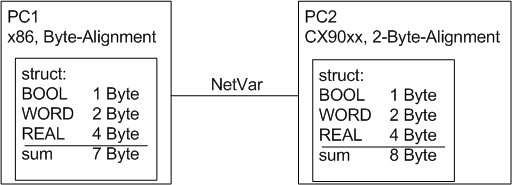
1、问题
使用pytorch进行分布式训练,一机多卡,采用 DistributedDataParallel 方式,多次执行卡在了同一个地方。但是单卡和 DataParallel 方式都没有卡住的现象。
执行nvidia-smi,此时全部GPU利用率均为100%:

2、debug大法(print)
逐一print后发现,卡住的地方有个进程没有执行:

因为我用了4个进程4张卡,卡住的地方只打印了3个,于是考虑进程同步问题。
3、方案
在每轮epoch结束后添加进程同步,虽然底层原因暂不清楚,但是问题得以解决。
![]()
该方法仅提供一个解决思路,读者还需根据自身情况分析。