介绍
论文地址:https://arxiv.org/abs/2405.00355
在这篇评论文章中,我们研究了自监督、预训练Transformers与监督、预训练Transformers和传统神经网络(ConvNets)相比,在检测深度伪造方面的效果如何。
我们尤其关注在训练数据有限的情况下提高泛化能力的潜力。尽管利用Transformers架构的大规模视觉语言模型在各种任务(包括零镜头和少镜头学习)中取得了显著的成功,但在深度假体检测领域,预训练视觉Transformers(包括大规模视觉Transformers)作为特征提取器仍然是个难题。ViTs)作为特征提取器仍然存在阻力。
其中一个令人担忧的问题是,当训练或微调数据较少或不多样化时,往往需要过大的容量,而且无法获得最佳泛化效果。这与 ConvNets 形成了鲜明对比,后者已经成为一种稳健的特征提取器。此外,从头开始训练和优化转换器需要大量的计算资源,这主要局限于大公司,阻碍了学术界更广泛的研究。
变压器自监督学习(SSL)的最新进展,如 DINO 及其衍生物,已经显示出在各种视觉任务中的适应性,并具有明确的语义分割能力。使用 DINO 进行的深度假货检测显示了有限的训练数据和部分微调的实施情况,证实了对任务的适应性以及通过注意力机制对检测结果的自然解释能力。此外,对用于深度假货检测的Transformers进行部分微调提供了一种资源节约型替代方案,可显著减少计算资源。
算法框架
问题的提出
作为一个基本的二元分类问题,给定一个输入图像(I)和一个去掉了分类头的预训练骨干网(B),目标是构建一个网络(F),利用(B)将(I)分类为 "真 "或 “假”。这可以表达如下:
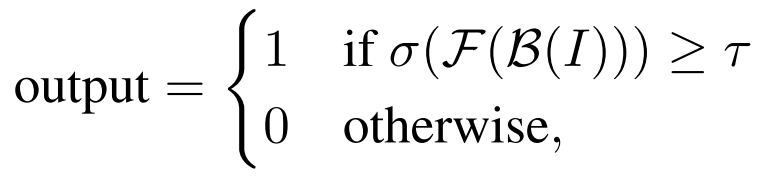
其中,σ(−) 是一个 sigmoid 函数,将 F(B(I)) 的输出映射到 [0, 1] 范围内的概率。另外,τ 是阈值。
软最大值函数可用于将 F 提取的对数转换为概率,但使用软最大值有助于从二元分类扩展到多类分类。主干 B 从预处理模块开始,由 n 块组成。为简单起见,我们将块 i 提取的中间特征 I 称为 ji。至于 τ 的值,不同论文确定其最佳值的方法可能有所不同。本文将 τ 设为 0.5 或与验证集上计算出的平均错误率 (EER) 相对应的阈值,具体取决于实验设置。

图 1:正在考虑的两种方法概览。
方法 1:使用冻结骨干网作为多级特征提取器
在这种方法中,中间特征 ji由适配器 A(可选)进一步处理,通过特征融合操作 Σ 与其他区块提取的其他中间特征融合,然后由分类器 C(一般为线性)进行分类。这种方法就是图 1 的左侧。主干 B 保持冻结。使用由 K 最终块提取的 K 最终中间特征。其形式如下
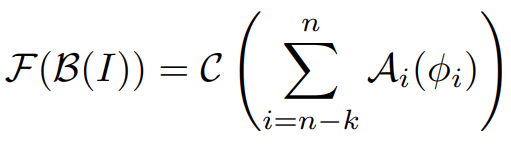
方法 2:微调最后一个变压器模块
这种方法比方法 1 更直接。如图 1(右)所示,它在主干 B 之后添加了一个新的分类器 C。其形式如下
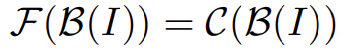
在微调过程中,前 n−k 块将被冻结。对于转换器主干,类(CLS)标记和寄存器标记(如果存在)也会解冻,并与最后解冻的 k 块一起用新分类器 C 进行微调。这种方法的两个主要优点是:a. 最后的 k 块与新分类器 C 一起被冻结和微调。
- 适配器 A 和特征融合操作 Σ 无需额外参数。避免附加参数的好处在于,现代特征提取器(尤其是Transformers)的尺寸已经足够大。
- 随着最终转换器块和标记的微调(在转换器主干的情况下),CLS 标记的注意力权重也会进行调整,以便进行深度伪造检测。这些可用于自然可视化重点区域,类似于 DINO 中使用的可视化技术。这一改进提高了检测器的可解释性,而可解释性是深度伪造检测的一个重要因素。
实验测试
数据集和评估指标
我们收集了各种深度伪造方法生成或处理的图像,并将其用于建立数据集。表 1 列出了训练集、验证集和测试集的详细信息。数据集的设计在真实图像与虚假图像的比例以及每种训练方法的图像数量上保持平衡,确保不出现重复。
在交叉数据集评估中,使用了Tantaru 等人构建的数据集,其中包含基于扩散方法生成或处理的图像。训练集用于训练或微调模型,验证集用于选择超参数。然后使用测试集进行评估和比较。
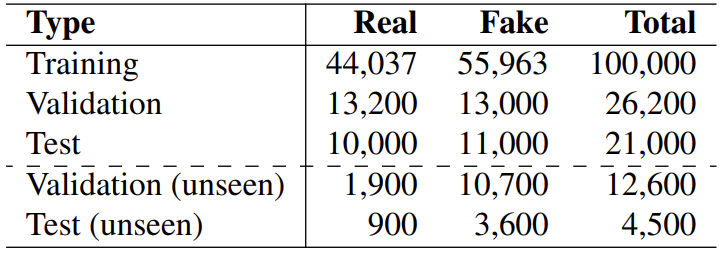
表 1.数据集摘要。
在 评估指标方面,采用了以下指标。
-
分类准确率 ɑ( text{Accuracy} = \frac{TP + TN}{TP + TN + FP + FN} \),其中 ɑ( TP \)为真阳性, ɑ( TN \)为真阴性, ɑ( FP \)为假阳性, ɑ( FN \)为假阴性。
-
真阴性率 (TNR)Ј( \text{Accuracy} = \frac{TP + TN}{TP + TN + FP + FN} \)
-
等效错误率 (EER):假阳性率 (FPR) 等于假阴性率 (FNR) 时的值
-
Half Total Error Rate (HTER) ɑ( \text{HTER} = \frac{FPR + FNR}{2} \)
方法 1 的实验结果
深层伪造检测的任务是识别伪造和不规则图案等深层伪造指纹,由于完全依赖 CLS 标记并非最佳选择,我们评估了结合补丁标记和多个中间特征以及最终区块的效果。我们还比较了加权求和(WS)和串联(concat)这两种特征融合技术的性能。此外,还对不同大小的 DINO 主干网进行了验证,结果见表 2。
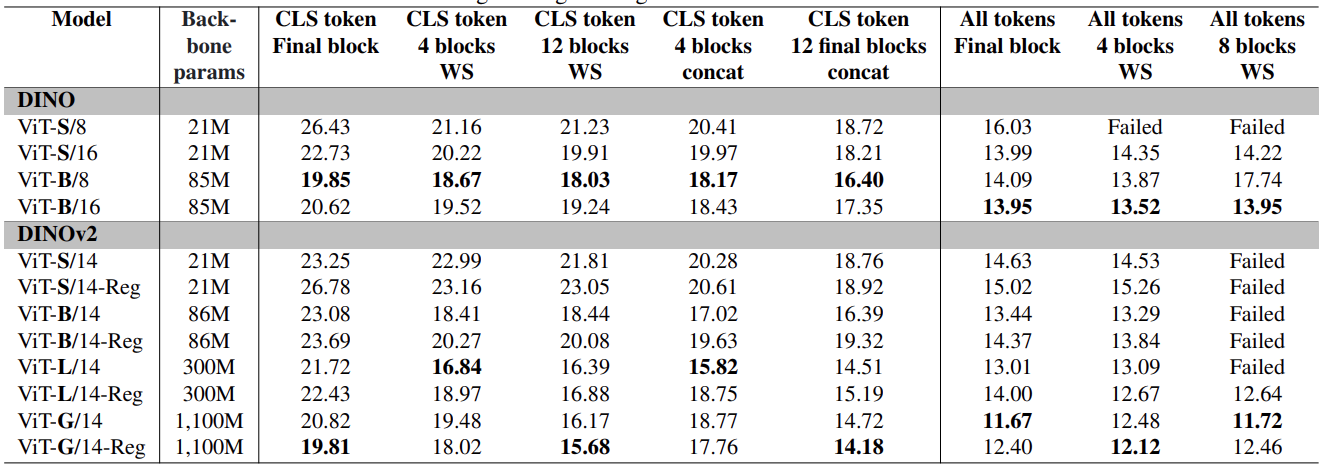
表 2:采用不同版本和结构的 DINO 作为骨干的方法 1 模型的能效比
这里适用 "越大越好 "的原则。骨干网规模越大,EER 通常越低。与完全依赖 CLS 标记相比,使用所有标记会产生更好的结果。此外,使用多个区块比使用单个区块的性能更好,不过随着 k 的增加,训练下游模块会变得更加困难。虽然 DINO 和 DINOv2 在性能上通常没有明显差异,而且在 DINO 中,使用大尺寸和小尺寸补丁也没有明显的性能差异,但特征串联比使用加权和得到的结果更好。

表 3.1.1.1.1. 以 SSL 预先训练的 DINOv2 - ViT-L/14-Reg 为骨干对方法 1 的强化
选择 DINOv2 - ViT-L/14-Reg(因为在性能和模型大小之间取得了平衡)。使用简单的线性适配器来降低特征维度和特征联系。此外,还采用了 "丢弃 "技术来减少过度学习。结果见表 3。
最佳配置使用了滤除、线性适配器和特征串联的组合。这一最佳配置被应用于 EfficientNetV2、DeiT III 和 EVA-CLIP,并将其性能与 DINOv2 进行了比较。结果如表 4 所示:DINOv2 的性能明显优于 EfficientNetV2 和 DeiT III,EVA-CLIP 的性能也不错。这些结果凸显了使用 SSL 进行预训练的优势,可以学习到适用于多种任务的良好表征。
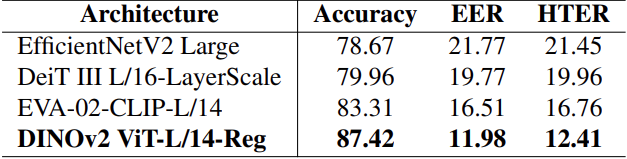
表 4.与以往研究的比较
方法 2 的实验结果
DINOv2 - ViT-L/14-Reg 被选为 DINOv2 的代表,并在方法 1 中进行了详细验证。同样,我们还选择了 EfficientNetV2、DeiT III 和 EVA-CLIP 进行比较。表 5 显示了微调最终区块(在转换器中为标记)时的性能。与方法 1 相比,所有模型的性能都有所提高,DINOv2 与其他模型的性能差距有所缩小,但 EVA-CLIP 是最接近的竞争对手。尽管如此,DINOv2 的性能仍然名列前茅:为了缩小与 DINOv2 的差距,EVA-CLIP 需要在注释丰富的大量数据集上进行预训练。与 DINOv2 相比,这是一项耗资巨大的任务,因为 DINOv2 是在一个小得多、未加注释的数据集上进行预训练的。在相同的架构下(DeiT III 和 DINOv2),就 EER 而言,性能差异接近 6%。其中一些差异可能是由不同的训练数据造成的。总之,这些结果再次凸显了使用 SSL 对 ViT 进行预训练的重要优势。
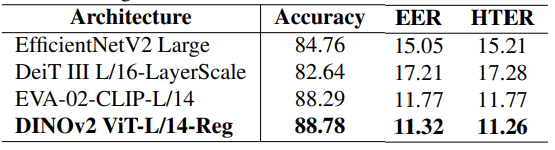
表 5.方法 2 中 ConvNet 与 Transformer 架构的比较
交叉数据集检测
在这项实验中,对检测器检测未知深度假货的泛化能力进行了评估。这种情况被认定为激烈竞争。这是因为训练集不包含漫反射图像。使用未知验证集重新校准了分类阈值。结果见表 6。值得注意的是,所有模型的性能都有所下降。表现最好的 EER 从 11.32% 下降到 27.61%。总体而言,方法 2 的性能始终优于方法 1。在方法 2 中,EfficientNetV2 比其他受监控的预训练变压器表现出更好的泛化能力;DINOv2 保持了表现最佳的地位,再次证明了在 ViT 中使用 SSL 的优势。
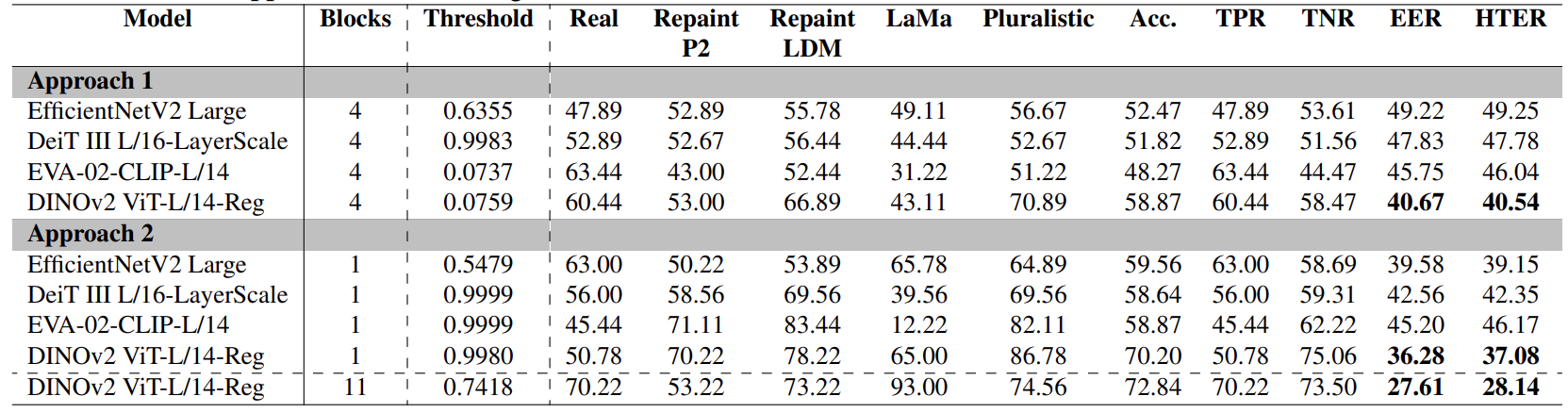
表 6:各种 ConvNet 和传感器架构在未使用的测试集上的性能比较,该测试集由使用基于扩散的方法生成或处理的图像组成
总结
在这篇评论文章中,提出了两种使用 SSL 预训练 ViT(特别是 DINO)作为特征提取器进行深度假货检测的方法。第一种方法是使用冻结的 ViT 骨干来提取多层次特征。第二种方法则涉及对最终的 k 个块进行部分微调。
通过多次实验发现,微调方法显示出卓越的性能和可解释性。本研究的结果为数字取证界在深度伪造检测中使用 SSL 预训练 ViT 作为特征提取器提供了宝贵的见解。







![[二次元]个人主页搭建](https://i-blog.csdnimg.cn/direct/773bf4bfab614a97aa077bb6ed4468c3.png#pic_center)