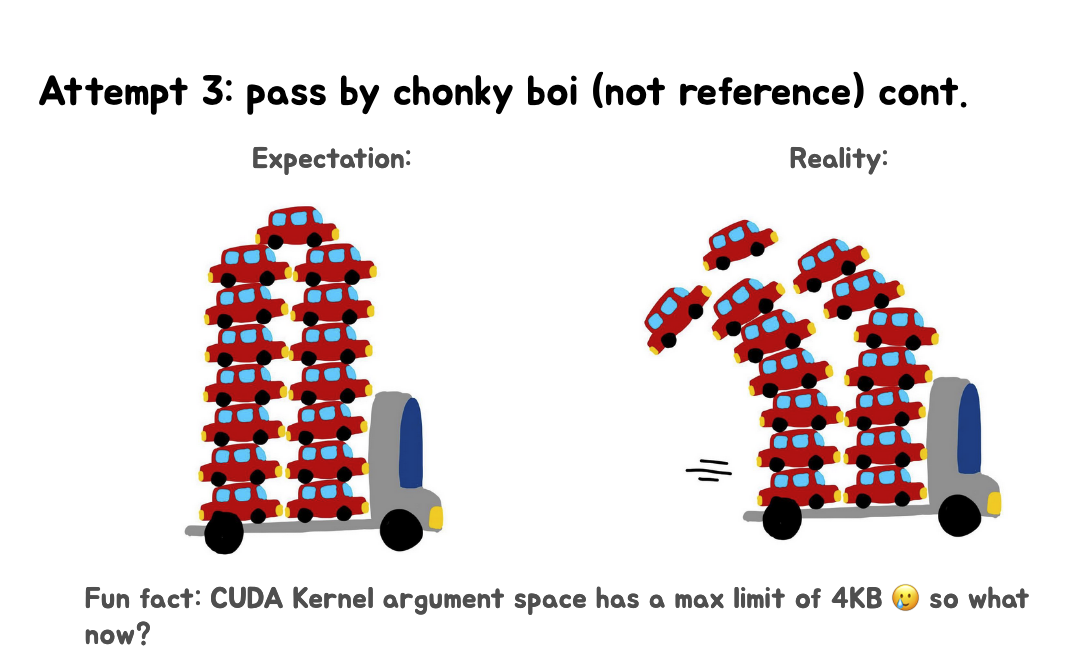
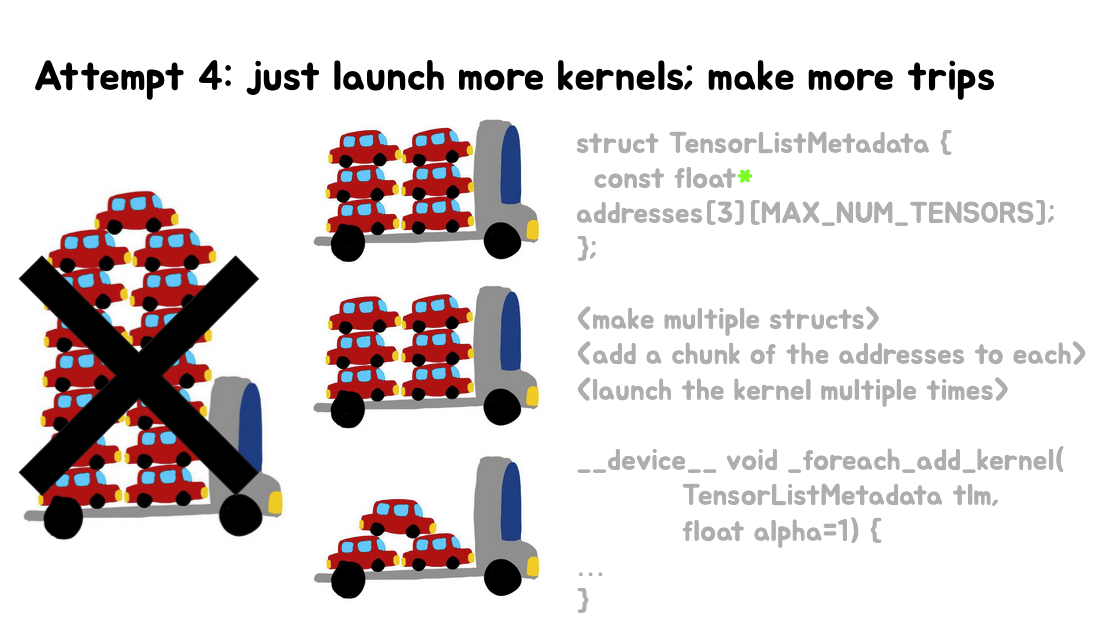
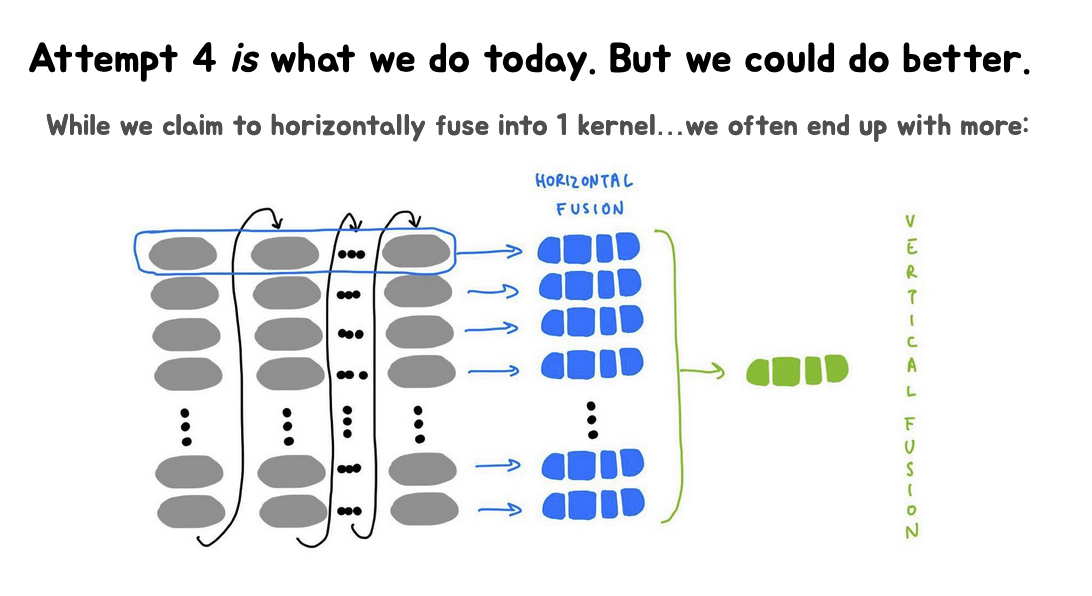
这里的第一张Slides期望是能够一次性将所有数据(用小汽车表示)装载到一辆大卡车上。现实是由于CUDAkernel参数空间的4KB限制,无法一次性装载所有数据,导致部分数据"掉落"。第二张Slides提出了"Attempt 4"(第四次尝试)的解决方案,建议通过多次启动kernel来解决问题,即"make more trips"(多次运输)。第三张Slides展示了当前的方法是进行水平融合(Horizontal Fusion),将多个操作合并到一个kernel中,但实际上常常会产生多个水平融合的kernel和垂直融合的kernel。
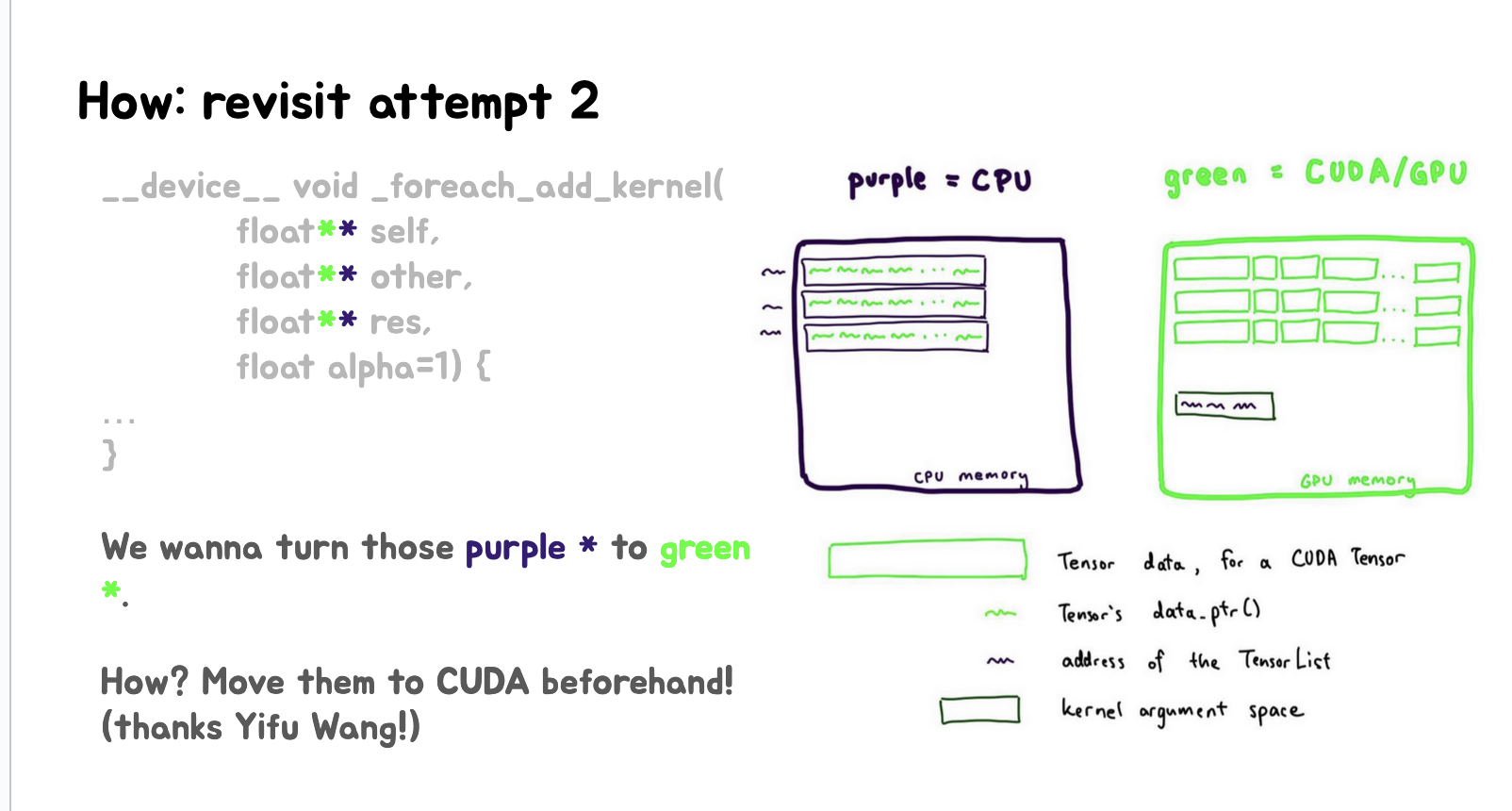
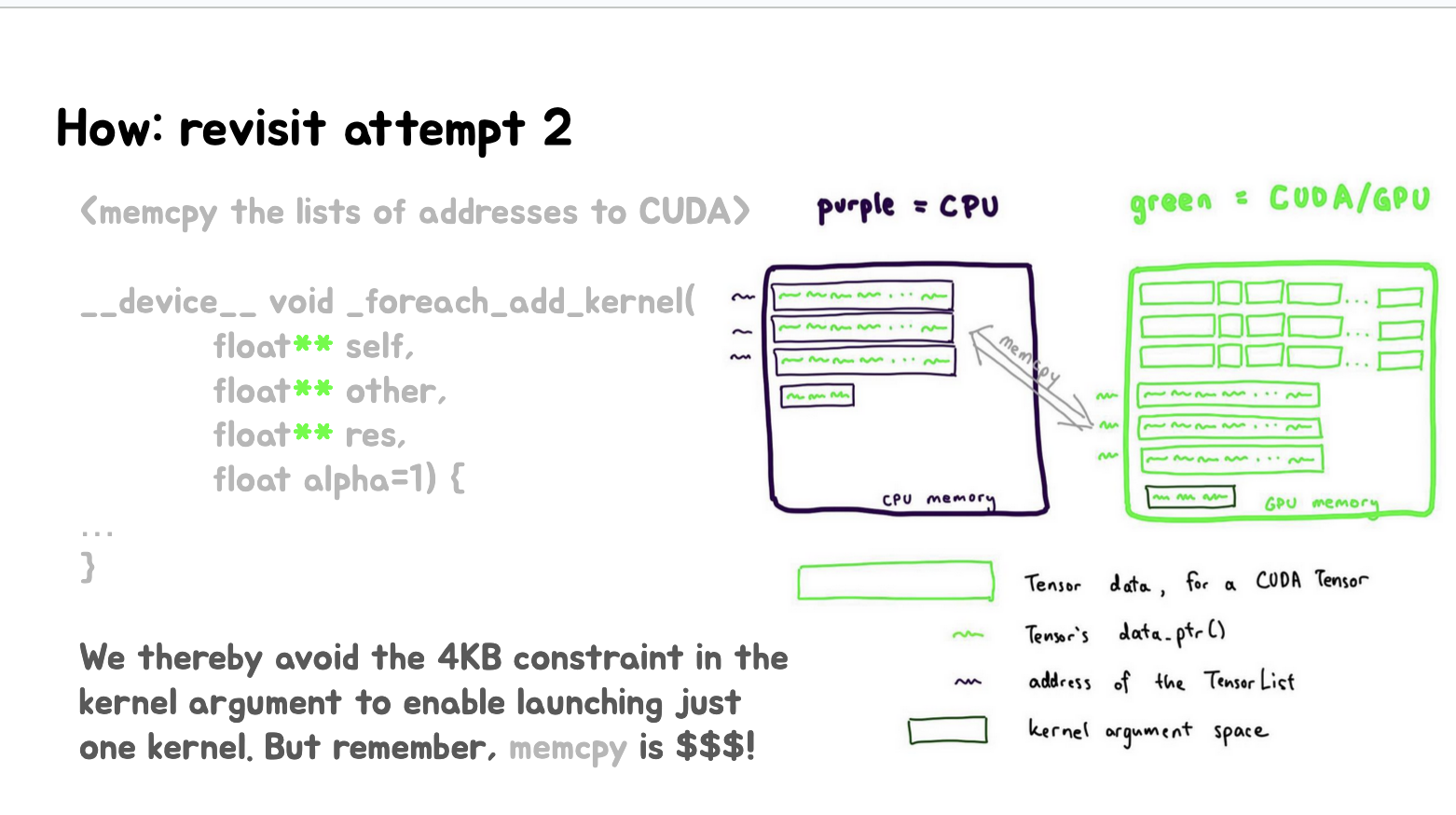
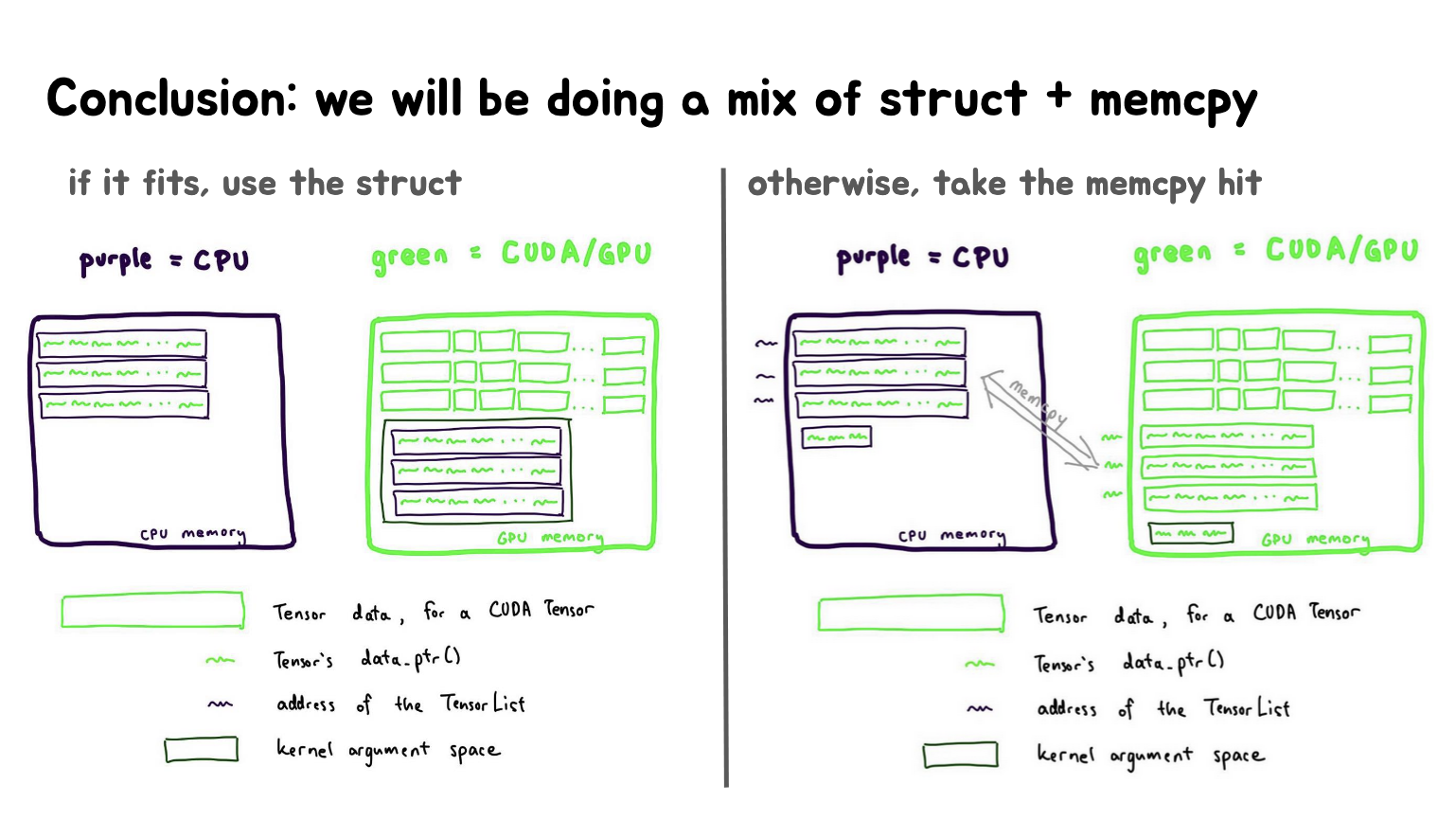
这里的第一张Slides展示了"尝试2"的回顾,目标是将CPU内存(紫色)中的数据转移到CUDA/GPU内存(绿色)中。最后提出了将紫色的指针(*)转变为绿色的想法,即将数据从CPU移到GPU。第二张Slides进一步详细说明了解决方案,即使用memcpy将地址列表复制到CUDA内存中。通过这种方法,可以避开CUDAkernel参数空间的4KB限制,从而能够启动单个kernel处理所有数据,注意,memcpy操作是昂贵的($$$)。
第三张Slides总结了最终的解决方案,提出了结构体(struct)和memcpy的混合使用策略。左侧:如果数据量较小,符合kernel参数空间限制,就直接使用结构体传递。右侧:如果数据量超过限制,则使用memcpy将数据复制到GPU内存,然后传递指针。
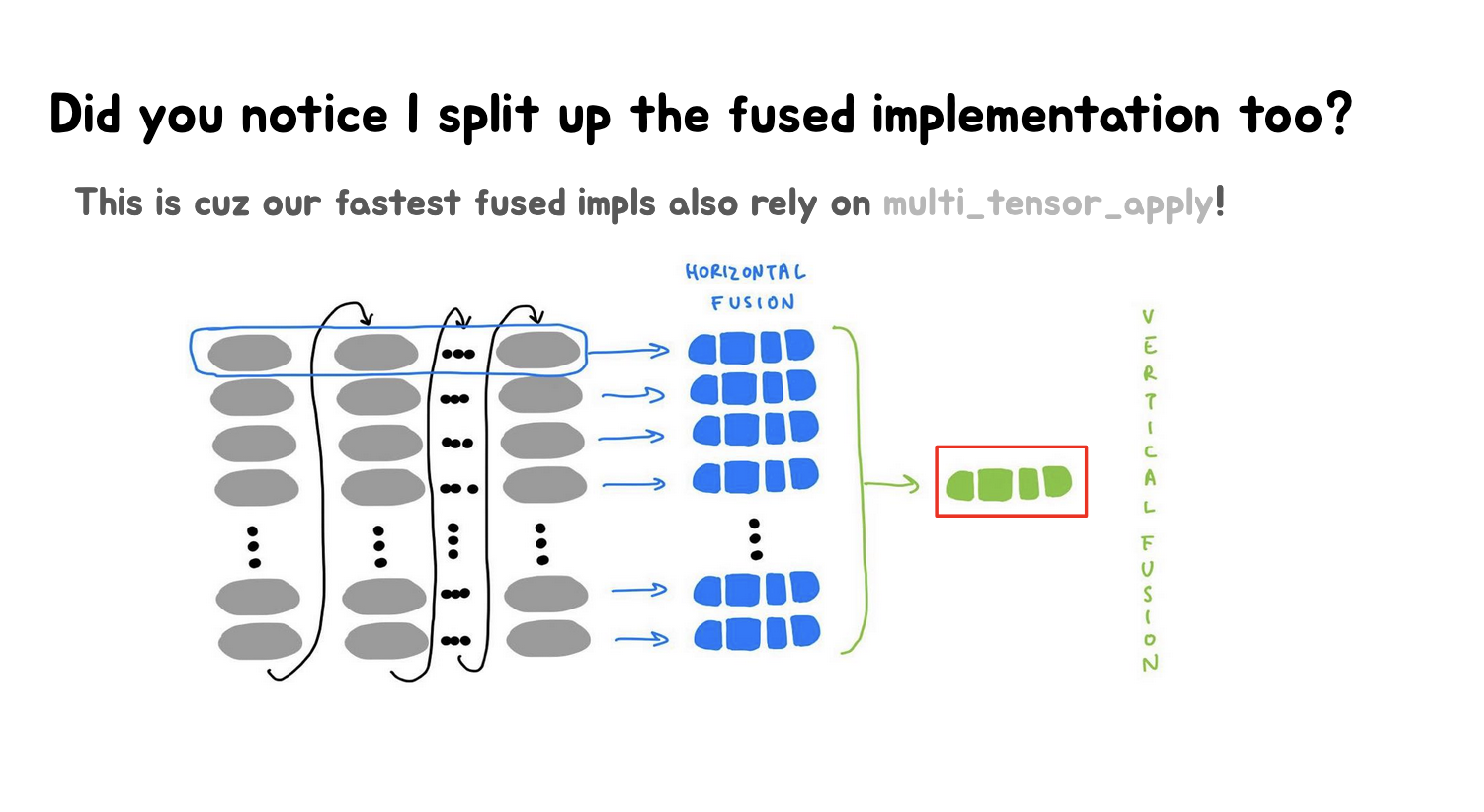
这里的第一张Slides展示了水平融合(Horizontal Fusion)和垂直融合(Vertical Fusion),多个独立的操作(灰色块)首先进行水平融合,变成蓝色的块,然后这些蓝色的块可能进一步进行垂直融合,形成一个更大的绿色块。这种看起来比较麻烦的实现依赖multi_tensor_apply函数。
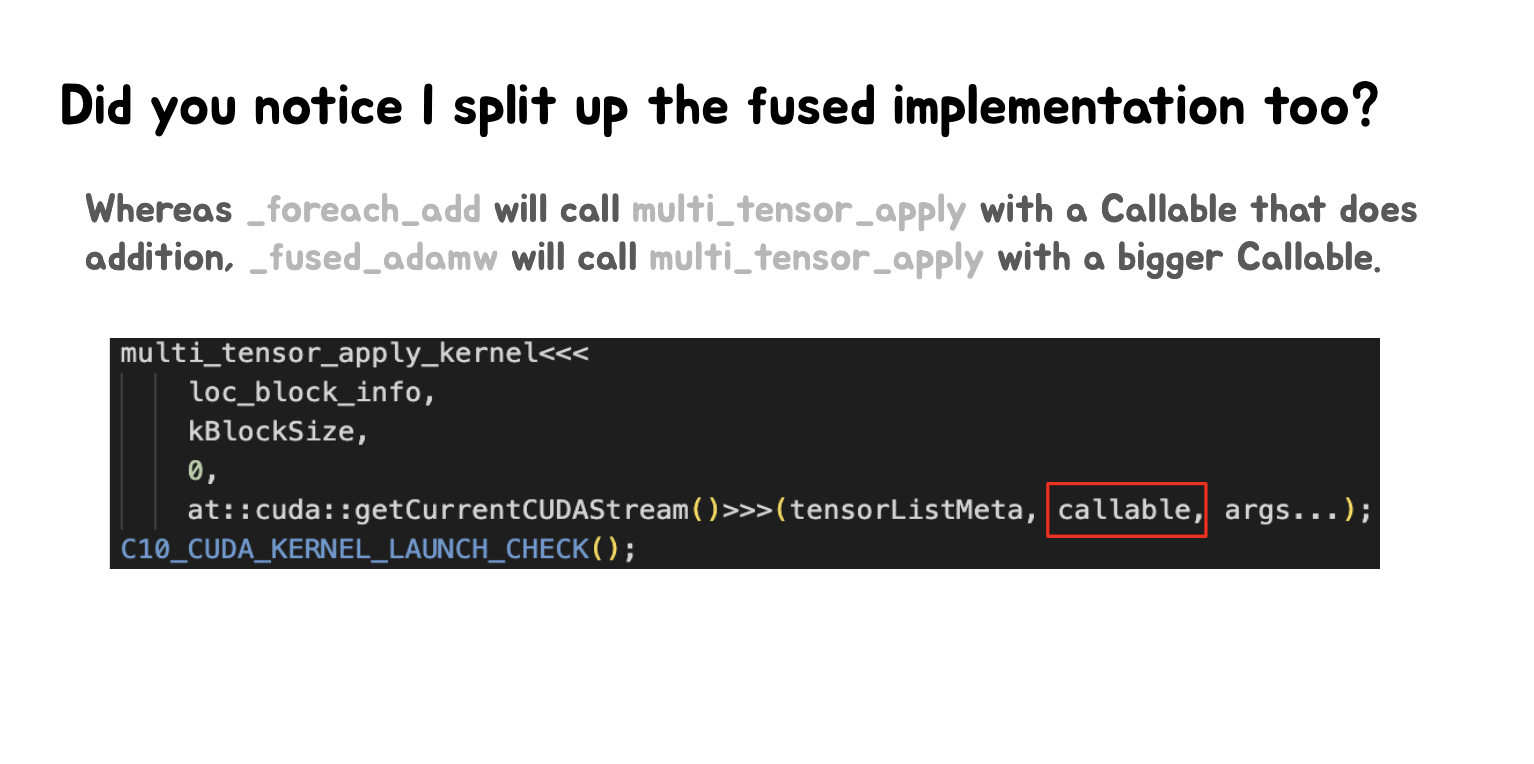
第二张Slides解释了 _foreach_add 和 _fused_adamw 两种操作的实现差异。_foreach_add 调用 multi_tensor_apply 时使用一个执行加法的 Callable。_fused_adamw 调用 multi_tensor_apply 时使用一个更大的 Callable。还展示了 multi_tensor_apply_kernel 的代码片段,其中包含 callable 参数。
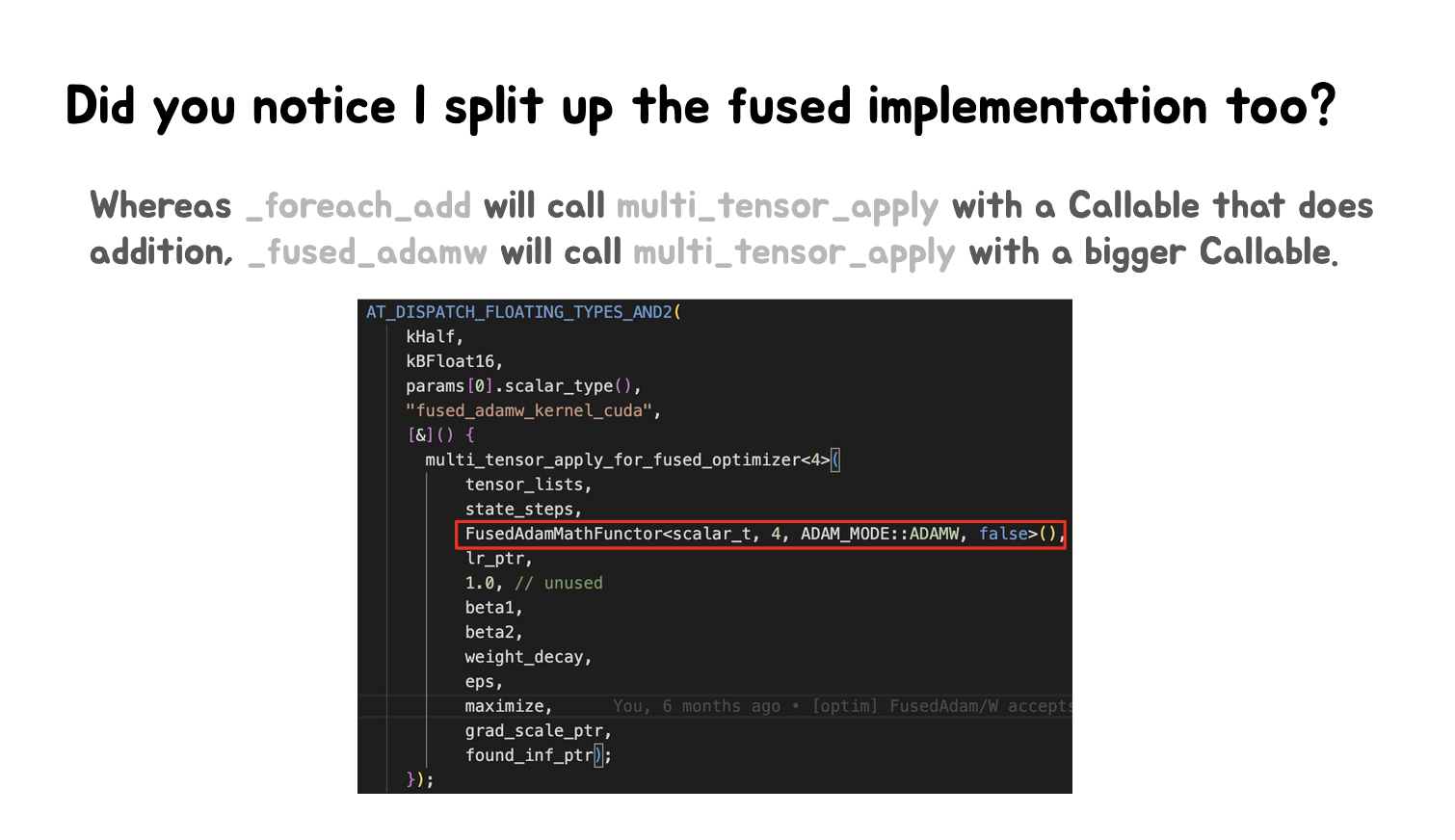
第三张Slides继续解释了 _foreach_add 和 _fused_adamw 的实现差异并展示了 _fused_adamw 的具体实现代码。可以粗略浏览到以下内容,使用AT_DISPATCH_FLOATING_TYPES_AND2 宏来处理不同的浮点类型。调用 multi_tensor_apply_for_fused_optimizer 函数,传入 FusedAdamMathFunctor 作为参数。

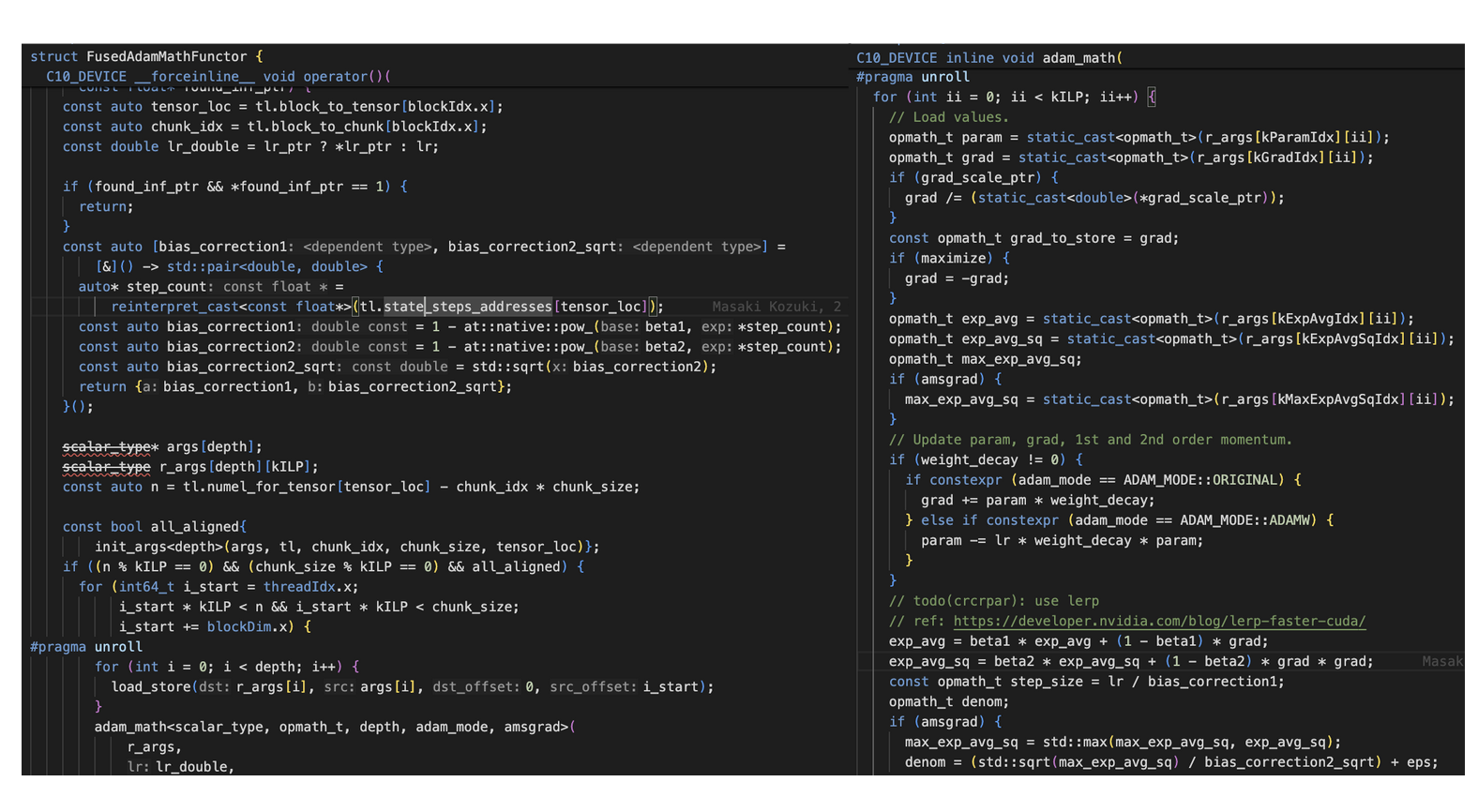

这里UP主展示了FusedAdamMathFunctor的代码实现,包括两个主要部分:
- 左侧是FusedAdamMathFunctor结构体的定义,包含operator()函数的实现。
- 右侧是adam_math函数的实现,这是Adam优化器的核心计算逻辑。实现了Adam优化器的各个步骤,包括梯度计算、一阶和二阶动量更新等
这里的第三张Slides显示了"…that was very manual."的文字,暗示这种实现方式是非常手动和复杂的。

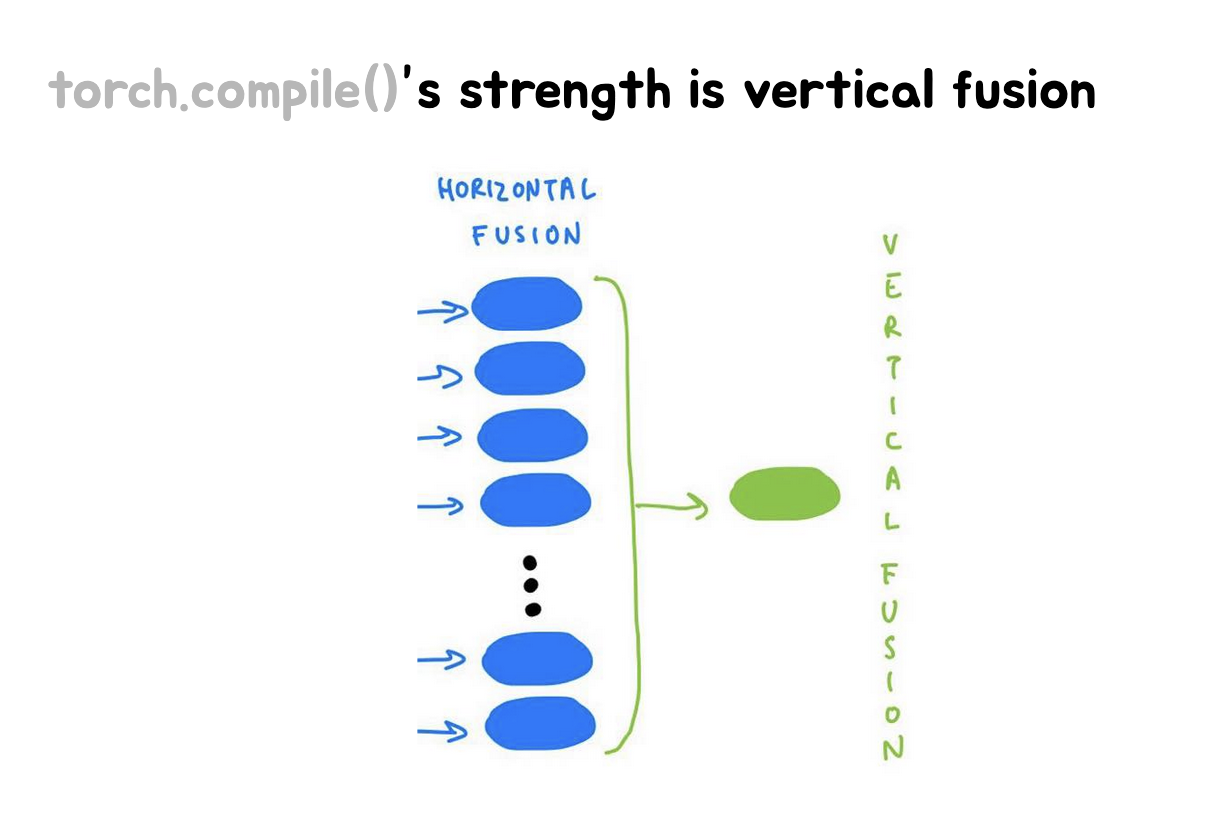


这几张Slides讲了PyTorch中的torch.compile()功能及其在优化器中的应用,主要内容如下:
- 第一张Slides介绍了torch.compile()函数。
- 第二张Slides解释了torch.compile()的主要优势是垂直融合(vertical fusion)。图示展示了如何将多个水平融合(horizontal fusion)的操作进一步垂直融合成一个更大的操作。
- 第三张Slides展示了如何在优化器中使用torch.compile():
- 首先创建一个AdamW优化器
- 然后使用@torch.compile装饰器定义一个compiled_step函数
- 在训练循环中,使用compiled_step替代原来的optimizer.step()
- 最后一张Slides展示了torch.compile()生成的Triton kernel的一部分代码。这是一个大型的、高度优化的kernel,包含了许多临时变量(tmp0, tmp1等)和复杂的数学运算。这说明torch.compile()确实可以生成非常复杂和高效的fuse kernel。

最后这张Slides展示了了 PyTorch 中编译优化器(compiled optimizers)的工作条件和使用情况。
- 需要 CUDA 功能版本 7.0 或更高以支持 Triton
- PyTorch 中所有具有 foreach 实现的优化器现在都可以编译。
- 除了 L-BFGS 和 SparseAdam 外,其他所有优化器都支持编译。
- 任何支持的 foreach* 操作序列都应该能够进行垂直融合。
- 鼓励用户尝试自己的实验性优化器。如果发现不能工作的情况,建议提交issue。
个人总结
这节课实际上就是宏观介绍了一下PyTorch的Optimizer是怎么通过CUDA kernel fuse优化的。我这里使用Claude-3-Opus-200k来总结一下这节课涉及到的要点。
下面的内容由Claude-3-Opus-200k总结而成
这堂课程的主要内容是介绍如何在PyTorch中优化优化器的性能。重点包括以下几个方面:
- 1.运行时间和内存使用之间的权衡。一般来说,提高速度往往需要更多的内存。但有时也会受到硬件或系统的限制。
- 2.优化器实现的不同方式:
- Naive实现:简单地遍历所有参数,执行所有操作,总共需要M*N次操作。
- 水平融合(Horizontally fused):将循环融合,减少总操作数。
- 垂直融合(Vertically fused):将整个优化器操作融合成一个CUDA kernel。
- 3.在CUDA编程中,减少kernel启动次数可以提高效率。这可以通过水平融合(合并相似的并行操作)和垂直融合(合并不同的计算步骤)来实现。
- 4.PyTorch中的multi_tensor_apply函数允许同时对张量列表进行操作,类似于vectorized的"_foreach"操作。但需要注意CUDA kernel参数空间的4KB限制。
- 5.针对超出4KB限制的情况,可以采取的解决方案:
- 分多次启动kernel(make more trips)
- 使用memcpy将数据从CPU复制到GPU内存
- 结合使用struct和memcpy:小数据量直接用struct传递,大数据量先memcpy再传递指针
- 6.手动实现水平和垂直融合的优化器(如FusedAdamW)的过程比较复杂。
- 7.PyTorch的torch.compile()功能可以自动生成高度优化的vertical fusion kernel,大大简化了编译优化器的实现。
- 8.目前PyTorch中大部分优化器都支持编译优化(compiled optimizers),但对CUDA版本有要求(>=7.0)。用户也可以尝试自己的实验性优化器。
总的来说,这门课深入讲解了如何从多个方面优化PyTorch中的优化器实现,包括算法层面的水平/垂直融合,工程实现层面的参数传递和内存管理,以及新功能torch.compile()带来的便利。