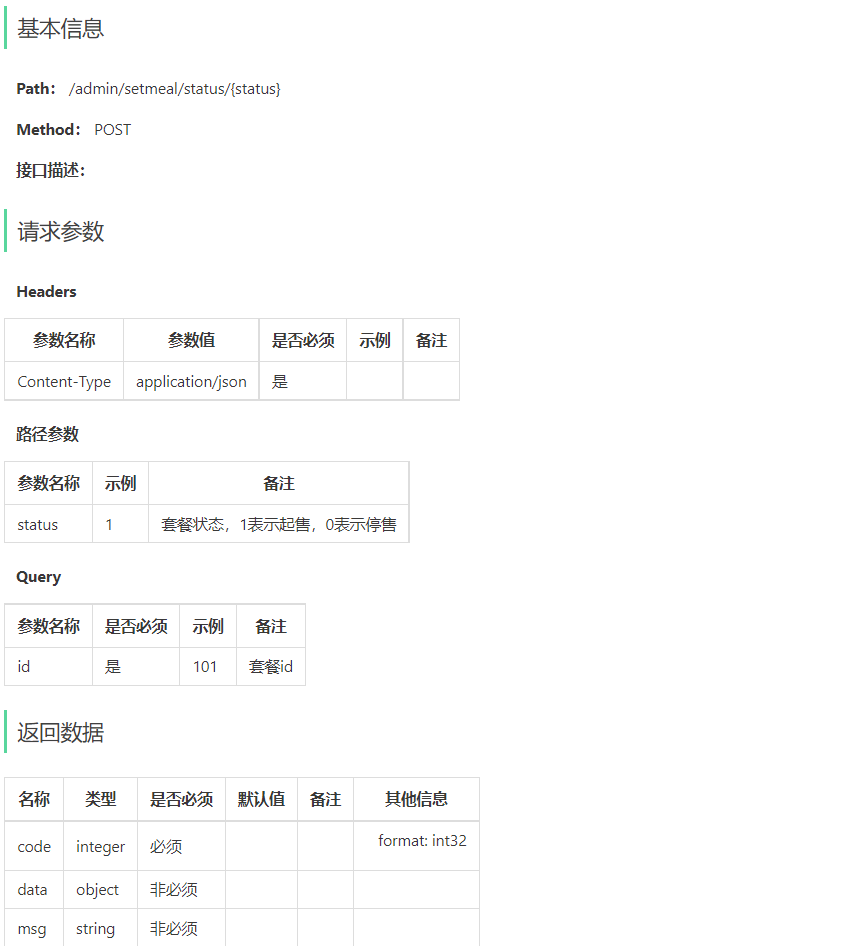
import torch
import torch.nn as nn
import torch.nn.functional as F
class RepVggBlock(nn.Module):
def __init__(self, ch_in, ch_out, act='relu'):
super().__init__()
self.ch_in = ch_in # 输入通道数
self.ch_out = ch_out # 输出通道数
# 第一个卷积层,使用 3x3 卷积核,填充为 1
self.conv1 = ConvNormLayer(ch_in, ch_out, 3, 1, padding=1, act=None)
# 第二个卷积层,使用 1x1 卷积核,无填充
self.conv2 = ConvNormLayer(ch_in, ch_out, 1, 1, padding=0, act=None)
# 初始化激活函数,如果未指定则使用恒等变换
self.act = nn.Identity() if act is None else get_activation(act)
def forward(self, x):
# 前向传播,将输入 x 通过两个卷积层并相加
y = self.conv1(x) + self.conv2(x)
# 应用激活函数
return self.act(y)
def convert_to_deploy(self):
# 转换为部署模式,将两个卷积层融合为一个
if not hasattr(self, 'conv'):
self.conv = nn.Conv2d(self.ch_in, self.ch_out, 3, 1, padding=1)
# 获取等效的卷积核和偏置
kernel, bias = self.get_equivalent_kernel_bias()
# 更新融合后的卷积层的权重和偏置
self.conv.weight.data = kernel
self.conv.bias.data = bias
# 注释:以下两行被注释掉了,它们原本用于删除 conv1 和 conv2 层
# self.__delattr__('conv1')
# self.__delattr__('conv2')
def get_equivalent_kernel_bias(self):
# 获取等效的卷积核和偏置
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.conv1)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.conv2)
# 将 1x1 卷积核填充为 3x3 大小
return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1), bias3x3 + bias1x1
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
# 如果 1x1 卷积核不存在,则返回 0
if kernel1x1 is None:
return 0
else:
# 使用 F.pad 对 1x1 卷积核进行填充,使其成为 3x3 大小
return F.pad(kernel1x1, [1, 1, 1, 1])
def _fuse_bn_tensor(self, branch: ConvNormLayer):
# 如果分支层不存在,则返回 0, 0
if branch is None:
return 0, 0
# 获取卷积层的权重
kernel = branch.conv.weight
# 获取批量归一化层的参数
running_mean = branch.norm.running_mean
running_var = branch.norm.running_var
gamma = branch.norm.weight
beta = branch.norm.bias
eps = branch.norm.eps
# 计算并返回融合后的卷积核和偏置
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std功能解释:
RepVggBlock类实现了一个可部署的卷积块,它可以在训练时使用两个卷积层(一个 3x3 卷积和一个 1x1 卷积),并在部署时将它们融合为一个 3x3 卷积层,以减少模型的复杂性和提高推理速度。forward方法定义了模型的前向传播逻辑,它将输入x通过两个卷积层,并将它们的结果相加,然后应用激活函数。convert_to_deploy方法用于将模型转换为部署模式,通过融合两个卷积层为一个卷积层,并更新其权重和偏置。get_equivalent_kernel_bias方法用于获取融合后的卷积核和偏置,以便在部署模式下使用。_pad_1x1_to_3x3_tensor方法用于将 1x1 卷积核填充为 3x3 大小,以便与 3x3 卷积核相加。_fuse_bn_tensor方法用于融合 BatchNorm 层到卷积层中,计算融合后的卷积核和偏置。
整体而言,RepVggBlock 类提供了一种灵活的方式来构建和部署高效的卷积块,它通过融合卷积和归一化层来简化模型结构,同时保持性能。这种设计在实际应用中有助于提高模型的推理速度和减少内存占用。
import torch
from torch import nn
class CCFF(nn.Module):
def __init__(self,
in_channels,
out_channels,
num_blocks=3,
expansion=1.0,
bias=None,
act="silu"):
super(CCFF, self).__init__() # 调用基类的初始化方法
# 计算隐藏层的通道数,基于输出通道数和扩展比例
hidden_channels = int(out_channels * expansion)
# 第一个1x1卷积层,用于通道混合
self.conv1 = ConvNormLayer(in_channels, hidden_channels, 1, 1, bias=bias, act=act)
# 第二个1x1卷积层,用于跨通道特征融合
self.conv2 = ConvNormLayer(in_channels, hidden_channels, 1, 1, bias=bias, act=act)
# 构建瓶颈层序列,包含多个 RepVggBlock
self.bottlenecks = nn.Sequential(*[
RepVggBlock(hidden_channels, hidden_channels, act=act) for _ in range(num_blocks)
])
# 如果隐藏层通道数不等于输出通道数,则添加第三个1x1卷积层进行通道映射
if hidden_channels != out_channels:
self.conv3 = ConvNormLayer(hidden_channels, out_channels, 1, 1, bias=bias, act=act)
else:
# 如果相等,则使用恒等变换
self.conv3 = nn.Identity()
def forward(self, x):
# 前向传播方法
# 通过第一个1x1卷积层和瓶颈层
x_1 = self.conv1(x)
x_1 = self.bottlenecks(x_1)
# 通过第二个1x1卷积层
x_2 = self.conv2(x)
# 将两个分支的输出相加,然后通过第三个1x1卷积层或恒等变换
return self.conv3(x_1 + x_2)
# 测试代码
if __name__ == '__main__':
# 实例化模型对象,输入和输出通道数均为64
model = CCFF(in_channels=64, out_channels=64)
# 创建一个随机初始化的输入张量,大小为 (批量大小, 通道数, 高度, 宽度)
input = torch.randn(1, 64, 32, 32)
# 通过模型前向传播得到输出
output = model(input)
# 打印输入和输出张量的大小
print('input_size:', input.size())
print('output_size:', output.size())功能解释:
CCFF类是一个深度学习模块,它使用两个1x1卷积层和一个瓶颈层序列来实现特征融合和通道混合。in_channels和out_channels分别指定了输入和输出的通道数。num_blocks指定了瓶颈层序列中 RepVggBlock 的数量。expansion用于计算隐藏层的通道数,如果设置为1.0,则隐藏层通道数与输出通道数相同。bias参数用于控制卷积层是否使用偏置项。act指定了激活函数的类型,默认为 "silu"。ConvNormLayer是一个自定义的卷积层,包含卷积和批量归一化操作。RepVggBlock是一个自定义的卷积块,它可以在训练和部署时进行优化。forward方法定义了数据通过CCFF模块的流程,包括通过卷积层、瓶颈层、相加操作和最后的卷积或恒等变换。
整体而言,CCFF 类实现了一个灵活的特征融合模块,可以用于深度学习模型中的各种任务,如特征提取、特征融合等。通过调整参数,可以适应不同的网络结构和应用需求。
完整代码

import torch
import torch.nn as nn
import torch.nn.functional as F
# https://arxiv.org/abs/2304.08069
'''
论文题目:DETR 在实时目标检测方面击败 YOLO CVPR 2024
即插即用模块:CCFF跨尺度特征融合模块
CCFF基于跨尺度融合模块进行优化,该模块将多个由卷积层组成的融合块插入到融合路径中。
融合块的作用是将两个相邻的尺度特征融合成一个新的特征,其结构如图 5 所示。
融合块包含两个 1 × 1 卷积来调整通道数,由 RepConv[8]组成的 N 个 RepBlocks 用于特征融合,
两路径输出通过元素加法融合。
'''
# 激活层模块
def get_activation(act: str, inpace: bool = True):
'''get activation
'''
# 将输入的激活函数名称转换为小写
act = act.lower()
if act == 'silu': m = nn.SiLU()
elif act == 'relu': m = nn.ReLU()
elif act == 'leaky_relu': m = nn.LeakyReLU()
elif act == 'silu': m = nn.SiLU()
elif act == 'gelu': m = nn.GELU()
# 如果没有指定激活函数,使用恒等变换
elif act is None: m = nn.Identity()
# 如果输入的是一个 nn.Module 对象,则直接使用该对象
elif isinstance(act, nn.Module): m = act
else: raise RuntimeError('')
# 如果激活层模块有 inplace 属性,则设置该属性
if hasattr(m, 'inplace'): m.inplace = inpace
return m
# 类 ConvNormLayer 用于构建一个包含卷积、归一化和激活函数的卷积层。
class ConvNormLayer(nn.Module):
def __init__(self, ch_in, ch_out, kernel_size, stride, padding=None, bias=False, act=None):
super().__init__()
self.conv = nn.Conv2d(
ch_in,# 输入通道数
ch_out,# 输出通道数
kernel_size,# 卷积核大小
stride,# 步长
padding=(kernel_size - 1) // 2 if padding is None else padding,# 计算填充,以保持输出尺寸不变
bias=bias)# 是否使用偏置项
# 初始化批量归一化层
self.norm = nn.BatchNorm2d(ch_out)
# 根据提供的激活函数名称或对象,初始化激活层
self.act = nn.Identity() if act is None else get_activation(act)
def forward(self, x):# 前向传播方法,将输入 x 通过卷积层、归一化层和激活层
return self.act(self.norm(self.conv(x)))
class RepVggBlock(nn.Module):
def __init__(self, ch_in, ch_out, act='relu'):
super().__init__()
self.ch_in = ch_in # 输入通道数
self.ch_out = ch_out # 输出通道数
# 第一个卷积层,使用 3x3 卷积核,填充为 1
self.conv1 = ConvNormLayer(ch_in, ch_out, 3, 1, padding=1, act=None)
# 第二个卷积层,使用 1x1 卷积核,无填充
self.conv2 = ConvNormLayer(ch_in, ch_out, 1, 1, padding=0, act=None)
# 初始化激活函数,如果未指定则使用恒等变换
self.act = nn.Identity() if act is None else get_activation(act)
def forward(self, x):
# 前向传播,将输入 x 通过两个卷积层并相加
if hasattr(self, 'conv'):
y = self.conv(x)
else:
y = self.conv1(x) + self.conv2(x)
# 应用激活函数
return self.act(y)
def convert_to_deploy(self):
# 此函数将模型转换为部署模式
# 如果模型中还没有融合的卷积层,则创建一个
# 转换为部署模式,将两个卷积层融合为一个
if not hasattr(self, 'conv'):
self.conv = nn.Conv2d(self.ch_in, self.ch_out, 3, 1, padding=1)
# 获取融合后的卷积核和偏置
kernel, bias = self.get_equivalent_kernel_bias()
# 更新融合后的卷积层的权重和偏置
self.conv.weight.data = kernel
self.conv.bias.data = bias
# self.__delattr__('conv1')
# self.__delattr__('conv2')
def get_equivalent_kernel_bias(self):
# 此函数获取等效的卷积核和偏置,将两个卷积层融合为一个
# 获取等效的卷积核和偏置
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.conv1)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.conv2)
# 将1x1卷积层的权重扩展为3x3大小,然后与3x3卷积层的权重相加
return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1), bias3x3 + bias1x1
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
# 如果 1x1 卷积核不存在,则返回 0
if kernel1x1 is None:
return 0
else:
# 使用 F.pad 对 1x1 卷积核进行填充,使其成为 3x3 大小
return F.pad(kernel1x1, [1, 1, 1, 1])
def _fuse_bn_tensor(self, branch: ConvNormLayer):
# 如果分支层不存在或为None,则返回0, 0
if branch is None:
return 0, 0
# 融合卷积层和批量归一化层的权重和偏置
kernel = branch.conv.weight
# 获取批量归一化层的参数
running_mean = branch.norm.running_mean
running_var = branch.norm.running_var
gamma = branch.norm.weight
beta = branch.norm.bias
eps = branch.norm.eps
# 计算并返回融合后的卷积核和偏置
std = (running_var + eps).sqrt()# 计算标准差
t = (gamma / std).reshape(-1, 1, 1, 1)# 计算缩放因子
return kernel * t, beta - running_mean * gamma / std# 返回融合后
class CCFF(nn.Module):
def __init__(self,
in_channels,
out_channels,
num_blocks=3,
expansion=1.0,
bias=None,
act="silu"):
super(CCFF, self).__init__()# 调用基类的初始化方法
# 计算隐藏层的通道数,基于输出通道数和扩展比例
hidden_channels = int(out_channels * expansion)
# 第一个1x1卷积层,用于通道混合
self.conv1 = ConvNormLayer(in_channels, hidden_channels, 1, 1, bias=bias, act=act)
# 第二个1x1卷积层,用于跨通道特征融合
self.conv2 = ConvNormLayer(in_channels, hidden_channels, 1, 1, bias=bias, act=act)
# 构建瓶颈层序列,包含多个 RepVggBlock
self.bottlenecks = nn.Sequential(*[
RepVggBlock(hidden_channels, hidden_channels, act=act) for _ in range(num_blocks)
])
# 如果隐藏层通道数不等于输出通道数,则添加第三个1x1卷积层进行通道映射
if hidden_channels != out_channels:
self.conv3 = ConvNormLayer(hidden_channels, out_channels, 1, 1, bias=bias, act=act)
else:
# 如果相等,则使用恒等变换
self.conv3 = nn.Identity()
def forward(self, x):
# 前向传播方法
# 通过第一个1x1卷积层和瓶颈层
x_1 = self.conv1(x)
x_1 = self.bottlenecks(x_1)
# 通过第二个1x1卷积层
x_2 = self.conv2(x)
# 将两个分支的输出相加,然后通过第三个1x1卷积层或恒等变换
return self.conv3(x_1 + x_2)
# 输入 N C H W, 输出 N C H W
if __name__ == '__main__':
# 实例化模型对象
model = CCFF(in_channels=64, out_channels=64)
# 创建一个随机初始化的输入张量,大小为 (批量大小, 通道数, 高度, 宽度)
input = torch.randn(1, 64, 32, 32)
output = model(input)
print('input_size:',input.size())
print('output_size:',output.size())