1、端到端的发展驱动力
1.1 对标驱动:特斯拉FSD的标杆作用吸引行业关注
大部分行业专家表示,特斯拉FSD v12的优秀表现,是端到端自动驾驶这一技术路线快速形成大范围共识的最重要的推动力;而在此之前,从来没有一个自动驾驶产品可以让从业者和用户如此便捷地感受到技术带来的体验提升。
由第三方网站FSDTracker统计的特斯拉车辆接管里程数据也表明了FSD v12的巨大性能提升。在此前很长一段时间,FSD的版本迭代处于瓶颈期,自2022年初FSD v10更新以来,其接管里程数据保持在稳态波动,行业普遍认为这是传统架构的工程优化陷入瓶颈的表现;但FSD v12更新后,较之此前版本,用户完全无接管的行程次数占比从47%提升到了72%,平均接管里程(Miles Per Intervention,MPI)从116英里提高到了333英里,性能的大幅提升代表着端到端技术突破了原有的技术瓶颈,推动自动驾驶系统的能力再上台阶。
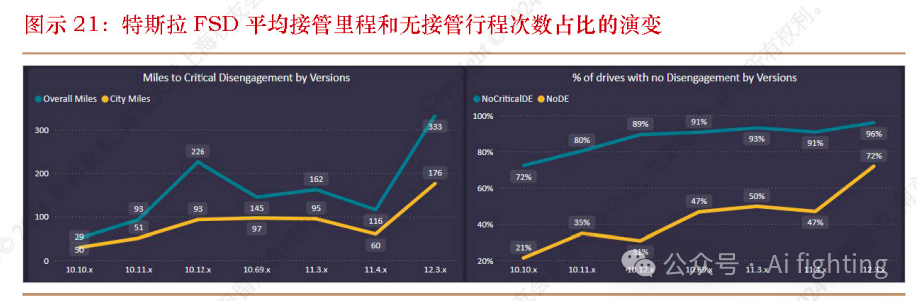
作为自动驾驶行业最重要的标杆企业之一,特斯拉的技术路线一直备受关切。从Elon Musk在2023年5月首次公开提出“特斯拉FSD v12是一个端到端AI”,到2024年3月特斯拉开始大范围推送v12,特斯拉端到端技术不断演进和成熟的过程,也是中国自动驾驶行业逐渐凝聚共识的过程。很多业内专家表示,公司下决心投入端到端自动驾驶,与特斯拉的进展密不可分。
1.2 用户体验驱动:端到端解决长尾场景的安全性和动态博弈的拟人化程度
第一是提升了系统的安全性。自动驾驶的很多长尾场景是“只可意会,不可言传”的,意即对于人类驾驶来说可以靠直觉“搞定”,但很难用规则化的语言来表述,这类问题是传统技术路径依赖的专家系统很难解决的。某自动驾驶芯片公司AI负责人提到,诸如“道路上一滩正在起火的油”与“道路上的积水”、“正面飘来的空塑料袋”和“前车落下的钢筋”这类需要常识推理的场景,以及“不同地区的不同红绿灯外观和路口等待规则”这类需要复杂环境理解能力的场景,要么很难用规则准确描述,要么其开发工程量太大(因为专家无法总结所有规律)。这类场景对于端到端系统来说,可以被训练为隐式的中间表示,从实践上表现出很强的应对能力。
第二是驾驶风格的拟人化。当前的自动驾驶功能在车道保持、定速巡航这类简单场景下的表现已经和人类司机相当,但是在拥堵跟车、加塞响应、变道超车等需要博弈的场景,其驾驶风格通常与乘客的预期不一致。究其原因,是因为基于规则的决策规划系统需要海量的工程优化才能报合出人类的高动态驾驶策略。相比之下,端到端系统能够表现得更像人类司机,这有利于自动驾驶系统与用户建立信任。
1.3 组织价值驱动:简化研发流程,优化组织效率
目前,大多数自动驾驶公司在量产落地阶段都会面临大量的研发人员投入的挑战。传统技术架构下,要实现高阶驾驶功能的交付,头部公司基本都需要投入近千人或上千人的资源。而多位专家认为,端到端会简化自动驾驶的研发流程,因而有很大概率可以降低自动驾驶研发的人力成本。
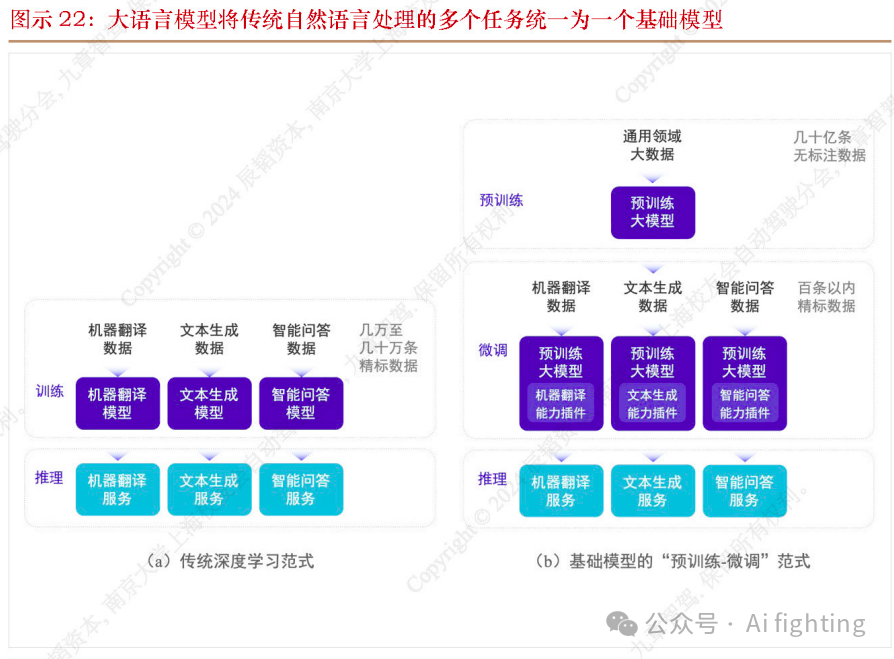
端到端对研发流程体系的简化可以体现在两个方面:第一是功能系统层面,端到端意味着原来以横向控制和纵向控制为基础、从底盘执行单元推演而来的自动驾驶功能体系可以被彻底革新。将浩如烟海的“Use Case定义和分析”的工作转向“场景提取”和“数据挖掘”方向。类比ChatGPT的出现将原来细分的NLP任务统一,端到端自动驾驶也可能意味着自动驾驶任务的统一。
第二是算法层面,传统的感知-融合-预测-决策-规划架构可能涉及到十几个子系统和更多的软件模块,而端到端则可以将与之相关的子系统缩减为一个。子系统简化意味着研发团队的分工简化,并可以大大减少部门墙对组织效率的影响。
许多专家都表示,很多时候,自动驾驶测试中遇到的问题,很难准确界定属于感知部门还是决策规划部门,也许无论哪个子系统的优化都可以解决这个问题,因而,在实际工作中这两个部门的接口也最容易遇到责权不清的问题,这就间接地增加了系统工程、各个算法方向上的人力投入。而端到端的核心技术原理是全局统一优化,这同时也意味着组织目标的统一对齐。
除了功能、系统、算法团队的简化外,端到端对公司组织架构的影响还体现在AIInfra的重要性将持续提升。由于核心算法的开发范式全部更选为数据驱动的开发范式,数据处理(包括数据来集、场景挖掘和定义、合成数据等)以及训练平台基础设施将会变得越来越重要,自动驾驶公司的组织架构可能演变为AI算法+AIInfra的双核心。
1.4 技术驱动:端到端是实现自动驾驶AGI新范式的基础
以ChatGPT为代表的生成式AI大模型彻底颠覆了传统的自然语言处理,而Elon Musk表态“特斯拉即将迎来ChatGPT时刻”和对外公开端到端的时间都在ChatGPT推出半年后,因此业界普遍猜测,ChatGPT的出现是影响特斯拉投入端到端路线的重要驱动因素。
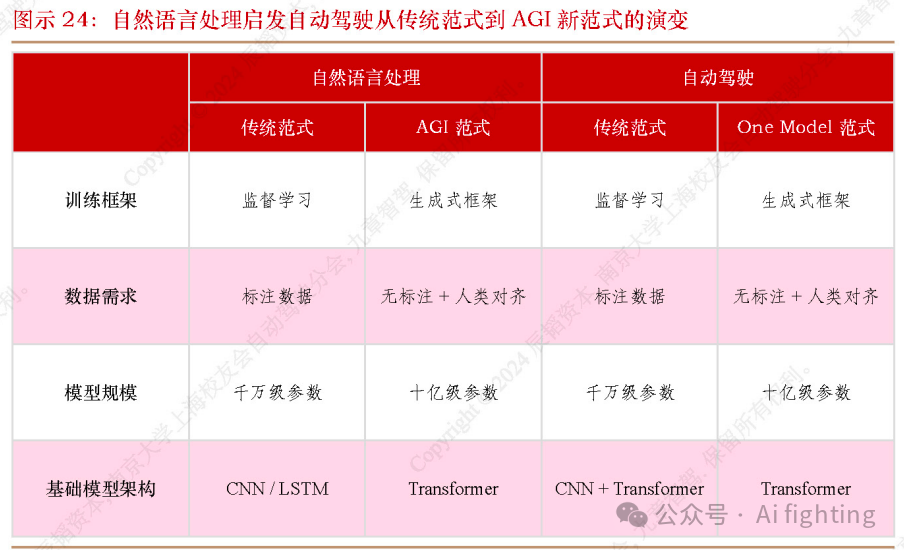
虽然GPT、Sora等很难直接用于自动驾驶任务,但其代表的AGI(Artificial General Intelligence,通用人工智能)新范式的思路同样可以应用于自动驾驶。根据鉴智机器人联合创始人、CTO都大龙博士等专家的观点,AGI新范式对自动驾驶的启发包含以下几点:a. 生成式的训练框架,特点是自回归、模型可与环境交互,减少了数据标注的巨额成本。
b. Transformer 作为基础模型结构的强大能力。
c. 通过增加模型规模和数据量提升模型性能(Scaling Law)。
2、端到端落地面临的挑战及分析
2.1 技术路线分歧
虽然在理论上,每种技术路线都有其优劣势,但其最终对用户体验的价值如何、工程开发代价如何等关键问题,在当前环境下没有共识。造成当前技术路线分歧的原因,除了行业还处于发展早期以外,最关键的原因是:行业内尚未出现可供参考的最佳实践案例。
特斯拉在2021年和2022年举办的两场AI Day基本确定了BEV和Occupancy Network的网络结构的标准,而其端到端的网络结构至今为止还没有对外披露。开源社区的标志性成果UniAD尽管提供了一个公开的技术架构,但UniAD尚未真正经过量产交付的验证,特别是与其配套的模型验证和评测方案、数据采集和处理方式还没有明确,目前,UniAD也无法作为确定的终局技术架构。
2.2 对训练数据的需求量空前提升
端到端自动驾驶是数据驱动的模型,因此,训练数据的重要性前所未有地提升。端到端数据的挑战可以分为数据量、数据标注、数据质量和数据分布四个方面。
首先是训练端到端所需的数据量。特斯拉在多个场合中提到,其FSD训练需要用到上千万个视频片段,假设每个视频片段时长为30~60秒,以此为参考,训练端到端模型最起码需要几万小时的视频数据。目前规模最大的公开数据集包含大约1200小时数据,这意味着,要拿到端到端研发的入场券,自动驾驶公司还必须使用更大规模的非公开数据。
第二是数据标注需求的变化。长期来看,端到端由于没有感知决策规划的中间接口,面对感知的标注需求将会转向面对规划的标注需求,对现有的包括3D检测、车道线检测、路面标识语义分割等感知模块的真值的标注需求将大大减少。但短期内,大部分公司,特别是采用“模块化端到端架构的公司,依然会对感知的中间结果做标注和监督,提高训练的效率。
第三是对数据质量的要求。一位自动驾驶工程师提到,他们在训练端到端模型时发现,原本积累的路测数据只有2%可以用。特斯拉用来训练端到端模型的几万小时自动驾驶数据,是从超过20亿英里(截至发稿)的FSD里程数据中挖掘出来的。对于端到端自动驾驶来说,其数据质量问题还叠加了更复杂的因素——对人类驾驶员能力的要求。自动驾驶系统的理想目标是像老司机一样开车,而很多驾驶员的驾驶行为并能达到“老司机”的水平,这就需要一套有效的数据管理和处理流程,仅提取老司机所驾驶的车辆在特定场景下的高质量数据,这也增加了数据获取的难度。
第四是数据分布问题。全面和多样化的数据对于端到端自动驾驶模型至关重要,但多样性很难用量化方法来掌握。数据的分布需要考虑诸多因素,例如环境因素包含各种天气和光线、道路情况。与特斯拉不同,许多公司面临的最大难题是缺乏数据采集能力。即使是车企采集的数据也往往是在受控环境中获得的,这些数据可能无法完全代表真实世界中的复杂情况。真正能够反映真实世界的复杂性的数据应该是由大量用户在无意识中采集的。更有挑战的问题是,如何调整长尾场景(Corner Case)在训练数据中的分布比例,目前行业还没有一套行之有效的方法论,有专家认为,在解决数据分布的问题上,行业在模型化决策规划方面的探索会有很大价值。
合成数据可以解决上述部分问题。合成数据可以低成本增加训练数据的规模、泛化场景增加多样性、低成本生成长尾场景。自前,很多企业已经开始通过混合使用合成数据和真实数据来提高系统性能。
2.3 对训练算力的需求越来越高
随着自动驾驶系统的AI模型化程度越来越高,其对训练算力资源的需求越来越大。尽管大部分公司表示100张大算力GPU可以支持一次端到端模型的训练。
但这并不意味着端到端进入量产阶段只需要这一数量级的训练资源。量产研发阶段更需要考虑团队分工和模型迭代效率问题,企业所拥有的训练算力越大,完成端到端模型训练的时间就越短,越能抢占市场先机。另外,当企业拥有更大训练算力时,更有可能研发出性能更强(大多数时候意味着云端模型的参数量更大)的自动驾驶端到端模型,也会提升部署在车端的模型的能力。
特斯拉近年来不断增加训练算力投入,2023年底已经跻身英伟达H100首批客户之列。在2024Q1财报电话会上,特斯拉表示,公司已经有35000张H100 GPU,并计划在2024年内增加到85000张H100以上,达到和谷歌、亚马逊同一梯队。此前,特斯拉还部署了规模更大的A100 GPU训练集群,其实际训练算力投入在自动驾驶行业中遥遥领先。
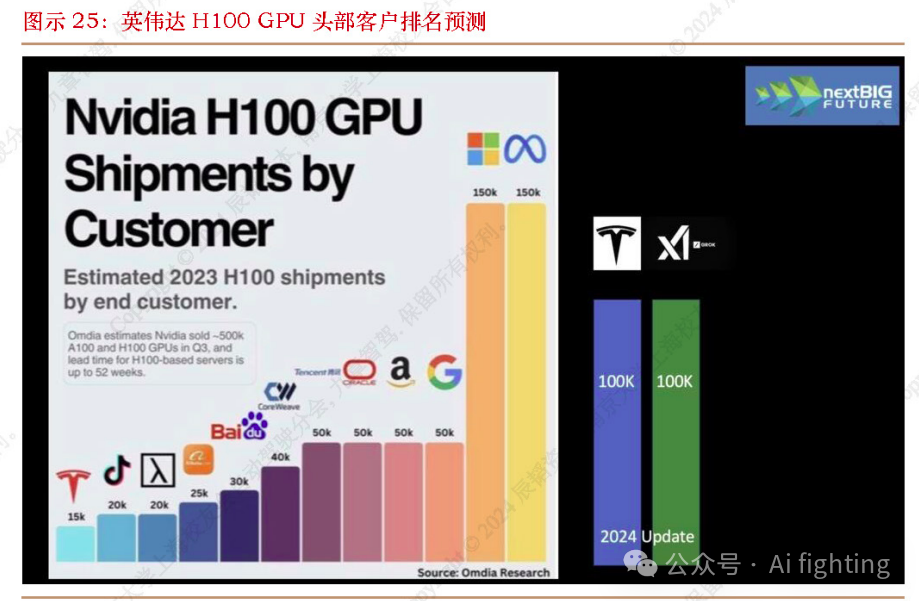
国内主机厂和自动驾驶公司的训练算力很少能达到特斯拉的规模。小鹏是在训练算力建设方面比较领先的公司,其于2023年8月宣布建成了“扶摇”自动驾驶智算中心,算力可达600 PFLOPS(以英伟达A100 GPU的FP32算力推算,约等于3万张A100 GPU)。商汤大装置已经布局全国一体化的智算网络,拥有4.5万块GPU,总体算力规模达12000 PFLOPS,2024年底将达到18000 PFLOPS。大部分研发端到端自动驾驶的公司目前的训练算力规模在千卡级别,随着端到端逐渐走向大模型,训练算力将显得捉襟见肘。
2.4 测试验证方法尚不成熟
实车测试验证的成本高昂,针对经典的自动驾驶架构,行业已经有一套行之有效的方案进行模型上车前的测试验证,即感知算法使用回灌数据进行离线开环测试,规控算法基于模拟器进行闭环测试验证。然而,以上方法无法满足端到端自动驾驶的测试验证需求。一方面,在基于数据回灌的闭环测试条件下,端到端系统无法与环境交互,系统一旦出现偏离采集路径的操作,后续系统的响应将无法评估。例如,商汤绝影智驾副总裁石建萍表示,公司之前基于闭环测试验证后的模型,部署在实车上后差异很大,可见,离线数据开环验证的结果基本无法等效于实车的表现。另一方面,基于模拟器可以实现模型的闭环测试验证,但现有的模拟器在传感器一致性和保真度上离真实世界尚有较大差距。
2.5 组织资源投入的挑战
端到端将带来自动驾驶团队的组织重塑。大部分All in端到端的公司都在削减原有团队规模,将团队重心调整到AI大模型和数据基建方向。参考特斯拉从FSD V11到V12经历的“性能爬坡”,端到端模型上车后,其早期性能可能不会强于极致优化的经典技术方案,这也对管理层进行技术路线转型的决心提出考验。
同时,削减团队规模不意味着总体投入的减少,一方面,端到端转型会导致现有智驾团队的人员规模减少,另一方面,端到端对数据、数据基础设施的投入增加。对部分公司管理层来说,扩张团队的决策是容易的,但对数据、工具链等“看不见、摸不着”的资源的投入更需要认知模式的切换。
2.6 车载芯片算力会不会成为瓶颈?
无论开发何种自动驾驶技术,算法工程师总是希望车载芯片算力越大越好。因此,当提到端到端模型部署的挑战时,“端到端需要更大算力芯片”是一个容易达成的推论。然而,与直觉不同的是,部分受访者认为,车载芯片算力限制并不是端到端落地的主要矛盾,而这样的观点也许更具有现实意义。
支持BEV+Transformer模型的部署;端到端的基础思想是整个算法处理流程的模型化,从经典架构到端到端,总的代码数量会显著降低,端到端神经网络带来的计算资源消耗相比BEV模型并不一定会有显著的提升。对更高算力的渴望更多来自于模型参数量和模型性能的提升,而不是来自于经典算法架构到端到端的转变。
另一方面,软件与芯片一直是动态演化的,与其思考“端到端模型需要多少算力”,不如考虑“基于当前的芯片,应该如何优化端到端模型以实现高效部署”。智驾芯片的性能上限依然在不断提升,几乎每3年其算力就会上一个台阶,可以支持自动驾驶公司部署性能更强大的端到端模型。同时,行业头部玩家如英伟达、华为、地平线、蔚来、Momenta都在逐渐走向软硬一体,针对自研模型定制化开发更匹配的计算芯片,可以做到最大程度的优化。
2.7 模型缺乏“可解释性”是否构成障碍?
行业中有一种观点认为,端到端系统由于没有模块间显示表达的中间结果,无法保障各个模块的确定性和安全性,这增加了错误发生的风险和调试的难度。这样的担忧对于追求安全性和确定性的L4级无人驾驶系统更加显著。
然而,大部分受访专家认为,缺乏“可解释性”并不会成为限制端到端模型应用的问题。主要原因有二:
第一,尽管端到端没有显示表达的中间结果,但是模块化端到端依然保留了各个主要功能模块,中间的特征输出可以被进一步提取为可解释的数据,帮助分析和理解模型是如何工作的。
第二,对可解释性的担忧从AI在计算机视觉领域应用以来一直存在,但与其性能较传统算法的显著提升相比,可解释性成为一个次要考量因素。目前的自动驾驶技术方案中,基于AI模型的BEV感知也存在可解释性问题,但是BEV模型由于其性能的显著性能提升,已经成为自动驾驶感知的主流技术方案。
关注我的公众号auto_driver_ai(Ai fighting), 第一时间获取更新内容。



















