目录
文章目录
- 目录
- 网络剪枝——network-slimming 项目复现
- clone 存储库
- Baseline
- vgg
- 训练
- 结果
- resnet
- 训练
- 结果
- densenet
- 训练
- 结果
- Sparsity
- vgg
- 训练
- 结果
- resnet
- 训练
- 结果
- densenet
- 训练
- 结果
- Prune
- vgg
- 命令
- 结果
- resnet
- 命令
- 结果
- densenet
- 命令
- 结果
- Fine-tune
- vgg
- 训练
- 结果
- resnet
- 训练
- 结果
- densenet
- 训练
- 结果
- 模型大小计算脚本 param_counter.py
- 结果汇总
- CIFAR10
网络剪枝——network-slimming 项目复现
- 【GiHnub】:Eric-mingjie/network-slimming: Network Slimming (Pytorch) (ICCV 2017) (github.com)
- 【作者复现项目】:
- 通过百度网盘分享的文件:network-slimming-regin.zip
链接:https://pan.baidu.com/s/1vTJSLS5ZDjE8R8XaApW96A?pwd=t1z2
提取码:t1z2- 仅以 CIFAR-10 为例,CIFAR-100 同理.
- 提供中文README_zh-CN.md.
- 包含 CIFAR-10/100 数据集data.cifar10、data.cifar100.
- 解决了 main.py 运行报错问题.
- 加入了计算训练后模型的 Parameters 大小脚本param_counter.py.
clone 存储库
注:若 clone 作者复现项目,则忽略这一步,直接进入下一步;若想自行从头复现,则 clone 以下存储库.
-
链接:https://pan.baidu.com/s/1nppPLKoiPbJPW60HOa2TxQ?pwd=ud89
提取码:ud89
Baseline
vgg
训练
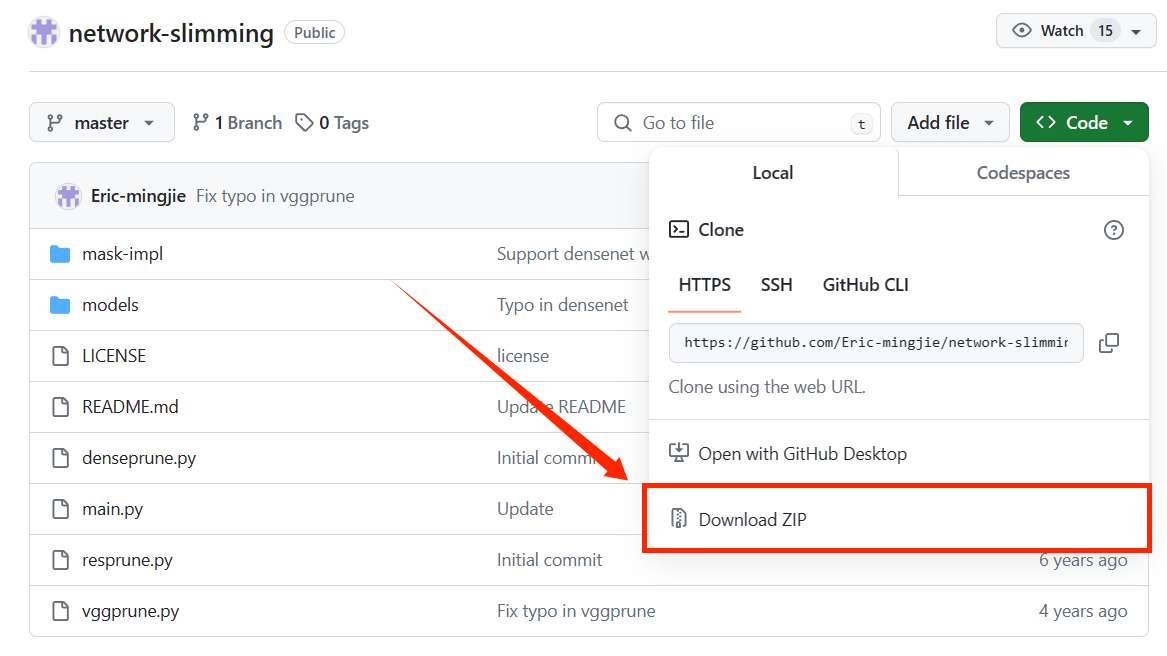
- 【命令】:
python main.py --dataset cifar10 --arch vgg --depth 19
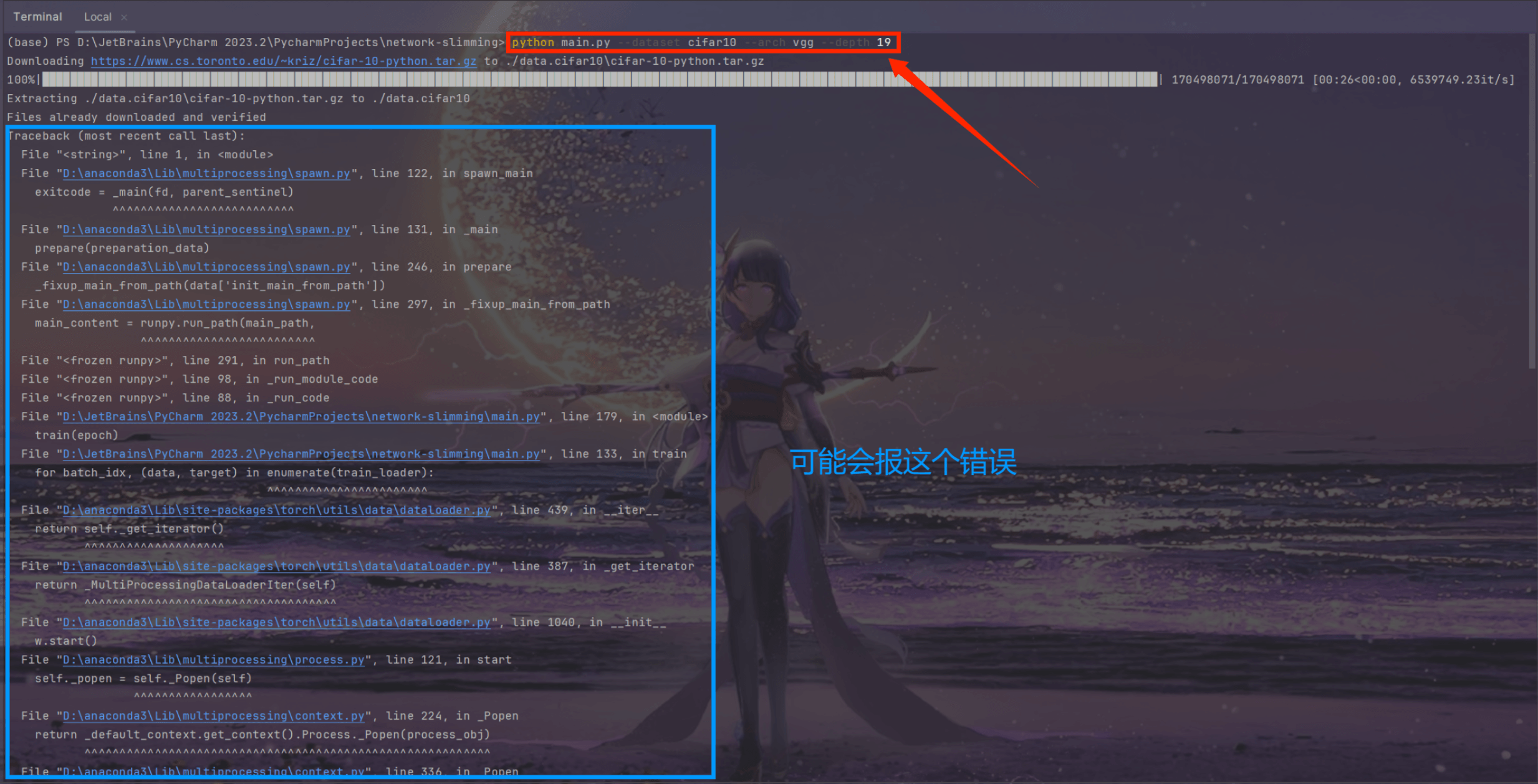
- 这个报错通常出现在使用 Python 的
multiprocessing库来创建进程时,尤其是在 Windows 操作系统上. 在 Windows 上,Python 的multiprocessing模块启动新进程的方式与 Linux 或 macOS 不同,它使用 “spawn” 来启动新进程,这意味着每个子进程都会从头开始执行脚本. 因此,如果在脚本顶层级别启动进程(而不是在受保护的if __name__ == '__main__':块中),每个子进程都会尝试再次启动子进程,从而导致无限递归和上述错误.
- 为了解决这个问题,应 确保多进程代码(即main.py)位于
if __name__ == '__main__':保护块内.
# 导入部分
...
def main():
...
if __name__ == '__main__':
main()
- 再次运行命令,又报错:
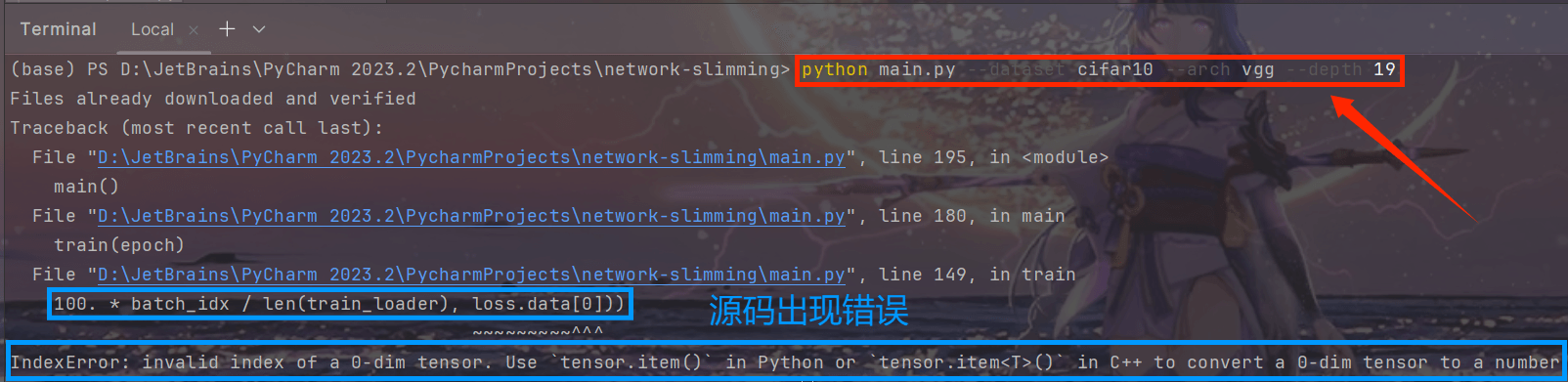
- 这个报错通常发生在尝试直接索引一个0维的张量(tensor)时. 在 PyTorch 中,0 维张量是一个单一值的张量,但是不能像普通的数组那样通过索引来访问。要从 0 维张量中获取其 Python 数值,需要使用
.item()方法.
- 为了解决这个问题,应该 使用
.item()方法来替换所有.data[0]的用法:
# 在 train 函数中
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.1f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
# 在 test 函数中
for data, target in test_loader:
if args.cuda:
data, target = data.cuda(), target.cuda()
data, target = Variable(data), Variable(target)
output = model(data)
test_loss += F.cross_entropy(output, target, reduction='sum').item() # sum up batch loss
pred = output.data.max(1, keepdim=True)[1]
correct += pred.eq(target.data.view_as(pred)).cpu().sum()
test_loss /= len(test_loader.dataset)
- 再次运行命令就正常运行了:

结果
- Terminal:
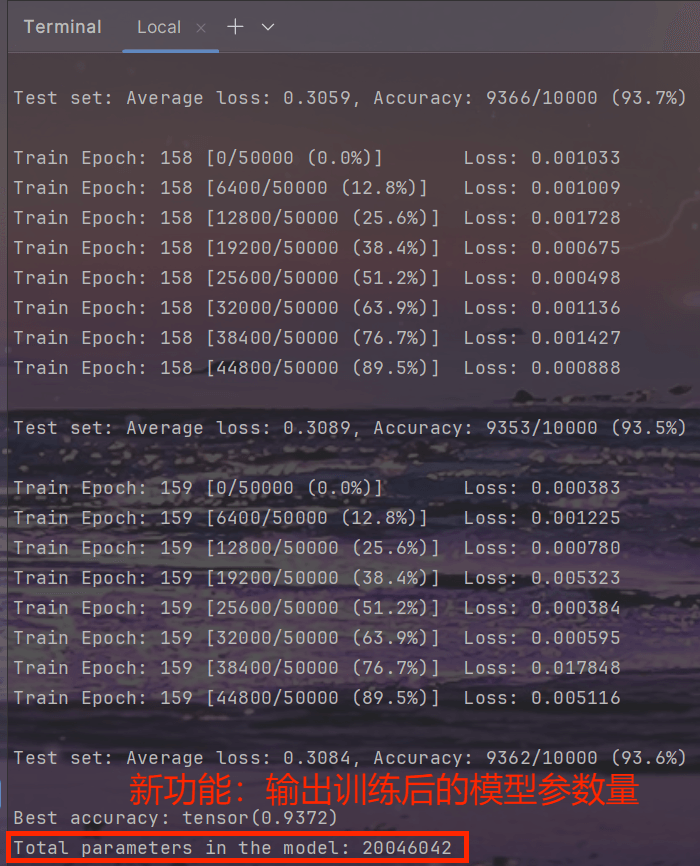
- 在 ./logs 生成文件:checkpoint.pth.tar、model_best.pth.tar
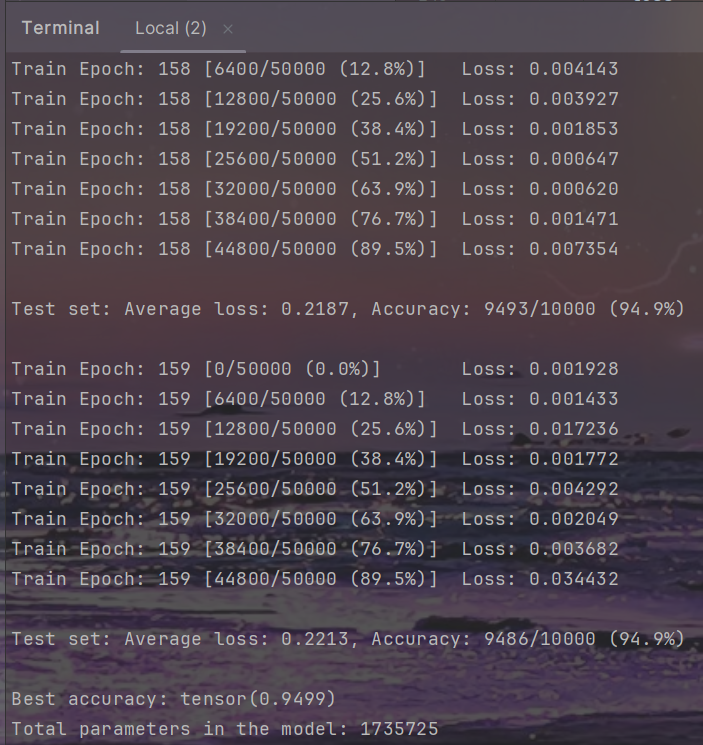
resnet
训练
- 【命令】:
python main.py --dataset cifar10 --arch resnet --depth 164
结果
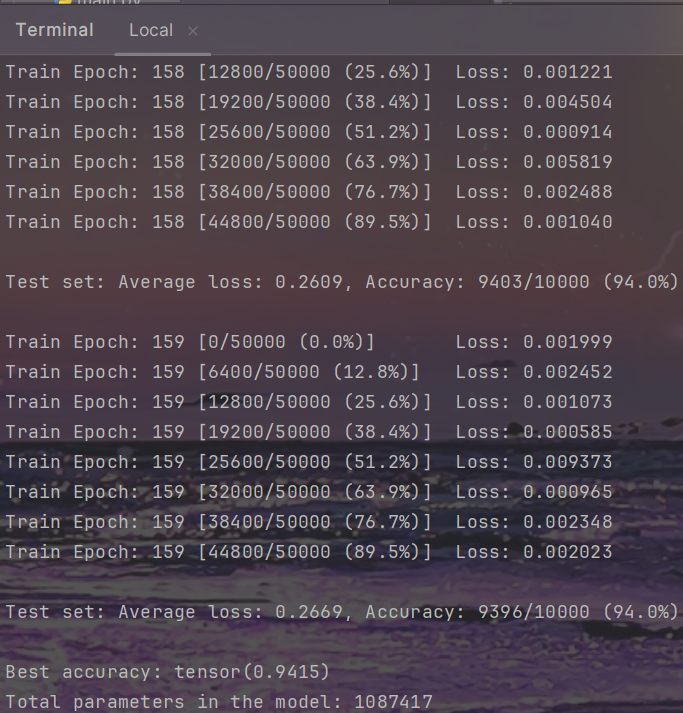
densenet
训练
- 【命令】:
python main.py --dataset cifar10 --arch densenet --depth 40
结果
Sparsity
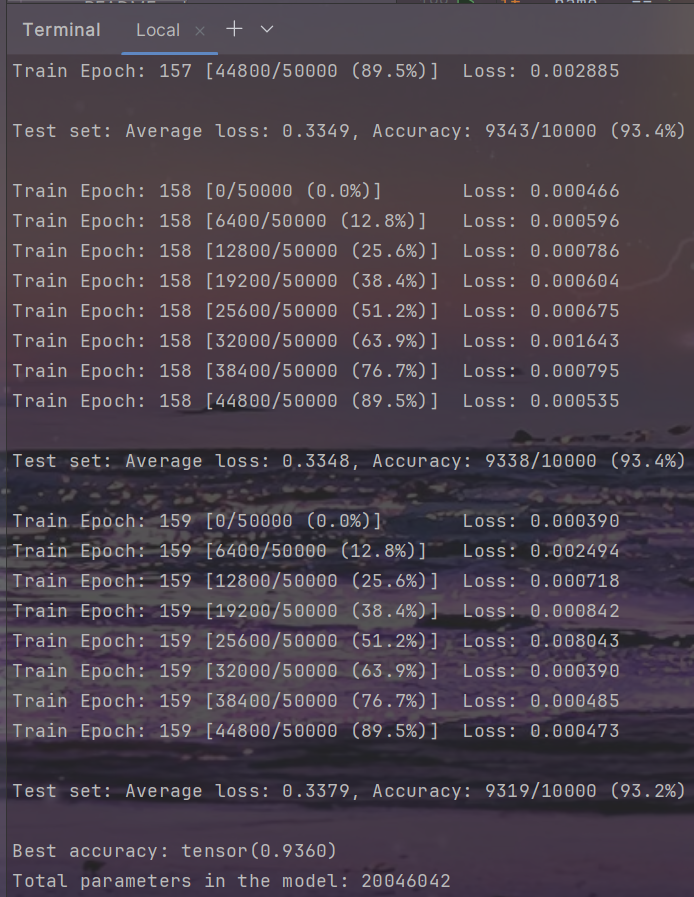
vgg
训练
- 【命令】:
python main.py -sr --s 0.0001 --dataset cifar10 --arch vgg --depth 19
结果
resnet
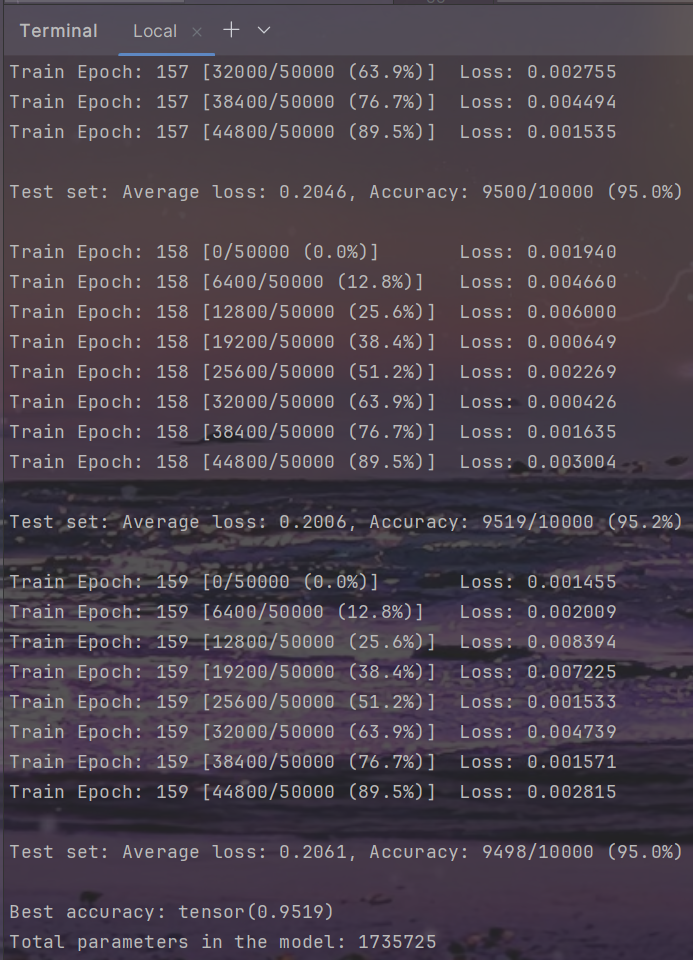
训练
- 【命令】:
python main.py -sr --s 0.00001 --dataset cifar10 --arch resnet --depth 164
结果
densenet
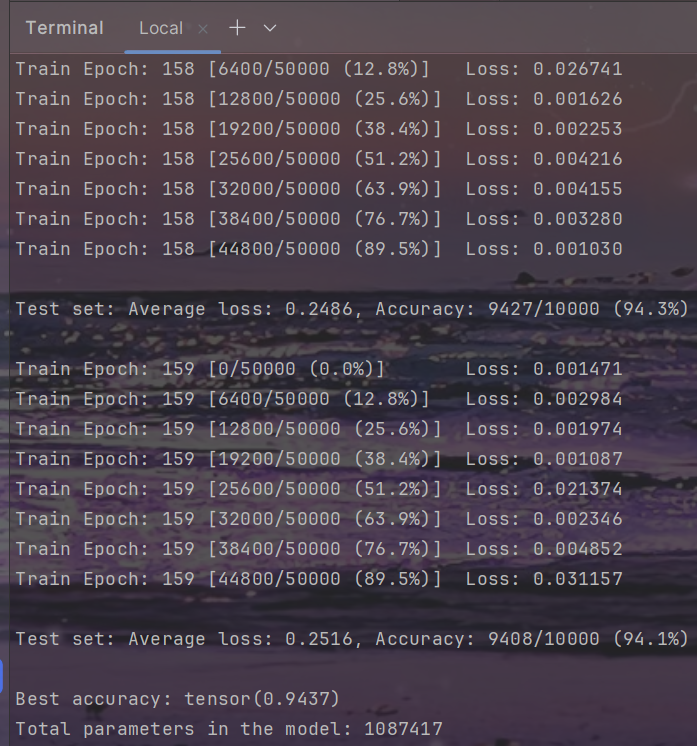
训练
- 【命令】:
python main.py -sr --s 0.00001 --dataset cifar10 --arch densenet --depth 40
结果
Prune
vgg
命令
python vggprune.py --dataset cifar10 --depth 19 --percent 0.7 --model ./results/CIFAR10_results/CIFAR10-Vgg/Sparsity/model_best.pth.tar --save ./prunes
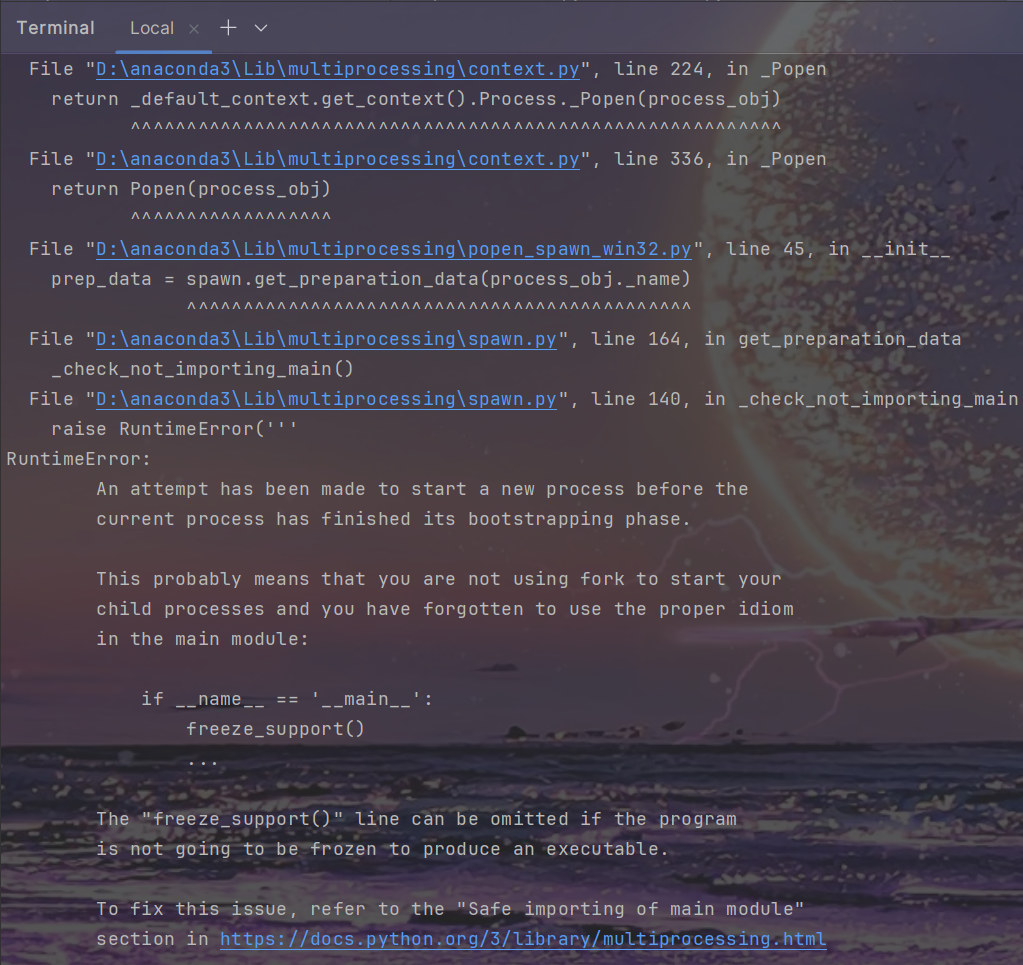
- 与main.py同理,为了解决这个问题,应 确保多进程代码位于
if __name__ == '__main__':保护块内:
# 导入部分
...
def main():
...
if __name__ == '__main__':
main()
- 之后就可以正常运行了.
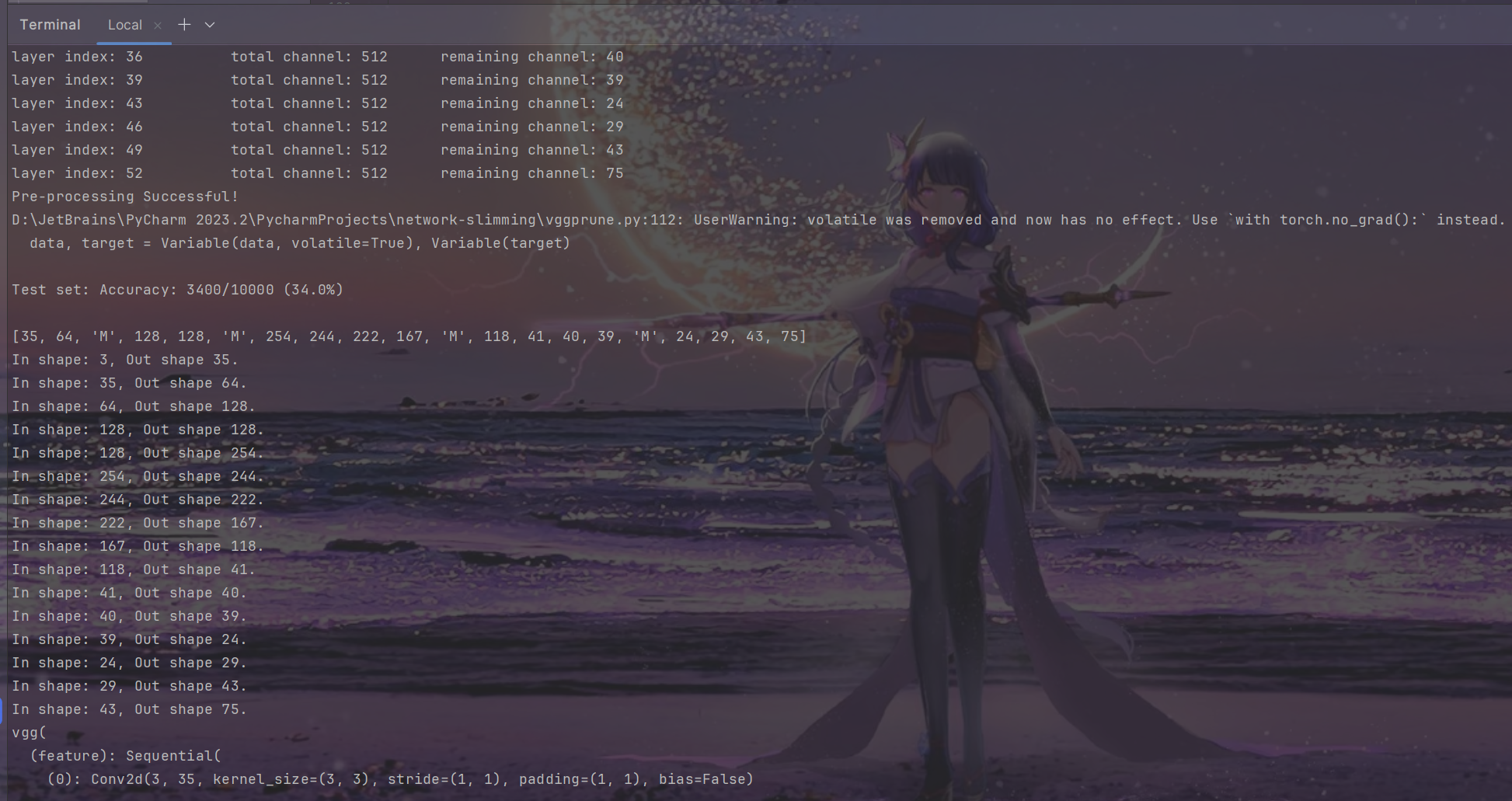
结果
- Terminal:
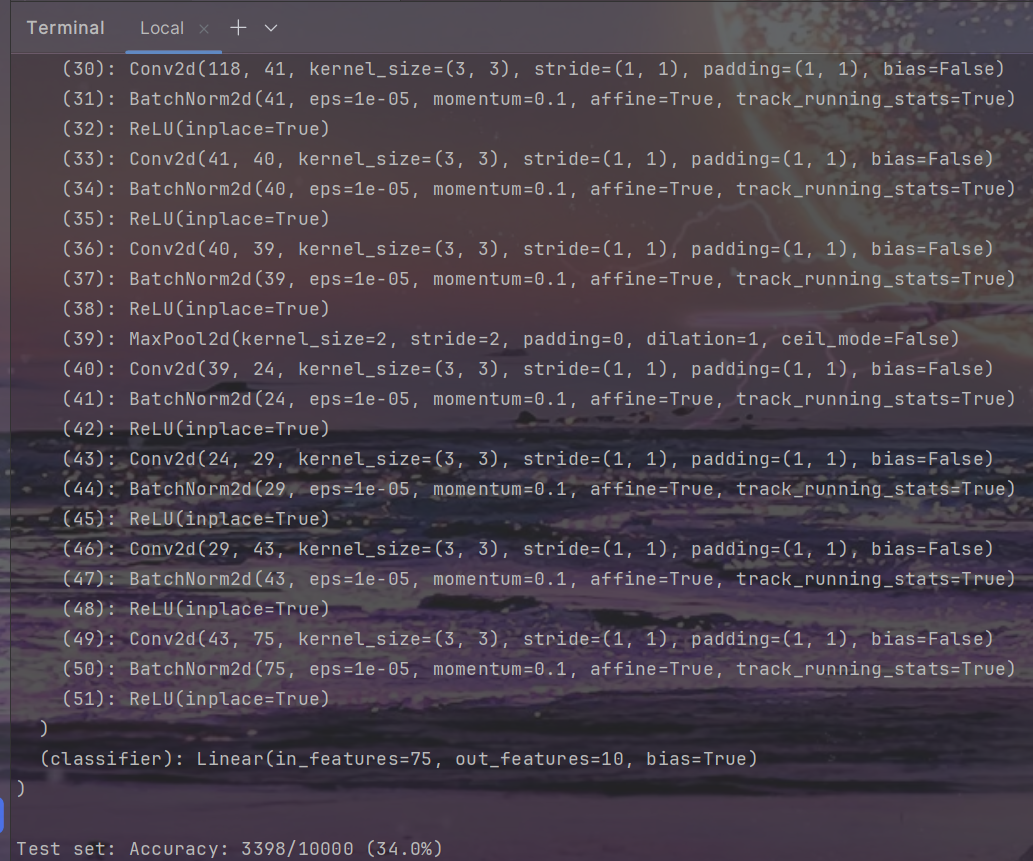
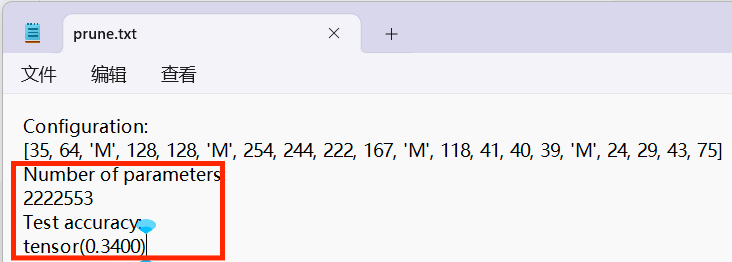
- 在./prunes生成文件:prune.txt、pruned.pth.tar

- 在prune.txt中我们可以看到 Number of parameters、Test accuracy:
resnet
命令
python resprune.py --dataset cifar10 --depth 164 --percent 0.4 --model ./results/CIFAR10_results/CIFAR10-Resnet-164/Sparsity/model_best.pth.tar --save ./prunes
结果
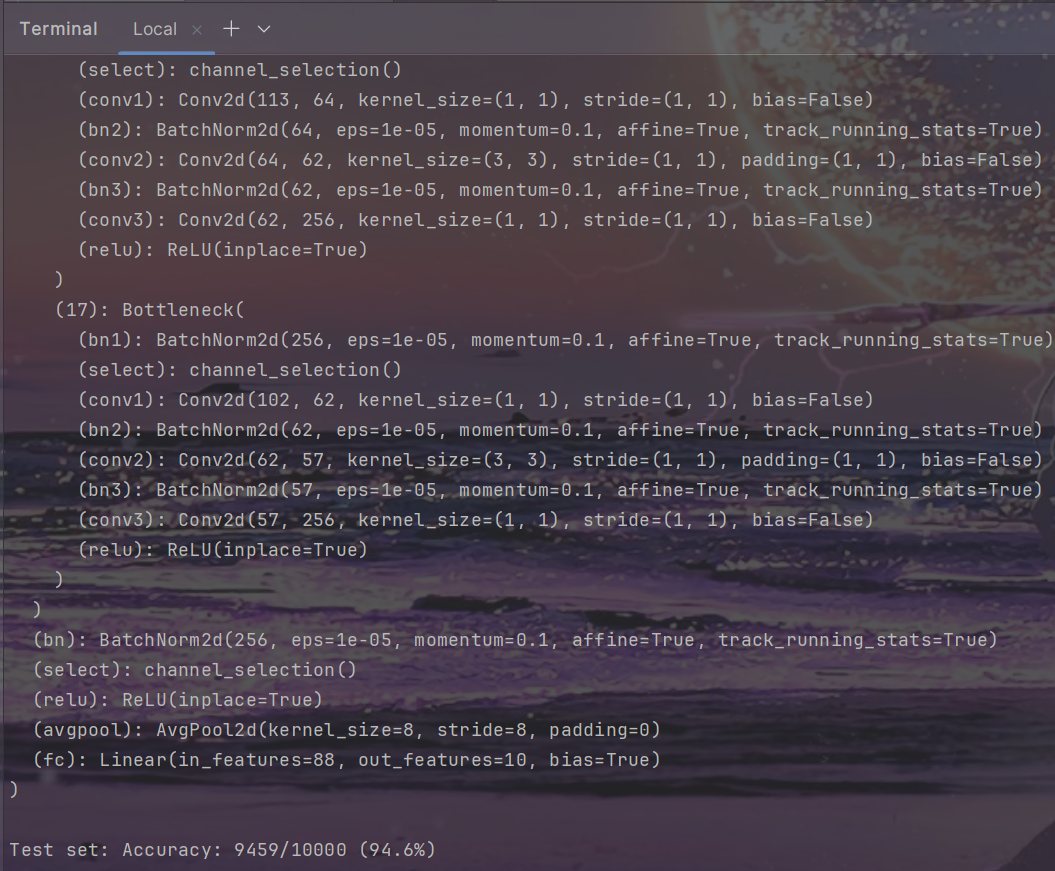
densenet
命令
python denseprune.py --dataset cifar10 --depth 40 --percent 0.4 --model ./results/CIFAR10_results/CIFAR10-Densenet-40/Sparsity/model_best.pth.tar --save ./prunes
结果
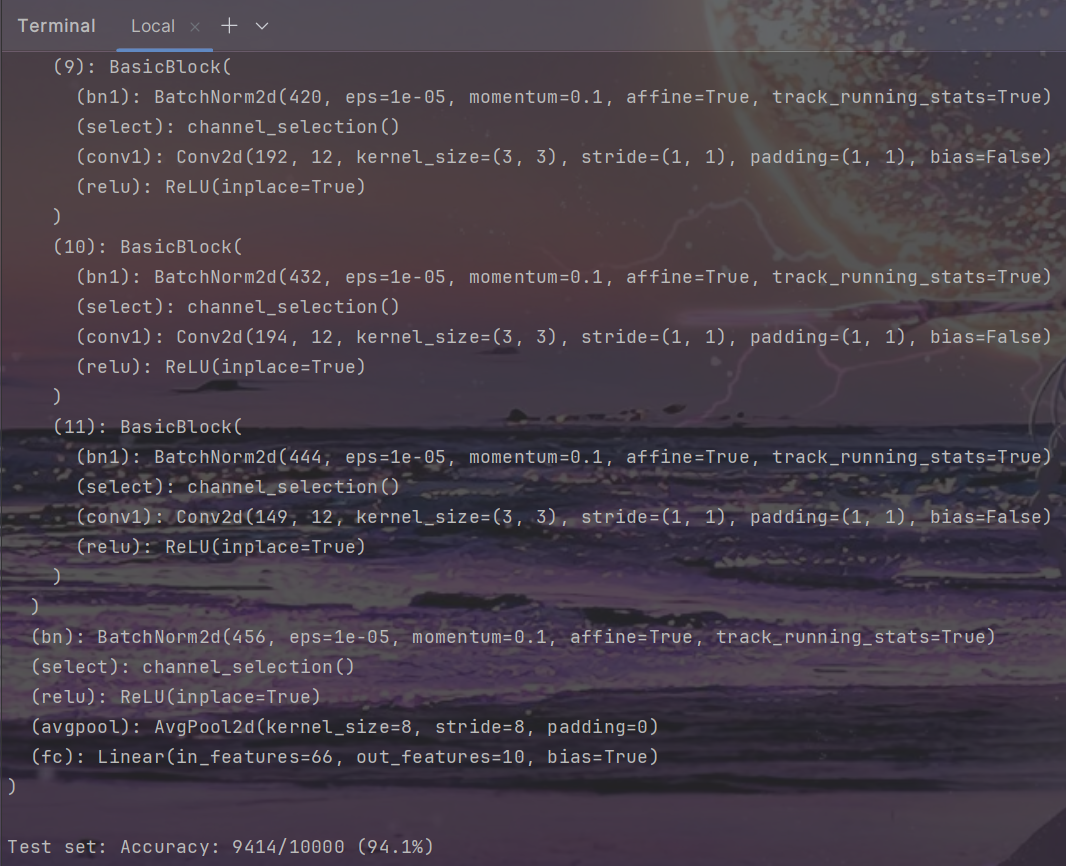
Fine-tune
vgg
训练
- 【命令】:
python main.py --refine ./results/CIFAR10_results/CIFAR10-Vgg/Prune/pruned.pth.tar --dataset cifar10 --arch vgg --depth 19 --epochs 160
结果
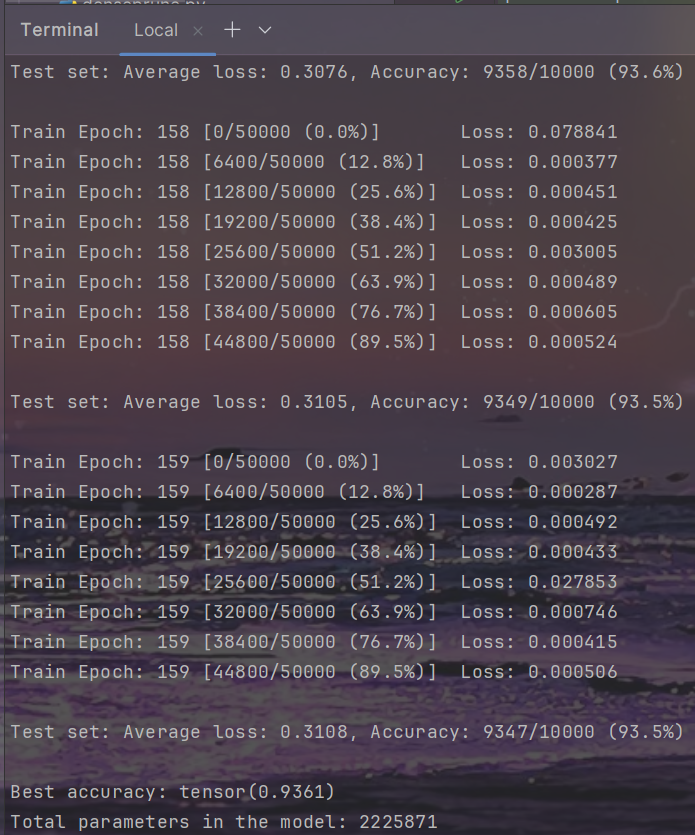
resnet
训练
- 【命令】:
python main.py --refine ./results/CIFAR10_results/CIFAR10-Resnet-164/Prune/pruned.pth.tar --dataset cifar10 --arch resnet --depth 164 --epochs 160
结果
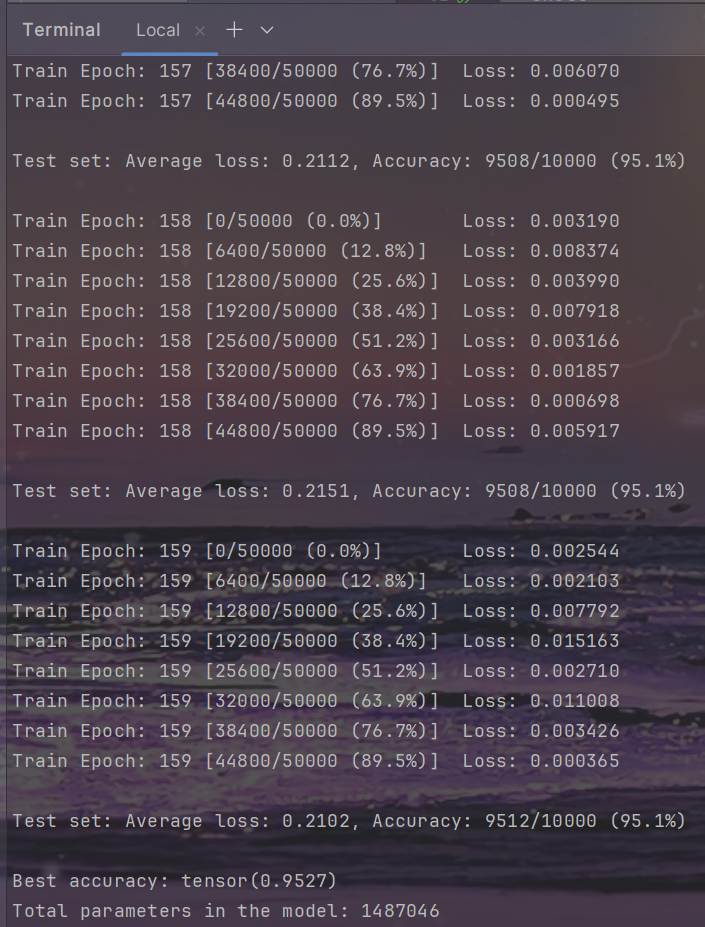
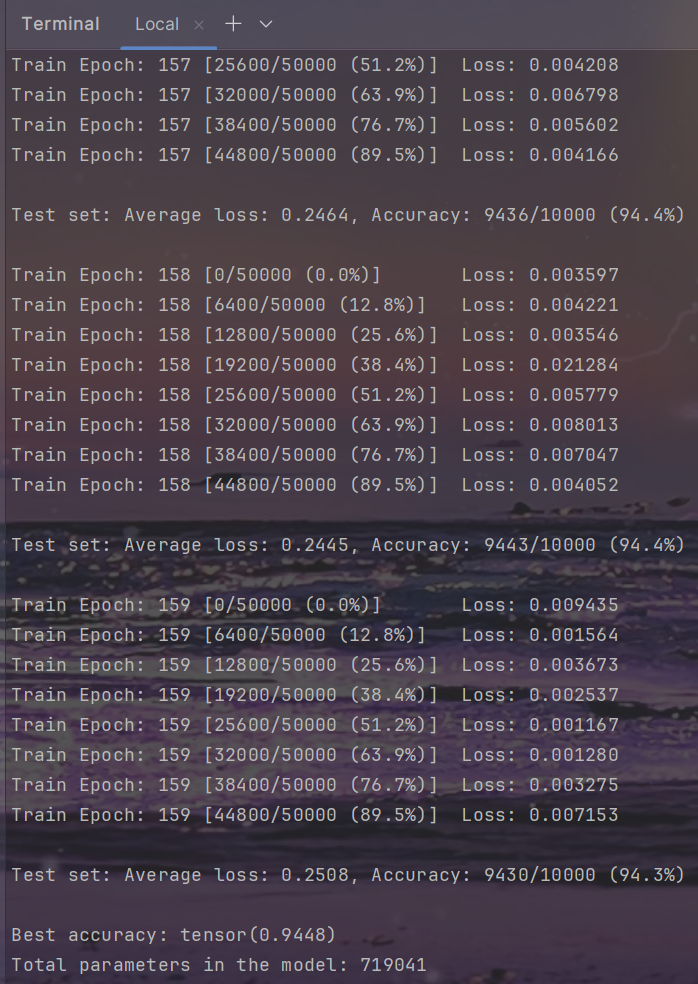
densenet
训练
- 【命令】:
python main.py --refine ./results/CIFAR10_results/CIFAR10-Densenet-40/Prune/pruned.pth.tar --dataset cifar10 --arch densenet --depth 40 --epochs 160
结果
模型大小计算脚本 param_counter.py
- 【路径】:./script/param_counter.py
import torch
def load_model(model_path):
model = torch.load(model_path, map_location=torch.device('cpu'))
return model
def count_parameters(model_state_dict):
total_params = sum(p.numel() for p in model_state_dict.values())
return total_params
def get_model_parameters(model_path):
# 加载模型状态字典
model = load_model(model_path)
# 模型状态字典存储在 'state_dict' 键下
model_state_dict = model['state_dict'] if 'state_dict' in model else model
# 计算参数总数
total_params = count_parameters(model_state_dict)
return total_params
- 在main.py中:
from script.param_counter import get_model_parameters
def main():
...
# 计算 Parameters
model_path = 'logs/model_best.pth.tar'
total_params = get_model_parameters(model_path)
print(f'Total parameters in the model: {total_params}')
结果汇总
注:与原项目结果略有差别.
CIFAR10
| CIFAR10-Vgg | Baseline | Sparsity(1e-4) | Prune(70%) | Fine-tune-160(70%) |
|---|---|---|---|---|
| Top1 Accuracy(%) | 93.72 | 93.60 | 33.98 | 93.75 |
| Parameters | 20.05M | 20.05M | 2.22M | 2.23M |
| CIFAR10-Resnet-164 | Baseline | Sparsity(1e-5) | Prune(40%) | Fine-tune-160(40%) |
|---|---|---|---|---|
| Top1 Accuracy(%) | 94.99 | 95.00 | 94.59 | 95.27 |
| Parameters | 1.74M | 1.74M | 1.46M | 1.49M |
| CIFAR10-Densenet-40 | Baseline | Sparsity(1e-5) | Prune(40%) | Fine-tune-160(40%) |
|---|---|---|---|---|
| Top1 Accuracy(%) | 94.15 | 94.37 | 94.14 | 94.48 |
| Parameters | 1.09M | 1.09M | 0.70M | 0.72M |