司马阅一直在升级,这次升级后,我们将司马阅和主流的AI大模型再做一次测评。这次极端测评,主要pk各大模型对复杂文档处理的精确度。
我们选取的依然是这份专业的行业报告:《中国生成式AI开发者洞察》,共58页,信息量很大、数据复杂,几乎每一页都有图表,且数据具有隐秘性和迷惑性。
我们准备了3个问题,现在开测!
第1个问题:“生成式AI开发者职位中,哪三类最多,用表格呈现出来。”
我们先来问司马阅,司马阅快速理解并回答:资深研发人员占比34.6%,初级研发人员占比14.5%,技术总监占比12.2%。
我们看看原文档,的确是这三类职位,且数据一一对应,回答准确无误。
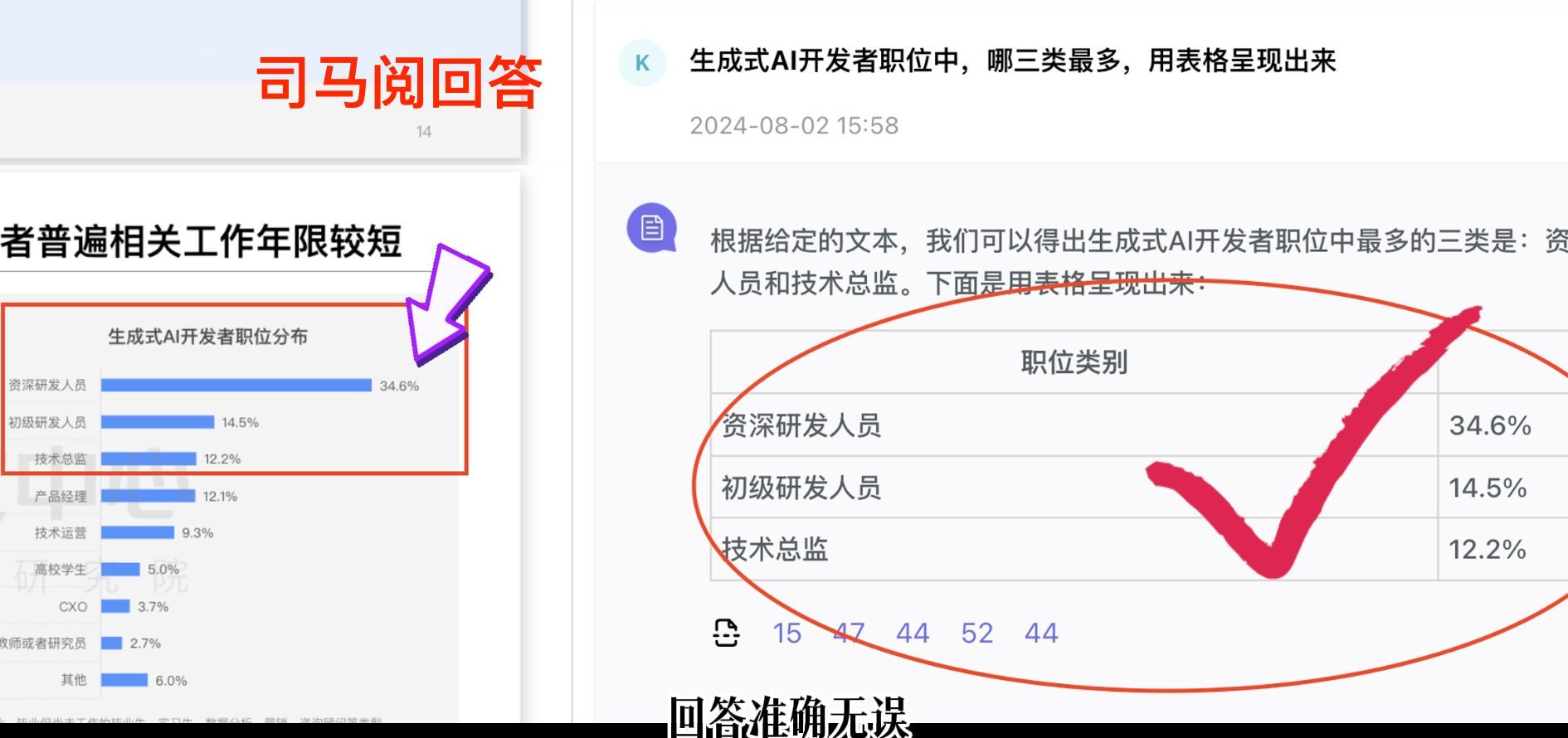
再来看豆包怎么回答,豆包回答的职位是:初级研发人员、资深研发人员、产品经理,职业与原文件不符,且把初级研发人员和资深研发人员的占比数据搞反了。
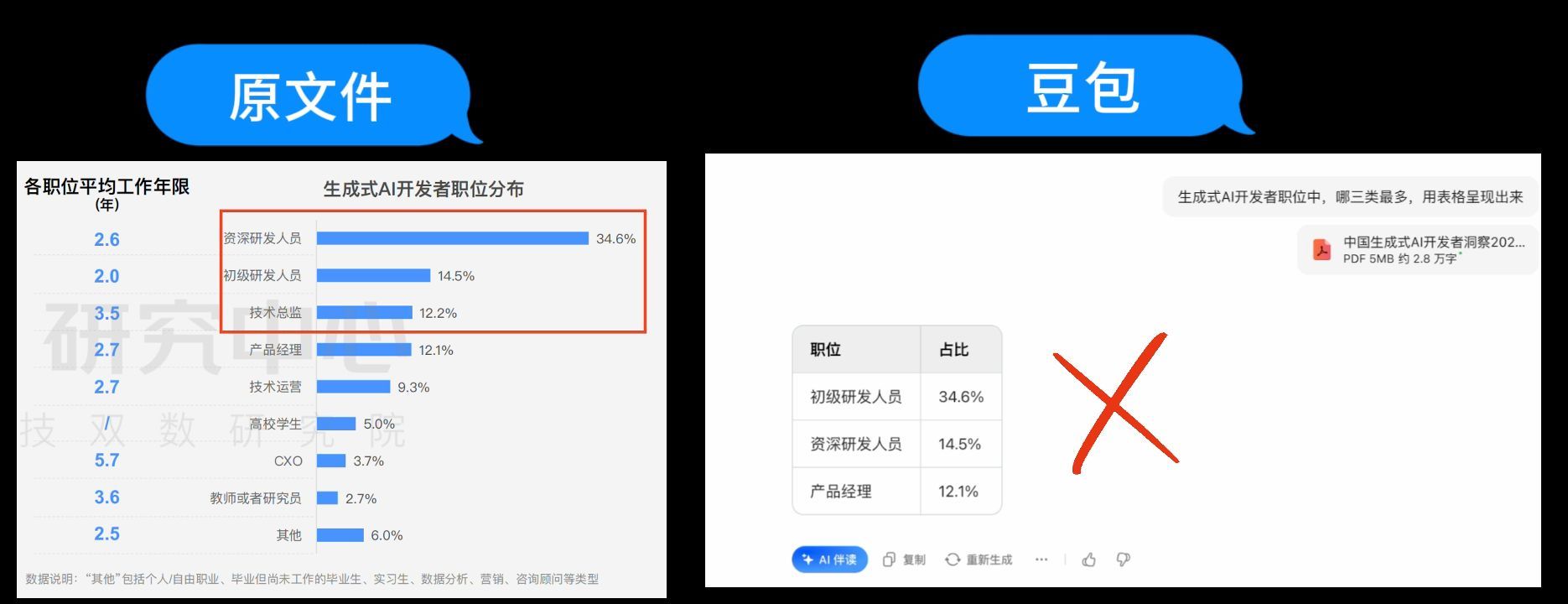
接着问通义千问,通义千问给出的职位是算法工程师、产品经理、大模型开发,三个职位全错,对应的数据自然也是错误的。
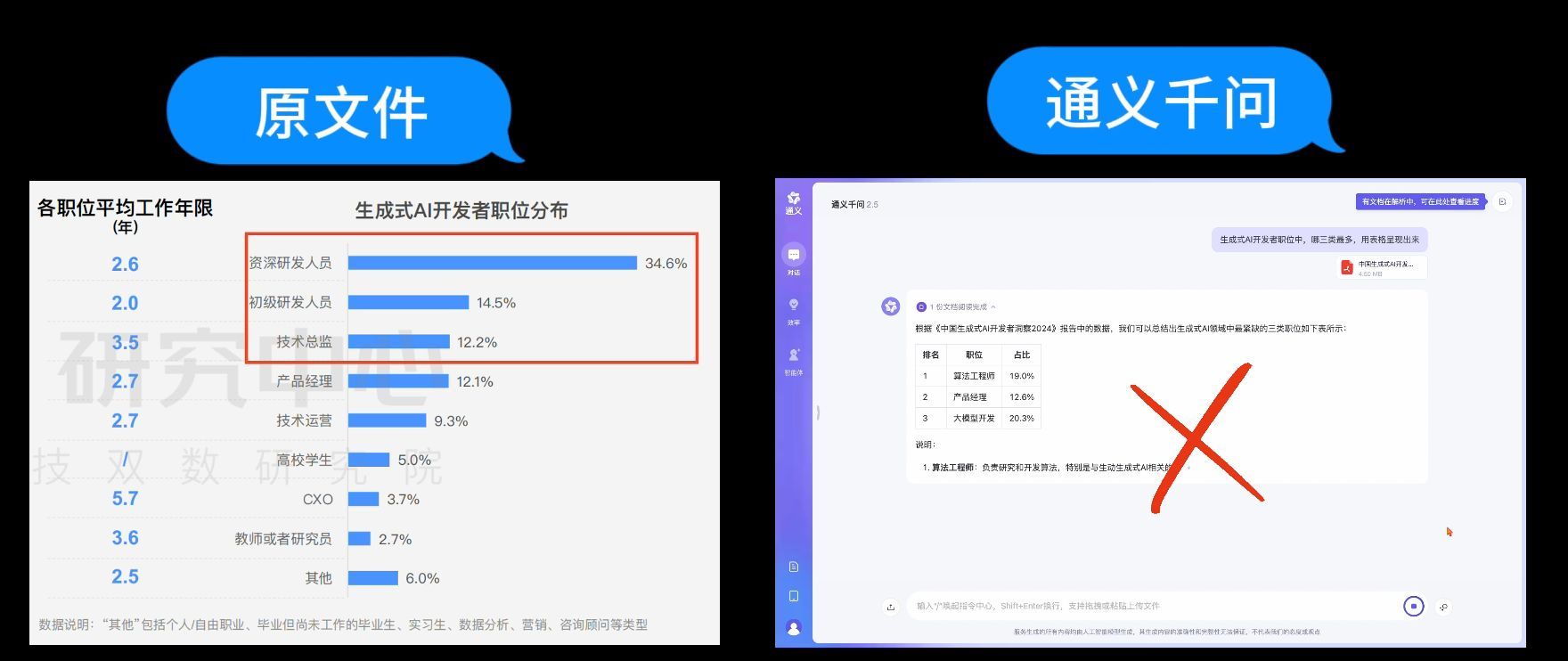
接着我们问Kimi,Kimi的回答是初级研发人员、产品经理、算法工程师,与原文件的前三类职业有差别,且读取的数据也是全错。
接下来问的是腾讯元宝,腾讯元宝回答对了资深研发人员和初级研发人员,前两类的数据也是正确的,但是它给出的第三类职位是产品经理,而原文中是技术总监,结果不完全正确。
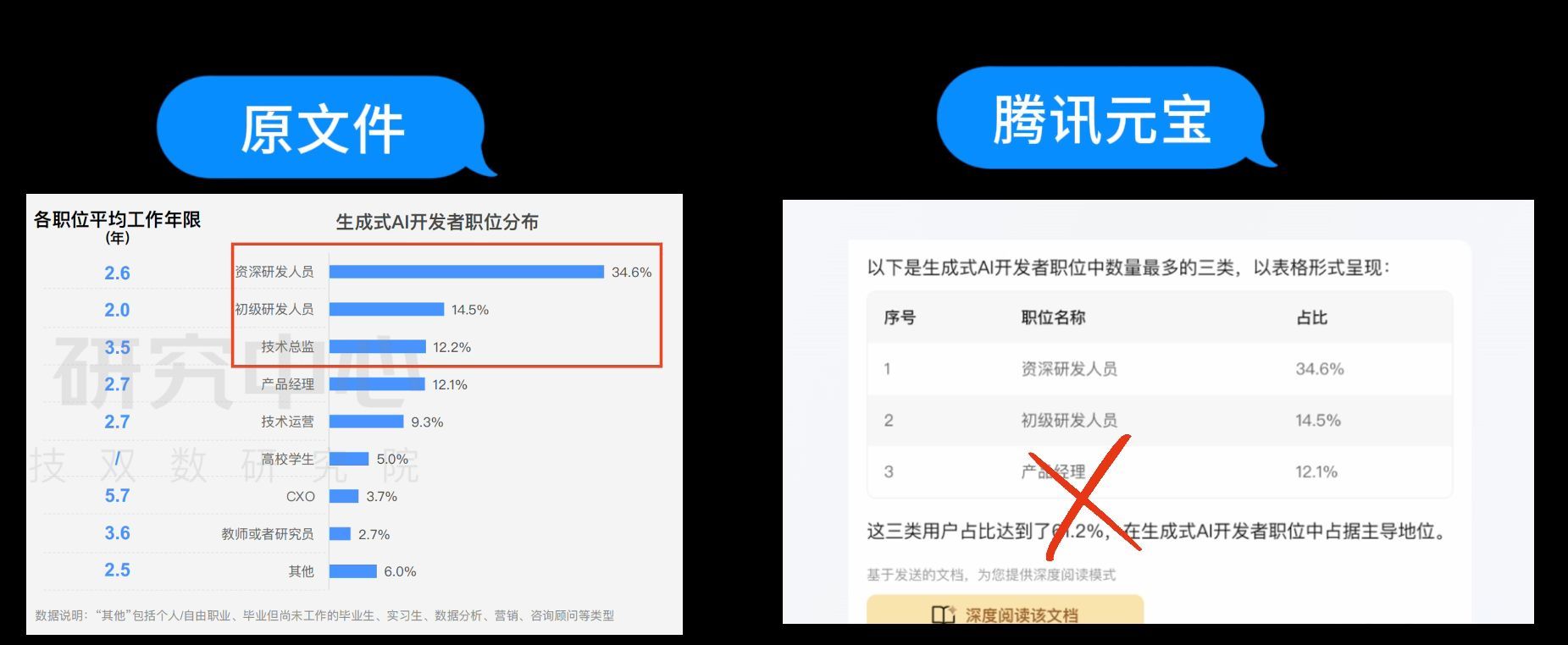
接着我们问文心一言,文心一言给的占比数据是对的,但是三个职位全部对应错误,所以结果不准确。
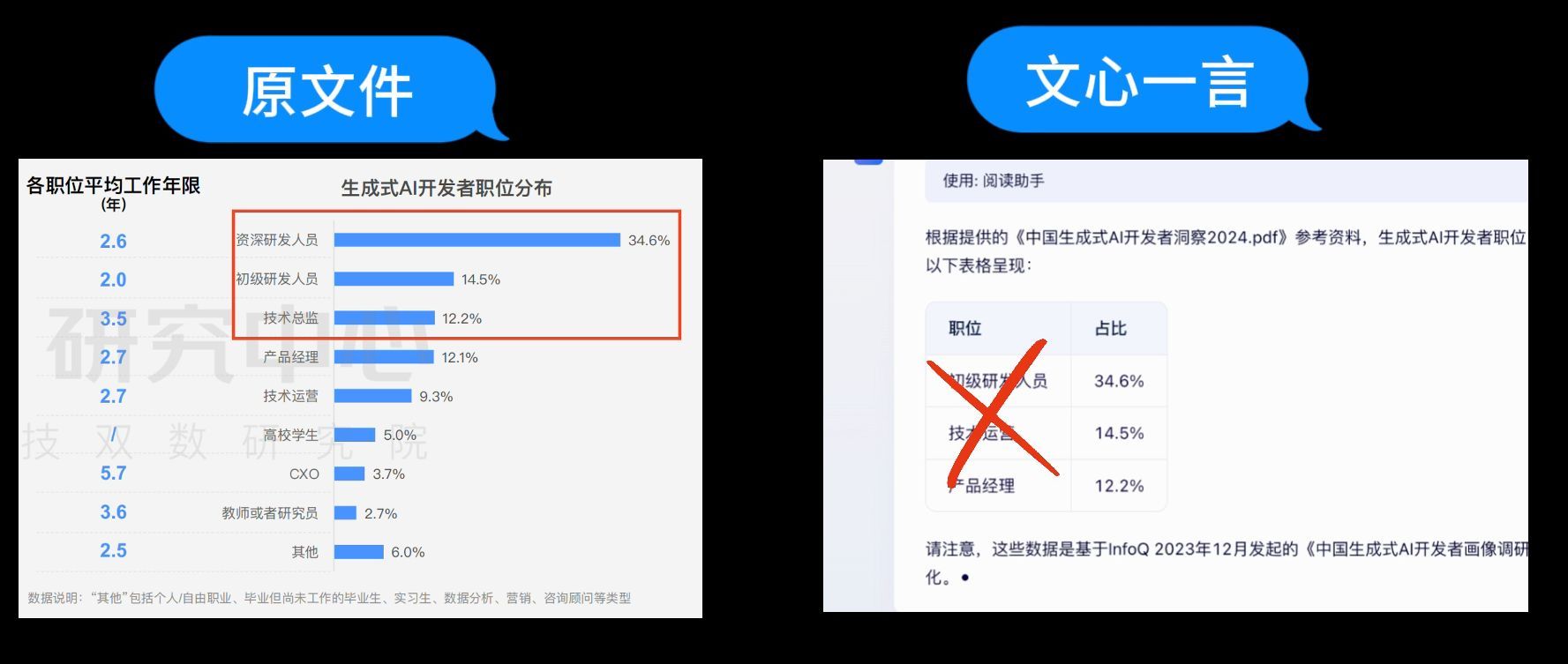
接下来我们来问ChatGPT,ChatGPT给出的回答是算法工程师、产品经理、自然语言处理,职位和占比全错。
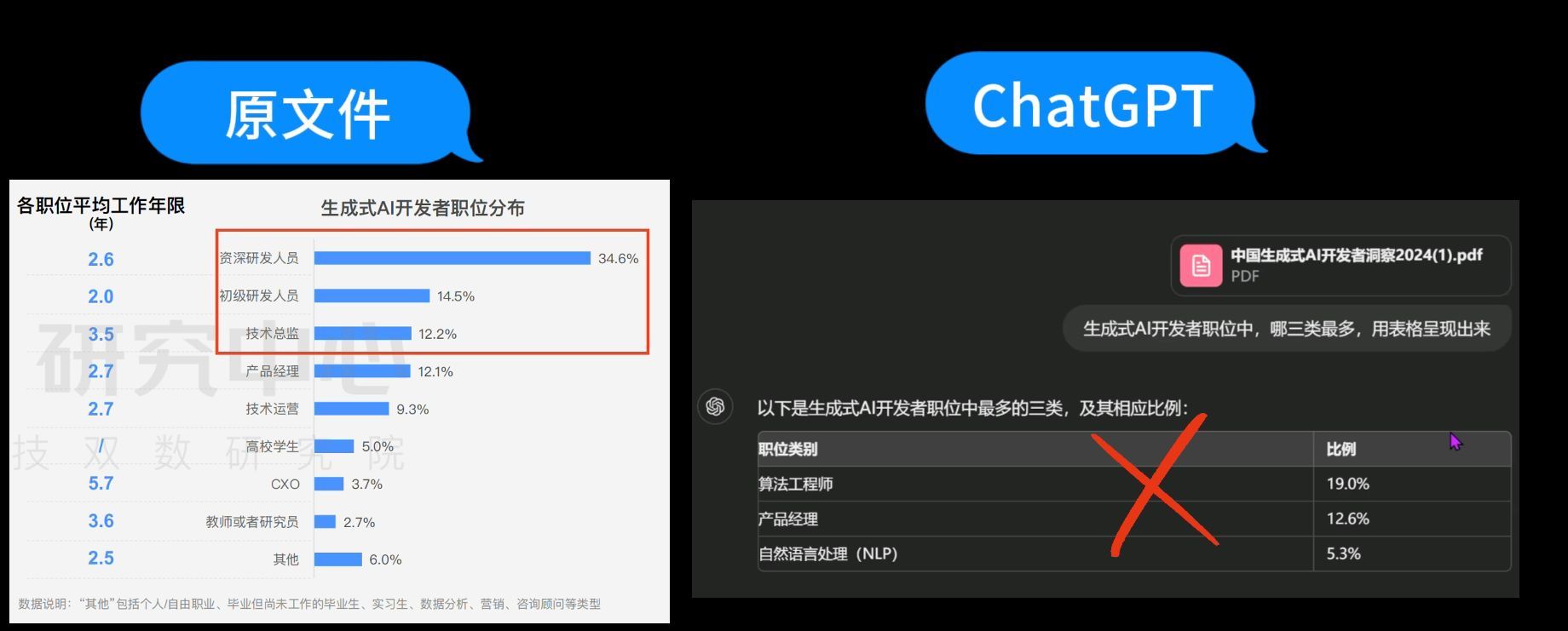
第1个问题测试完毕,接着进行第二轮测试。
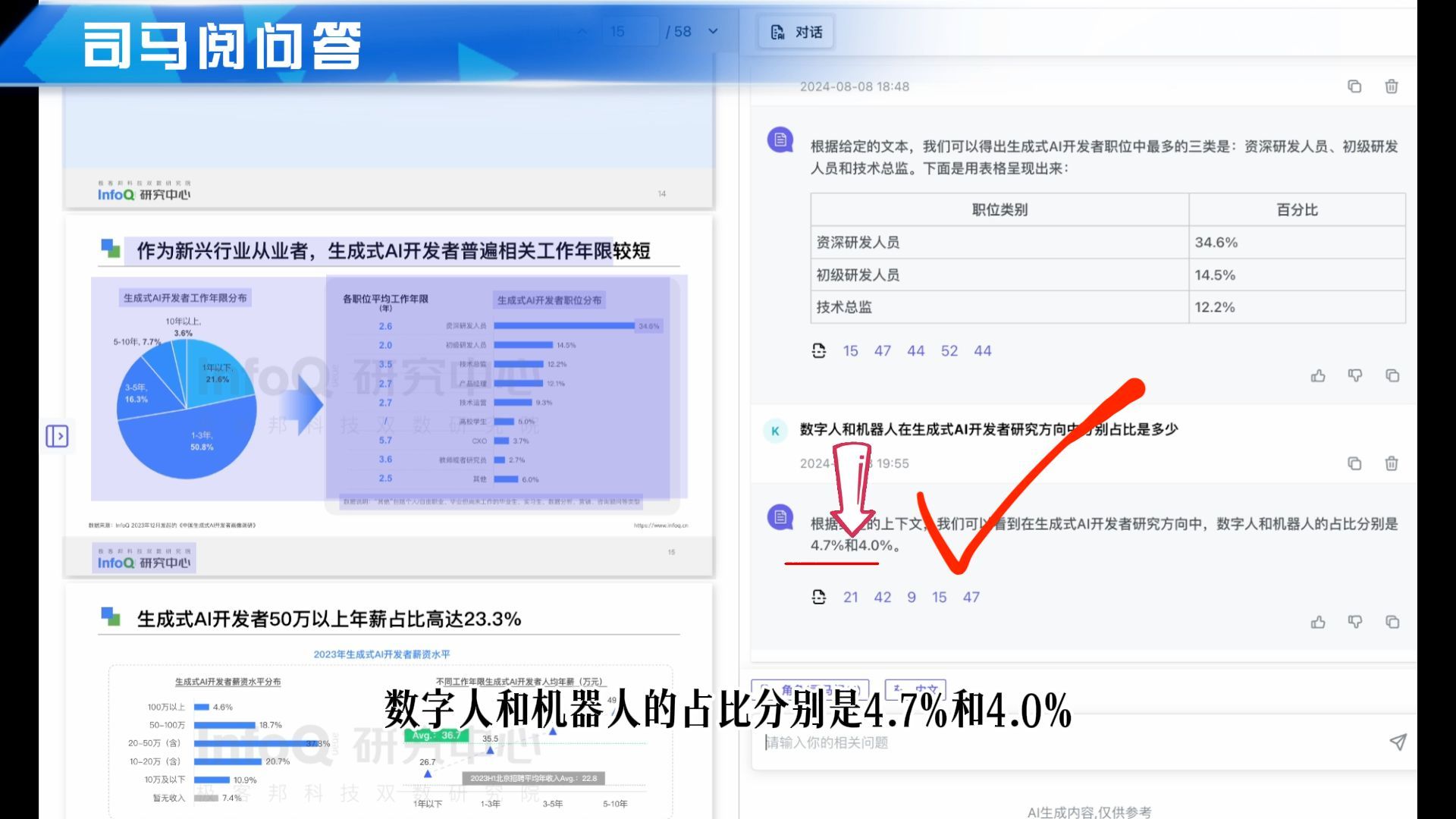
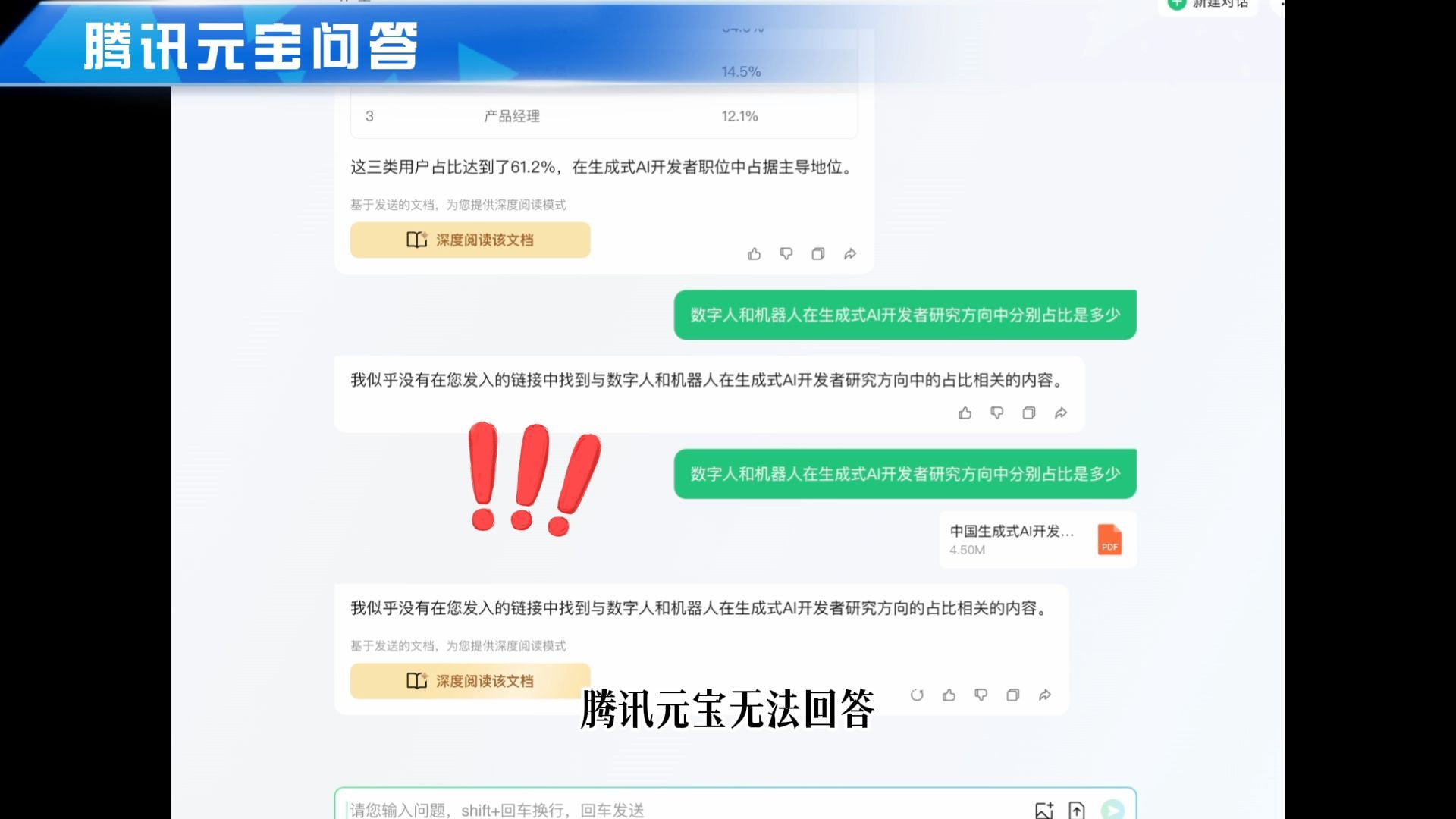
第2个问题:“数字人和机器人在生成式AI开发者研究方向中分别占比是多少?”
首先来看司马阅是怎么回答的,数字人和机器人的占比分别是4.7%和4.0%,看看原文,回答准确。
接着来问豆包,豆包给出的答案是9.1%和6.7%,两个数据均错误。
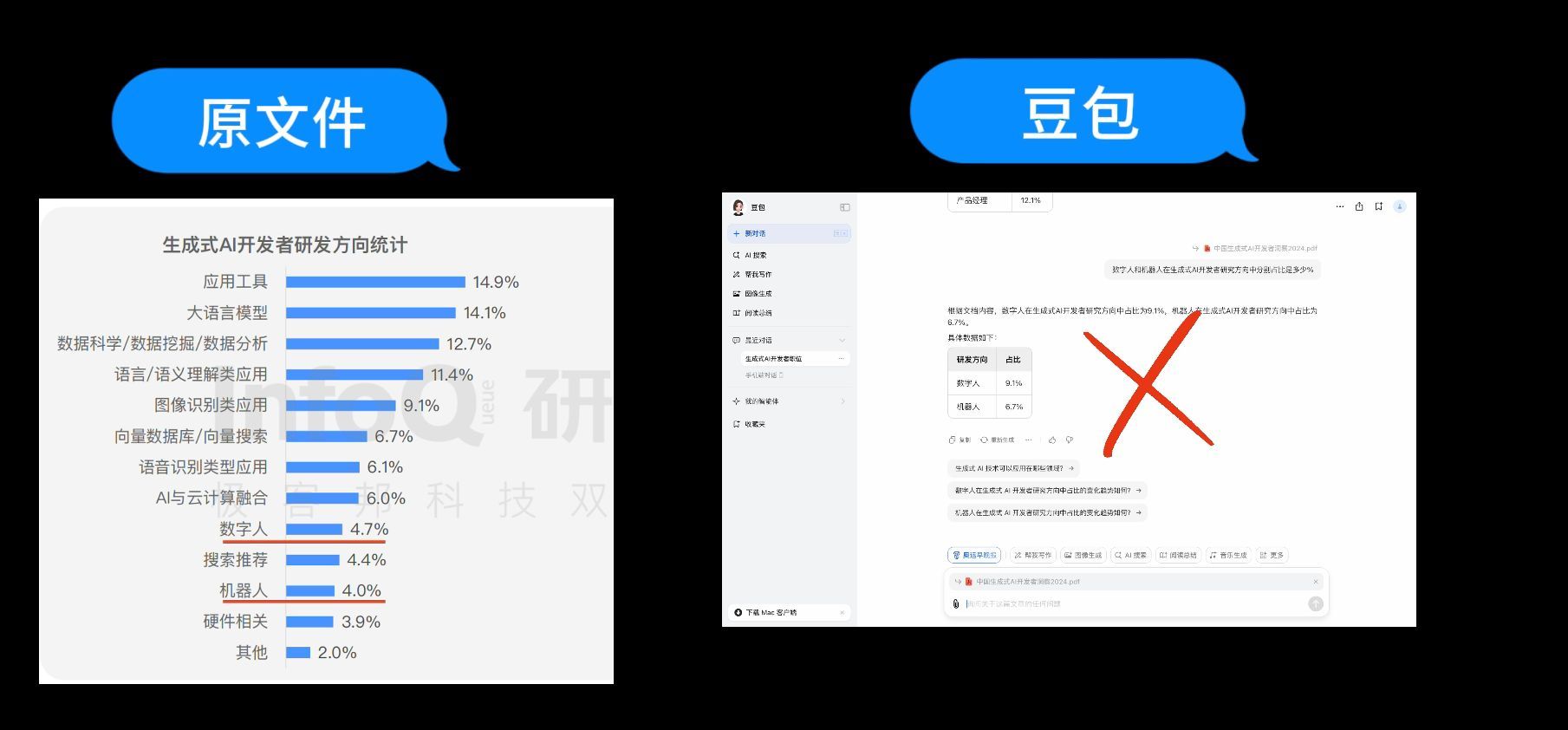
接着我们来问通义千问,通义千问回答的占比都是4.0%,只回答对了机器人的占比。
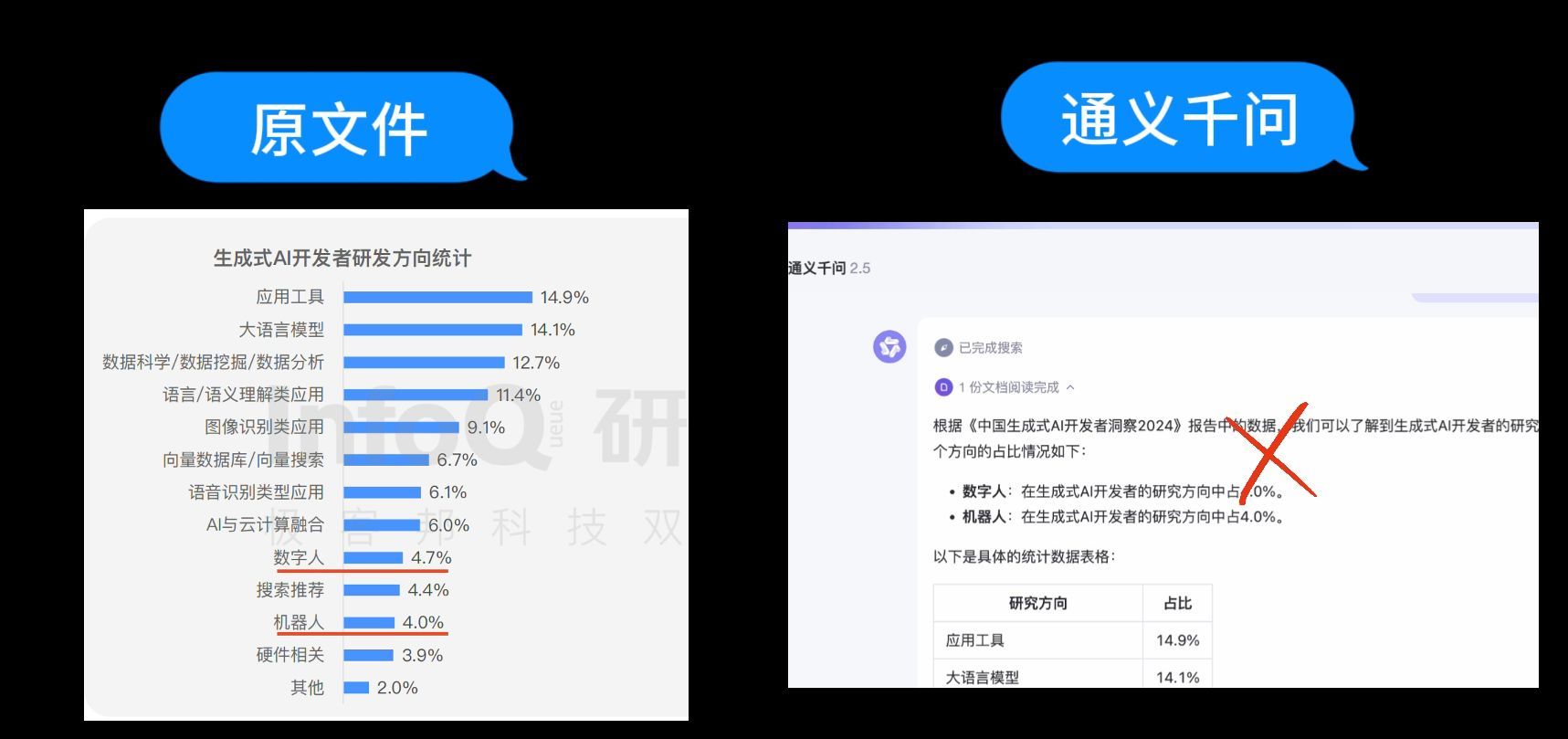
接着我们问Kimi,Kimi的回答是数字人占比4.7%,机器人占比2.0%,只回答对了数字人的占比。
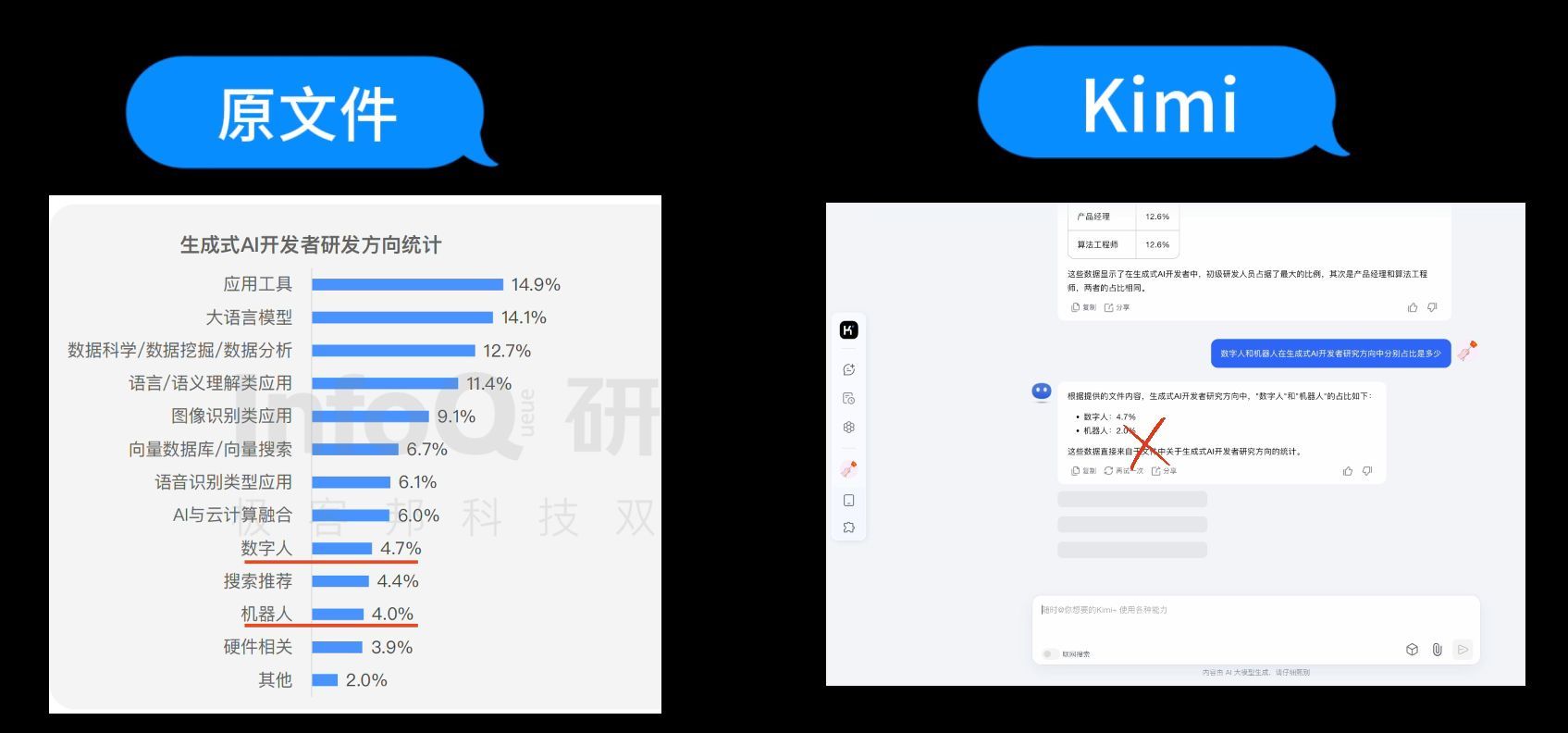
再看看腾讯元宝,腾讯元宝无法回答。
接着我们问文心一言,文心一言同样无法回答这个问题。
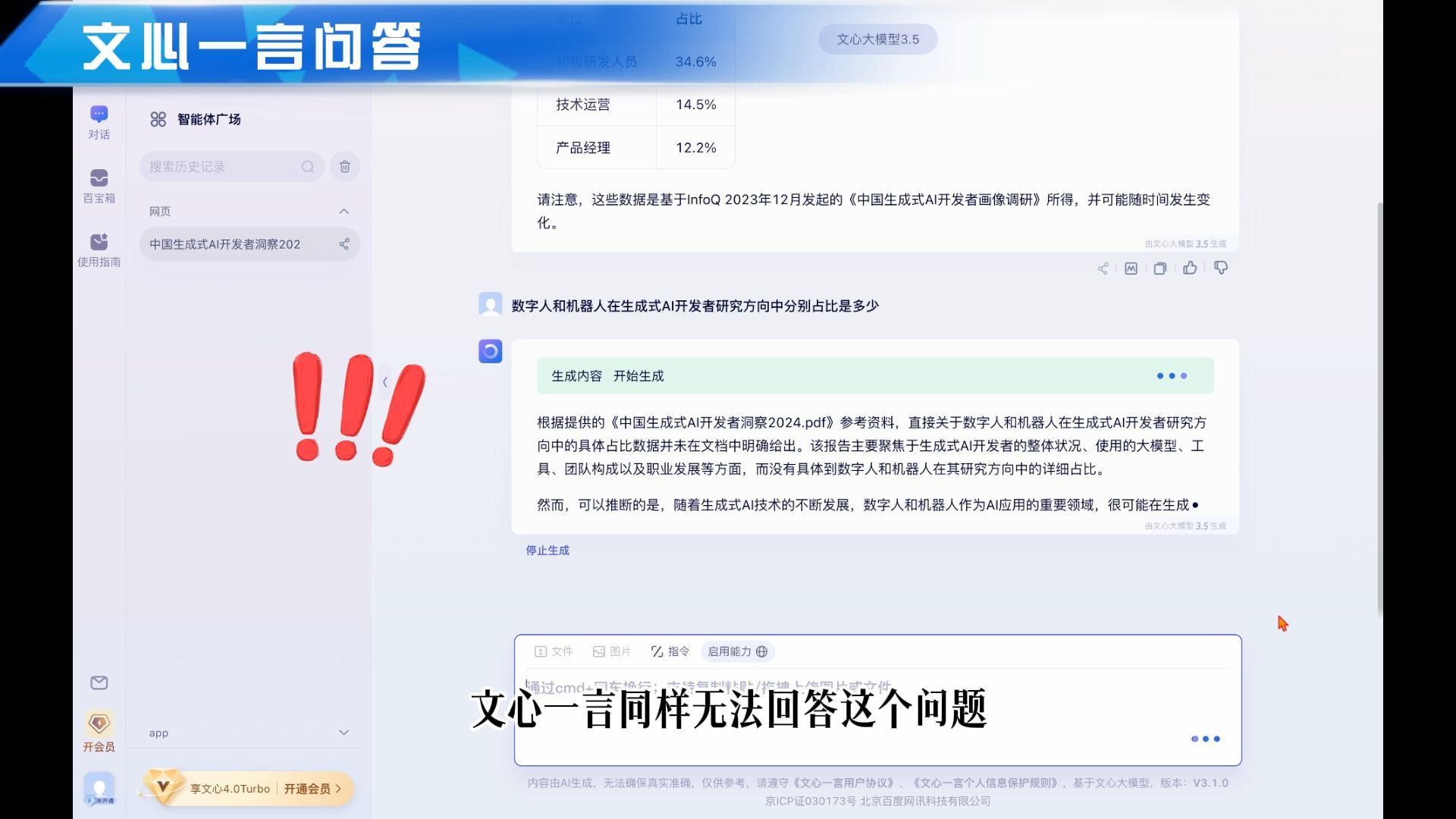
接下来我们来问ChatGPT,ChatGPT给出的回答是数字人占比6.0%,机器人占比4.0%,只回答对了机器人的占比。
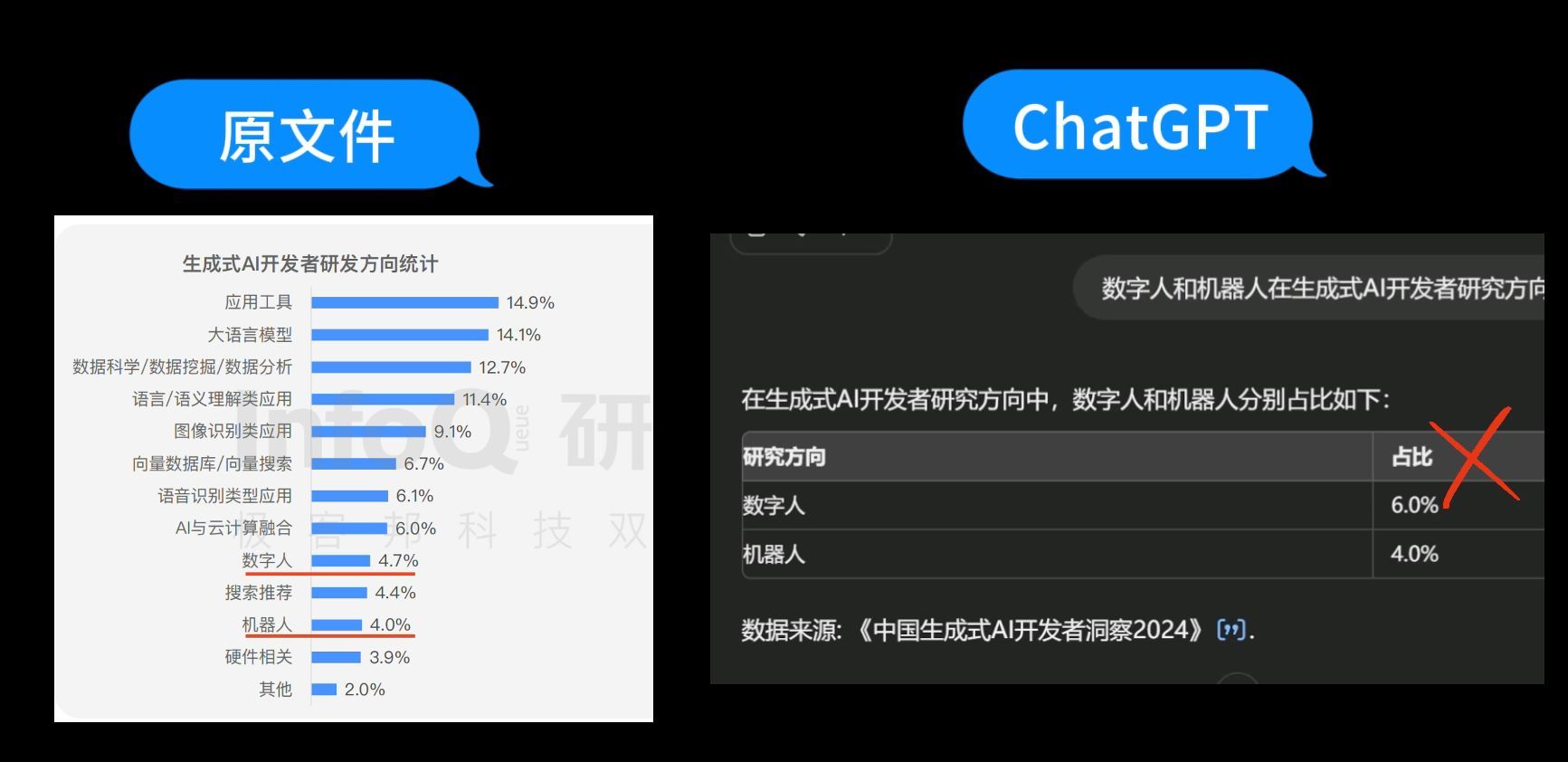
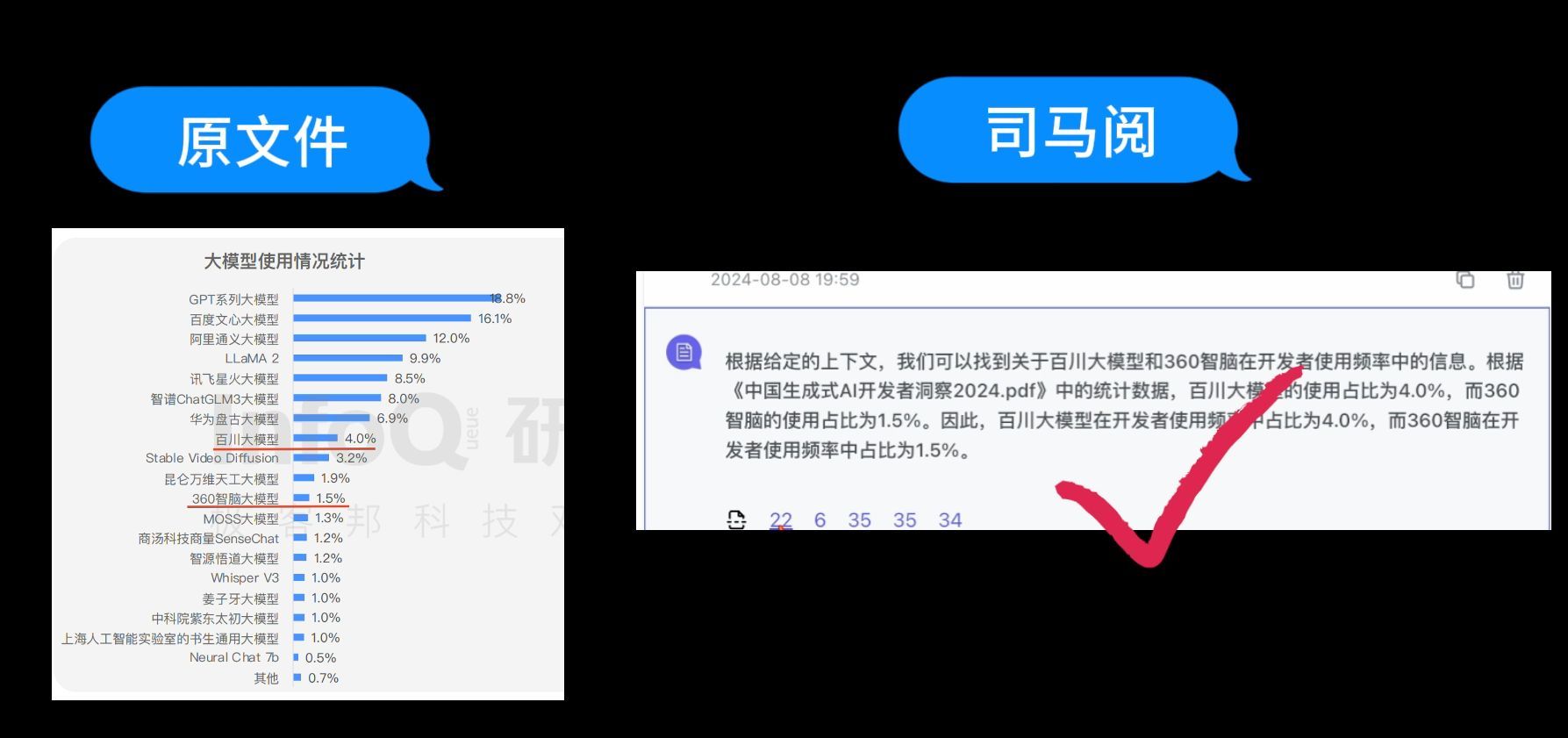
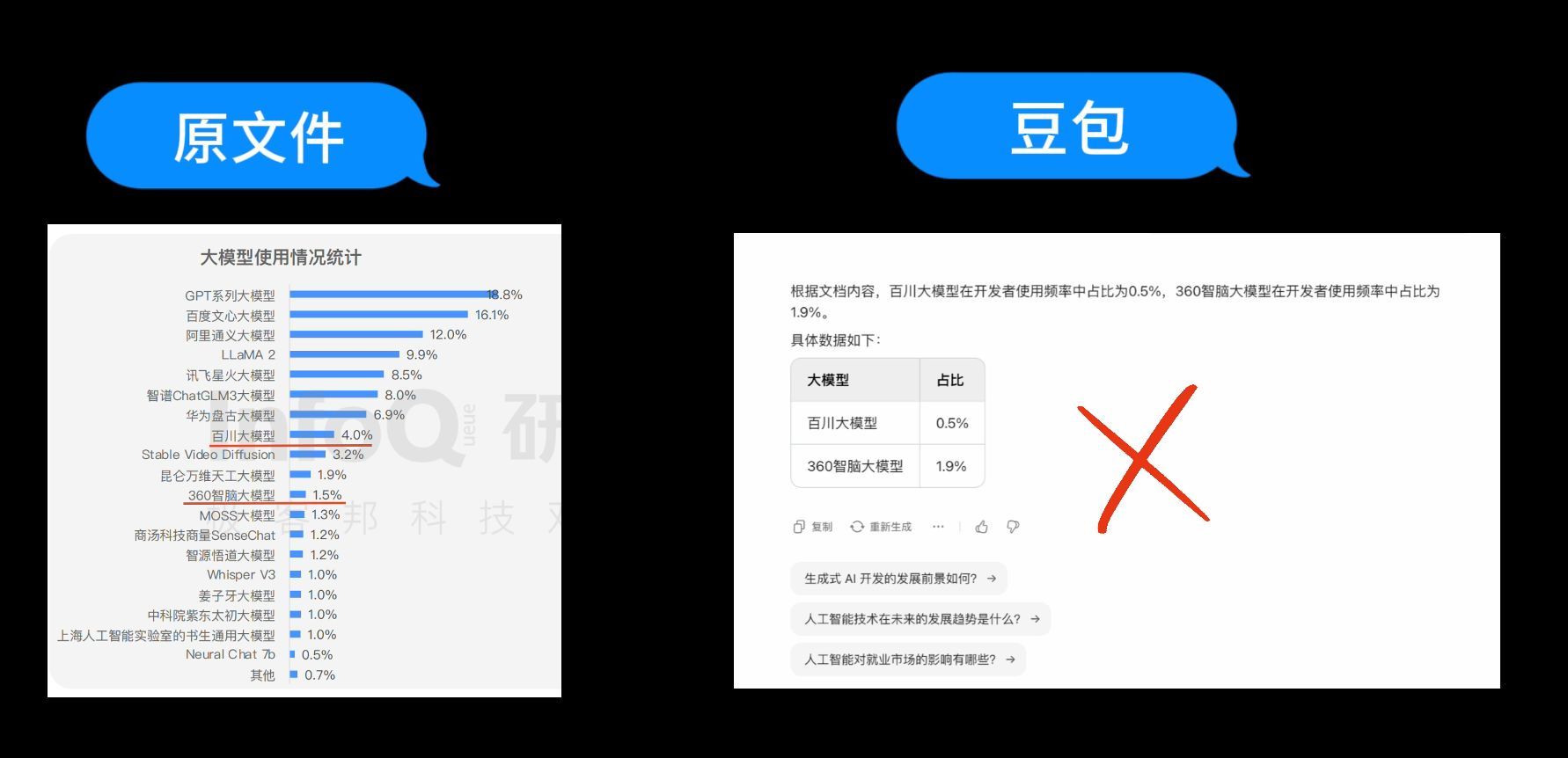
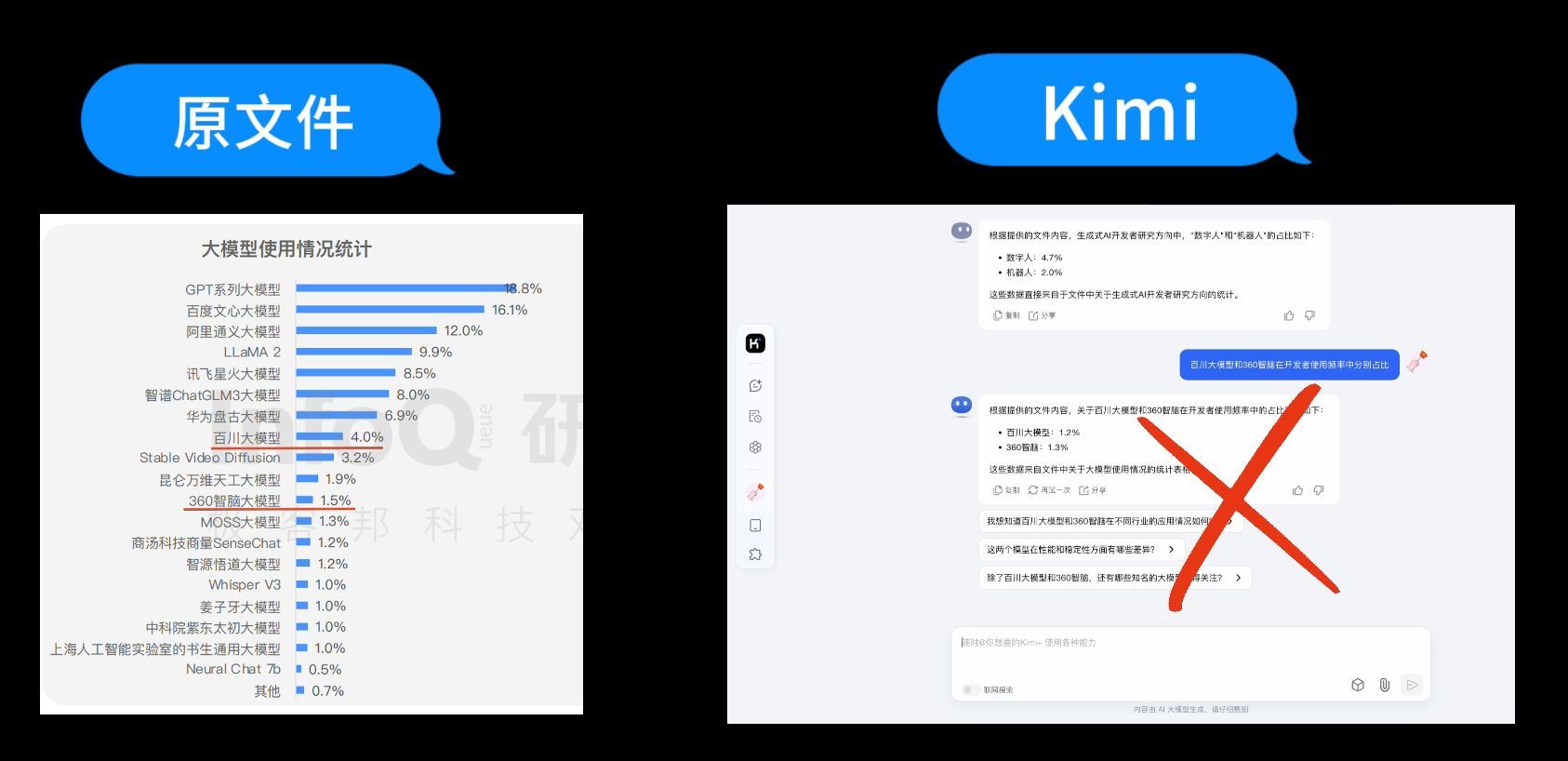
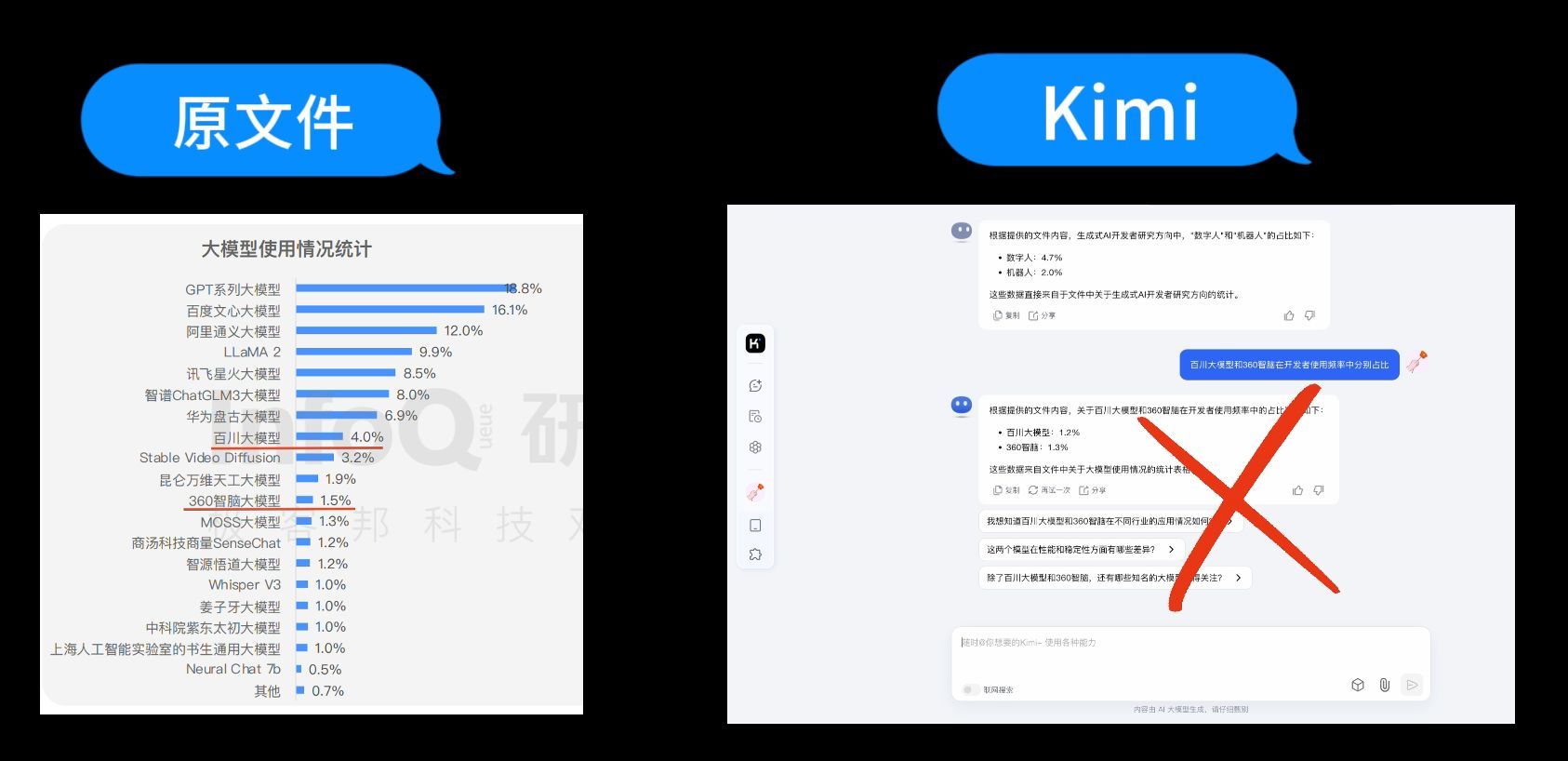
第3个问题:“百川大模型和360智脑在开发者使用频率中分别占比”
来看看司马阅的回答,司马阅给出的答案是百川大模型的使用占比为4.0%,360智脑的使用占比为1.5%,原文也是这两个数据,回答正确。
再来看豆包怎么回答,豆包的回答是0.5%和1.9%,两个数据均和原文对不上。
接着问通义千问,通义千问无法给出百川大模型和360智脑在开发者使用频率中的占比。
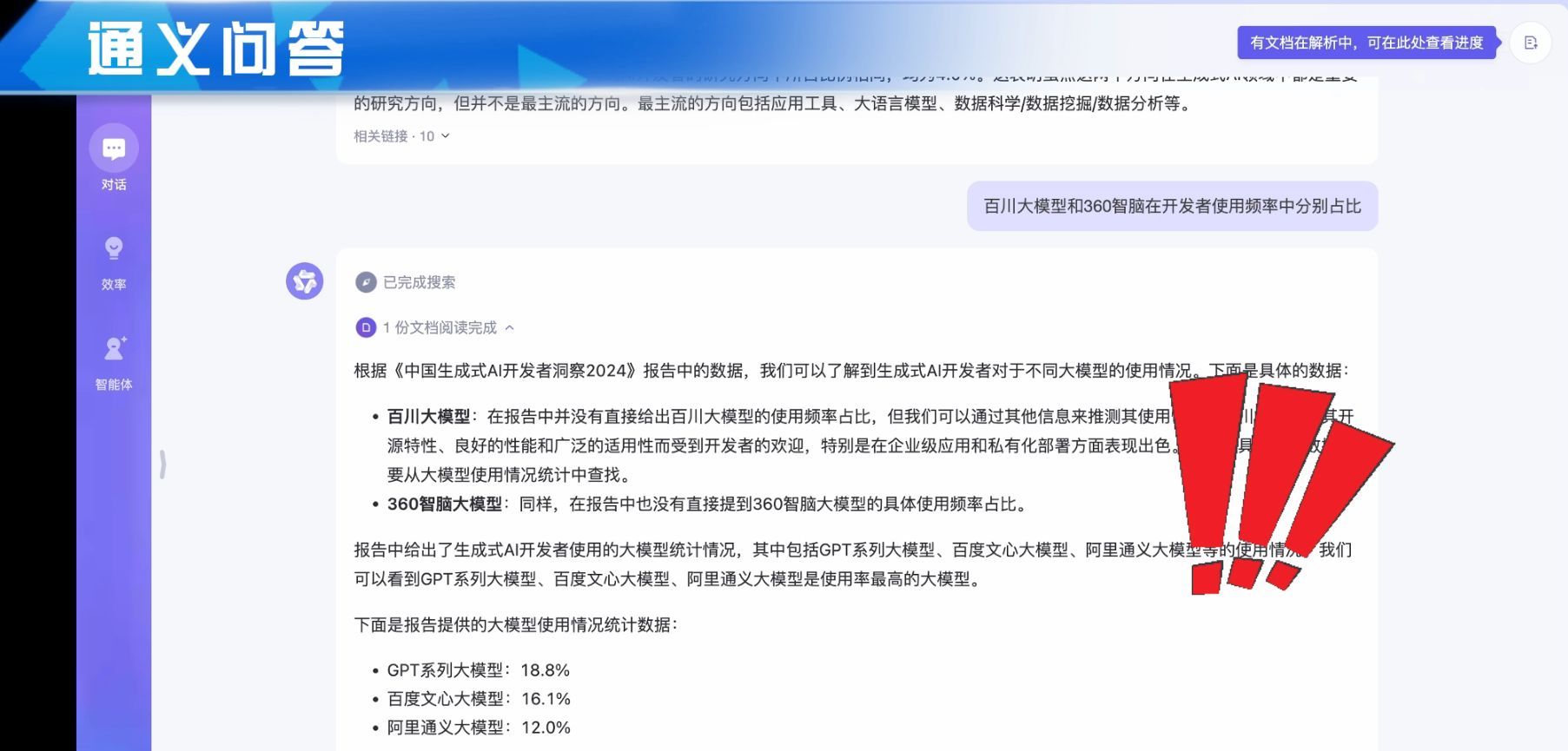
接着我们问Kimi,Kimi的回答是百川大模型占比1.2%,360智脑占比1.3%,与原文差别较大。
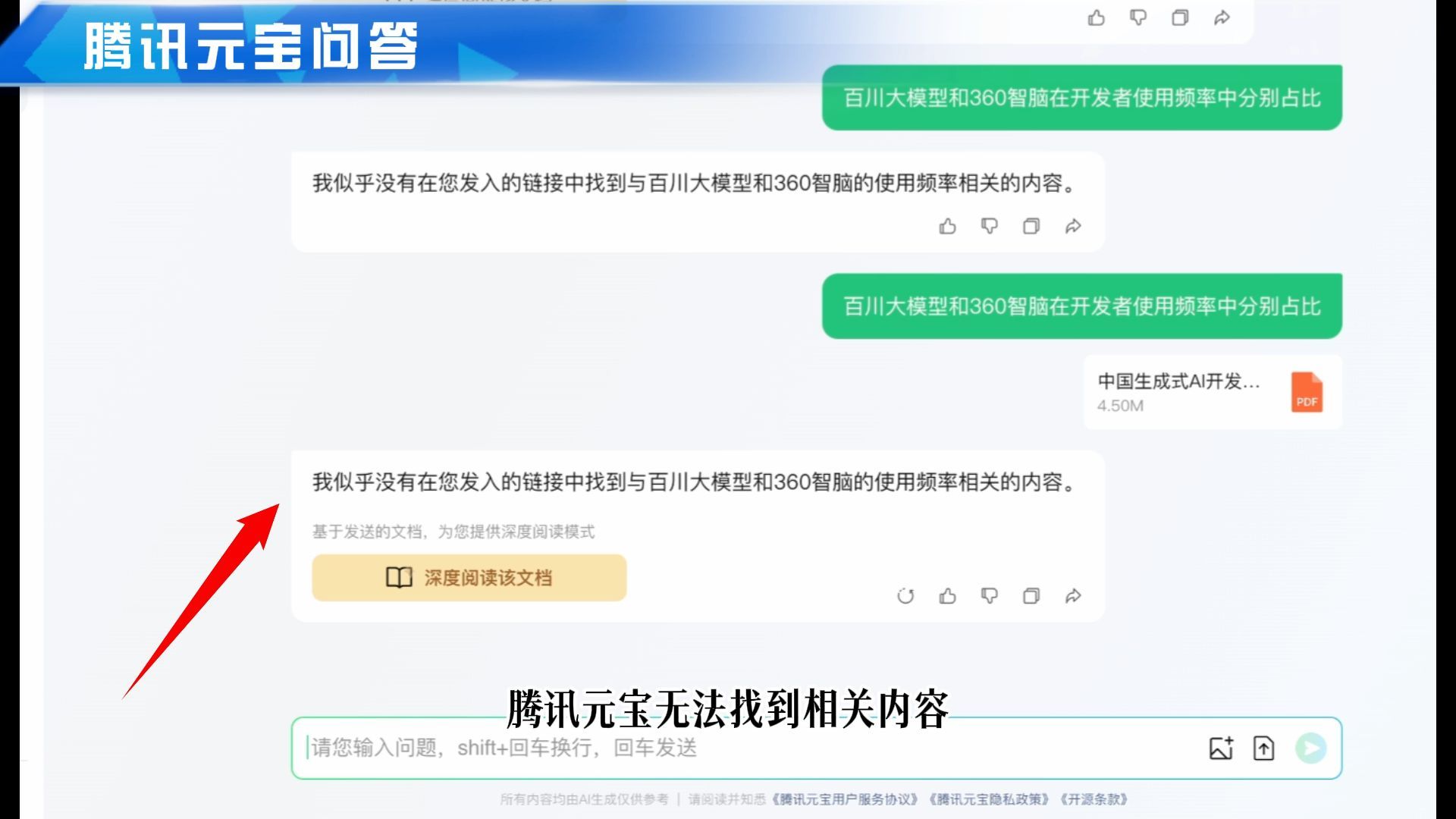
接下来问的是腾讯元宝,腾讯元宝无法找到相关内容,提取信息失败。
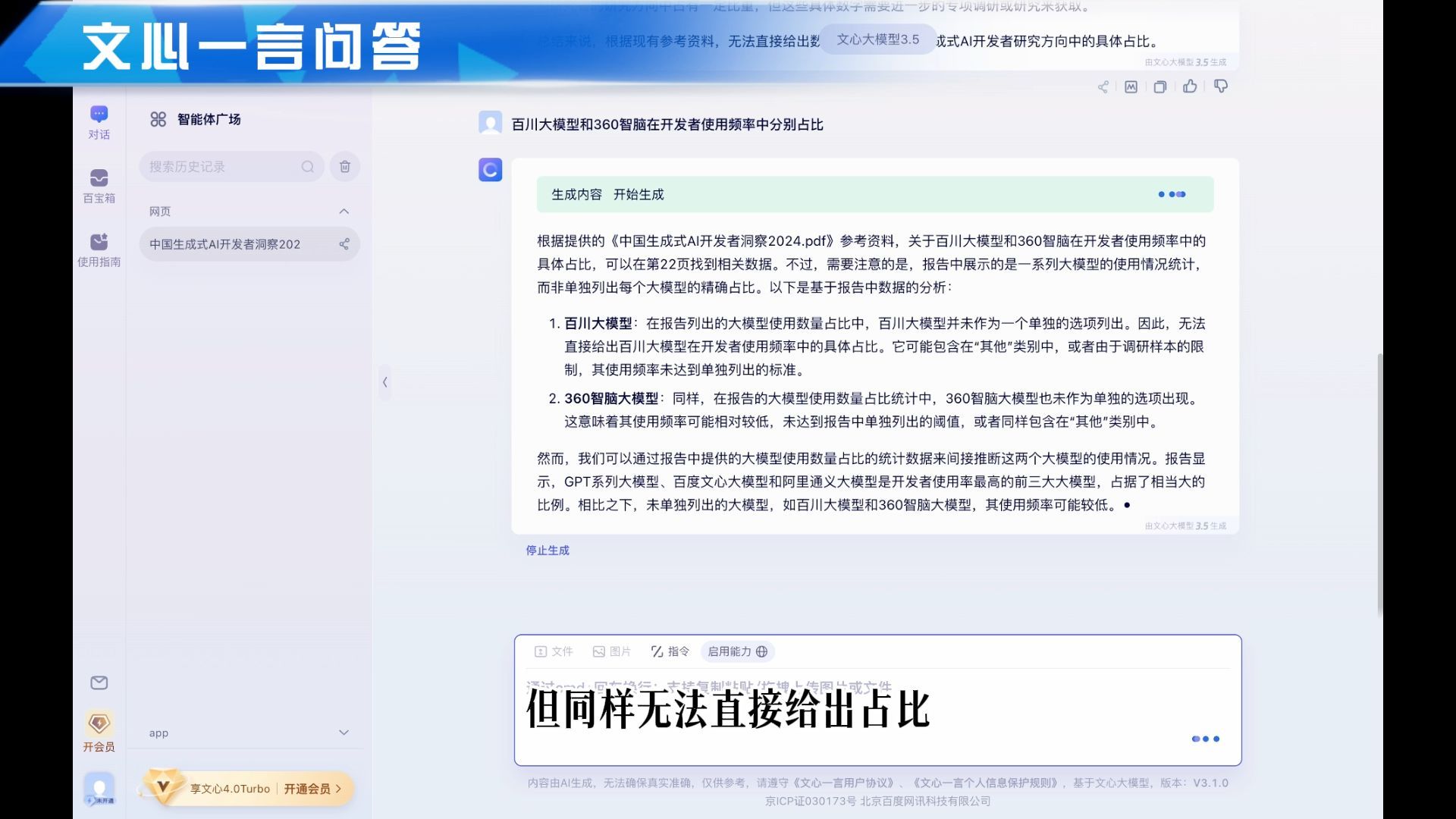
接着我们问文心一言,文心一言说了很多,但同样无法直接给出占比。
接下来我们来问ChatGPT,ChatGPT给出的占比分别是4.0%和3.2%,百川大模型的使用占比回答正确,360智脑的使用占比错误。
3个问题测评下来,司马阅在对复杂文档处理的精确度上仍然具有领先的优势,这得益于DocMind文档智能大模型。
DocMind是司马阅自研文档智能大模型,基于Transformer结构,融合深度学习、自然语言处理(NLP)和计算机视觉(CV)等技术的文档理解预训练模型,DocMind能够处理富文本文档中的复杂结构和视觉信息,提高信息抽取的准确性。
经过DocMind处理过的文档,然后通过大语言模型进行自然语言交互,相当于DocMind为大语言模型提供了更有价值的语料,最终回答精准度和实用性更高,也更适用于严肃商业应用场景。
司马阅使用链接:https://smartread.cc/