HIve数仓新零售项目
注:大家觉得博客好的话,别忘了点赞收藏呀,本人每周都会更新关于人工智能和大数据相关的内容,内容多为原创,Python Java Scala SQL 代码,CV NLP 推荐系统等,Spark Flink Kafka Hbase Hive Flume等等~写的都是纯干货,各种顶会的论文解读,一起进步。
今天继续和大家分享一下HIve数仓新零售项目
#博学谷IT学习技术支持
文章目录
- HIve数仓新零售项目
- 前言
- 一、ODS层搭建--数据导入--全量覆盖
- 二、ODS层搭建--数据导入--增量同步
- 三、ODS层搭建--数据导入--新增和更新同步
- 总结
前言

这是一个线下真实HIve数仓的一个搭建项目,还是比较复杂的,主要和大家一起分享一下整个HIve数仓的思路。
整个项目分为:
1.ODS层
2.DWD层
3.DWB层
4.DWS层
5.DM层
6.RPT层
每一层都有每一层的知识点。我会和大家分享从数据源MySQL开始,如何搭建整个完整的项目。
一、ODS层搭建–数据导入–全量覆盖
不需要分区,每次同步都是先删后写,直接覆盖。
适用于数据不会有任何新增和变化的情况。
比如区域字典表、时间、性别等维度数据,不会变更或很少会有变更,可以只保留最新值。
这里以t_district区域字典表为例,进行讲解。
DROP TABLE if exists yp_ods.t_district;
CREATE TABLE yp_ods.t_district
(
`id` string COMMENT '主键ID',
`code` string COMMENT '区域编码',
`name` string COMMENT '区域名称',
`pid` int COMMENT '父级ID',
`alias` string COMMENT '别名'
)
comment '区域字典表'
row format delimited fields terminated by '\t'
stored as orc tblproperties ('orc.compress'='ZLIB');
sqoop数据同步
因为表采用了ORC格式存储,因此使用sqoop导入数据的时候需要使用HCatalog API。
-- Sqoop导入之前可以先原表的数据进行清空
truncate table yp_ods.t_district;
方式1-使用1个maptask进行导入
sqoop import \
--connect 'jdbc:mysql://192.168.88.80:3306/yipin?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true' \
--username root \
--password 123456 \
--query "select * from t_district where \$CONDITIONS" \
--hcatalog-database yp_ods \
--hcatalog-table t_district \
--m 1
二、ODS层搭建–数据导入–增量同步
每天新增一个日期分区,同步并存储当天的新增数据。
比如登录日志表、访问日志表、交易记录表、商品评价表,订单评价表等。
这里以t_user_login登录日志表为例,进行讲解。
DROP TABLE if exists yp_ods.t_user_login;
CREATE TABLE if not exists yp_ods.t_user_login(
id string,
login_user string,
login_type string COMMENT '登录类型(登陆时使用)',
client_id string COMMENT '推送标示id(登录、第三方登录、注册、支付回调、给用户推送消息时使用)',
login_time string,
login_ip string,
logout_time string
)
COMMENT '用户登录记录表'
partitioned by (dt string)
row format delimited fields terminated by '\t'
stored as orc tblproperties ('orc.compress' = 'ZLIB');
sqoop数据同步
- 首次(全量)
1、不管什么模式,首次都是全量同步;再次循环同步的时候,可以自己通过where条件来控制同步数据的范围;
2、${TD_DATE}表示分区日期,正常来说应该是今天的前一天,因为正常情况下,都是过夜里12点,干前一天活,那么数据的分区字段应该属于前一天。
3、这里为了演示,${TD_DATE}先写死。
sqoop import "-Dorg.apache.sqoop.splitter.allow_text_splitter=true" \
--connect 'jdbc:mysql://192.168.88.80:3306/yipin?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true' \
--username root \
--password 123456 \
--query "select *,'2022-11-18' as dt from t_user_login where \$CONDITIONS" \
--hcatalog-database yp_ods \
--hcatalog-table t_user_login \
--m 1
- 循环(增量同步)
#!/bin/bash
date -s '2022-11-20' #模拟导入增量19号的数据
#你认为现在是2022-11-20,昨天是2022-11-19
TD_DATE=`date -d '1 days ago' "+%Y-%m-%d"`
/usr/bin/sqoop import "-Dorg.apache.sqoop.splitter.allow_text_splitter=true" \
--connect 'jdbc:mysql://192.168.88.80:3306/yipin?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true' \
--username root \
--password 123456 \
--query "select *, '${TD_DATE}' as dt from t_user_login where 1=1 and (login_time between '${TD_DATE} 00:00:00' and
'${TD_DATE} 23:59:59') and \$CONDITIONS" \
--hcatalog-database yp_ods \
--hcatalog-table t_user_login \
-m 1
三、ODS层搭建–数据导入–新增和更新同步
每天新增一个日期分区,同步并存储当天的新增和更新数据。
适用于既有新增又有更新的数据,比如用户表、订单表、商品表等。
这里以t_store店铺表为例,进行讲解。
drop table if exists yp_ods.t_store;
CREATE TABLE yp_ods.t_store
(
`id` string COMMENT '主键',
`user_id` string,
`store_avatar` string COMMENT '店铺头像',
`address_info` string COMMENT '店铺详细地址',
`name` string COMMENT '店铺名称',
`store_phone` string COMMENT '联系电话',
`province_id` INT COMMENT '店铺所在省份ID',
`city_id` INT COMMENT '店铺所在城市ID',
`area_id` INT COMMENT '店铺所在县ID',
`mb_title_img` string COMMENT '手机店铺 页头背景图',
`store_description` string COMMENT '店铺描述',
`notice` string COMMENT '店铺公告',
`is_pay_bond` TINYINT COMMENT '是否有交过保证金 1:是0:否',
`trade_area_id` string COMMENT '归属商圈ID',
`delivery_method` TINYINT COMMENT '配送方式 1 :自提 ;3 :自提加配送均可; 2 : 商家配送',
`origin_price` DECIMAL,
`free_price` DECIMAL,
`store_type` INT COMMENT '店铺类型 22天街网店 23实体店 24直营店铺 33会员专区店',
`store_label` string COMMENT '店铺logo',
`search_key` string COMMENT '店铺搜索关键字',
`end_time` string COMMENT '营业结束时间',
`start_time` string COMMENT '营业开始时间',
`operating_status` TINYINT COMMENT '营业状态 0 :未营业 ;1 :正在营业',
`create_user` string,
`create_time` string,
`update_user` string,
`update_time` string,
`is_valid` TINYINT COMMENT '0关闭,1开启,3店铺申请中',
`state` string COMMENT '可使用的支付类型:MONEY金钱支付;CASHCOUPON现金券支付',
`idCard` string COMMENT '身份证',
`deposit_amount` DECIMAL(11,2) COMMENT '商圈认购费用总额',
`delivery_config_id` string COMMENT '配送配置表关联ID',
`aip_user_id` string COMMENT '通联支付标识ID',
`search_name` string COMMENT '模糊搜索名称字段:名称_+真实名称',
`automatic_order` TINYINT COMMENT '是否开启自动接单功能 1:是 0 :否',
`is_primary` TINYINT COMMENT '是否是总店 1: 是 2: 不是',
`parent_store_id` string COMMENT '父级店铺的id,只有当is_primary类型为2时有效'
)
comment '店铺表'
partitioned by (dt string)
row format delimited fields terminated by '\t'
stored as orc tblproperties ('orc.compress'='ZLIB');
sqoop数据同步
实现新增及更新同步的关键是,表中有两个跟时间相关的字段:
create_time 创建时间 一旦生成 不再修改
update_time 更新时间 数据变化时间修改
自己通过where条件来控制同步数据的范围。
- 首次
sqoop import "-Dorg.apache.sqoop.splitter.allow_text_splitter=true" \
--connect 'jdbc:mysql://192.168.88.80:3306/yipin?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true' \
--username root \
--password 123456 \
--query "select *,'2022-11-18' as dt from t_store where 1=1 and \$CONDITIONS" \
--hcatalog-database yp_ods \
--hcatalog-table t_store \
-m 1
- 循环
#!/bin/bash
date -s '2022-11-20'
TD_DATE=`date -d '1 days ago' "+%Y-%m-%d"`
/usr/bin/sqoop import "-Dorg.apache.sqoop.splitter.allow_text_splitter=true" \
--connect 'jdbc:mysql://192.168.88.80:3306/yipin?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true' \
--username root \
--password 123456 \
--query "select *, '${TD_DATE}' as dt from t_store where 1=1 and ((create_time between '${TD_DATE} 00:00:00' and '${TD_DATE} 23:59:59') or (update_time between '${TD_DATE} 00:00:00' and '${TD_DATE} 23:59:59')) and \$CONDITIONS" \
--hcatalog-database yp_ods \
--hcatalog-table t_store \
-m 1
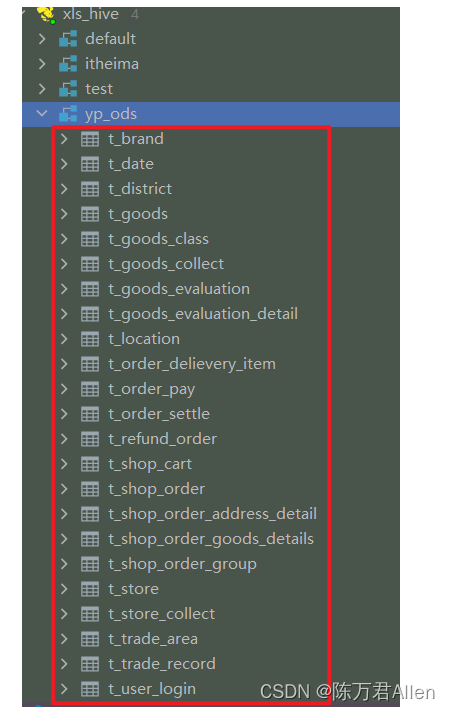
最终所有从MySql导入的的ODS层表格
总结
这里介绍了HIve数仓新零售项目ODS层的构建,主要三种方式.
- 全量覆盖
- 增量同步
- 新增和更新同步



![[附源码]SSM计算机毕业设计-东湖社区志愿者管理平台JAVA](https://img-blog.csdnimg.cn/20cd90f1b0cb406282fa3a84455e951d.png)





![[附源码]java毕业设计网络身份认证技术及方法](https://img-blog.csdnimg.cn/a14b55f6372d43f2b1172f8863b5ba1f.png)