《仙剑世界》作为仙剑 IP 系列的最新⻓篇⼒作,从故事和剧情上延续了仙剑的精髓。在仙剑 33 年的世界观下,《仙剑世界》打造出了⼀个由浪漫唯美的江南全景、磅礴恢弘的蜀⼭、神秘苗疆等区域构成的 384 平⽅公⾥完整的⽆缝开放⼤世界。以东⽅题材为起点,以江南的浪漫为开端,以巴蜀的幻想⻛格作为延续,通过不断的迭代和内容更新,为籼⽶们奉上⼀款难以忘怀的仙侠⼤作。
Unity 中国有幸采访到了主创团队,并邀请他们参加了 Unite 上海 2024,与开发者们面对面交流。
以下是采访内容、Unite 活动现场整理汇总。梳理《仙剑世界》是如何使用 HDRP 打造开放大世界,并进行跨平台优化。本文强烈建议收藏
可以为我们简单介绍下团队和项⽬吗?
⼤家好,我们是中⼿游旗下的满天星⼯作室,核⼼成员为原巨⼈⽹络巨⽕⼯作室原班团队,参与过《征途》端游研发,主导了《巨⼈》端游,《仙侠世界》系列端游和《⻰珠最强之战》⼿游的研发。⽬前我们正在开发的《仙剑世界》,是中⼿游⾃研⾃发的仙剑 IP ⾸款开放世界 RPG,游戏致⼒于在多端平台打造⼀个万物有灵的东⽅浪漫幻想世界。

但在项⽬研发早期,由于场景庞⼤,对视野要求也很⾼,我们⼀度纠结如何能在有限的时间内整合各类效果好的 feature,管理开销。所幸有 Unity HDRP 管线,得益于它的特性,最终帮助我们实现了对游戏世界的畅想,充分展现出东⽅浪漫幻想世界的魅⼒。

HDRP 相对于 URP,给《仙剑世界》带来了什么好处?
URP 确实是⼀个⾮常简洁灵活的渲染管线,但是当我们需要制作⼀款在 PC 体验的⼤世界游戏的时候,URP 就会有⼀些稍显不⾜的地⽅。特别是我们当时使⽤的是Unity 2021,URP 在原⽣⽀持的 feature上略微少⼀些。反之,HDRP 管线则为我们内置了⼤量⾮常实⽤且效果很好的 feature,确实为我们在项⽬初期,提供了快速、稳定、优质的画⾯效果提升。

*Unite Shanghai 2024《仙剑世界》 HDRP Feature 展⽰
例如,HDRP 下内置的 SSGI,在我们⾃⼰的 PRTGI ⽅案还未落地时,为游戏提供了很好的 GI 画⾯⽀持。SSS 也为⻆⾊⽪肤提供了⾮常好的质感,让⻆⾊变得更加真实⾃然,⽐项⽬早期使⽤预积分 Lut 的⽪肤 SSS ⽅案要更加润泽和透亮,总体来说更符合我们游戏中国⻛⼈物的⽪肤质感。Tile/Cluster 的点光解决⽅案,也让场景灯光师可以肆意摆放灯光,为副本、夜晚提供很棒的氛围和质感。另外对于实时天⽓和⽇⽉变化,当时 HDRP 下提供的 Volume 体系也可以实现⾮常炫酷的效果,甚⾄提供管线的管理和混合效果。⼜⽐如,我们剧情导演希望引擎这边能提供⼀个⽐较⾼质量基于物理的 DOF(景深) 效果,那 HDRP 下的 DOF 就是⼀个很好的选择,它基于物理相机的整套参数调整,可以让我们的剧情导演⾮常容易上⼿和理解。

*HDRP SSAO 遮蔽效果展示
在研发早期,⼈⼒相对⽐较紧张,但⼜正是项⽬确⽴游戏⻛格效果、质量体系等标准的时候, HDRP 相⽐于 URP 会更加适合我们,因此我们也⾮常坚定地选择了 HDRP 管线作为我们的渲染管线。从最终结果上看,它也为我们节约了不少预研时间,加快了开发进度。当我们想要尝试某些效果,⼏乎只需要在管线设置上打开相应开关,即可看到它带来的画⾯变化,⾮常⽅便。

*HDRP PCSS 阴影效果展⽰
从 PC 端移植到移动端⼤概花了多久?移植过程中遇到的最⼤困难是什么?
在最开始的时候,项⽬是基于 URP 管线的,但是由于 PC 端⽇渐新增的画⾯提升需求,我们加⼊了 HDRP 来作为 PC 端的管线。也就是说这个时期,我们确实是 URP 和 HDRP 同时进行的。
之所以选择同时进⾏,是因为 HDRP 原⽣不⽀持移动平台,放眼全球⾏业,也鲜有其他游戏对 HDRP 进⾏移植的案例。所以我们⼀开始对它报以谨慎的态度,对 HDRP 管线技术不断地进⾏学习和整合。但是随着对 HDRP 使⽤的深⼊,我们了解了它的各种特性和优点之后,出于对引擎维护和资产流程管理成本的考虑;也因为我们团队相对有⽐较成熟的 PC 和移动平台的开发移植经验,对⾃⼰的技术实⼒也很有信⼼。所以经过评估之后,我们决定将 HDRP 向移动平台进⾏移植。⾄此,我们游戏就只有 HDRP ⼀套渲染管线了。

*Unite大会上《仙剑世界》HDRP 跨平台优化技术分享
在开始移植之前,我们预留了约⼀个⽉左右的时间作为移植的缓冲时间,以防⽌遇到难以解决的突发问题。另外,我们提前评估了所有 PC 上我们正在使⽤的,甚⾄还未使⽤但是很可能会⽤到的 HDRP 下所有 feature,它们在移动端上可能的性能表现,⽤于确定是否能在移动平台保留或简化这些 feature。我们经过多次会议和讨论,确定了⼤体的移动端管线结构和流程,以及对应的RT的格式和尺⼨。然后就是通过平台宏控制,将移动平台下预期不佳的功能,从管线和 Shader 上先进⾏了屏蔽,渲染管线也进⾏了重新设计,以适配移动平台的带宽压⼒。在完成这些整理之后,我们才开始正式移植到移动真机上的。整个移植过程⾮常⾮常顺利。由于绝⼤部分的问题在上真机之前就已经预料和屏蔽了,因此⼏乎没有遇到什么困难就可以在移动平台的⾼端设备上跑起来。
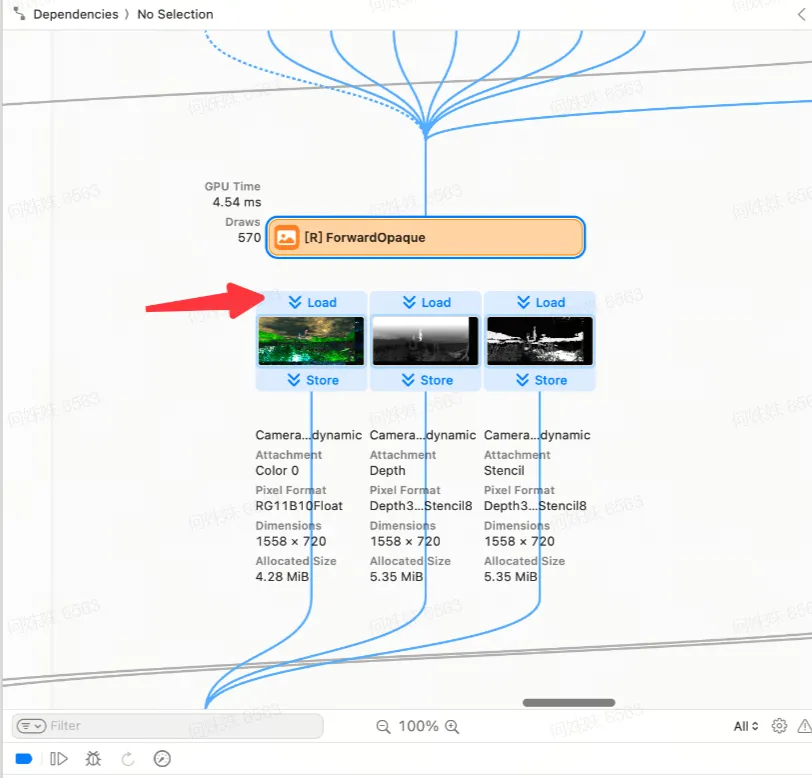
*Opaque 的 ColorBuffer 的 load 是不必要的
只是真正的难关,是在跑起来之后。
在 HDRP 移植到真机之后,我们发现其运⾏性能实在不是很好,⼤约可能只有 10+、20+ 的 FPS。这个离我们的预期太远了,所以我们开始 Profiler 真机看看问题都出在哪⾥。
主要的问题就是在 Shader 上⾯。HDRP 的标准 Lit Shander 在移动平台下编译出来数千⾏还带有循环的指令,实在是让移动平台的 GPU 难以应对。因此我们开启了⼤规模的 Shader 整理和简化⼯作。整个优化流程进⾏了很多轮,时⾄今⽇,我们仍然还在持续为 Shader 进⾏移动端的优化。但是在初期⼀两次核⼼整理之后,FPS 就有了⼤幅提升。
主要的优化⽅向有,去掉复杂的很多次循环迭代的某些算法(如阴影,环境⾼光等),改⽤适合移动端的轻量级算法。另外光栅化数据的结构整理也很有必要。去掉各种不必要的 feature 的分⽀。因为我们已经熟悉了⾃⼰项⽬的需求,因此不必保留这些 Shader ⾥⾯可能的分⽀流程。最后,由于 HDRP 原本并不是为移动平台设计的,因此会存在⼤量的动态索引设计。动态索引确实在设计的灵活性上⾮常⽅便,但是这会使得 buffer 的访问速度,甚⾄⼤量中间变量的计算速度变得很慢。因此去除主⽅向光、阴影等等渲染输⼊数据的 List 结构,使其变成可以通过静态偏移的⽅式去访问。使得 Shader 代码从⾏数、寄存器访问速度,甚⾄ CPU 数据填充⽅⾯都有很⼤的性能提升。
在移动端开发的过程中,我们也深刻地认识到——移动平台的优化是需要持续进行的,即使到了项目开发的中后期,也应该对移动端性能的保持关注和维护。过程虽然会有困难和卡点,但是优化过后的效果总能让移动端的表现更上一层楼。
PC 端的资源⽣产⼯作流和移动端是怎么平衡和配合的?
我们是以 PC 为基础⽣产模型资源的,在技术给定的规格框架内,保证基本效果的情况下向移动端过渡。这个过渡包括模型的⾯数、贴图材质的处理、LOD 的处理和衔接,以及技术 Shader 上的调整。两者之间有共⽤和继承关系,也有完全独⽴的部分。⽐如 PC 的最后⼀级 LOD 是移动端的第⼀级。当然,移动端因为兼顾性能和效果问题,我们也会对⼀些模型进⾏单独制作和调整。这个调整也是在 PC 资产的基础上去想办法,这样才能保证 PC 和移动端的效果统⼀。
游戏场景及规模都很⼤,资源和渲染管理⽅⾯做了哪些特殊的设计吗?
仙剑世界的地图⾯积⾼达 384 平⽅公⾥,涵盖多样化的地形地貌、⼈⽂景观和精怪⽣态。其中所涉及的资源种类和数量⾮常庞⼤,我们在寻找开发效率、包体⼤⼩、更新效率、性能优化和游戏品质之间的平衡点时,遇到了极⼤的挑战。通过项⽬前期的不断打磨和调整,我们最终探索出了⼀整套的涵盖资源制作、场景编辑等上下游的规范、流程和⼯具链。
⾸先是为不同平台制定不同的美术资源标准,确定每个平台的资源制作规格、命名规范和品质标杆。
其次我们将场景物件按“花草树⽊⼭⽯湖河器物”等进⾏细分,为每个类别制定专⻔的场景摆放规则。通过资源代理机制,地编只需制作⼀份场景,我们可以针对不同平台进⾏细节控制,在不影响功能性和品质的前提下适配平台特性。
*《仙剑世界》场景地编
在打磨和调整过程中,我们逐步完善了⼯具链,以标准、⾃动、可视、⾼效为原则,助⼒各个⽣产环节,提供效率,保障品质。
再次,我们引⼊了 Unity 新⼀代资源构建管线 SBP,其灵活、可定制、⾼效的特性,使我们可以从容管理数⼗万且还在不断增⻓的资产,随⼼控制打包粒度,缩减 CICD 的时⻓。
最后,我们通过对 Unity 引擎的深度定制化,让游戏可以承载更丰富的细节,容纳更多的玩法,体现更⾼的画⾯品质。在渲染⽅⾯,我们除了在近景使⽤了 HIS 系统进⾏⼤规模合批(在 Unite ⼤会详细分享过这个技 术,它主要针对材质相同,mesh 相同,但是数量⾮常庞⼤的组件式的 model 类型),还利⽤ Unity 的 Batch Renderer Group 来针对 mesh、材质重叠度不⾼,数量不⼤,但是种类很多的静态⾮组件式物件进⾏合批操作。这样我们近景对象的 DrawCall 问题就得到了很好的解决。

*通过 HIS 进⾏场景管理,同样的场景 FPS 可以达到 230 以上,性能增加了 15 倍
未来的上线计划能和我们透露吗?
在前段时间结束的多端付费删档测试中,⼀些 HDRP 在各个⼿机型号上的适配效果也得到了初步验证。虽然⽬前还没达到最佳理想的状态,但是从团队优化效果的轨迹来看,对于 HDRP 移动端的移植还是保持着乐观的预期。
同时,⽆论是 PC 端还是移动端平台,我们都希望游戏给玩家带来更好的感受。最近也是再度开启了⼩范围的共研服测试,针对画⾯、玩法、体验等不同层⾯进⾏优化和迭代。例如针对我们核⼼“万物有灵”的玩法,新增多御灵助战、注灵探索、御灵仙术、御灵派遣等丰富内容;针对“五灵⽣克”战⽃机制,优化战⽃效果与玩法策略;针对游戏基础体验,优化UI表现和战⽃⼿感等等。后续将会有更好的效果表现呈现给⼤家,也可以期待⼀下。

*《仙剑世界》御剑⻜⾏效果展⽰

以下为凡影网络 U3D 引擎开发工程师何姝姝,在 Unite 上的分享《<仙剑世界>: HDRP 管线下的超大世界游戏与跨平台优化》实录。

大家好,我叫何姝姝,来自上海凡影满天星工作室,我们最近开发了一款名叫《仙剑世界》的开放世界游戏,很高兴今天有机会跟大家分享我们在《仙剑世界》这款游戏中所遇到的技术方面的经验和数据。
立项的时候,我们计划制作一款大世界游戏,它可以上天入地、自由飞翔,它有什么特点呢?它非常的大,是一个开放性地图,地图直径有 24 公里,总规模达到 384 平方公里,全场景自由探索,并且完全没有 loading 条。我们支持 PC、iOS 和安卓,可能还会有其他平台后续的支持计划。在 PC 上,我们要求很高的质量,移动平台我们要求非常流畅。可以先看一下这个视频,这是我们游戏测试时的宣传视频,大家可以通过这个视频大致了解一下这个项目。
我们项目早期是 URP 管线,优点是简洁、灵活、代码总量小、便于维护,控制它的成本比较小,但这也是它的缺点,它实在太简单了,缺少大项目需要的很多 feature。当时我们有两个选择,一个是自己造轮子,进度和计划不是很允许。另外是寻找各种 feature 的 package,把它们整合到一起,但是整合成本也很高,可能会有很多 bug。总的来说,我们当时的诉求是快速、好看、灵活、效果丰富和稳定。
我们当时比较重视曾经使用了/或者还在使用的效果 feature,包括 SSS、Tile/Cluster 的精确光系统、volume级别的环境效果、管线管理,SSAO,基于物理的光照单位(lux、lumen等),物理的光照、大气,更加完善的 PBR 着色,基于探针的环境 GI、SSGI 等全局光照体系,PCF 和 PCSS 的阴影体系,后处理中比较方便的如 DOF、运动模糊等效果体系,以及 TAA、DLSS 等抗噪体系,更完善的 ColorGrading 和 Tonemaping 等画面风格化处理,最后是极度便捷好用的 RenderingDebug 系统。
我这里给大家直接在游戏内截的图,比较真实的反馈了 SSS 带来的皮肤效果。与选人或者抽卡等这种影棚灯光效果不同,大世界游戏场景的灯光会相对比较简单,这样更能给大家带来直观的 SSS 效果体验。我们这里看到,即使是从月光照射下,甚至在阴影下,SSS 都给角色皮肤带来了较为清透的质感效果。
SSAO 也是游戏中比较重要的效果,左下图是 SSAO 贴图,左上是关闭了 SSAO 的效果,右下是开启 SSAO 的效果。开启 SSAO 之后,屋檐下的遮蔽更加明显,建筑和画面也因此变得更加立体和扎实。

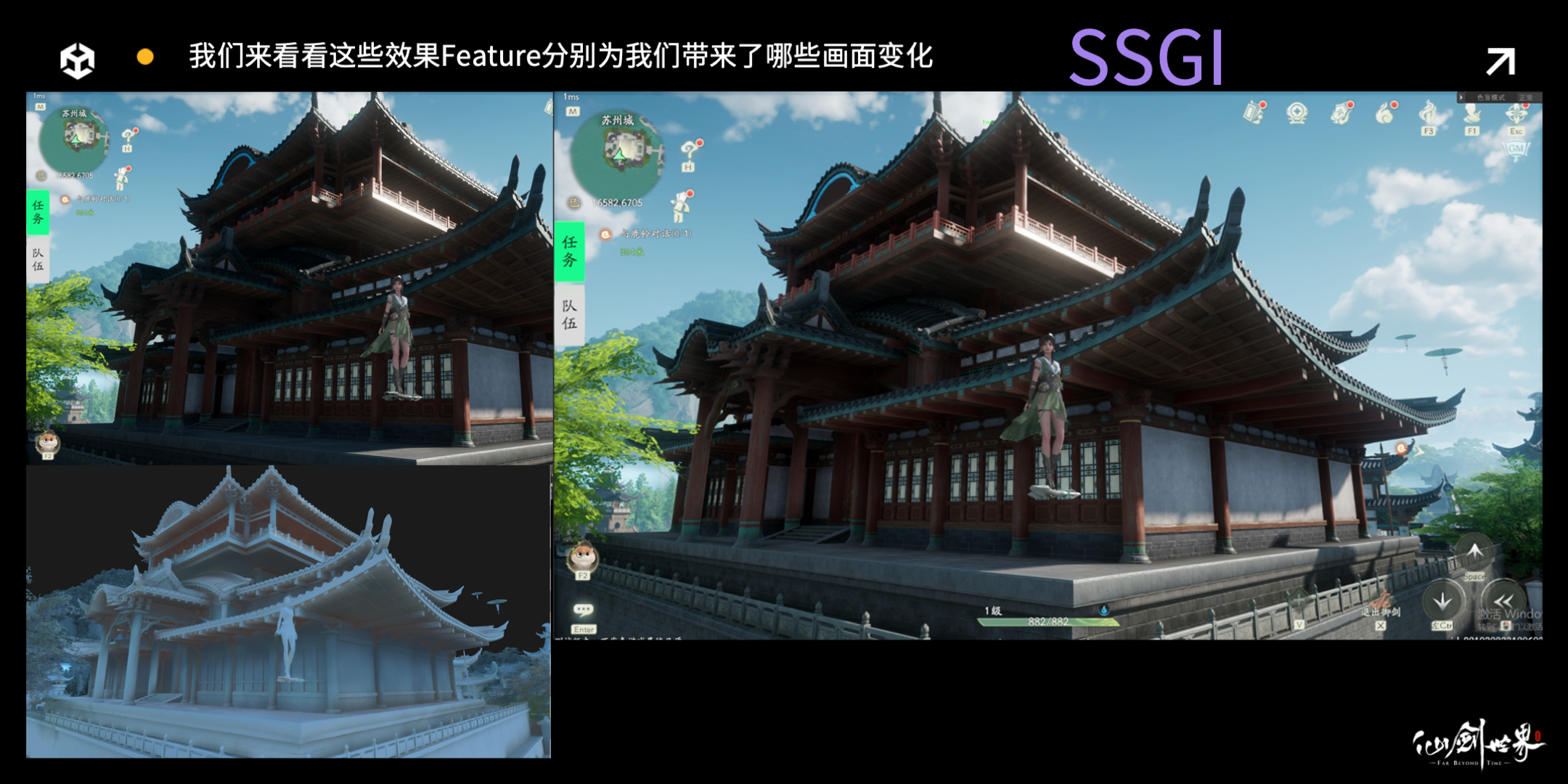
在后面这组画面中,建筑基本位于阴影之下,SSGI 没有开启之前,屋檐内部光照缺乏层次细节,黑糊糊一团,使用了 SSGI 之后,不仅外部柱子因为遮蔽减少,亮度提升,夹缝中的屋檐也因为反弹光被照亮了,并且屋檐下每个横梁、每个面都受到了不同 GI 的效果,画面也丰富了很多。
得益于 HDRP 便捷的 Volume 系统,我们可以方便快捷地实现日月变化和动态天气效果。
PCSS 也是 HDRP 的一个特色 feature,它可以为我们实现比较高质量的软阴影效果,大家可以看到树叶打到柱子、树叶、地面,墙壁上的阴影呈现不同程度的 soft 效果,比较柔和自然。

这里我还想给大家重点推荐一下 DLSS,关闭 DLSS 时画面的竹叶噪点很多,也比较闪烁,开启 DLSS 的那一刹那,画面得到了非常大的提升,没有噪点,更加稳定,甚至树叶形态都更加清晰了。DLSS 确实是非常重要的提升效果的 feature。
接入HDRP之后遇到的问题
我们后来接入 HDRP 之后遇到了一些问题,首当其冲的就是 Shader。HDRP 的 Shader 是基于 Uber 方式进行管理的,它提供了非常多便捷的 feature 支持,HDRP 开发者将众多大型游戏中或者其他工业渲染中可能会运用到的各种功能浓缩到一套 Uber Shader 下,这样做的好处非常明显,它可以在早期开发时期以很低廉的学习成本,直接运用和控制这些 feature。比如所有的 Lit shader 可以轻易切换成更适合自己的游戏算法。中后期,Uber 为我们带来了很多问题,比如它的代码量实在太大了,所以阅读起来非常耗时。其次它的编译太慢了,初期可能改一个底层的 Lightloop 文件需要编译 20 分钟时间,简直难以让人忍受。最后,代码或者 keyword 和分支过多之后,整个 shader 所占用的总内存就会变得很庞大,达到数百 M 以上。

这三点每一点都很痛。好在后面我们都摸索出了一些解决方案。
首先,我们仍然是建议在 HDRP 下,尽可能使用 Uber 的方式进行 shader 管理。HDRP 的 feature 过多,渲染代码量非常大,且分支过多,因此一定要注意维持 shader 以及 keyword 的数量,keyword 的新增是申请制,去掉一切不会使用到的 feature。采用静态 keyword 去替代掉动态 keyword。
第二,减少 if 分支的使用。去掉不用的 if 分支。HDRP 因为分支过多,会导致编译器无法合并,位于不同分支内的相同运算过程,这将使代码复杂度、运算量大大增加。
第三,尽量严格统一底层,使用相同的 Lit 和 LightLoop 等底层光照文件,便于后期统一优化,因为我们一定需要优化。效果没有确定下来之前,建议使用 Shader Graph 来探索渲染效果,建议花费一些时间修改 Shader Graph的 package 中源码,增加其 Shader Graph 转成 Code Shader 后的代码可读性和维护性,否则转出来的代码太长了,实在没有什么可读性,优化起来也不是很方便。
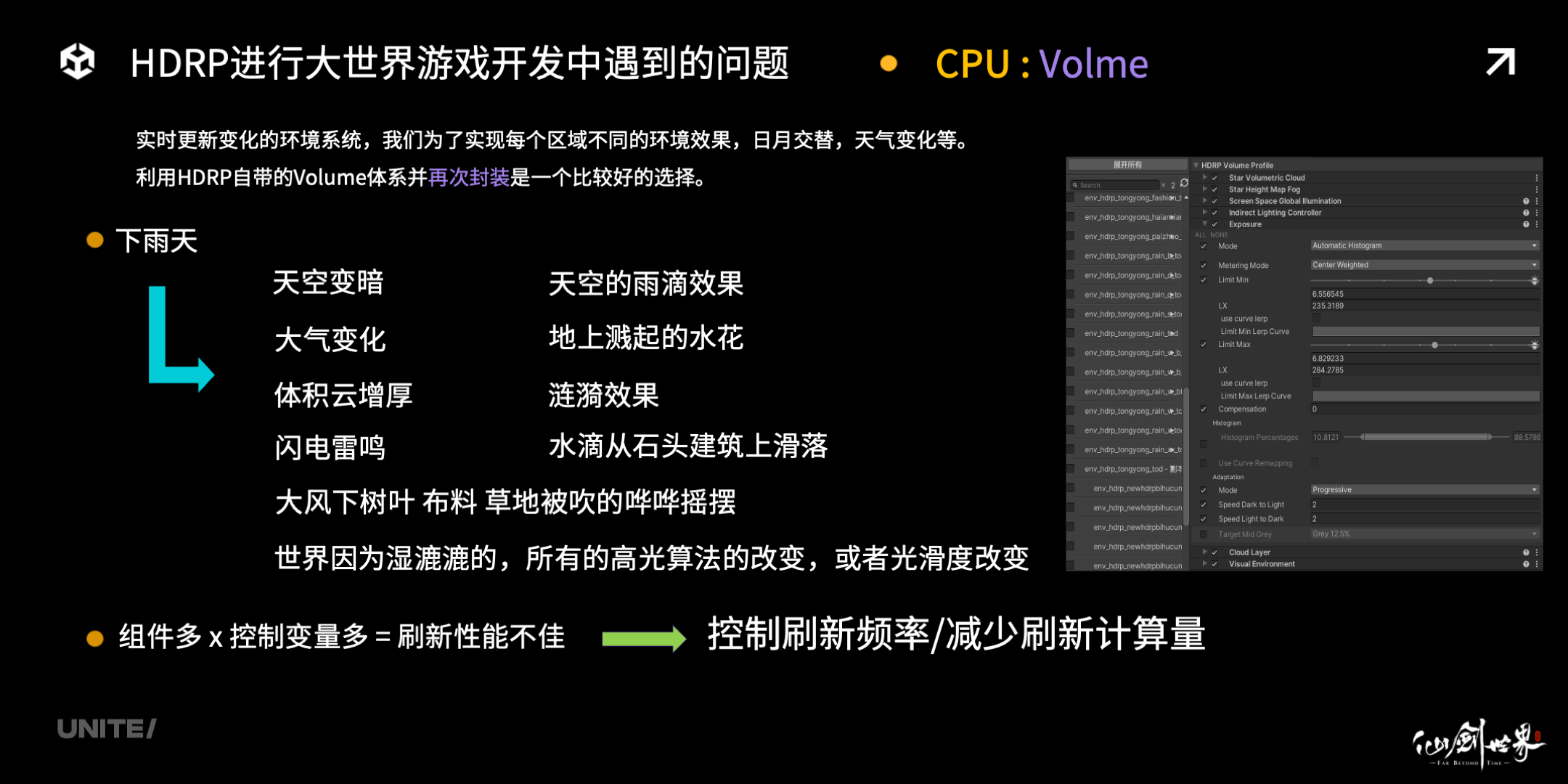
第二个问题是 Volume 的更新,因为有实时日月天气的变化,依赖 Volume 以后,可以很轻松实现。从右图可以看到,一个环境配置可能包括有数十个不同的组件,包括 Unity 自带的组件和我们自己实现的功能等,但是每个组件又带有数十个变量,会造成刷新性能不好的结果。因此,我们的优化方向是需要严格控制刷新频率,比如没有变化的时候不刷新、不需要刷新的变量也不刷新,这部分的优化是必不可少的大家可以根据自己的项目情况进行极限压缩,主要是为了减少刷新的计算量。
控制好 Volume 体系开销之后,我们发现 Render Graph 管线开销也很大。首先 HDRP 管线,我来给大家梳理一下它的大体工作流程:
他们大部分都需 new RendererListDesc() 函数,这就需要引擎层为这些所有的 pass,执行 SRP Batcher 工作。Unity 引擎底层会将这些通过了 Filter 裁剪器之后的 Renderer,pack 成 RenderNode,然后把他们分发到多个 Job 线程,去整合他们的材质,变量,区分每一个变量是否是 Global 的,如果是,还要把变量从 Global 区域 copy 出来,填充形成自己这个 Drawcall 的 cbuffer。另外还有每个需要裁剪的 Camera,还需要对所有 RenderNode 进行裁剪,还有各种 Probe 的裁剪,Bound 计算等等。管线的工作成本是非常高的。而且这个高,是会随着相机数量成倍数增长。即使开了 Job,并且在多线程中完成这些计算,但是当场景中的渲染对象多到一定程度之后,我们发现 RenderGraph 在 PC 上的成本都是很高的,更何况并行能力更差的移动平台。有时候其开销能达到 10ms 以上,基本上很难接受。

因此我们的优化策略是一定要控制住 Camera 的数量,绝不额外增加 Camera。剩下的相机,一定增加多种相机类型,以便于精确控制除了主相机之外的相机的渲染流程。例如:UICamera AvatarCamera 等等特殊相机类型。
如果要动态改变环境,当发生变化的时候,每个模块都需要刷新,这个时候就需要对每个相机的每个管线,进行量身定制,以减少除了主相机之外的所有次要管线内非必要计算:
例如:UpdateEnvironment()(他们包括了 SkyBox 更新,Convolution mipmap 的计算,GI 的球谐刷新等等),我们只需要计算和渲染主相机那一次,其他情况尽可能复用。另外,昂贵的 PostProcess 体系最好只有主相机有,其他相机只保留必要的 feature 即可,能去掉的尽量去掉。最后,GlobalBuffer 会在多条管线中填充多次,很多时候是可以复用的,尽量减轻管线的负担,尽量减少非必要填充。
跨过了 RenderGraph 之后,我们遇到了一个新的问题,那就是 Batch。首先,我们已经定制修改渲染管线了,CPU 压力就解决了吗?但是别忘了,我们是一个大世界游戏。
这里我给大家补充一些信息。
第一个,HDRP 和 URP 同属于 SRP 管线,其底层都是具有 SRP Batcher 功能的。本来 SRP Batcher 是一个优化游戏性能的东西,为什么到这里,就变成一个性能瓶颈了呢?因为大世界的 Renderer 数量太多了,能达到 30W 个以上,其 CPU 管理成本非常非常高,所以 Batch 成本也是很高。

所以我们开发了一套 HIS 系统。场景的 Renderer 太多,动态计算即使使用 Job 也很难承担 SRP Batch 和底层渲染的 CPU 压力。那么我们采取的方案是:脱离 Renderer 对象管理 (Renderer 仅用于烘焙场景) —— 这样做减少了绝大部分原本 SRP Batch 的压力。
BVH Tree 场景静态烘焙加速场景管理,它可以预先烘焙记录材质、变量等信息,直接从烘焙结果中得到 Batch 结构,不再需要动态计算。适合大量的,相同材质 Shader 的场景组件,可以一次性使用 Draw Instanced 绘制成百上千的对象。彻底解决 SRP Batcher 合批之后,仍然会有多个 Drawcall Set 的问题。得益于这个系统,我们可以发现,大量相同的场景组件,其 Drawcall 以及其他渲染状态切换均只有一次。GPU 压力也因此得到降低。
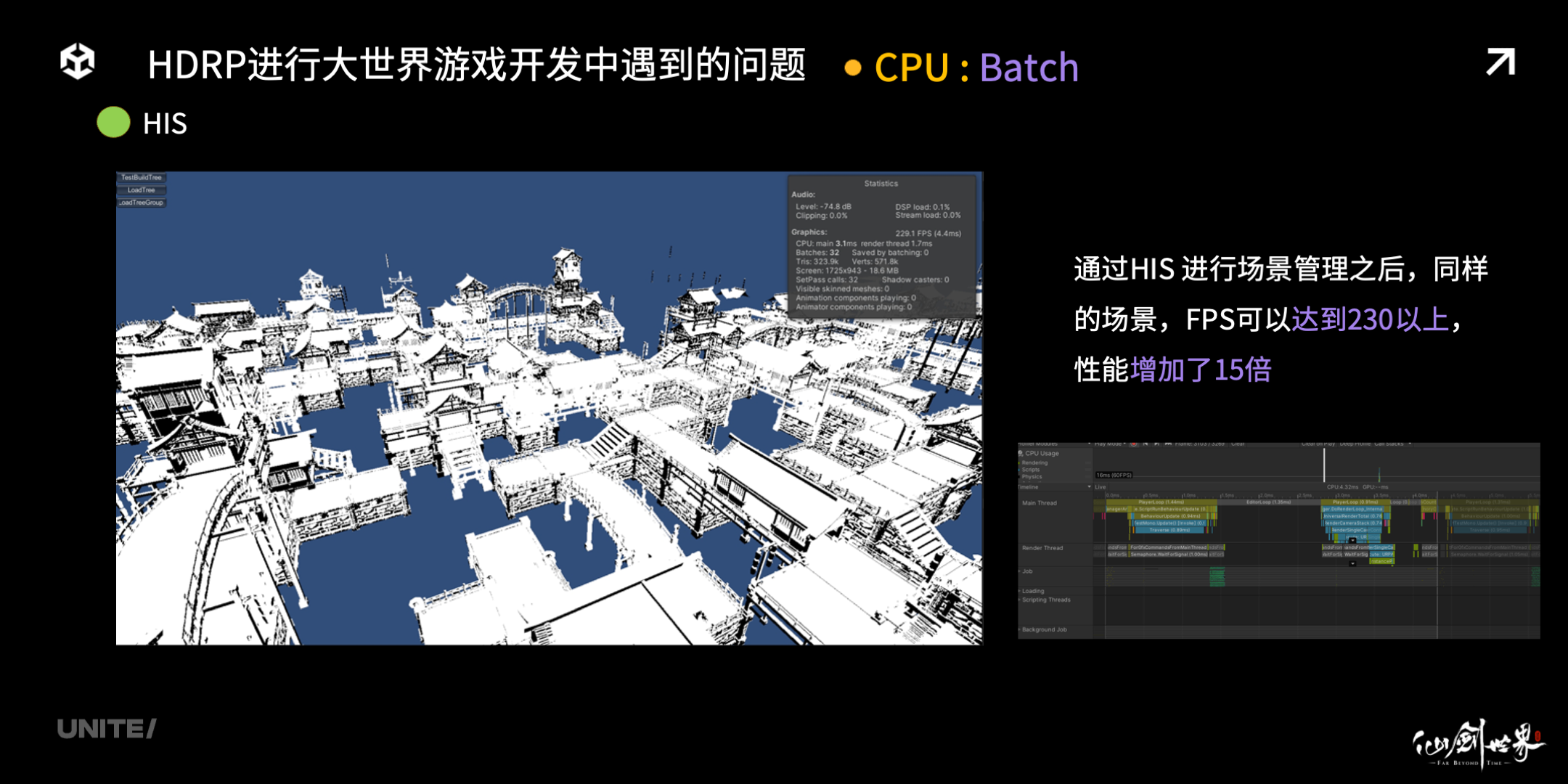
我们可以看到右边图片,HIS 合并之后,场景中的大量物体都进行了 Instancing 合批绘制,非常高效,最高的有 1200 多次。

这是 BVH Tree 的烘焙结果,这个动画展示了 4 层的 BVH Tree 的烘焙结果。当我们想要定位摄像机内有哪些渲染对象的时候,可以根据 BVH Tree 进行加速筛选定位。

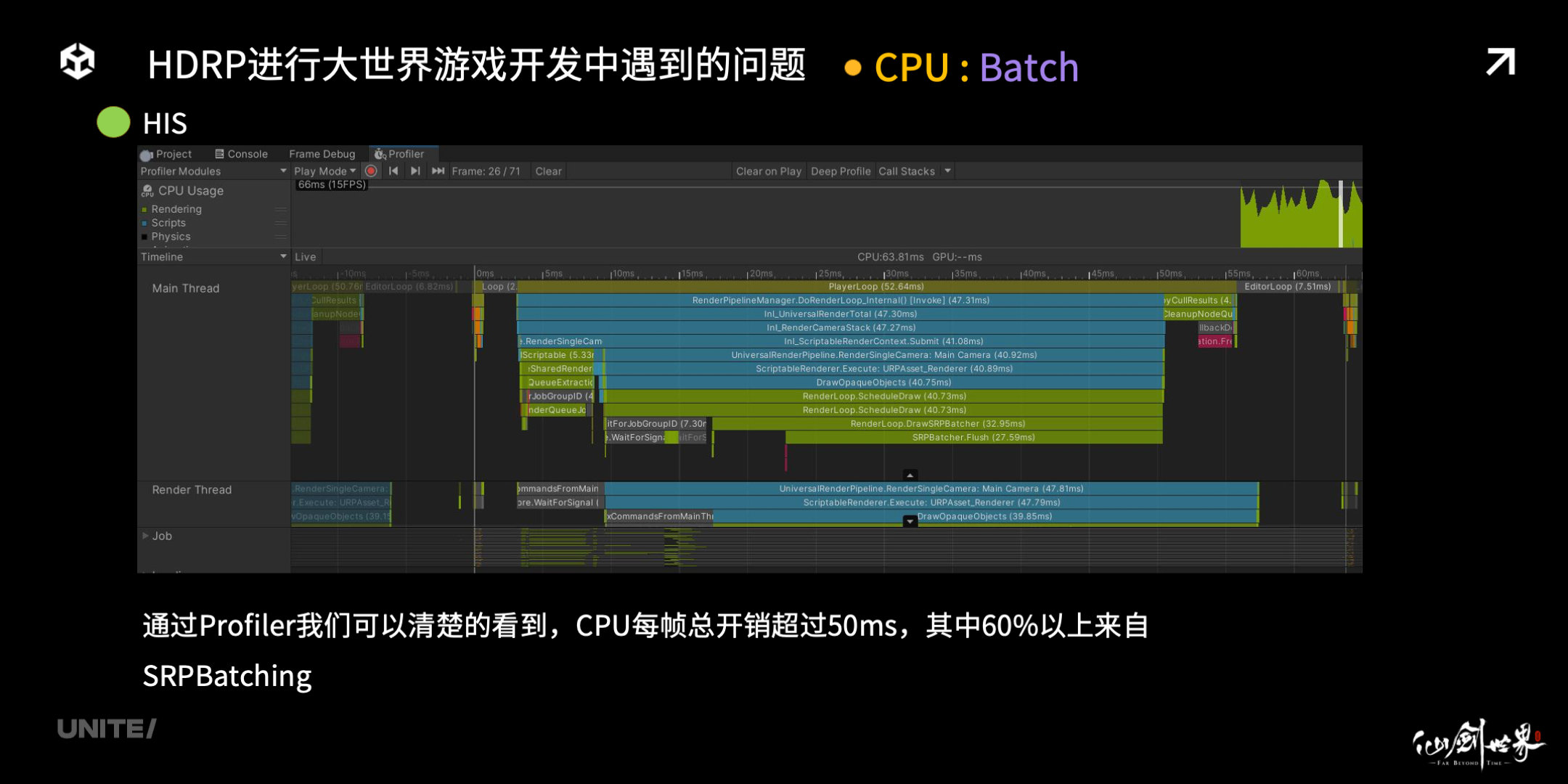
我们来看看这个 HIS 系统加入前后的性能表现差异,这是以一个 Renderer 对象超过 8W 的小型城市建筑群。大家可以通过右上角的统计面板看到,SPR Batch 之后只有 10 个左右的 set pass。但是在我的电脑 I7 的 Cpu 上,它仅仅能跑 15fps。

我们来看 Profiler,是什么消耗了 CPU 性能。通过 Unity 的 Profiler,我们可以清楚的看到,CPU 每帧总开销超过 50ms,其中 60% 以上来自 SRP Batcher 的开销。当开启了 HIS 之后,我们的 FPS 可以达到 230 以上,整体 CPU 性能增加了 15 倍。
在场景的管理解决之后,我们又发现大世界中的光照也很麻烦。左边的视频可以看到,制作人要求我们实现实时日月光照角度变化,同时又要支持不同的天气效果切换。右边的视频可以看到角色从地面飞行到三百米的高空中,如果使用 Lightmap,可能需要加载很大范围内的贴图数据,并且 PC 端还被要求实现一根柱子不同朝向的 GI 变化,因此传统的 Lightmap 很难从内存和效果上达到我们的要求。因此我们采用 PRTGI 的方式来实现实时 GI。

我们基本上参考了《对马岛之魂》在 2021 的 SIGGRAPH 上发表的这篇文章,来实现预烘焙部分。烘焙主要采用了 DX12 的光线追踪算法,来记录了以 0.5 米为单位的 LightProbe 内烘焙信息。具体做法是,烘焙时通过构建一个单位亮度为 1 的白色天空球的反弹信息 × 实时天空盒的 0 阶球谐(天光的反弹) + 模拟水平面和垂直面的反弹的实时主光的反弹球谐(主光反弹)+ 实时天空盒 SH,计算游戏的最终 GI。
我们通过这种预烘焙和实时结合的方式,获得了低成本的实时 GI 效果。由于其优秀的性能和内存表现,这套方案可以完全运行到移动平台上,它的性能开销可以控制在 2ms 内和 40m 左右。当然便捷的操作也是必不可少了。不能让我们场景美术手动去布置这些探针球,毕竟我们场景很大。因此自适应生成系统必不可少。另外特殊的地方可以进行人为修正也是支持的。

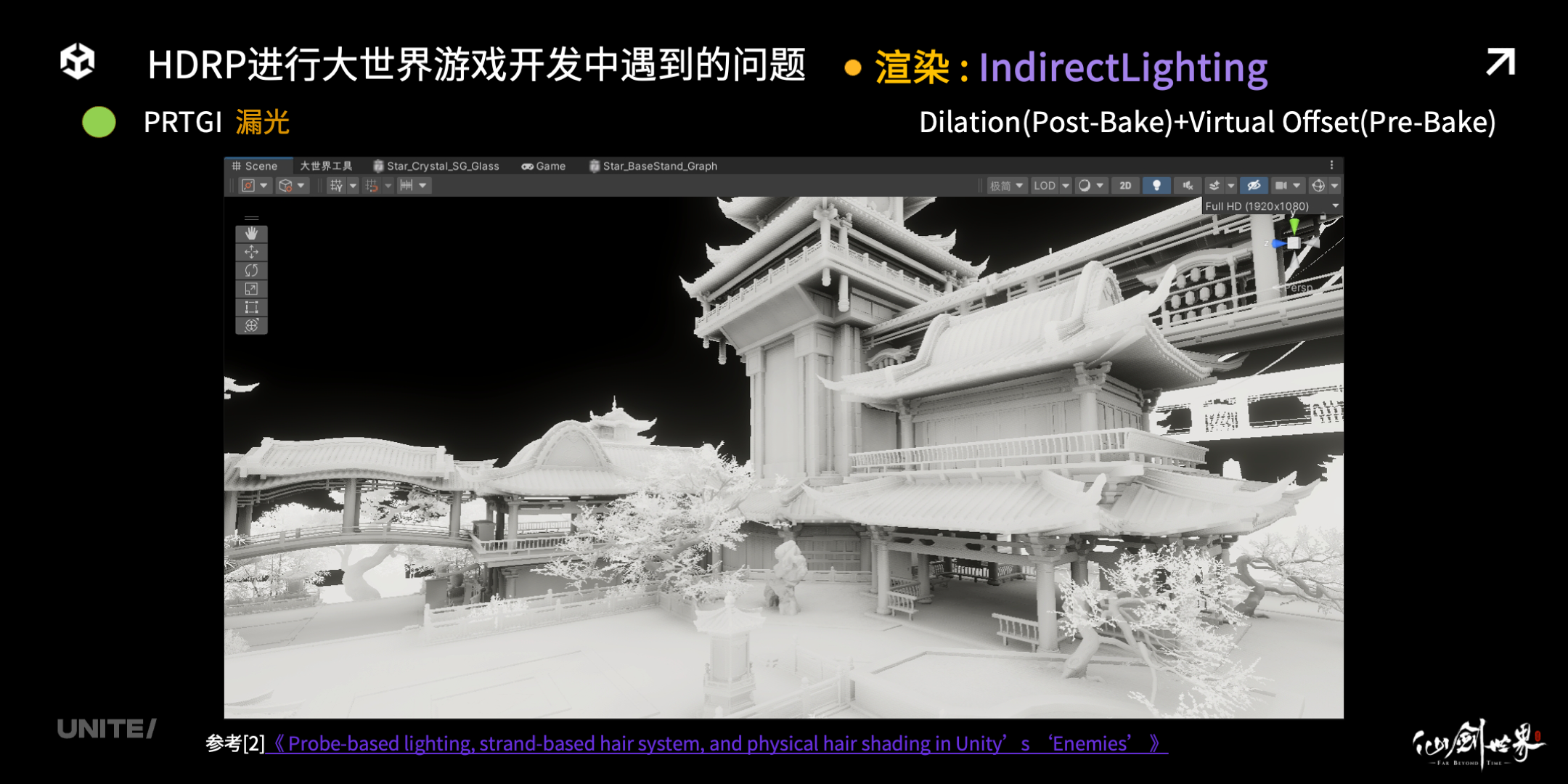
但是我们和大部分的 PRTGI 系统一样,都会遇到的类似的问题,那就是——漏光。我们可以看到,由于漏光,在墙体物件和外界交界的地方,存在大量不均匀的、不稳定的遮蔽程度,严重影响效果。

我们采用的方案是借助 Dilation(Post-Bake) 和 Virtual Offset(Pre-Bake) ,很好地控制住了漏光现象,获得了均匀可信的烘焙 GI 信息。大家可以看同一个场景,漏光解决后,是不是均匀很多?大家可以参考 Unity 在 SIGGRAPH 2022 年发布的 Enemies 论文,我在这里就不作过多的详述了。
HDRP向移动平台移植
PC 平台的一些问题我们介绍完了,下面着重给大家介绍一下移动平台。在 PC 版本逐渐稳定了之后,我们开启了对其进行移动平台的移植。这将是一个更大的挑战,因为我们都知道,HDRP 原生是不支持移动平台的,如果我们要做一致,要选择适合的项目时机,我们要预留比较长的容错时间,安排合适的项目进度。由于管线的复杂程度,可能早期 8Gen3 的手机上只有 10FP,但一定要有坚定的信心。
移植前需要做一些什么准备工作呢?
第一,HDRP 是同时支持延时和前向管线的。所以需要根据自己项目对渲染的需求,设计自己的移动平台的渲染管线,是 forward/deferred。挑选移动平台需要的 feature。
第二,由于 HDRP 整个管线体系内的 Shader 都并非面向移动平台,因此有大量 feature 是 Compute Shader,即使可以优化,也需要做好自己项目的支持的设备性能基线机型选择。因为 Compute Shader 可能对少部分低端机不友好。部分 feature HDRP 提供了 Shader 和 CS 两种版本,可以按需选择。如果要支持移动平台,建议尽量使用 shader 版本。因此要评估自己的项目对低端机下限的容忍程度。如果没有特别长的时间专门去做优化,选择 HDRP 可能不能做到面向特别低端的手机。
第三,由于是移植,多端通用的资源意味着往往并不是为移动平台设计的资源。那么需要提前预备好优化这些资源的人力和时间。根据 PC 端的面数和 Drawcall 数量,估算出多端资源的各级指标,比如角色面数上限,场景面数上限等,这些需要在制作 PC 资源的时候就要准备好,可以加快移动平台的移植进程。
接下来看一下我们早期遇到的问题,我们早期的 Drawcall 数量可能达到了一两千个,带宽开销可能是 1G 以上,巨量的三角面数有时候达到了两千万亿左右,管线和 Shader 代码对移动平台不太友好,很多机型上有崩溃现象。

优化的其中一点就是 DrawCall,我们的解决方案就是前面介绍过的 HIS 系统。游戏的场景物件,尽可能使用模块组件化设计。目的是为了极大提高 Mesh 的利用率,从而提高我们自己写的 Insancing 合批程度。另外就是 HLod 系统,HIS 系统合并掉了近处的物件,那么中远景的场景就交给了 HLod 系统。它可以将一大堆建筑合并成一个 Drawcall,也极大的减轻了管线压力,是非常值得挖掘的体系。
另外一点就是面数。我们的方案是多轮的资源优化和面数控制,最重要的还是输入数据就能控制到接近的数量级上,其次是多级的 LOD 体系,非常有助于减面。
最后我想讲一下剔除算法,第一个是 HIZ 剔除,它用 GPU Driven 的方式,利用 PreDepthPass 的深度图,生成 HIZ 的深度金字塔,将实际上被遮挡的水体、植被等进行 GPU 上的剔除处理。它的特点是是可以以非常廉价的 GPU 开销,一次性剔除掉大量的 Renderer 对象。但是如果不采用 GPU 回读的方式,由于它的剔除行为发生在 GPU 阶段,因此所有渲染数据都需要向 GPU 提交。因此 CPU 压力并没有得到释放。如果进行回读,当视角与上一帧变化稍大一些,其回读数据就会丧失可信任性,仍然是会产生 CPU 的渲染提交,以及 GPU 上最终的渲染成本。另一方面,由于它是以相同材质和 Mesh 来作为单元管理,当材质和 Mesh 的多样性非常高,实例化数量却不大的时候,CPU 的管理压力就相对会比较大。
最后,在 CPU 方面,我们采取了 Intel 的 SOC 软光栅化剔除来减少从 CPU 提交 Drawcall 的数量。CPU 剔除就没有材质类型的限制,但是它依赖遮挡体的设计和制作。因此也更适合用于城市中,墙体周围的小道具和小建筑等等的剔除。
这两个剔除算法都很重要。他们能协助我们从每一个层面,去最大可能地减少 Drawcall 的渲染数量。

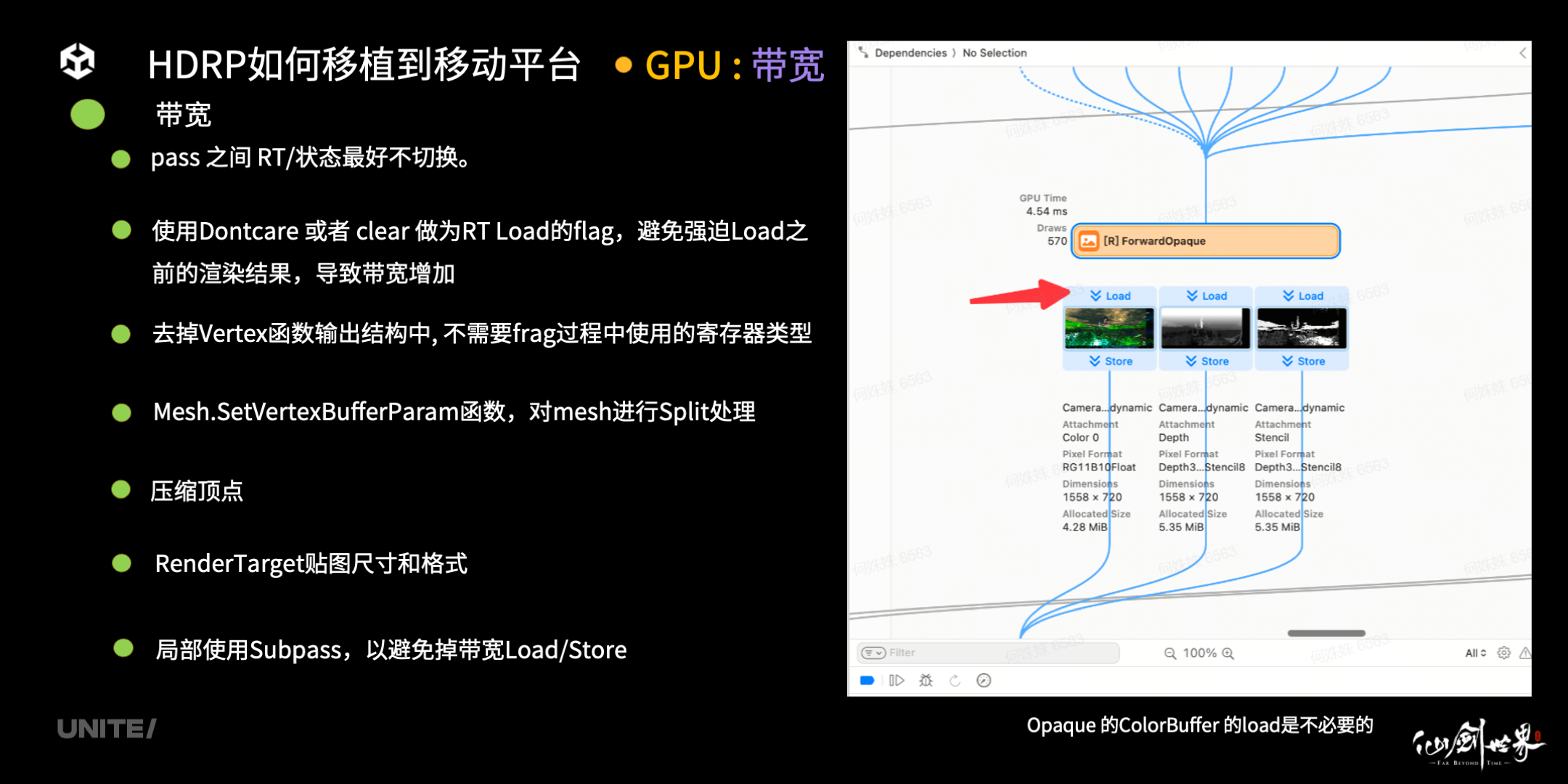
Drawcall 看完了,让我们来看看带宽。首先,重新设计管线流程,尽量去掉每个 pass 之间 RT 和状态切换的次数,最好不切换。另外,不需要读取 RT 之前信息的时候,如 ColorBuffer 在 Opaque 阶段第一个 pass 前,使用 DontCare 或者 Clear 做为 RT Load 的 Flag,避免强迫 Load 之前的渲染结果,导致带宽增加。
第三,由于 feature 的减少,HDRP 下 Shader 的 VertShader 部分的输出会出现大量冗余操作,例如去掉了 NormalBuffer 的输出,则无需读取顶点法线,更无需进入光栅化过程等。因此优化过程一定要去掉 Vertex 函数输出结构中不需要 frag 过程中使用的寄存器类型,不要有浪费的情况,应该控制住每个寄存器。容易被忽略的是使用 Unity 提供的 Mesh.SetVertexBufferParam 函数,对 Mesh 进行 Split 处理,使其在非着色 pass 中 VertexBuffer 绑定大小减少。
第四,可以尝试压缩顶点,但是可能会带来额外的顶点计算量,要权衡一下是否适合,每个项目的情况也不一样。最后,评估优化每一张管线中的 RenderTarget 贴图,选择适合移动平台的尺寸和格式。比如能用 R16,千万不要用 R36,也不要使用全分辨率等等。最后,如果带宽切换太过严重,可以考虑局部使用 Subpass,以避免掉带宽 Load/Store。
说完了管线部分,我们来看看 shader 部分。首先 Shader 里面尽可能去掉各种开关某些功能的条件分支和 for 循环。分支间的即使相同的计算,也无法获得优化。比如寄存器不能复用,可能导致多次相同计算和采样(可能还会产生大量带宽问题)建议将其降低次数后展开 for 循环,并根据项目 feature 依赖情况直接去掉不需要的分支(或者采用静态宏条件分支)。
其次 HDRP 采用了大量的动态生成的 Buffer 来进行数据填充,比如 GISh,比如主光,点光,阴影设置,等等。严格控制 RWBuffer 的数量,最大不可超过 4 个,否则会有移动平台很多设备上的兼容问题。
然后提高 Half 计算占比,是我们一个 Shader 优化的常用手段。但是Half计算之后,HDRP的光照强度很可能会溢出超过10W以上,需要进行压缩后再计算,否者我们常年可能会遇到各种溢出。
还有环境高光计算太过复杂,过多的循环和混合,导致性能非常差,由于对画面贡献较小,移动平台上替换成 URP 类似的环境高光计算即可。
最后更换阴影 PCSS 算法(循环次数过多),使用更合适的阴影算法,如 PCF、VSM 等。

让我们来看看还有哪些 Shader 中被忽略的点。索引大家都知道是什么意思,那么动态索引呢,就是 HDRP 底层比较喜欢将渲染的数据,比如方向光主光,生成 list 结构,用 for 循环的方式在 Lightloop 中进行渲染,这样,当 GPU 在执行一次渲染的时候,将两个像素分别派发给了不同的 wave,这时 GPU 就不能清楚的知道,这两个 wave 在访问方向光数据的时候,是否使用了相同索引数据,那么这样数据访问的结果就会被存储到向量寄存器 VGPR 中,而 VGPR 中的数据,是无法在多个 wave 之间进行共享的。
反之,如果这些数据被存到了标量寄存器中,GPU 多个 wave 之间将会只采样和计算一次这个光照数据,在所有 wave 间进行共享。因此这两种寄存器会给 Shader 带来非常大的性能差异结果。因此我们对 Shader 的优化方向,就需要严格控制 Shader 中 VGRP 寄存器的使用率。具体的做法是,将 HDRP 管线下 Shader 中动态索引数据,比如主光,精确光,阴影等数据,统统都抛弃了 list 的数据结构,直接定义到 Buffer 中,用固定的 offset 去访问这些 Buffer 数据。这样这些被访问的数据以及这些数据的中间计算结果,都将有可能被存储到标量寄存器中,从而实现 wave 间的共享,避免掉多次计算。
另外还有容易被忽略的 LRZ 的被关闭的条件。除了我们众所周知的 Frag中进行与深度相关的 Clip 操作。还有,比如在这些 pass 渲染输出了深度/stencil 也不行。这里提供一种解决的思路,如果我们希望 Opaque 内能 LRZ 的更高效一些,我们需要尽量将深度和 stencil 的 write,在 Opaque pass 内关闭掉。最后,不可以使用 SecondCommandBuffer ,否则在某些设备上可能也会被关闭 LRZ。

我们再来看看还有哪些注意点,使用 Vulkan,性能指标要好很多,对 ComputeShader 支持也更好,机型兼容性更强。使用多线程渲染和 Rendering Batches Jobs ,可以参照右边的截图。另外,移动平台下,对于 CPU 和 GPU 都会访问的 ComputeBuffer,比如 CPU 内填充 setdata 数据,GPU 也会访问读取这些数据。这种情况,new ComputeBuffer 的时候,尽量去指定使用 ComputeBufferMode 的 Dynamic/SubUpdates 类型,以避免因为申请成默认的Immutable类型Buffer,而产生每帧大量的CopyBuffer成本。因为 Imm 类型的 Buffer 只允许 GPU 进行读写,但是我们又要 setdata,因此渲染底层会帮我们在每帧的最开始,将这个我们会 setdata 的 buffer,通过 copyBuffer 出一个新的 dynamic buffer,给 CPU 使用和填充。这样会产生每帧大量的 CopyBuffer 成本。具体写法可以参考右边的图片。
最后,有源码条件的同学,也可以尝试更改一下渲染 Job 的同步点类型,不同的项目可能适合的同步点不一样,有助于更好的实现线程之间,或者 CPU/GPU 之间的并行。

现在我们来说说移动平台的光照解决方案。得益于 PRTGI 烘焙,可以让实时计算的复杂度减少。这是 shader 优化后效果。我们可以看到房屋下面的 AO 遮蔽和 GI 效果也比较明显。

让我们来继续看一下移动平台的点光方案。因为我们是一个多端通用资源的项目。从维护的便捷性方面考虑,移动平台仍然使用 HDRP 的 Cluster 点光管理方案,但是,我们限制了最大同一个 Cluster 内支持 4-8 盏点光,同屏最大支持达到 80 个以上点光
精确光循环的计算内容,代码完全被展开,以更好地进行寄存器共享,并利用 SIMD 计算,一次性计算多盏点光的光强衰减和 diffuse 和 GGX 高光计算。可将点光所有的代码量控制到 150 行 DXBC 指令左右。
我们可以看到左边是移动平台的副本点光效果,右边是 PC 平台的点光效果。除了资源有所不同,其光照效果基本一致。

HDRP下各种Debug工具
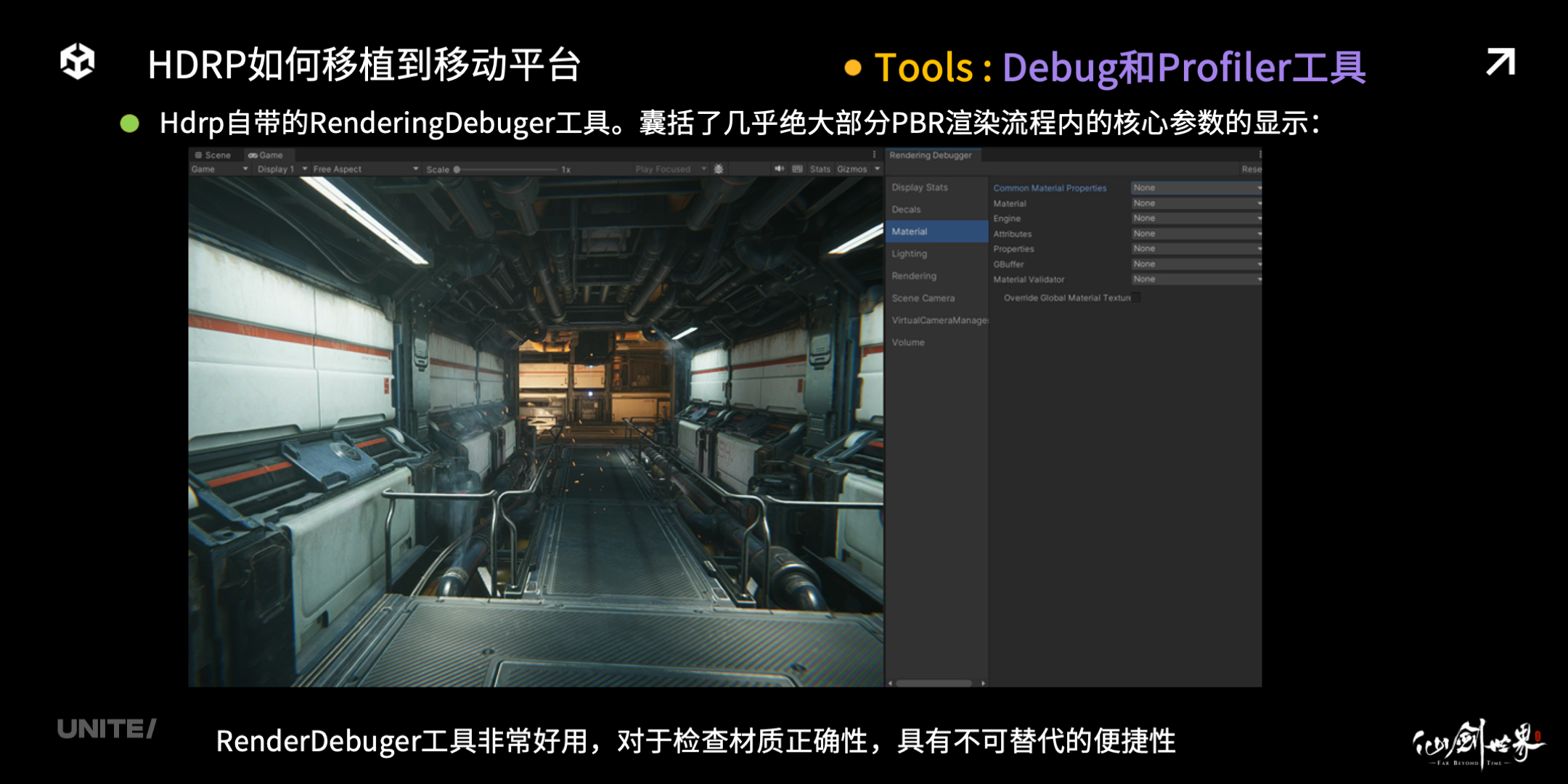
最后的最后,我想聊一下 HDRP 平台上的各种 Debug 工具。首先 HDRP 自带的 RenderingDebuger 工具非常好用,它囊括了几乎绝大部分 PBR 渲染流程内的核心参数显示,对于检查材质正确性,它具有完全的不可替代性。
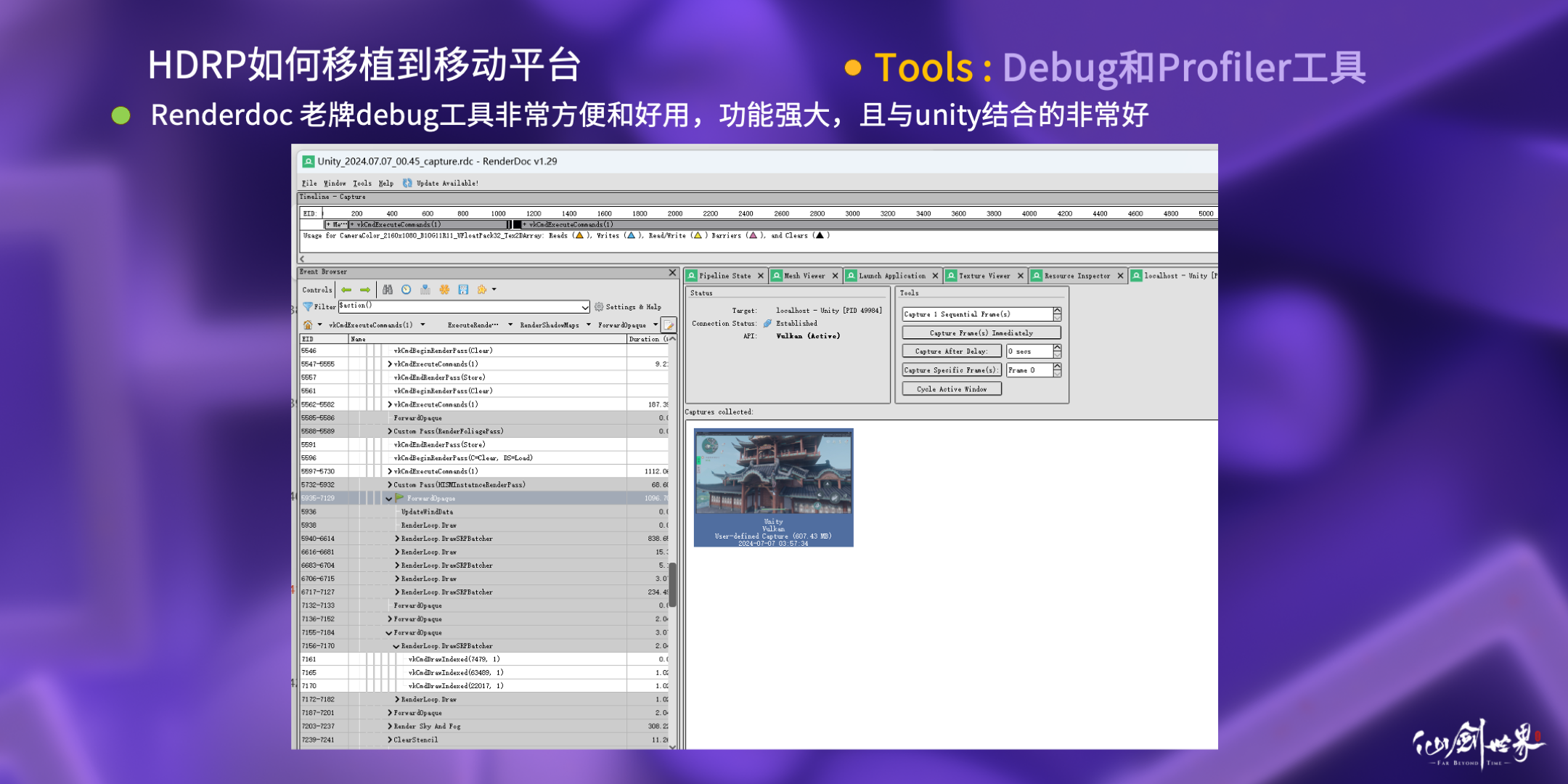
第二个是经常被使用的老牌 Debug 工具Renderdoc,它非常好用,与 Unity 也结合的非常好。
在移动平台,Xcode 的各种工具 Profiler,用于检查 IOS 真机的内存、CPU、GPU、管线带宽、Shader/CS 性能开销,CasheMissing 程度等等敏感指标,仍然是最方便的。Snapdragon Profile 用于检查安卓真机的性能开销profiler 性能数据也不错,遗憾对 vulkan 支持较弱。Arm_Mobile_Studio 用于检查 shader 性能,分析寄存器情况。SimplePerf 用于查看安卓真机 CPU 开销情况也很好用。

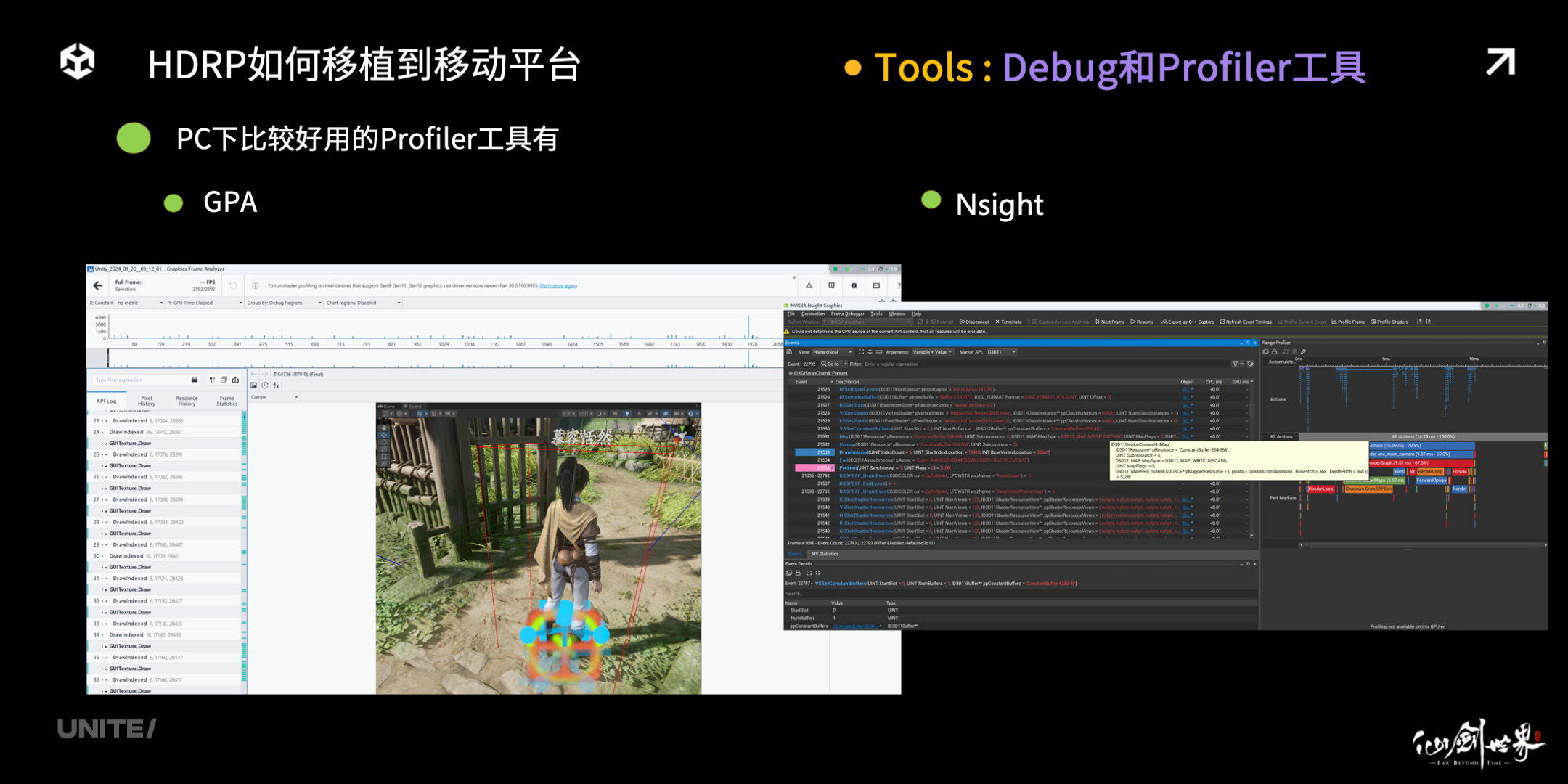
在 PC 上,我们比较喜欢使用的是 GPA 和 Nsight,特别是 N 卡用户,可以通过 Nsight,可以获得更加准确的 GPU 开销信息。
下面是刚才提到的两个算法论文选型,谢谢大家!

[1] https://advances.realtimerendering.com/s2021/jpatry_advances2021.pdf
[2] https://advances.realtimerendering.com/s2022/SIGGRAPH2022-Advances-Enemies-Ciardi%20et%20al.pdf



















