如何使用 LLama 3.1(一个本地运行的模型)来执行GraphRAG操作,总共就50号代码。
首先,什么是GraphRAG?GraphRAG是一种通过考虑实体和文档之间的关系来执行检索增强生成的方式,关键概念是节点和关系。
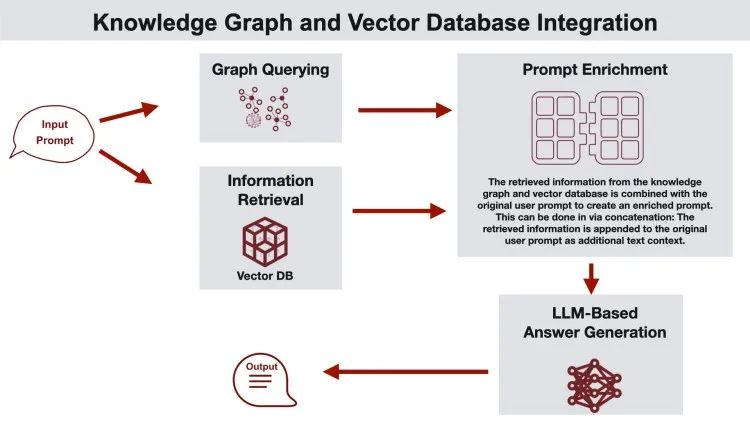
▲ 知识图谱与向量数据库集成
知识图谱与向量数据库集成是GraphRAG 架构之一:这种方法利用知识图谱和向量数据库来收集相关信息。知识图谱的构建方式可以捕获向量块之间的关系,包括文档层次结构。知识图谱在从向量搜索中检索到的块附近提供结构化实体信息,从而通过有价值的附加上下文丰富提示。这个丰富的提示被输入到 LLM 中进行处理,然后 LLM 生成响应。最后,生成的答案返回给用户。此架构适用于客户支持、语义搜索和个性化推荐等用例。
节点代表从数据块中提取的实体或概念,例如人、组织、事件或地点。
知识图谱中,每个节点都包含属性和特性,这些属性为实体提供了更多上下文信息。
然后我们定义节点之间的连接关系,这些连接可以包括各种类型的关联,例如层次结构(如父子关系)、时间顺序(如前后关系)或因果关系(因果关系)。
关系还具有描述连接性质和强度的属性。当你有很多文档时,你会得到一个很好的图来描述所有文档之间的关系。
让我们看一个非常简单的例子,在我们的数据集中,节点可以代表像苹果公司和蒂姆·库克这样的实体,而关系则可以描述蒂姆·库克是苹果公司的 CEO。
这种方法非常强大,但一个巨大的缺点是它计算成本很高,因为你必须从每个文档中提取实体,并使用 LLM 计算关系图。这就是为什么使用像 LLaMa 3.1 这样本地运行的模型来采用这种方法非常棒。
保姆级教程开始
在本文中,我们将结合使用LangChain、LLama 和 Ollama ,以及 Neo4j 作为图数据库。我们将创建一个关于一个拥有多家餐厅的大型意大利家庭的信息图,所以这里有很多关系需要建模。
先利用Ollama拉取llama3.1 8b模型:
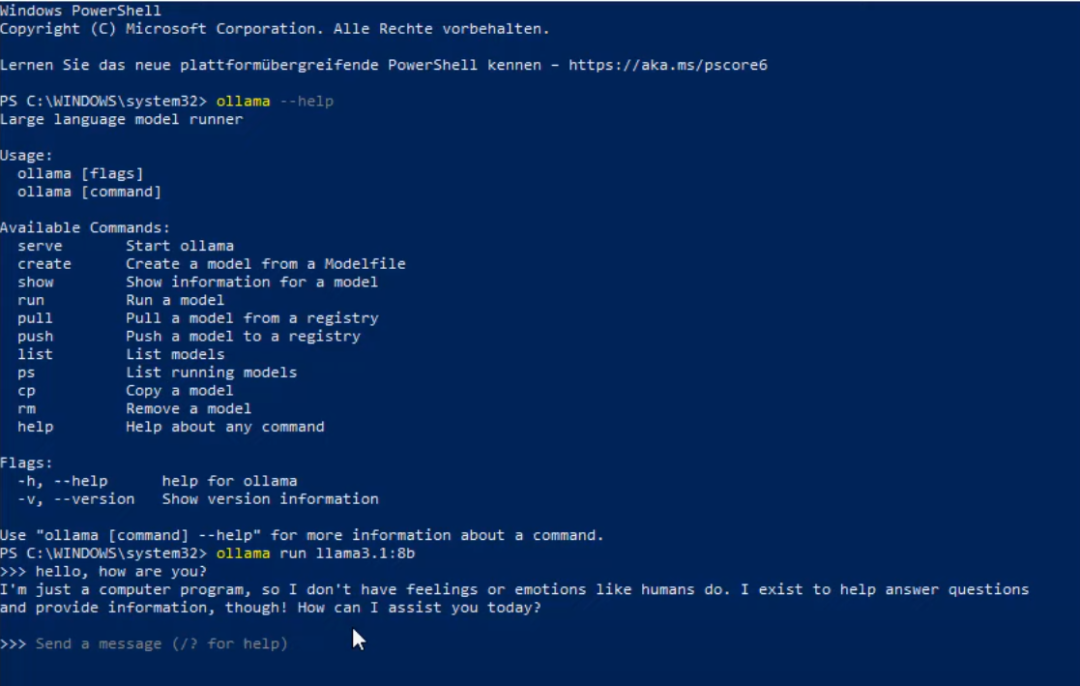
所有代码的链接我放在文末。。。
打开代码文件,来到VS Code 中,你可以在左边看到我们将使用的多个文件。
配置运行Neo4j数据库
在进入代码之前,我们将设置 Neo4j。我为你创建了一个 Docker Compose 文件。所以我们将使用 neo4j 文件夹,里面有一个 jar 文件,这是我们创建图所需的插件。
要创建我们的数据库,只需运行 docker compose up:
这将设置所有内容,并且可以直接使用。可能需要几秒钟,之后你会看到数据库正在运行。