摘 要
在业务系统中,一般的事务型SQL语句涉及到的数据记录数不会很多,即便涉及到多个数据节点,基于AntDB-M的优化,访问也都很快。但是统计分析型SQL语句往往涉及到大量数据,甚至包括全表数据,基本都会覆盖所有相关数据节点。即便数据的读取做了很多优化,也避免不了在不同节点间传递大量数据,过多的网络交互,没有充分利用各数据节点的计算能力等问题会使分析型SQL语句执行缓慢。为此,AntDB-M提供了聚合下推功能来提升统计分析型SQL的查询性能。
一、性能初探
这里先来看一个简单的sum统计场景
部署方式:1个计算节点,2个数据节点。
通过Sysbench创建一个100万条记录的表。对开启聚合下推、关闭聚合下推、单机部署分别进行聚合查询来查看各自的查询时间。
查询语句: select sum(k) from sbtest1;
开启聚合下推
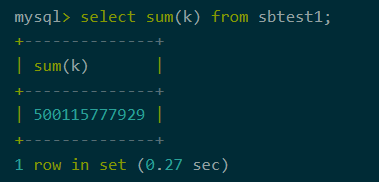
图1:开启聚合下推耗时
关闭聚合下推
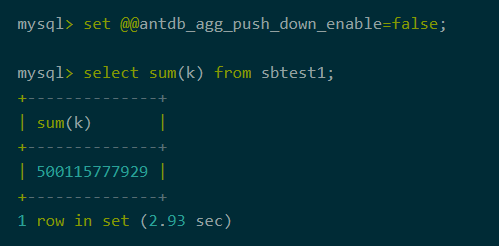
图2:关闭聚合下推耗时
单机版
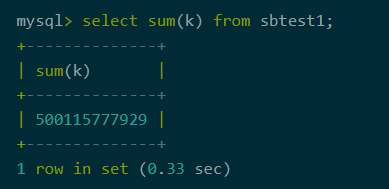
图3-单机版耗时
表1-查询耗时比对
| 单机版 | 关闭聚合下推 | 开启聚合下推 |
| 0.33 sec | 2.93 sec | 0.27 sec |
分布式部署的AntDB-M开启聚合下推是单机版的1.2倍,是不开启聚合下推的10.8倍。由此可以看出聚合下推功能对分析型SQL有着极大的性能提升。
二、功能支持
1、用户变量
在聚合下推中,支持使用用户变量。使用用户变量,业务系统可以很方便的编写灵活的SQL语句。
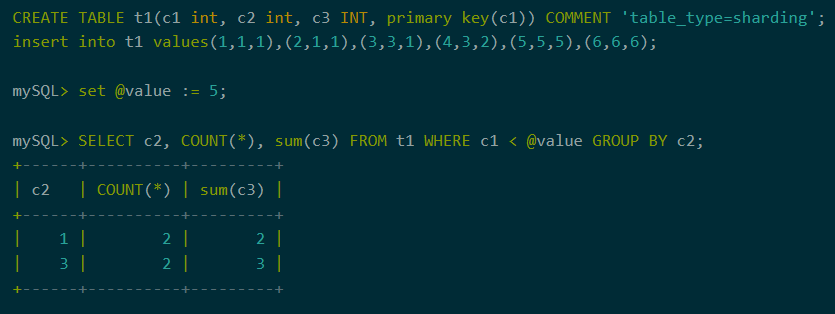
图4:用户变量
2、数字编号引用查询列
支持group by, order by从句中通过数字编号引用查询列。通过数字引用查询列,可以简化SQL的编写,使得SQL逻辑更简单清晰,也方便动态生成SQL的编写。
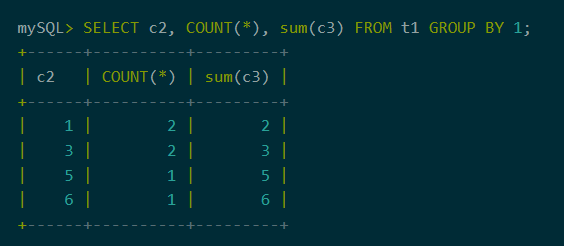
图5:数字编号引用查询列
3、having从句
having从句不但可以使用聚合函数,也可以引用基础列,使用上没有限制。

图6:having
4、Order by从句
排序是查询中常用的功能。聚合下推不仅支持order by从句,也支持对查询列的数字编号引用。还可以根据需要灵活设置排序规则。
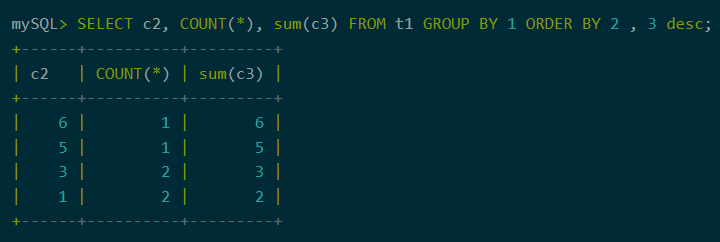
图7:order by
5、limit从句
当查询结果数据量太大时,可以通过limit限制一次返回的记录数。支持多种limit语法。
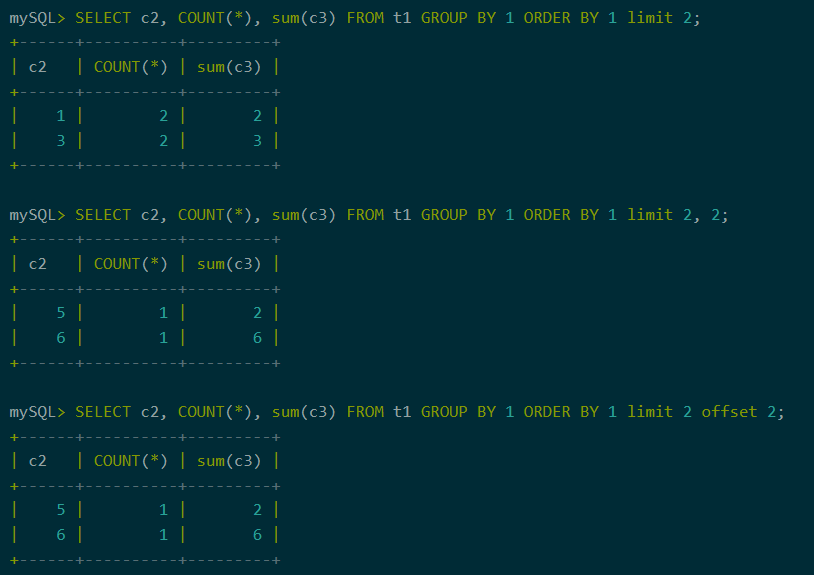
图8:limit
6、into从句
根据业务需要,查询结果可以导出到外部文件,支持into outfile, into dumpfile。也支持导出到变量。支持灵活的into从句位置。
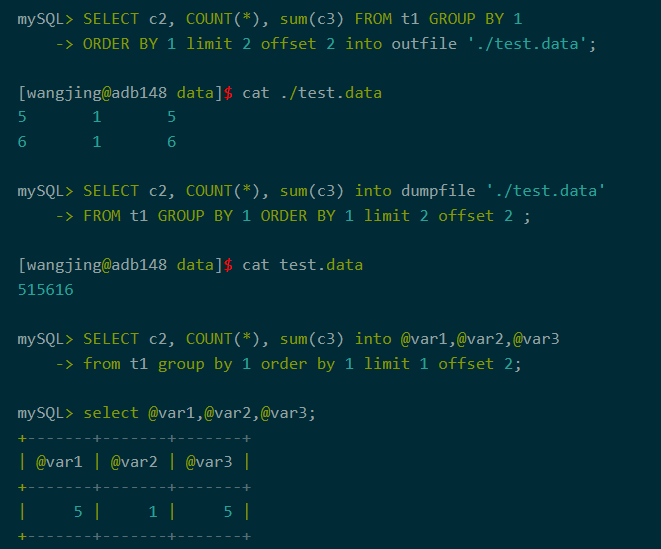
图9-into
7、存储过程,触发器
聚合下推不仅仅支持直接的SQL查询,还支持存储过程和触发器。当存储过程或触发器中存在聚合查询时,会触发聚合下推。
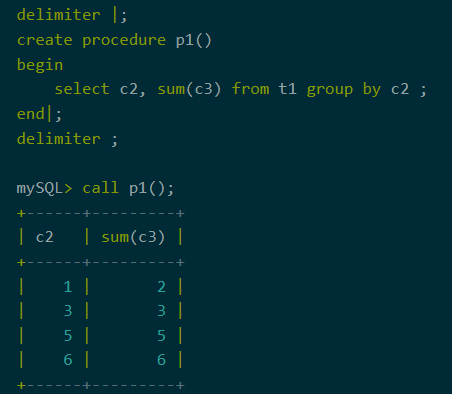
图10:存储过程
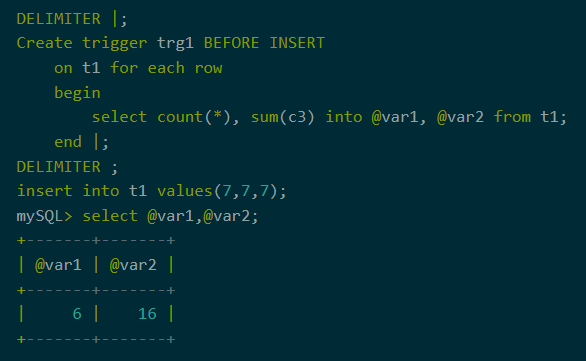
图11:触发器
三、结论
AntDB-M通过聚合下推,减少了分布式数据库各节点间的网络交互次数,降低了数据传输量,充分发挥了数据节点的计算能力,极大提升了分析型SQL的处理性能。同时灵活支持各种查询从句,通过SQL即可完成更多功能,极大方便了业务开发。
关于亚信安慧AntDB数据库
AntDB数据库始于2008年,在运营商的核心系统上,服务国内24个省市自治区的数亿用户,具备高性能、弹性扩展、高可靠等产品特性,峰值每秒可处理百万笔通信核心交易,保障系统持续稳定运行超十年,并在通信、金融、交通、能源、物联网等行业成功商用落地。