今天我们来聊一个新兴的、创新空间很大的方向:时间序列+预训练大模型。
预训练大模型因为在大规模多领域的数据集上进行训练,能学习到丰富的、跨领域的时间序列表示,在面对新的、没见过的时间序列数据时,它能够表现出更强的泛化性和数据处理能力,实现更高的准确性。
因此关于时间序列+预训练大模型的研究正在快速发展,并且已经在多个领域和应用中有了显著的成果,比如Chronos、清华Timer等,更有提高了42.8%性能的ViTST。
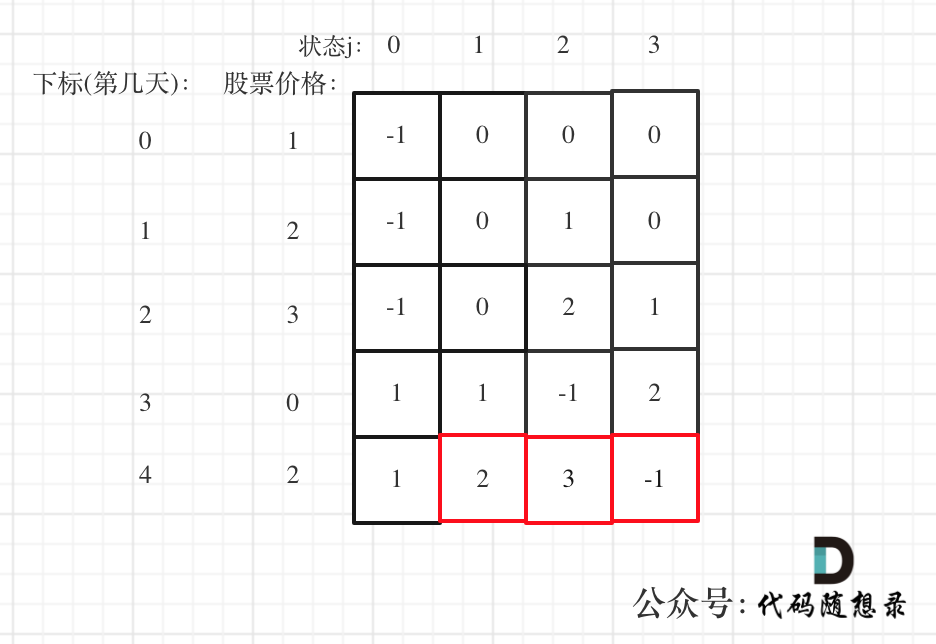
如果有同学有想法发论文,可以从零样本和通用性下手,这俩是这个方向关注的重点。另外为方便大家找参考,我整理了10个时间序列+预训练大模型最新成果,全都已开源可复现。
论文原文+开源代码需要的同学看文末
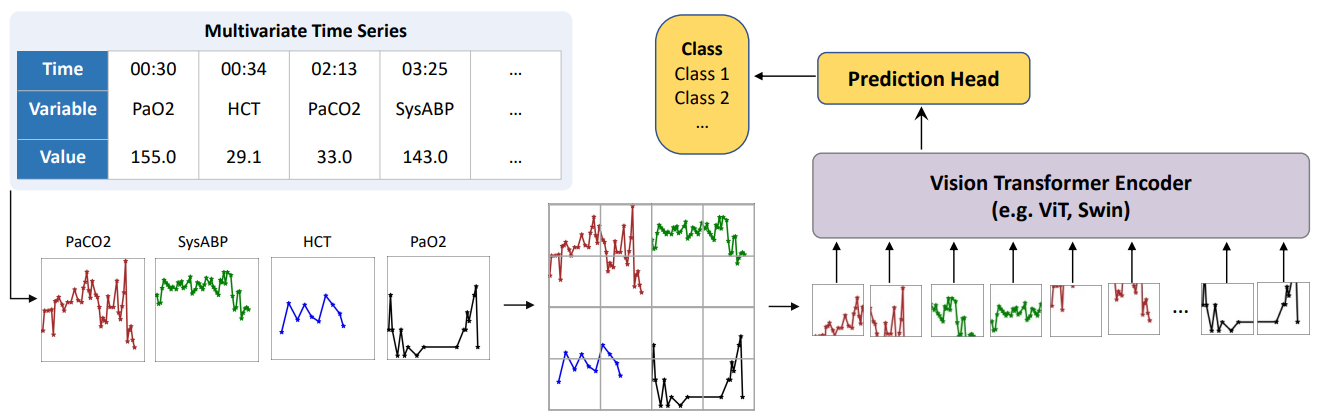
Time Series as Images: Vision Transformer for Irregularly Sampled Time Series
方法:论文介绍了一种新颖的方法,通过将非规则采样的时间序列转换为线图图像,然后利用预训练的ViT进行时间序列分类,类似于图像分类。该方法不仅简化了专门的算法设计,还具有成为时间序列建模的通用框架的潜力。
创新点:
-
将不规则采样的时间序列转化为线图图像,利用预训练的ViT进行时间序列分类。这种方法简单而直观,能够处理具有不同特征的时间序列数据,无论其是否规则、结构不同还是尺度不同。
-
ViTST在缺失观测值的情况下展现出的鲁棒性:在“leave-sensors-out”设置中,即使在测试时掩盖了一半的变量,ViTST在绝对F1分数上比领先的专门基线提高了42.8%性能。

Chronos: Learning the Language of Time Series
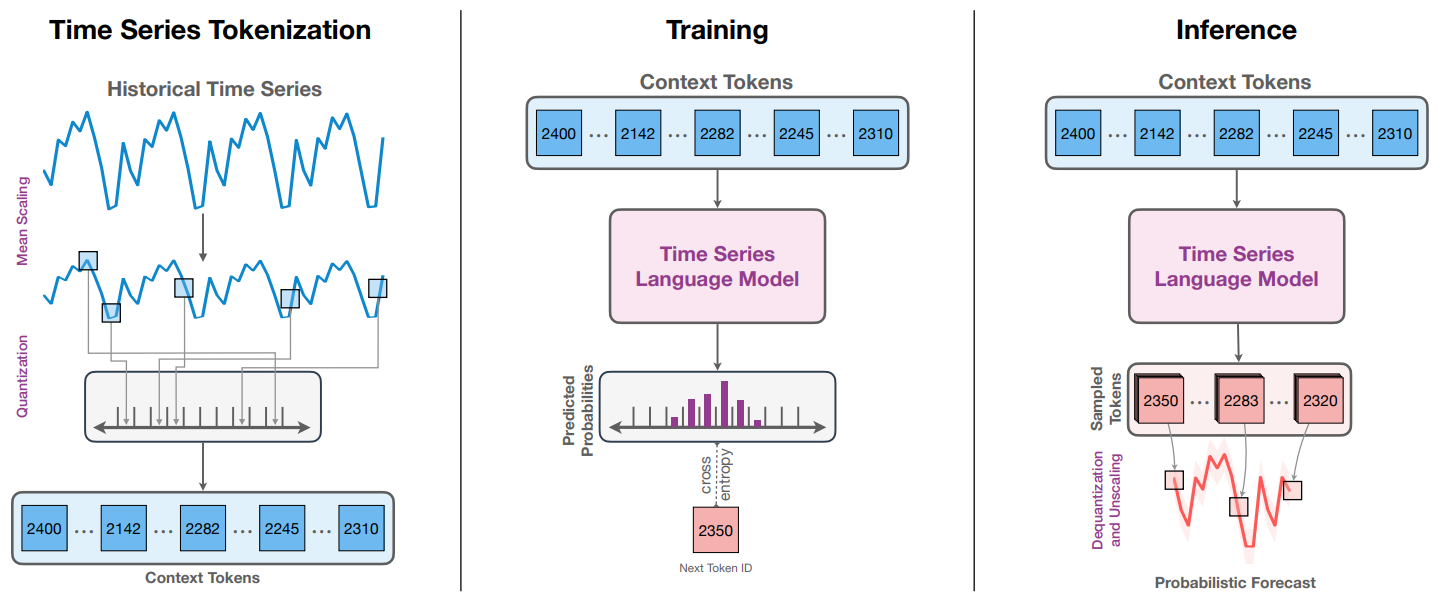
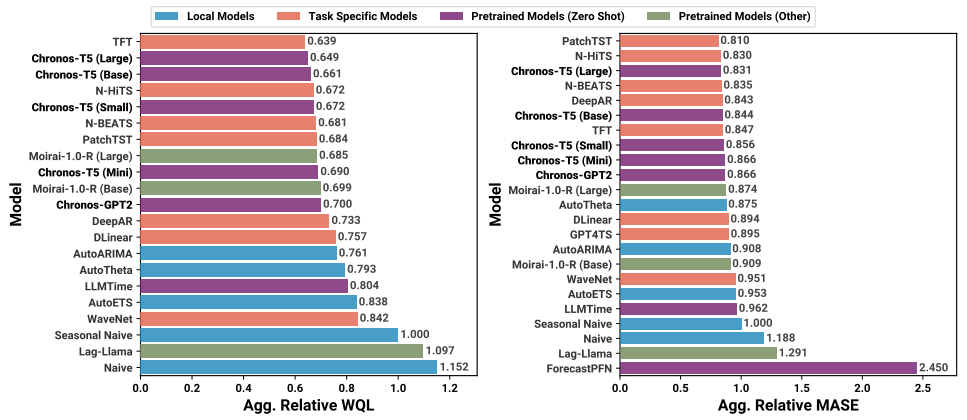
方法:论文提出了一种通用的预训练时间序列预测模型,名为Chronos,该模型基于语言模型框架,并通过简单的缩放和量化将时间序列标记化为离散的标记,以实现对未来模式的预测。实验证明,Chronos模型在训练语料库中的数据集上显著优于其他方法,并表现出良好的零样本性能。
创新点:
-
Chronos将现有的语言模型体系结构和训练过程最小化地适应于时间序列预测,通过简单的缩放和量化处理,将时间序列离散化为离散的标记序列,然后可以使用现成的语言模型在这个“时间序列语言”上进行训练,而无需对模型体系结构进行任何修改。
-
Chronos引入了数据增强策略,包括TSMixup和KernelSynth,来增强模型的鲁棒性和泛化能力。TSMixup从不同训练数据集中随机抽取一组基本时间序列,并根据它们的凸组合生成新的时间序列;KernelSynth使用高斯过程根据随机组合核函数生成合成时间序列。
Timer: Generative Pre-trained Transformers Are Large Time Series Models
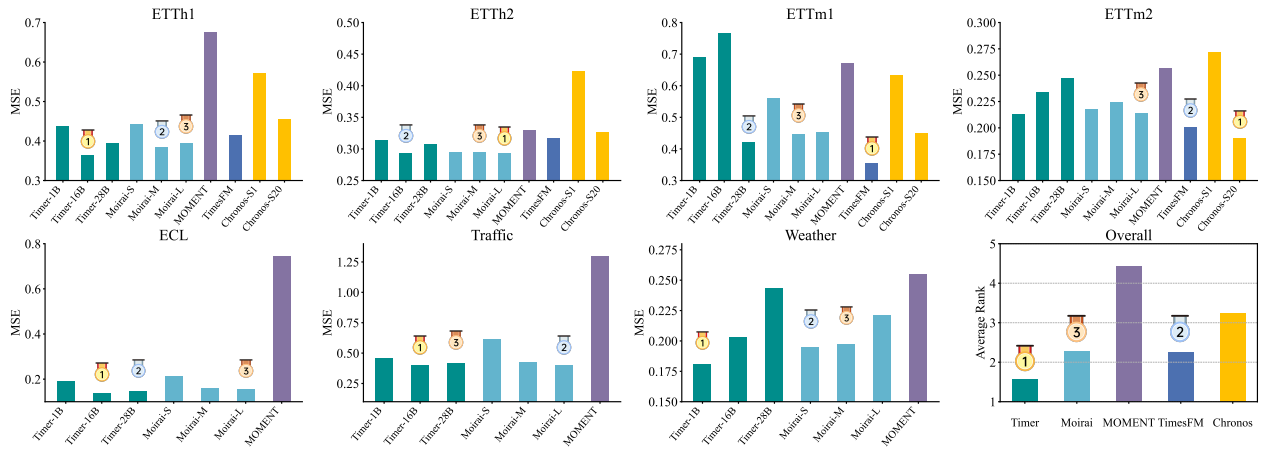
方法:论文提出了一个名为 Timer 的时间序列Transformer,它通过大规模的自回归下一个时间点预测来进行预训练,并针对不同的下游场景进行微调,展现出作为大型时间序列模型(LTSM)的潜力。该模型在大规模时间序列数据上进行了生成式预训练,并在预测、插补和异常检测等任务中展示了优越的性能。
创新点:
-
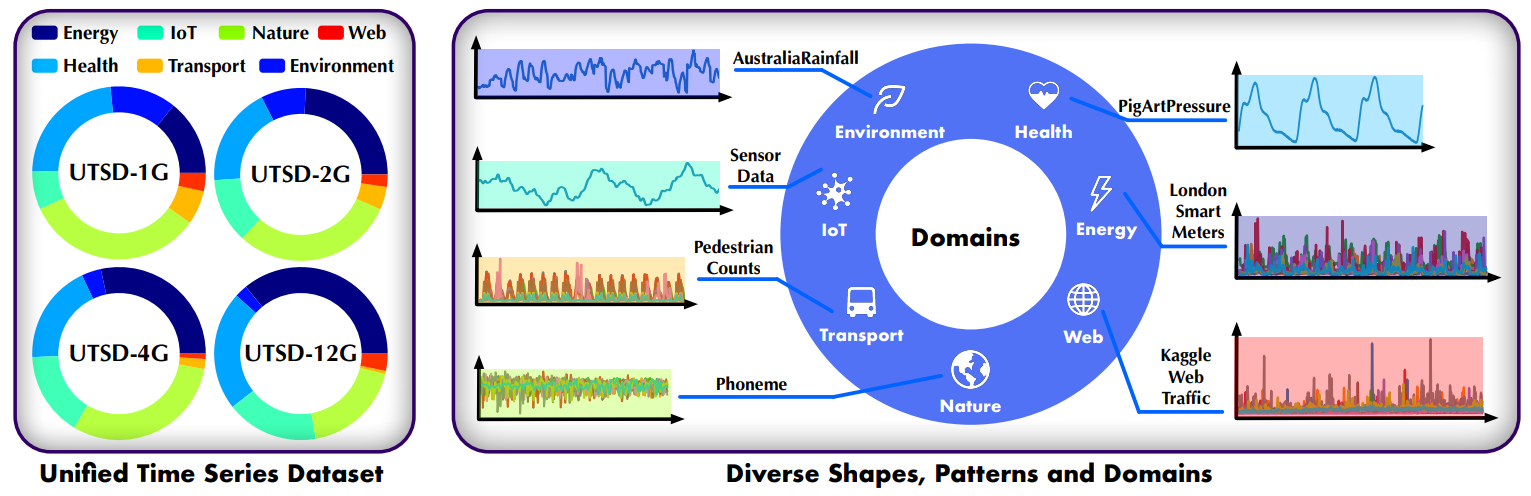
引入了一个新的基准数据集UTSD,该数据集经过精心筛选和处理,包含了多个不同领域和难度的时间序列数据,用于评估模型性能。
-
提出了一种新的时间序列预训练模型Timer,该模型基于Transformer架构,通过生成下一个时间序列标记来进行预训练。
-
建立了大规模时间序列预训练的评估标准,包括模型大小和数据规模的影响,并与其他先进的时间序列模型进行了比较。
Bidirectional Generative Pre-training for Improving Time Series Representation Learning
方法:论文提出了一种新颖的架构,名为BiTimelyGPT,这是一种用于时间序列数据的预训练模型,通过双向的下一个和上一个时间步的预测任务来改善时间序列的表示学习。
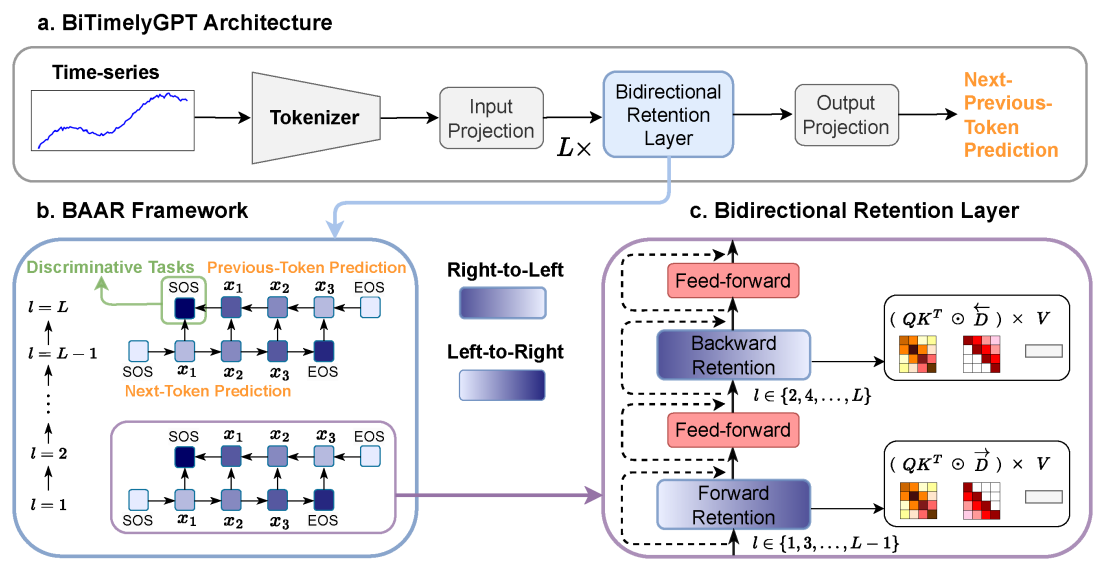
创新点:
-
提出了一种新的预训练策略BiTimelyGPT,通过整合双向性到生成式预训练中,改进了时间序列表示学习。该方法引入了一种新的Next-Previous-Token Prediction预训练任务,保持了原始数据分布和时间序列的形状,而无需进行任何数据修改。
-
提出了一种新的双向交替自回归模型(BAAR)框架,在层间交替建模从左到右和从右到左的信息,学习深层双向上下文用于判别任务。
-
提出的BiTimelyGPT中的前向和后向注意力矩阵都是满秩的,具有表达能力强的表示能力。

关注下方《学姐带你玩AI》🚀🚀🚀
回复“时序预训练”获取全部论文+开源代码
码字不易,欢迎大家点赞评论收藏