🎁🎁创作不易,关注作者不迷路🎀🎀
目录
🌸完整代码
🌸分析
🎁基本思路
🎁需要的库
🎁提取图片的链接和标题
👓寻找Cookie和User-Agent
👓图片链接和标题
🎁下载保存图片
🎁获取目录页面图片和翻页提取
👓目录页图片的提取
👓翻页规律寻找
🌸运行效果
🌸文末彩蛋🎀

我们经常想要寻找一些高清的壁纸,图片作为素材(为CSDN博客找一张吸引读者的封面🤣),然而一张一张的下载太慢了,因此为了提高工作效率, 我们可以采用爬虫的方式,快速下载图片。
🌸完整代码
import os#导入操作系统的库
import requests #导入HTTP库
from lxml import etree#导入lxml库,数据解析
global num
num=1
#请求头,伪装爬虫
header={
'user-agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36 Edg/127.0.0.0',
'cookie':
'zkhanecookieclassrecord=%2C66%2C70%2C'
}
#获取具体的图片的地址和名字信息
# url='https://pic.netbian.com/tupian/34694.html'
def get_pic(url,header):
re=requests.get(url,headers=header)
re.encoding=re.apparent_encoding#获取html文本时用网页原有的编码方式,防止乱码
#print(re.apparent_encoding) #返回的编码
html=etree.HTML(re.text)
link=html.xpath('//div[@class="photo-pic"]/a/img/@src')[0]#获取图片链接
link='https://pic.netbian.com'+link
print(link)
title=html.xpath('//div[@class="photo-pic"]/a/img/@title')[0]#获取图片名称
print(title)
return title,link
#下载保存图片
def download_pic(url,header):
global num
title,link=get_pic(url,header)
if not os.path.exists(r"C:\Users\liu\Desktop\图片\4K壁纸"):#未找到文件夹则创建文件夹
os.mkdir(r"C:\Users\liu\Desktop\图片\4K壁纸")
content=requests.get(link,headers=header).content
with open(rf"C:\Users\liu\Desktop\图片\4K壁纸\{str(num)}.jpg",'wb') as f:#以二进制编码写入文件
f.write(content)
num += 1
#目录翻页提取链接
def get_content_link(url,header):
# url='https://pic.netbian.com/pingban/index.html'
re=requests.get(url,headers=header)
re.encoding=re.apparent_encoding
# print(re.text)
html=etree.HTML(re.text)
links=html.xpath('//div[@class="slist"]//a/@href')
for x in links:
x='https://pic.netbian.com'+x
download_pic(x,header)
#循环遍历网页,处理信息
for i in range(1,24):
if i==1:
url='https://pic.netbian.com/pingban/index.html'
else :
url=f'https://pic.netbian.com/pingban/index_{i}.html'
get_content_link(url,header)🌸分析
🎁基本思路
- 找到图片页网页源代码
- 提取所有图片的链接和标题
- 下载保存图片
- 爬取目录页的网页源代码
- 下载目录页的图片
- 分析不同页面的地址变化,找出规律实现翻页下载
🎁需要的库
import os
import requests
from lxml import etreerequests和lxml库是第三方库,需要自己安装
🎁提取图片的链接和标题
👓寻找Cookie和User-Agent
首先打开页面,打开开发者工具,按Ctrl+R刷新页面,点击开发者工具的“网络”选项,点击第一份文件,查看请求地址,Cookie和User-Agent



将Cookie和User-Agent作为请求头
header={
'user-agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36 Edg/127.0.0.0',
'cookie':
'zkhanecookieclassrecord=%2C66%2C70%2C'
}👓图片链接和标题

这里需要用到lxml库以及xpath的知识,看图说话,链接和地址存在<div class="photo-pic">下的a元素中img元素中的src属性和title属性
图片链接
link=html.xpath('//div[@class="photo-pic"]/a/img/@src')[0]#获取图片链接图片标题
title=html.xpath('//div[@class="photo-pic"]/a/img/@title')[0]#获取图片名称写成函数方便调用
#获取具体的图片的地址和名字信息
# url='https://pic.netbian.com/tupian/34694.html'
def get_pic(url,header):
re=requests.get(url,headers=header)
re.encoding=re.apparent_encoding#获取html文本时用网页原有的编码方式,防止乱码
#print(re.apparent_encoding) #返回的编码
html=etree.HTML(re.text)
link=html.xpath('//div[@class="photo-pic"]/a/img/@src')[0]#获取图片链接
link='https://pic.netbian.com'+link
print(link)
title=html.xpath('//div[@class="photo-pic"]/a/img/@title')[0]#获取图片名称
print(title)
return title,link🎁下载保存图片
存储到一个新的文件夹“4K壁纸”,如果文件夹不存在,需要创建,这里要用到os库
#未找到文件夹则创建文件夹
if not os.path.exists(r"C:\Users\liu\Desktop\图片\4K壁纸"):
os.mkdir(r"C:\Users\liu\Desktop\图片\4K壁纸")写入文件
content=requests.get(link,headers=header).content
with open(rf"C:\Users\liu\Desktop\图片\4K壁纸\{str(num)}.jpg",'wb') as f:#以二进制编码写入文件
f.write(content)写成函数方便调用
#下载保存图片
def download_pic(url,header):
global num
title,link=get_pic(url,header)
if not os.path.exists(r"C:\Users\liu\Desktop\图片\4K壁纸"):#未找到文件夹则创建文件夹
os.mkdir(r"C:\Users\liu\Desktop\图片\4K壁纸")
content=requests.get(link,headers=header).content
with open(rf"C:\Users\liu\Desktop\图片\4K壁纸\{str(num)}.jpg",'wb') as f:#以二进制编码写入文件
f.write(content)
num += 1🎁获取目录页面图片和翻页提取
上面我们实现一张图片的保存,写了十几行代码算是成功保存了🤣🤣🤣,一张图片干嘛这么麻烦捏😂,直接点击“图片另存为”不就行了吗,那如果是很多图片吗,那肯定是爬虫更快了呗
👓目录页图片的提取
依然用到lxml库,利用xpath语法提取

#目录翻页提取链接
def get_content_link(url,header):
# url='https://pic.netbian.com/pingban/index.html'
re=requests.get(url,headers=header)
re.encoding=re.apparent_encoding
# print(re.text)
html=etree.HTML(re.text)
links=html.xpath('//div[@class="slist"]//a/@href')
for x in links:
x='https://pic.netbian.com'+x
download_pic(x,header)👓翻页规律寻找
📕找到第一页目录页
https://pic.netbian.com/pingban/index.html📕找到第二页目录页
https://pic.netbian.com/pingban/index_2.html📕找到第三页目录页
https://pic.netbian.com/pingban/index_3.html发现规律:第一页单独列出来,其他页通过for循环改变index_{i}即可
#循环遍历网页,处理信息
for i in range(1,24):
if i==1:
url='https://pic.netbian.com/pingban/index.html'
else :
url=f'https://pic.netbian.com/pingban/index_{i}.html'
get_content_link(url,header)通过for循环遍历,最终可以实现所有图片的下载
🌸运行效果
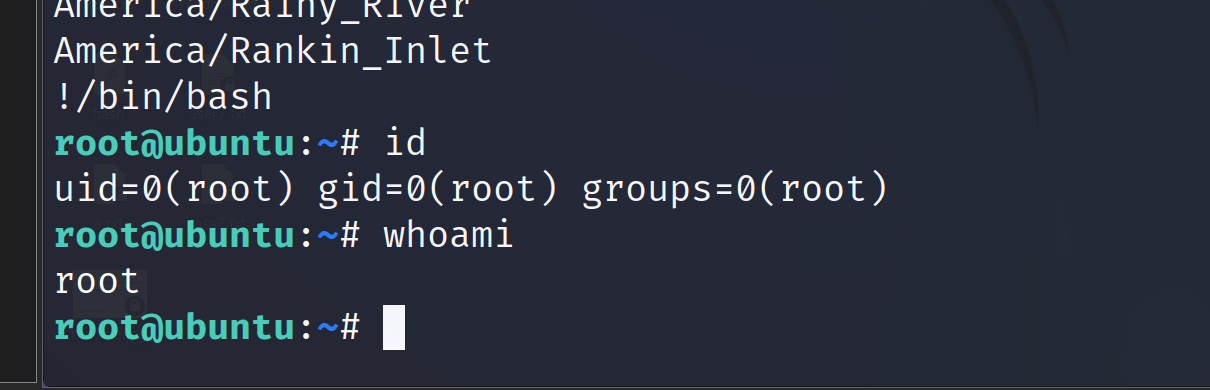
成功下载4K壁纸,耗时两分半🐔,下载400多张图片,爬虫提取就是快,手动提取预估一坤时左右🐔


🌸文末彩蛋🎀