FSD 效果惊艳,Robotaxi 迈向现实
2024 年 3 月 FSD V12.3 推出,解决复杂场景能力大幅提升,驾驶体验平顺丝滑拟人化程度高。FSD 开始从“测试版”晋级为“监督版”,并面向所有北美车主免费试用 30 天。随后马斯克在社交媒体上表示将在 8 月 8 日推出 Robotaxi 功能,自动驾驶即将真正带来汽车商业模式的变革。FSDV12 是一个端到端算法,对算力和数据需求激增,马斯克表示到 2024 年底将累计投入 100 亿美金在算力和数据领域,到 2024 年底总算力规模有望突破 100EFlops,目前 FSD 的累计行驶里程数已经超过 10 亿英里,特斯拉快速推进探索自动驾驶“无人区”。
端到端助力自动驾驶“融会贯通”,大模型时代到来
相比传统的感知、规控等模块拼接而成的模块化算法,端到端算法采用整体化的神经网络,模型的一端输入感知信息,另一端直接输出轨迹或者控制信号。
端到端算法优势显著:
(1)信息无损传递,减少人为偏见,灵活度大幅提升;(2)面向整体驾驶目标进行全局优化;(3)从“行为”学习“行为”,驾驶行为更加拟人化;(4)数据驱动,更易发挥规模法则;(5)精简计算任务,减少级联误差,降低延迟。端到端算法形成几大方向:由多个神经网络模块拼接而成的端到端、单一神经网络构建成的端到端、以及以大语言模型为核心的端到端算法。业界和学界对各类路线作出诸多探索,自动驾驶迎来大模型时代。
1、 FSD V12 效果惊艳,Robotaxi 迈向现实
1.1、 特斯拉 FSD V12.3 登场,自动驾驶辅助功能推向全量用户
特斯拉 FSD V12.3 登场,智驾时代更进一步。早在 2023 年 5 月,马斯克即在社交媒体上表示,FSDV12 将是一个视频输入+控制输出的端到端的自动驾驶算法;2023 年底,FSD V12 版本开始在北美的特斯拉车辆中试用;2024 年 3 月 12 日,FSD V12.3 推出,体验跨越式提升;随后,FSD 去掉“Beta”改为“Supervised”并开始向所有北美用户开放,允许免费试用 30 天,另外马斯克还要求北美地区销售必须带客户短途试驾 FSD 才能交车。2023 年 4 月,FSD 的订阅价格从 199 美元降低至 99 美元,买断价格从 12000 美元降低至 8000 美元。价格下探叠加向全美用户开放,表明公司马斯克已经对 FSD 功能的完善度相当自信,意味着将有百万数量级的用户有机会体验到自动驾驶辅助功能,有望显著增加 FSD 的曝光度以及订阅率,同时大规模试用也将为 FSD 收集可观的数据,助力功能完善。
1.2、 端到端算法加持,驾驶体验显著提升
特斯拉 FSDV12.3 推出以来,驾驶体验丝滑优雅,获得市场广泛好评。具体而言,我们看到几个方面的驾驶体验显著改善。
(1)解决复杂场景的能力大幅提升:例如可顺滑处理无保护左转和环岛等场景,相比 V11 大幅进步;无缝处理施工路段等复杂场景;对人类意图的理解加深,部分场景可以识别手势;可以根据其他车辆行驶状况判断当前场景是否可以通行,接管次数大幅降低。
(2)驾驶体验丝滑平顺拟人化:转弯、红绿灯启停无顿挫感,加减速拟人化;遇到开双闪的车辆占道会毫不犹豫变道绕行,流畅自然;遇到周围骑行者、行人绕行时从容淡定,绕行幅度拟人化;遇到其他车辆倒车,会留足空间,驾驶具有“礼貌性”;拟人化程度高,经常让乘客难以区分到底是人还是算法在执行驾驶行为。
(3)新增部分功能:部分场景可以掉头,抵达目的地后可以自主寻找停车处停车,不依赖导航。当然当前版本也会出现一些问题如距离道路边缘近,容易出现剐蹭,对交通规则的遵守度弱,以及其他车辆意图判断仍需提升,无法倒车等问题。未来,随着算法的迭代,小的问题有望逐步修复。
 FSDV12 甚至可识别自行车骑手的手势并减速 FSD V12 可以从 0 时速启动
FSDV12 甚至可识别自行车骑手的手势并减速 FSD V12 可以从 0 时速启动
1.3、 特斯拉推动,Robotaxi 有望迈向现实
随着自动驾驶性能的进一步提升,Robotaxi 有望成为现实。特斯拉关于Robotaxi 的规划早在 2016 年发布的《宏图计划第二部分》(Master Plan Part Deux)中即出现,后续马斯克亦在多次财报电话会议中提及。具体而言,一旦特斯拉实现了完全自动驾驶,将创立一个共享出行平台,通过特斯拉车辆来实现 Robotaxi 运营。特斯拉建立自有车队,同时特斯拉车主也可将自己的车辆加入到共享车队,后续特斯拉从每个订单中抽成。Robotaxi 将与造车业务实现协同,其运行数据将成为整个特斯拉数据闭环的一部分,最大化提升自动驾驶的盈利能力,此外闲置车辆可以赚钱将提升车辆的使用效率和特斯拉车辆的吸引力。2023 年 4 月,马斯克在社交媒体上宣布特斯拉将在 2024 年的 8 月 8 日推出 Robotaxi。目前,自动驾驶功能的完善度将是 Robotaxi 能否实现的核心,Robotaxi 有望为自动驾驶打开新的成长空间。
1.4、 算力、数据全面加速,特斯拉加足马力快速推进
端到端开创特斯拉自动驾驶新时代。对端到端自动驾驶而言,马斯克在多个场合表示,模型仅仅依靠神经网络构建,并未加入环形交叉路、红绿灯等场景和元素,对场景的理解和驾驶行为完全依靠模型自身通过大量的人类驾驶视频训练而学习到。和大语言模型类似,规模法则(Scaling Law)在自动驾驶领域也效果凸显,对端到端算法来说,算法之外,更迫切的是需要海量的数据和算力将模型的能力推升到更高水平。2024 年初,马斯克在多个场合表示,算力制约了特斯拉 FSD 功能的迭代,而在 3 月开始,马斯克表示算力并不在成为限制,FSD 的迭代将大大加快。
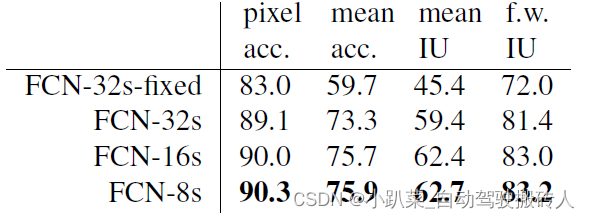
回顾 FSD 发展历史,算力累积伴随 FSD 迭代,并进一步强化特斯拉竞争力。根据特斯财报公布的算力增长曲线,我们可以观察到,在 FSD V11 以及之前版本的时代,算力基本在等效 5000 片 H100 的水平之下,在 FSD V12 也就是端到端算法推出前后,算力开始阶跃式提升至约等效 15000 片 H100 水平,此后算力进一步快速拉升至等效 3.5 万片 H100 左右,时间节点大约与 FSD V12.3 版本推出对应,此时特斯拉开始向所有订阅用户推送 V12 以上版本,并去掉 Beta 改为 Supervised,同时为所有用户开启 FSD 试用 1 个月。在 2024Q1 财报电话会议上,马斯克表示,2023 年底将会有等效 8.5 万片 H100 的算力投入使用,与此前公布的在 2024 年将达到 100Eflops 算力对应。可以观察到的是,伴随端到端的落地,特斯拉对算力的需求出现了近乎数量级的提升,这也反过来帮助其算法实现更加快速的迭代。
算力补足的特斯拉 FSD 迭代速度显著加快,每个新版本都带来性能的大幅提升。特斯拉 FSD 从 V12 版本推出到 V12.3 共推出 7 个迭代的衍生版本,花费了近 4个月时间,而从 V12.3 到 V12.3.6 推出的 8 次版本迭代所花费的时间仅有 1 个半月左右。功能方面,V9 到 V11 时代更多的是一些微小的性能提升和用户开放规则的放宽。而 V12 时代以来,新版本的功能实现大跨步提升,V12.3 甚至可以做到识别手势,而近期马斯克在社交媒体上表示,即将推出的版本中 FSD 将会把自动驾驶和自主泊车结合,实现“真正的代客泊车”,同时将去掉手握方向盘检测,此外在面临最新场景时也将有更好的表现,如驶入狭窄封闭道路中需要倒车来寻找新的路线等。
践行规模法则,特斯拉快速推进探索自动驾驶“无人区”。马斯克曾经在财报会中提到训练模型所需的数据:“100 万个视频 Case 训练,勉强够用;200 万个,稍好一些;300 万个,就会感到 Wow;到了 1000 万个,就变得难以置信了。”而训练数据仍需来自于优质的人类驾驶行为。对特斯拉而言,目前有数百万辆量产车辆可以实现数据收集,同时亦有大量订阅 FSD 的用户可以反馈 FSD 使用过程中的问题。特斯拉用户带来的 FSD 的累计行驶里程数加速增长,从 2023Q1 的 1.5 亿英里,提升至 2023Q3 的 5 亿英里,2023Q4 达到接近 8 亿英里,2024 年 4 月突破 10 亿英里。在 2024 年 4 月马斯克表示到 2024 年在训练算力、海量的数据闭环体系以及海量视频存储上将特斯拉将累计投入超过 100 亿美元。特斯拉一步步探索自动驾驶的“无人区”,将规模和能力推升到极致。
2、 端到端助力自驾算法“融会贯通”,大模型时代到来
2.1、 端到端算法将驾驶行为“融会贯通”
端到端自动驾驶算法实现对驾驶行为的“融会贯通”。在传统模块化的自动驾驶算法中,人类工程师依靠自己的经验将驾驶问题拆解和提炼为一些简单的过程,通常情况下自动驾驶算法分为感知、预测、规划控制几个部分,以流水线式的架构进行拼接,模块之间会以人为定义的信息表征方式进行信息传递,进而实现驾驶任务。端到端算法则采用一个整体化的神经网络,在模型的一端输入感知信息,另一端直接输出轨迹或者控制信号,将整个驾驶行为“融会贯通”。

端到端算法将传统的感知、预测、规划等算法模块融为一体
2.2、 端到端算法优势显著但落地难度加大
2.2.1、 端到端的自动驾驶算法优势显著:
(1)信息无损传递,减少人为偏见,灵活度大幅提升且泛化性增强
模块化算法以人类定义的抽象结果作为中间产物,如感知模块将外部的汽车、行人、道路等元素简化为检测框(Bounding box)或者占用栅格以及车道线等;而预测和规划模块则根据上游感知提供的信息,将复杂的世界抽象为几类简单的场景,分别输出轨迹点和驾驶路径和行为。这实际上会造成信息损失,当人为定义的抽象的指标并不能很好的描述场景时,下游模块只能根据有限的信息做判断,造成错误的结果,体验上来讲会造成模型对复杂场景的处理能力不足,泛化性差,决策僵硬。端到端算法则可以将各个模块几乎所有信息传递给下游模块,并且由下游模块来决定使用哪些上一环节的信息。例如当经过侧面有障碍物遮挡的小巷子时,如果人类司机观察到障碍物后面有汽车发出的灯光,可能会提前减速。模块化的算法由于感知端只检测障碍物、车道线等内容,可能会丢掉光照变化的信息,规控算法则无法提前规避侧向来车;而对端到端算法来说,全部传感器感知到的数据都会被收集,只要有足够的数据,模型会自己学习到灯光和驾驶员行为的关联进而拟人化的处理相应的问题。
(2)面向整体驾驶目标进行全局优化
在模块化算法中,每个模块都以人类工程师定义的目标进行优化,各个部分分而治之,可能出现局部最优但整体效果差的情况,如目标检测的指标是平均精度(mAP),规控算法的检测指标要考虑碰撞率、任务完成率等。端到端自动驾驶则对整个自动驾驶流程进行优化,神经网络的链式法则可以从输出端(控制)向输入端(感知)贯通,输出结果可以将误差依次反向传播给所有模块,以最小化整体损失函数为目标,更加准确地更新每个网络层中的参数,以使体验达到最优状态。(好比考试的时候,答案中 ABCD 的占比是一样的,但如果不通篇看题目,会丢掉这一重要的全局信息)在特斯拉 FSDV12 版本的视频中,有些时候会出现规控算法不会完全按照感知呈现的结果执行驾驶行为,或许亦体现了全局优化的优势(规控会根据自己的经验忽略掉一些感知出现的问题如误检等)。
(3)从“行为”学习“行为”,驾驶变得更加丝滑和拟人化。
这一优势也可以被视为用基于神经网络的算法取代基于规则为主算法带来的优势。吴新宙在 GTC 大会上提到,在传统自动驾驶开发过程中,工程师希望定义一些动作,通过建立状态机转换不同的动作来实现驾驶,而为了实现更好的驾驶效果,会引入越来越多的动作让机器的行为尽量像人。但现实情况中,人类的行为难以通过一些离散的动作量化,规则无法定义什么是好的驾驶,甚至有些场景下并无最优决策,好比单纯用文字很难精确的描述一幅画的内容,何小鹏提到无限接近人的自动驾驶系统大概等效于 10 亿条规则,靠人类根本无法达到,因此传统算法产生的驾驶决策死板单调,拟人性差。端到端或者说基于学习的规划让模型去学习人类行为,会大幅提升算法的适应性和灵活度,据元戎启行在 GTC 大会上介绍道,元戎的算法由于使用了端到端技术,不仅实现了舒适、高效,还会考虑后车需求,实现了“礼貌”,如主动让出右转车道,地面有水会减速慢行等。
(4)数据驱动,发挥规模法则,性能突破上限
采用端到端的自动驾驶算法,可以采用无监督的算法训练方式,省去标注环节,采用海量数据对模型进行训练,突破性能上限。而模块化算法则只能依靠工程师来手动处理长尾场景,随着数据量的增大,效率逐步下降。
(5)精简计算任务,减少级联误差,降低延迟,计算简洁高效
模块化算法中,从传感器收集信息开始就不可避免的出现误差,每个模块产生的误差如标定误差、定位精度误差、控制误差等会在模块间传递,最终会在下游累积,导致控制模块收敛难度加大。同时,模块之间的数据传输和计算都需要花费时间,导致整体算法延时较高,处理紧急场景能力弱。端到端算法则可避免上述情况出现。此外马斯克亦表示,通过使用端到端自动驾驶算法,特斯拉采用 2000 行代码代替了原本的 30 万行代码,整体算法框架变得简洁高效。
2.2.2、 端到端的自动驾驶算法亦存在可解释性差、落地难度大等问题
首先由于模型被构建为一个整体,无法像传统自动驾驶任务一样将中间结果进行分析,因此可解释性较差。其次由于算法完全依靠数据驱动,对数据的质量、数据分布等要求高,海量数据的获取或生成难度较大。此外仿真验证也是端到端算法开发的难点,端到端算法更需要闭环评估,而在当前的技术条件下,缺乏良好的工具实现这一过程。最后对自动驾驶公司来说,算法的变化也意味着团队的调整,如何保持团队稳定性和量产经验的复用亦存在难点。
2.3、 端到端算法形成三大落地形式
多模态基础模型和大语言模型齐头并进,端到端自动驾驶算法百家争鸣。目前在自动驾驶端到端算法领域,大体形成几大方向:将不同功能的神经网络模块拼接形成端到端的自动驾驶算法(显式);依靠多模态基础模型实现端到端自动驾驶算法(隐式);以及依靠多模态大语言模型来实现自动驾驶。
2.3.1、 将多个神经网络拼接形成端到端算法(显式端到端):
显式的端到端自动驾驶即将原有的算法模块以神经网络进行替代并连接形成端到端算法。该算法包含可见的算法模块,可以输出中间结果,当进行故障回溯时可以一定程度上进行白盒化调整,训练时首先将每个模块分别训练,再将其拼接进行联合微调和训练,在数据量有限的情况下更容易收敛,且对于算法团队来说可以最大限度的继承此前模块化算法的开发能力,同时又具备端到端算法的优势,是目前诸多量产玩家青睐的方案。获得 2023 年 CVPR 最佳论文奖的 UniAD 模型亦采用此方法,可明显的观察到算法中仍包含感知、预测、占用预测、规划器等模块,并采用向量将模块连接,形成灵活的端到端架构。
2.3.2、 多模态基础模型+自动驾驶(隐式端到端):
隐式的端到端算法构建整体化的基础模型,利用海量的传感器接收的外部环境数据,忽略中间过程,直接监督最终控制信号进行训练。这类模型通常采用视觉或者多模态的信息作为输入,模型直接输出控制或者轨迹信号。诸多玩家探索的自动驾驶世界模型在这里也有应用,即将视频、甚至文字信息送入模型,此后模型可以预测未来发生的事情以及所应该采取的行动,或者可以对所执行操作进行文字解释。该方案理论上限更高,但训练难度高,收敛困难,对数据需求量大且可解释性差,模型调整也较为困难,量产玩家如 Wayve 以及学术界做出诸多探索。
Wayve 的端到端自动驾驶网络即采用单一的神经网络,直接输入感知数据,输车辆的驾驶动作,中间没有抽象化的感知结果输出,因此车辆上也不包含通常自动驾驶具备的“SR”(Situational Awareness,用来呈现自驾算法看到了什么)界面。

学术界百花齐放,世界模型成为玩家探索方向。近年世界模型受到市场关注,通过将外部环境的信息进行编码,由模型基于这些输入的语料来预测未来世界可能的状态,再通过不同的解码器解码出不同类型的信息,亦成为开发端到端自动驾驶算法的一大方式。以极佳科技和清华大学联合推出的 DriveDreamer 为例,模型主要采用注意力机制和 Diffusion 模型构建。可对驾驶场景实现全面的理解,集成了多模态的输入数据如文本、视频、高精度地图、3D 检测框、驾驶行为等,可以实现可控的驾驶视频生成和预测未来的驾驶行为。同时 DriveDreamer 还可以与驾驶场景互动,根据输入的驾驶动作预测不同的未来驾驶视频。
2.3.3、 大语言模型+自动驾驶:
大语言模型采用海量的互联网数据进行自监督学习,可以对人类的问题给出优质反馈。大语言模型凭借其强大的认知能力,越来越多的被应用于驾驶场景。经过前期的预训练,模型已经吸收了驾驶相关的知识,并且广泛理解世界的“常识”,通过好的提示词即可激发出其相关的能力。目前大语言模型可以被用于感知、预测、规划、整个驾驶环节、以及驾驶行为解释上。尤其是大语言模型可以对话的特性,让驾驶员可以对其做出的操作进行询问,增强模型的可解释性和驾驶的安全感。
目前工业界亦不乏大语言模型实践的先行者。端到端的坚定践行者 Wayve 公司,在 2023 年推出了 LINGO-1,该模型在各类视觉和语言数据源上进行训练,可以对感知、规划、推理等任务进行视觉问答,并可以对驾驶行为作出解释。升级版本的LINGO-1 甚至可以对道路语义信息进行分割。
在学术界大语言模型用作自动驾驶的方案更如雨后春笋。GPT-Driver、LanguageMPC、Drive like a Human、DriveLM、DriveGPT4 层出不穷。以港大和华为诺亚实验室等发表的文章中的 DriveGPT4 为例,它是一个使用 LLM 的可解释的端到端自动驾驶系统,通过将视频、语音提示、控制信号 Token 化之后送入大语言模型,语言模型生成对人类问题的相应回答以及控制信号,再经过编码等步骤还原成为文字和控制信息,即可对车辆实现控制。












![[C++][opencv]基于opencv实现photoshop算法灰度化图像](https://i-blog.csdnimg.cn/direct/171bb7eac04f47438a7ccba1009881e8.gif)