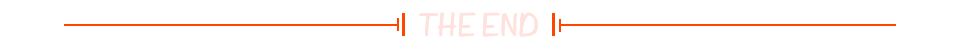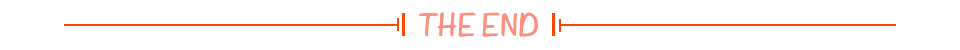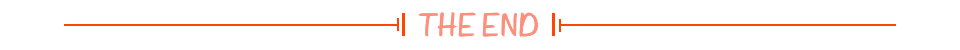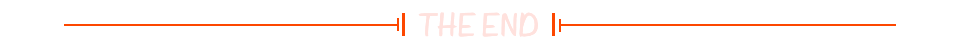摘要:
本文将深入探讨如何从前程无忧网站自动抓取岗位信息,通过分享五大实用的采集技巧,助您轻松掌握大数据时代的招聘情报。无需编程基础,也能高效获取目标职位详情,优化人力资源管理与市场分析。
正文:
一、了解数据采集基础
在探讨具体技巧之前,了解数据采集的基本概念至关重要。数据采集,俗称网络爬虫,是指自动抓取互联网上的信息并结构化存储的过程。对于想从前程无忧这类大型招聘网站获取岗位信息的用户来说,合理运用采集技巧是关键。
二、选择合适的采集工具
关键词聚焦:数据采集工具 市面上有多种数据采集工具可选,从免费到付费不等,如Selenium、BeautifulSoup等。选择时需考虑易用性、稳定性及是否支持复杂网页结构解析。推荐使用集蜂云平台,它提供了直观的界面操作与强大的数据处理能力,特别适合无编程背景的用户快速上手。
三、明确采集需求,精准定位
关键词强化:岗位需求定位 首先,明确您想抓取的岗位类型、地域、薪资范围等条件。利用前程无忧的高级搜索功能,可以帮助您精确到目标页面,从而提高采集效率与数据相关性。
四、模拟浏览器行为,绕过反爬机制
关键词嵌入:反爬策略应对 多数网站设有反爬虫机制,以防止数据被大量抓取。采用如User-Agent轮换、设置合理的请求间隔等策略,模拟人类浏览行为,可以有效降低被封IP的风险。
五、利用API接口,合法获取数据
关键词布局:API接口利用 前程无忧等大型网站往往提供官方API接口供开发者使用。注册开发者账号,遵循API使用条款,可以合法、高效地获取数据,避免了自行编写爬虫的繁琐与风险。
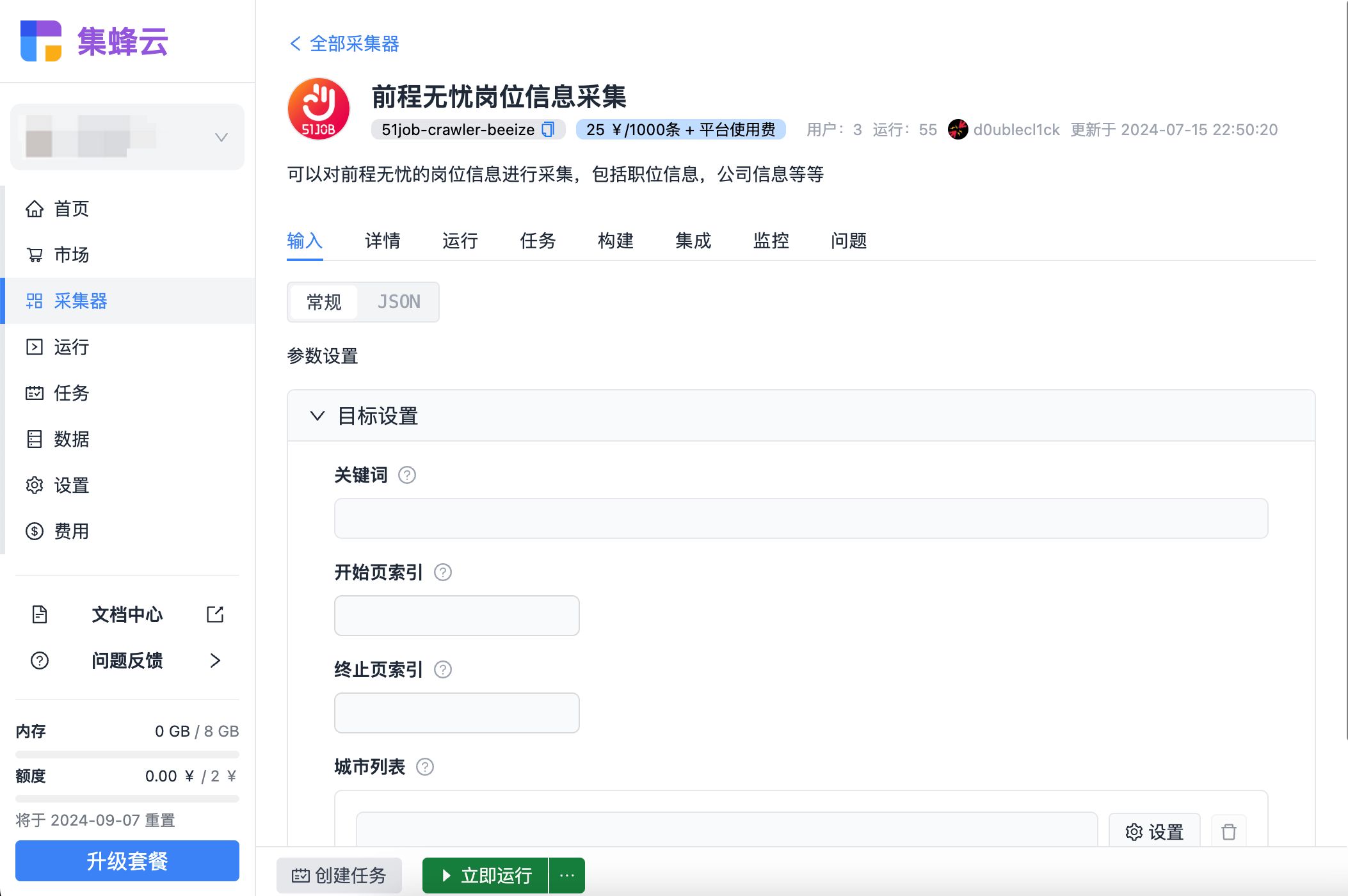
六、数据清洗与分析
采集到的数据往往需要进一步处理才能发挥价值。借助Excel、Python pandas库或集蜂云内置的数据处理功能,去除重复项、清洗无效数据,随后进行深度分析,为企业决策提供有力支持。
七、监控与自动化
设置定期任务,自动化执行数据抓取与更新,确保信息的时效性。集蜂云平台的“海量任务调度”功能在这方面表现卓越,让您坐享其成。
常见问题与解答:
Q: 抓取数据是否违法? A: 在遵守网站使用协议及版权法的前提下,合理范围内的数据采集是合法的。务必确保数据用途正当,尊重数据来源。
Q: 遇到反爬怎么办? A: 除了上述提到的方法,还可以尝试使用代理IP、调整访问频率,或直接联系网站申请API权限。
Q: 如何保证采集数据的质量? A: 设定明确的采集规则,利用数据验证机制,以及后期的数据清洗,都是保证数据质量的有效手段。
Q: 数据采集后如何存储? A: 可以选择本地存储如数据库,或云存储服务。集蜂云自带数据存储功能,方便快捷。
Q: 初学者应从何处开始学习数据采集? A: 从Python爬虫基础开始,利用requests、BeautifulSoup等库进行实战练习,逐步进阶到更复杂的项目。
结语:
在大数据驱动的今天,从前程无忧等平台高效抓取岗位数据已成为企业与个人提升竞争力的重要手段。通过上述五大技巧的学习与实践,相信您已掌握了开启这一领域的金钥匙。集蜂云平台以其全面的功能与用户友好的界面,无疑是您数据采集之旅的理想伴侣。





![[C++][opencv]基于opencv实现photoshop算法灰度化图像](https://i-blog.csdnimg.cn/direct/171bb7eac04f47438a7ccba1009881e8.gif)