项目简介:
小李哥将继续每天介绍一个基于亚马逊云科技AWS云计算平台的全球前沿AI技术解决方案,帮助大家快速了解国际上最热门的云计算平台亚马逊云科技AWS AI最佳实践,并应用到自己的日常工作里。
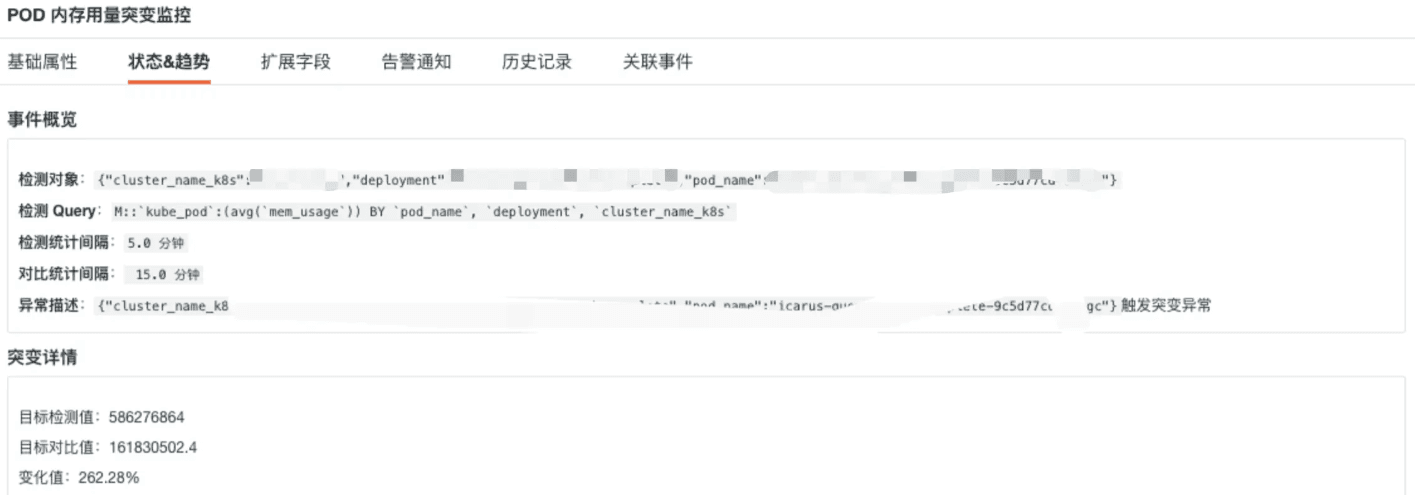
本次介绍的是如何安全、合规、私密地调用亚马逊云科技大模型托管服务Amazon Bedrock,本架构将在私有网络环境VPC中创建VPC网络节点,将AI大模型的访问请求路由至私有网络节点,在通过亚马逊云科技底层私有连接PrivateLink将请求传输到Amazon Bedrock大模型的API生成内容回复,以提升大模型交互过程中数据的隐私性和安全性。本架构设计全部采用了云原生Serverless架构,提供可扩展和安全的AI解决方案。本方案的解决方案架构图如下:

方案所需基础知识
什么是 Amazon Bedrock?
Amazon Bedrock 是亚马逊云科技提供的一项服务,旨在帮助开发者轻松构建和扩展生成式 AI 应用。Bedrock 提供了访问多种强大的基础模型(Foundation Models)的能力,支持多种不同大模型厂商的模型,如AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, 和Amazon,用户可以使用这些模型来创建、定制和部署各种生成式 AI 应用程序,而无需从头开始训练模型。Bedrock 支持多个生成式 AI 模型,包括文本生成、图像生成、代码生成等,简化了开发流程,加速了创新。
什么是亚马逊云科技 PrivateLink?
亚马逊云科技 PrivateLink 是一项网络服务,允许用户通过专用网络连接(而非公共互联网)私密访问亚马逊云科技的服务和第三方应用。它确保数据在传输过程中的安全性和隐私性。

通过 PrivateLink 私有访问 Amazon Bedrock 上的 AI 大模型的好处
增强安全性:
通过 PrivateLink,您可以在无需公开互联网访问的情况下,安全地连接到 Amazon Bedrock 上的 AI 大模型,确保数据传输的安全性。
降低延迟:
PrivateLink 提供了更快的网络路径,减少了访问 AI 大模型时的网络延迟,提升了应用的响应速度。
简化网络架构:
无需配置复杂的 VPN 或 NAT,PrivateLink 提供了更简单的网络架构,使得连接 Amazon Bedrock 更加直观和高效。
本方案包括的内容
1. 配置亚马逊云科技PrivateLink私密链接访问Amazon Bedrock上的AI大模型
2. 部署Amazon Lambda无服务器计算服务调用Amazon Bedrock上的AI大模型
3. 在VPC私有网络环境中对Amazon Bedrock、Amazon Lambda和Amazon RDS进行访问测试
项目搭建具体步骤:
1. 首先我们登录亚马逊云科技控制台,确认Amazon Bedrock上的AI大模型“Titan Text G1 - Express”是开启状态。

2. 接下来我们创建一台EC2服务器,部署一个数据库SQL服务器,复制其私有IP地址“10.0.4.23”。

3. 接下来我们创建一个无服务器计算服务Lambda,命名为“invoke_bedrock”,用于API调用Amazon Bedrock上的AI大模型

4. 在Lambda函数中创建一个Python文件“bedrock.py”,复制以下代码
import boto3
import json
from datetime import datetime
import os
model_id = os.environ.get('BEDROCK_MODEL_ID')
def test_bedrock():
model_id = os.environ.get('BEDROCK_MODEL_ID')
prompt_data = "What is the envelope budget method?"
r = call_bedrock(model_id, prompt_data)
return("""
\n\n\n
Model latency: %s\n
Response:\n
%s
\n\n\n
""" % (r['latency'],r['response'])
)
def call_bedrock(model_id, prompt_data):
bedrock_runtime = boto3.client('bedrock-runtime')
body = json.dumps({
"inputText": prompt_data,
"textGenerationConfig":
{
"maxTokenCount":1000,
"stopSequences":[],
"temperature":0.7,
"topP":0.9
}
})
accept = 'application/json'
content_type = 'application/json'
before = datetime.now()
response = bedrock_runtime.invoke_model(body=body, modelId=model_id, accept=accept, contentType=content_type)
latency = (datetime.now() - before).seconds
response_body = json.loads(response.get('body').read())
response = response_body.get('results')[0].get('outputText')
return {
'latency': str(latency),
'response': response
}
def json_to_pretty_table(json_data):
data = json.loads(json_data)
table = PrettyTable()
# Assuming all rows have the same keys
headers = data['rows'][0].keys()
table.field_names = headers
for row in data['rows']:
table.add_row(row.values())
return table
def generate_budget_report(customer_data):
prompt_data = f"""
Using the spending data in the table bellow, aggregate the spending by category and provide the total for each category.
Customer Spending Table:
%s
""" % (customer_data)
r = call_bedrock(model_id,prompt_data)
return r['response']
5. 再创建一个Python文件复制以下代码,命名为“db.py”,用于数据库访问
import boto3
import json
from datetime import datetime
import os
model_id = os.environ.get('BEDROCK_MODEL_ID')
def test_bedrock():
model_id = os.environ.get('BEDROCK_MODEL_ID')
prompt_data = "What is the envelope budget method?"
r = call_bedrock(model_id, prompt_data)
return("""
\n\n\n
Model latency: %s\n
Response:\n
%s
\n\n\n
""" % (r['latency'],r['response'])
)
def call_bedrock(model_id, prompt_data):
bedrock_runtime = boto3.client('bedrock-runtime')
body = json.dumps({
"inputText": prompt_data,
"textGenerationConfig":
{
"maxTokenCount":1000,
"stopSequences":[],
"temperature":0.7,
"topP":0.9
}
})
accept = 'application/json'
content_type = 'application/json'
before = datetime.now()
response = bedrock_runtime.invoke_model(body=body, modelId=model_id, accept=accept, contentType=content_type)
latency = (datetime.now() - before).seconds
response_body = json.loads(response.get('body').read())
response = response_body.get('results')[0].get('outputText')
return {
'latency': str(latency),
'response': response
}
def json_to_pretty_table(json_data):
data = json.loads(json_data)
table = PrettyTable()
# Assuming all rows have the same keys
headers = data['rows'][0].keys()
table.field_names = headers
for row in data['rows']:
table.add_row(row.values())
return table
def generate_budget_report(customer_data):
prompt_data = f"""
Using the spending data in the table bellow, aggregate the spending by category and provide the total for each category.
Customer Spending Table:
%s
""" % (customer_data)
r = call_bedrock(model_id,prompt_data)
return r['response']
6. 在Lambda服务的环境变量配置中配置如下键值对,用于Python代码运行读取环境变量。这里会用到刚刚复制的数据库服务器的私有IP地址,作为“DB_Host”的键值。

7. 接下来我们为Lambda函数配置网络,将其部署到亚马逊云科技VPC网络环境里。进入到Lambda函数的VPC选项,点击配置。

8. 在配置中指定VPC网络、私有子网Subnet以及Security Group安全组防火墙


9.下面我们进入到VPC服务主页的Endpoints功能,点击Create创建一个VPC endpoint,用于私密访问Amazon Bedrock

10. 为网络节点起名“bedrock-vpce”,选择的节点类型为“AWS Services”,节点服务名为“com.amazonaws.us-east-1.bedrock-runtime”,该服务则为Amazon Bedrock的API节点名。

11. 将该节点放置在我们创建的VPC和对应私有Subnet子网中。

12. 为该配置Security Group防火墙限制访问IP、端口和协议。

13. 为该节点添加如下JSON访问限制策略,用于限制在亚马逊云科技平台上访问的API操作、发起请求主体和请求对象,复制后点击创建。
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"bedrock:InvokeModel"
],
"Resource": [
"arn:aws:bedrock:us-east-1::foundation-model/amazon.titan-text-express-v1"
],
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:sts::<accountid>:assumed-role/lab_lambda_role/invoke_bedrock"
}
}
]
}
14. 最后通过Lambda函数的代码测试功能,我们成功得到私密调用Bedrock上的AI大模型和数据库的请求回复响应,说明私有大模型调用通道创建成功。该AI模型请求会自动被路由到我们刚刚创建的VPC节点中,通过PrivateLink访问大模型,得到回复。

以上就是在亚马逊云科技上通过PrivateLink,安全、合规、私密地调用Amazon Bedrock上的生成式AI大模型的全部步骤。欢迎大家未来与我一起,未来获取更多国际前沿的生成式AI开发方案。