为初学者提供清晰易懂的教程
为初学者提供清晰易懂的教程 Apache Spark 和 AWS EMR 上的 Spark 集群
添加图片注释,不超过 140 字(可选)
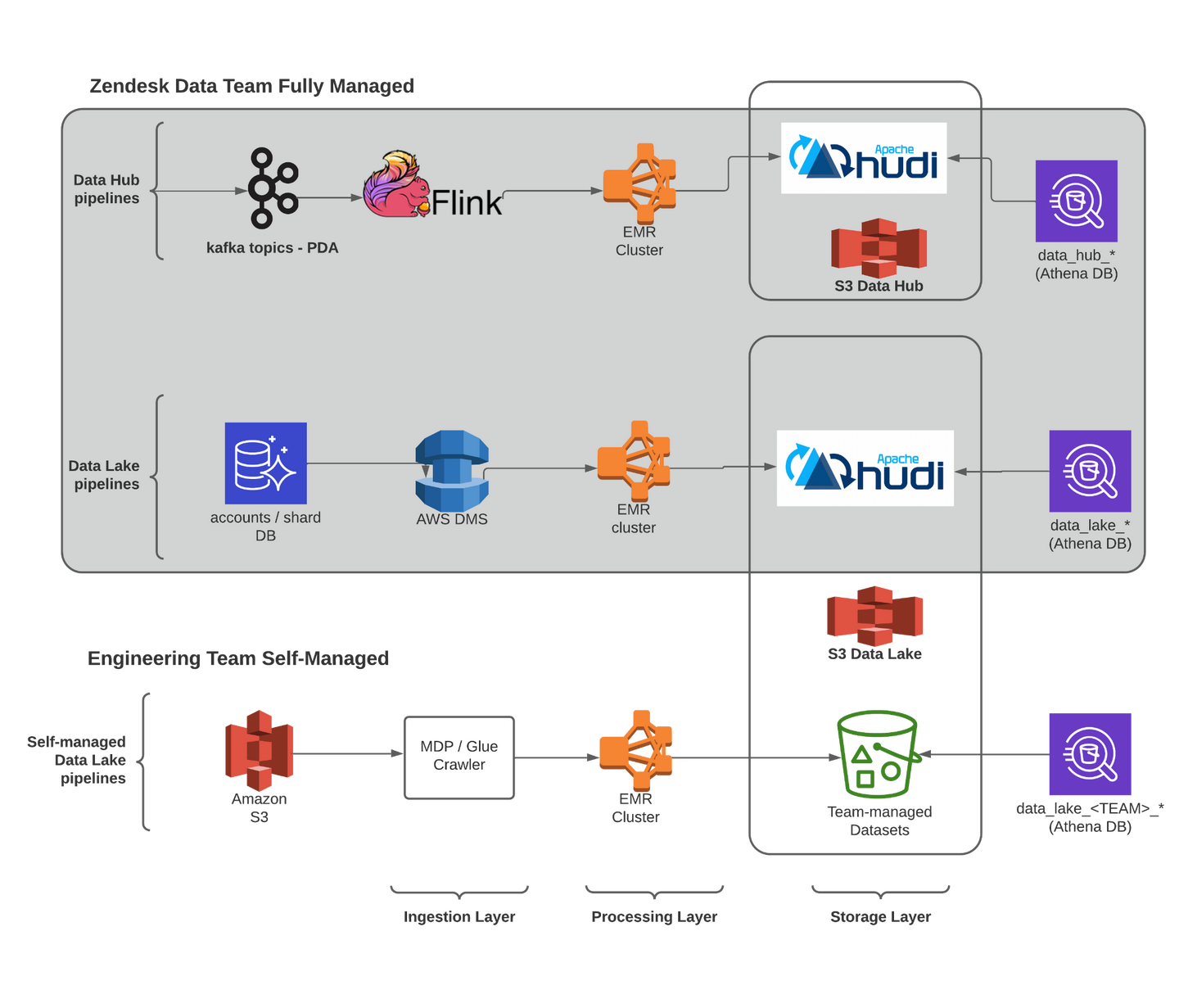
欢迎来到雲闪世界。Spark 被认为是“大数据丛林之王”,在数据分析、机器学习、流媒体和图形分析等领域有着广泛的应用。 Spark 有 4 种不同的模式:(1)本地模式:Spark 在单台机器(例如笔记本电脑)上用于学习语法和设计项目原型; 其他 3 种模式是集群管理器模式:(2)独立模式用于在私有集群上工作;(3)YARN和(4)Mesos 模式用于与团队共享集群。 在独立模式下,Spark 部署在私有集群上,例如 Amazon Web Service AWS 上的 EC2。 Spark 集群包含多台机器。 要在每台机器上使用 Spark 代码,需要手动下载并安装 Spark 及其依赖项。 借助AWS 的Elastic Map Reduce 服务 EMR,一切都准备就绪,无需任何手动安装。 因此,我们使用 EMR 服务来设置 Spark 集群,而不是使用 EC2。
本教程的动机
我确实花了很多时间努力使用AWS 命令行界面 (AWS CLI)在 EMR 上创建、设置和运行 Spark 集群。虽然我找到了一些关于此任务的教程或通过课程提供的教程,但大多数教程都很难理解。有些教程不够清晰;有些教程错过了一些关键步骤;或者假设学习者已经了解一些关于 AWS、CLI 配置等的先验知识。在成功设置并运行集群后,我意识到这个任务 实际上并不复杂;我们应该轻松完成它。我不想再看到人们为此苦苦挣扎。因此,我决定制作本教程。
本文假设您 已经具备一些 Spark、PySpark、命令行环境和 AWS 的工作知识。具体来说,本文适合那些知道为什么需要创建 Spark 集群的读者 :)。有关 Spark 的更多信息,请阅读此处的参考资料。
这是一个很长很详细的教程。简而言之,所有步骤包括:
-
创建 AWS 账户
-
创建 IAM 用户
-
在 EC2 中设置凭证
-
创建 S3 存储桶来存储集群生成的日志文件
-
安装 AWS CLI 包awscli
-
设置 AWS CLI 环境(创建凭证和配置文件)
-
创建 EMR 集群
-
允许 SSH 访问
-
与集群主节点建立 SSH 连接
-
开始使用 EMR 集群
请随意跳过您已经知道的任何步骤。
我很高兴你们中的许多人都觉得本教程很有用。我很荣幸与大家讨论您在 EMR 创建过程中遇到的任何问题。根据我们的一些讨论,以下是本教程的一些更新。
一些注意事项: 1. 对于本教程,应使用AWS 常规账户,而不是 AWS Educate 账户。AWS 常规账户为用户提供对 AWS 资源和 IAM 角色的完全访问权限;而教育账户则具有一些有限的访问权限。 2. 您有责任监控您使用的 AWS 账户的使用费用。每次完成工作后,请记住终止集群和其他相关资源。我已经多次实施了 EMR 集群;本教程在 AWS 上应该不会产生任何费用或费用低于 0.5 美元。 3. AWS 控制台和 Udacity 内容会随时间而变化/升级,因此我建议您搜索 AWS 网站和 Udacity 课程以获取任何更新的教程/指南。 4.本教程使用Chrome和Mac OS X制作,在Windows平台上应该不会有太大差别。
在 AWS CLI 上创建、设置和运行 EMR 集群的具体步骤
步骤 1:创建 AWS 账户
-
如果您还没有常规 AWS 账户,请创建一个。AWS网站上的说明非常容易理解。
-
登录您的 AWS 账户。
-
(可选)为了提高您的 AWS 资源的安全性,您可以按照此处的简单 AWS 指南配置并启用虚拟多重身份验证 (MFA)设备。
步骤 2:创建 IAM 用户
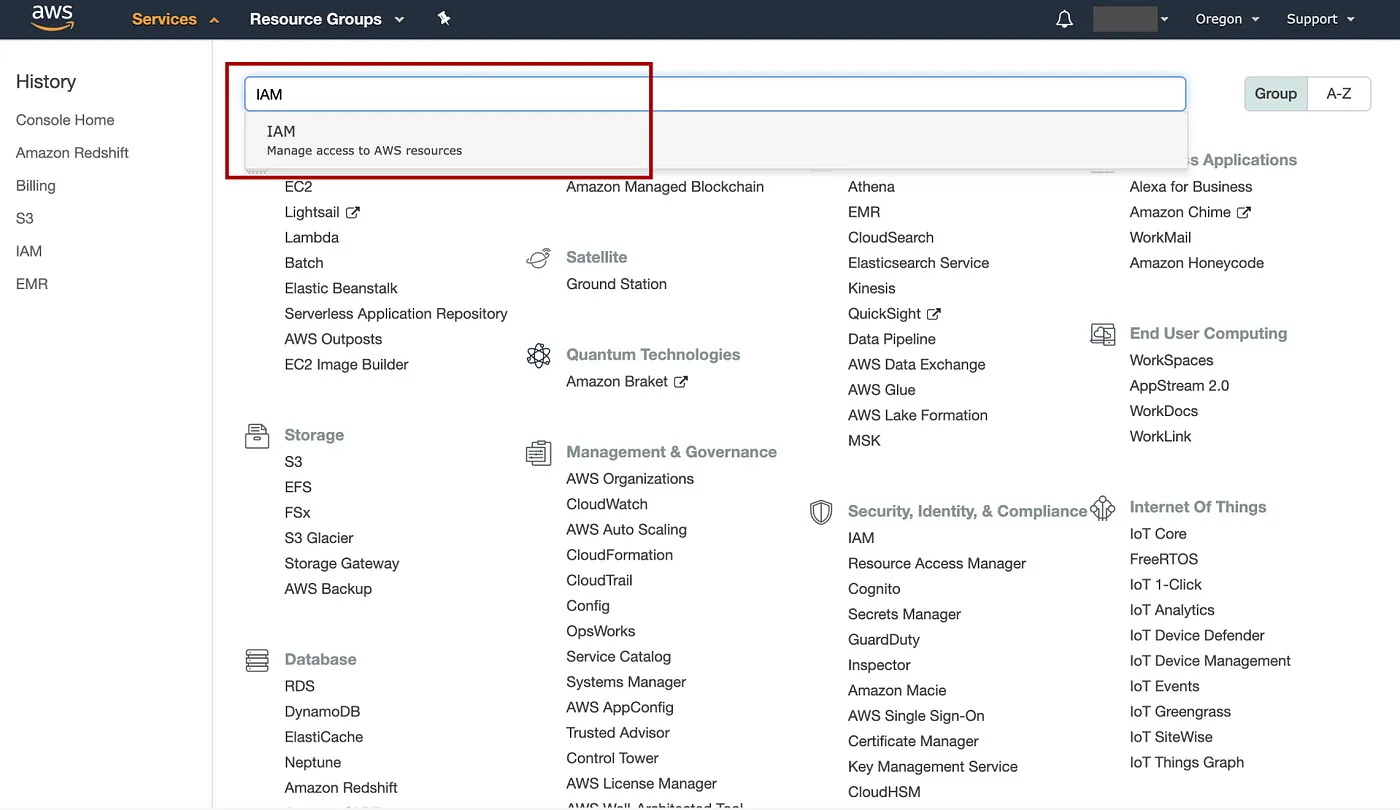
在 AWS 控制台中,单击Service,输入“IAM”转到 IAM 控制台:
添加图片注释,不超过 140 字(可选)
=> 选择User=> Add user=> 输入用户名例如“emr_user”,选择Access type为程序访问,然后Next: Permissions。
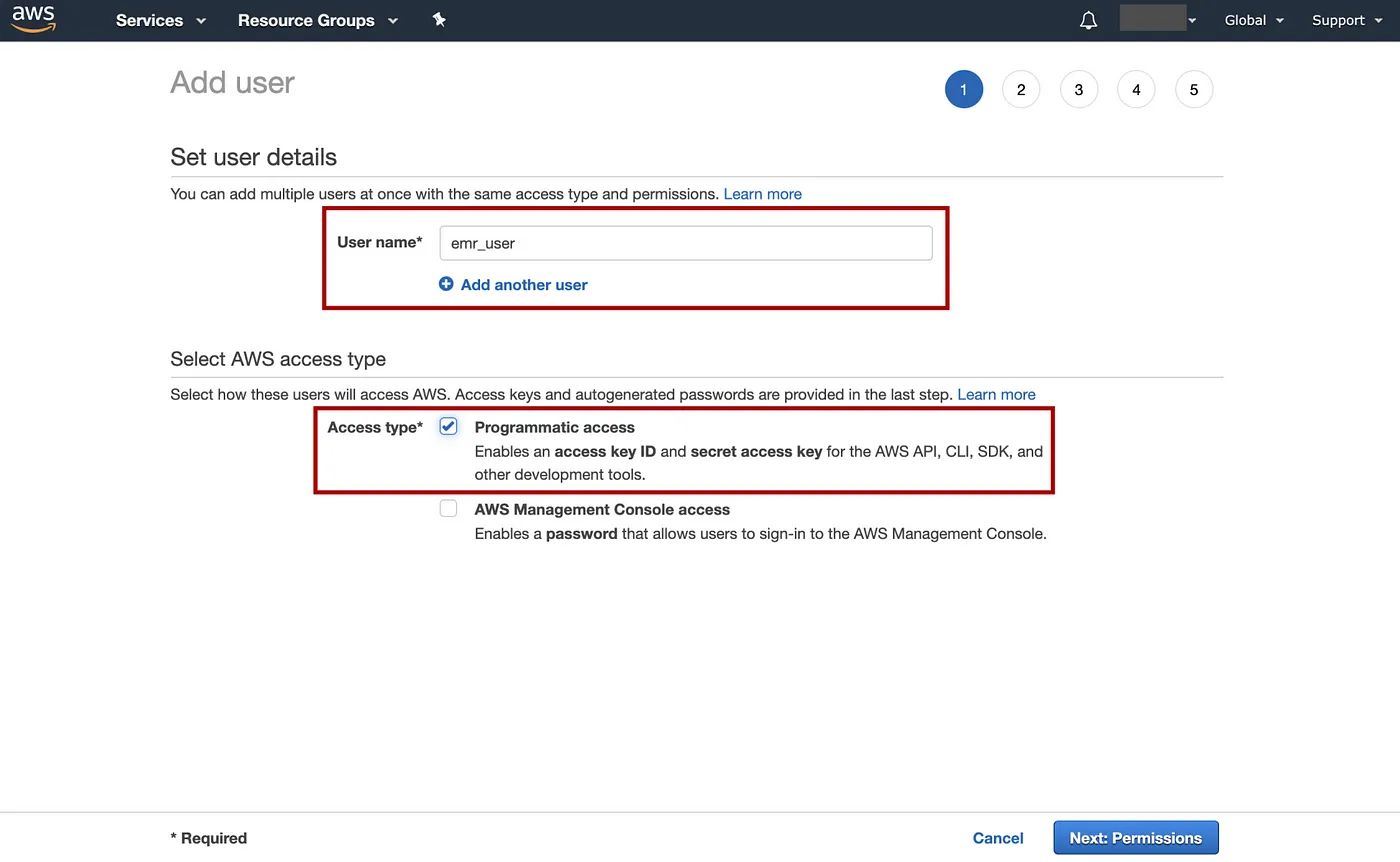
添加图片注释,不超过 140 字(可选)
单击Attach existence policies directly页面,输入并设置权限为Administrator Access,然后选择Next: Tags。
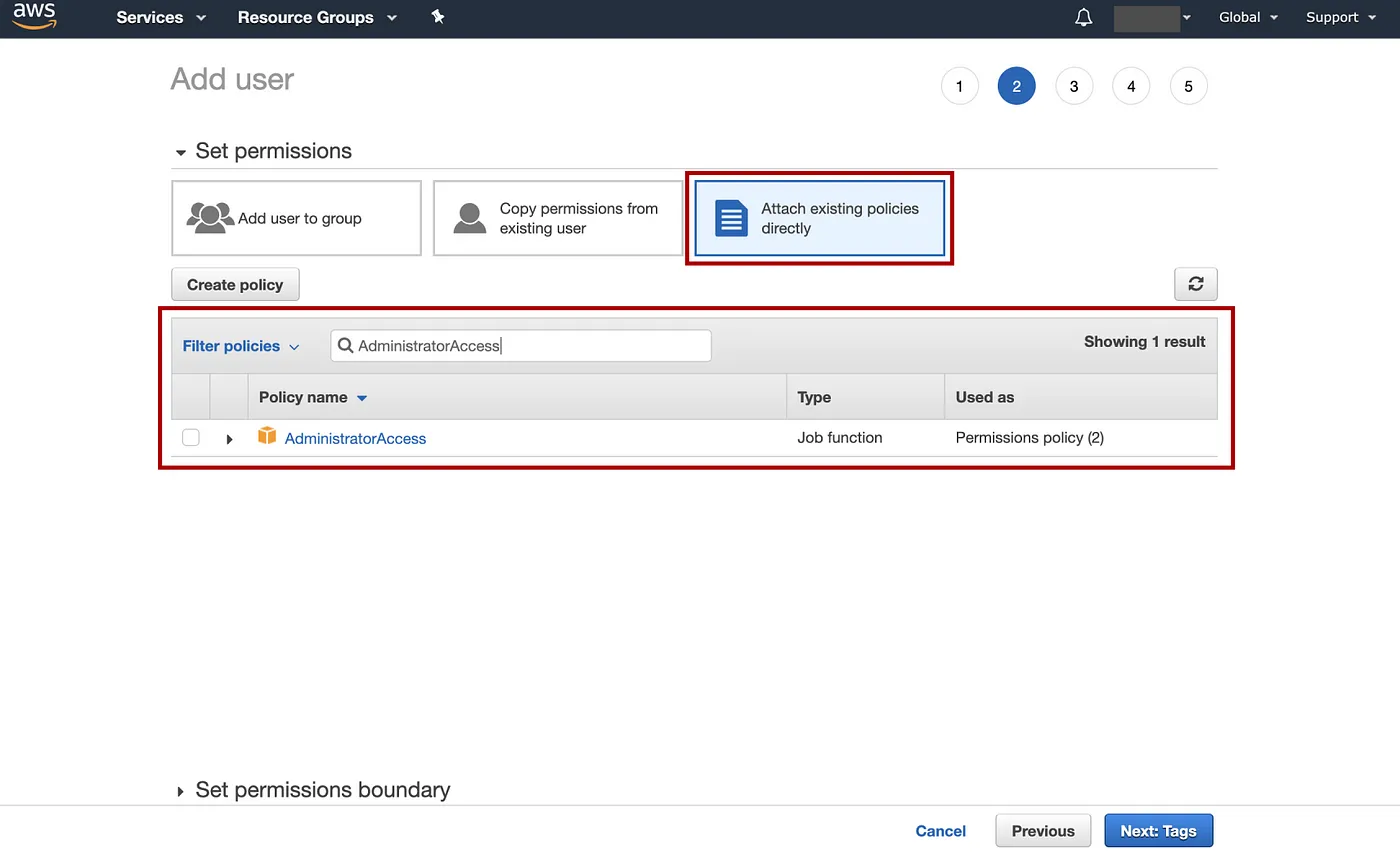
添加图片注释,不超过 140 字(可选)
跳过此标签页并选择Next: Review=> 选择Create user=> 保存用户名、访问密钥和秘密访问密钥。
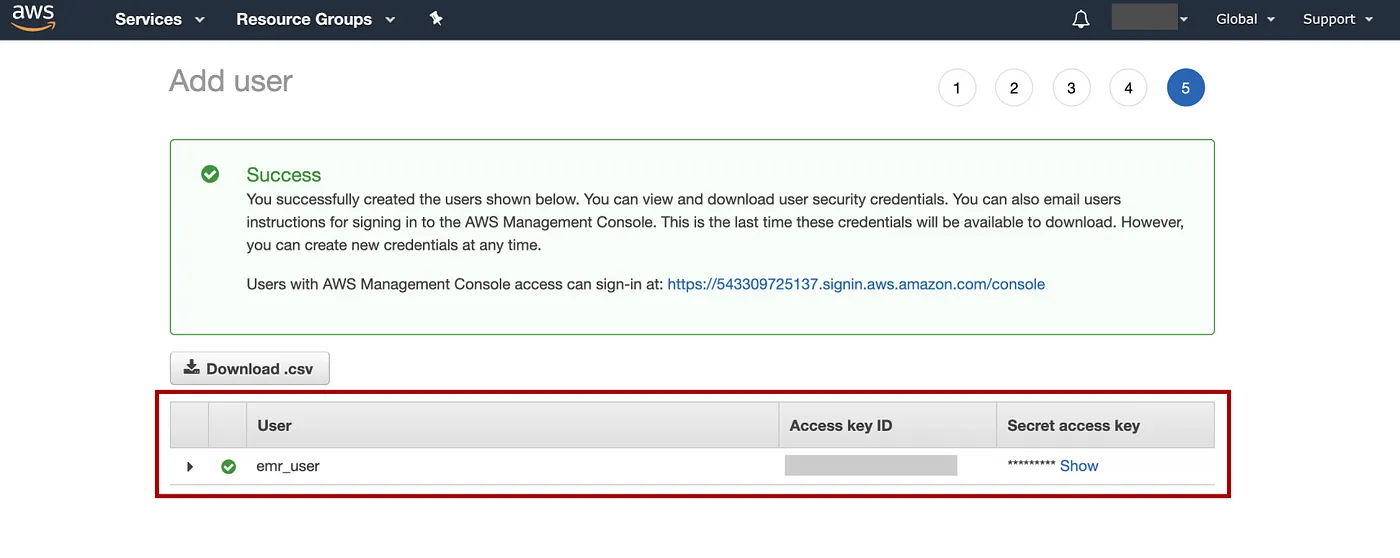
添加图片注释,不超过 140 字(可选)
我们将使用此 IAM 用户以及访问和密钥通过 AWS CLI 设置和访问 AWS。
步骤 3:在 EC2 中设置凭证
在 AWS 控制台中,单击“服务”,输入“EC2”以转到 EC2 控制台
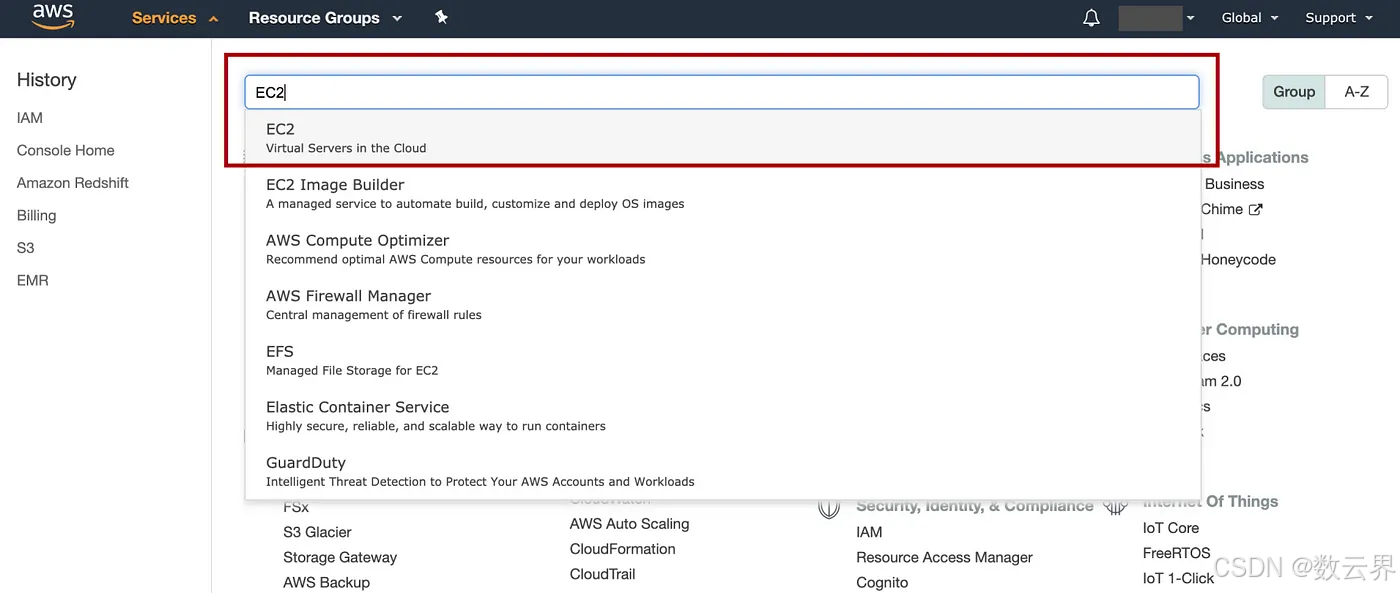
在左侧面板中Key Pairs选择“网络和安全” => 选择Create key pair
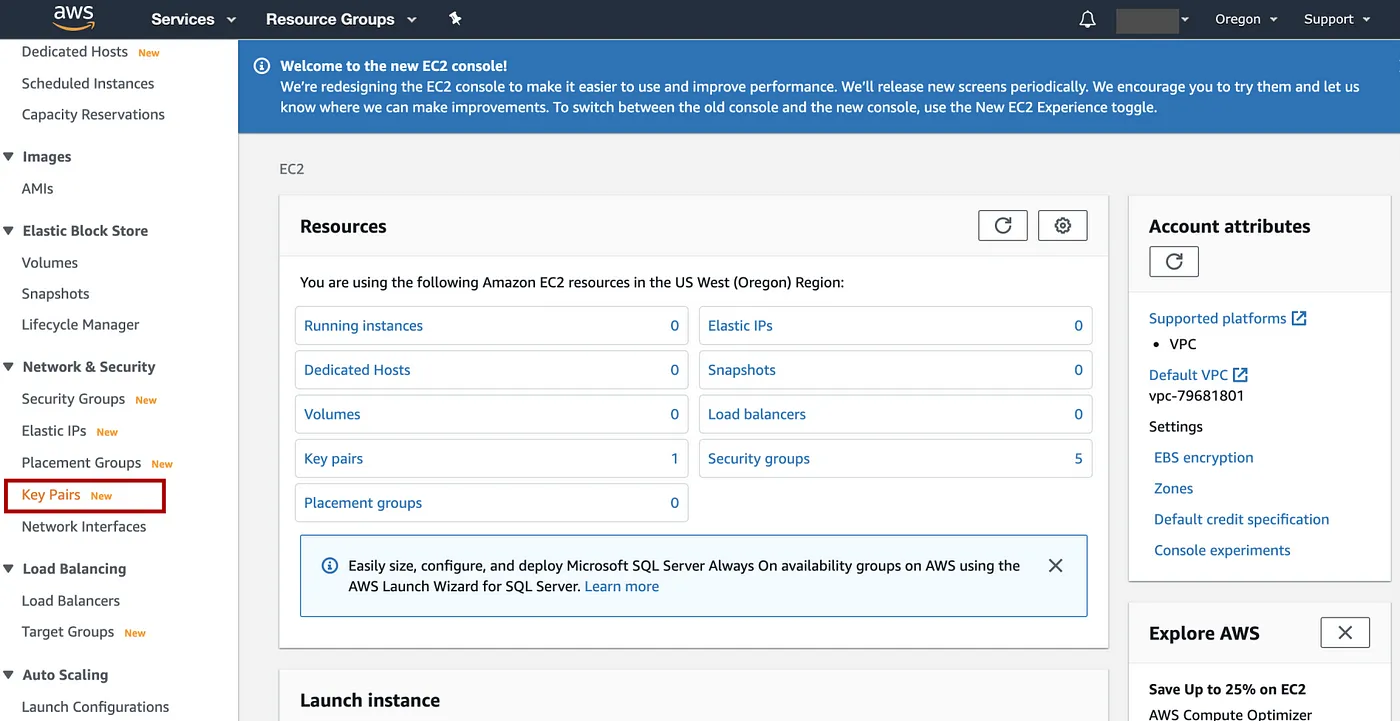
添加图片注释,不超过 140 字(可选)
输入密钥对的名称,例如“emr-cluster”,文件格式:pem => 选择Create key pair。完成此步骤后,将自动下载一个 .pem 文件,本例中文件名为emr_cluster.pem。我们将在步骤 6 中使用此文件。
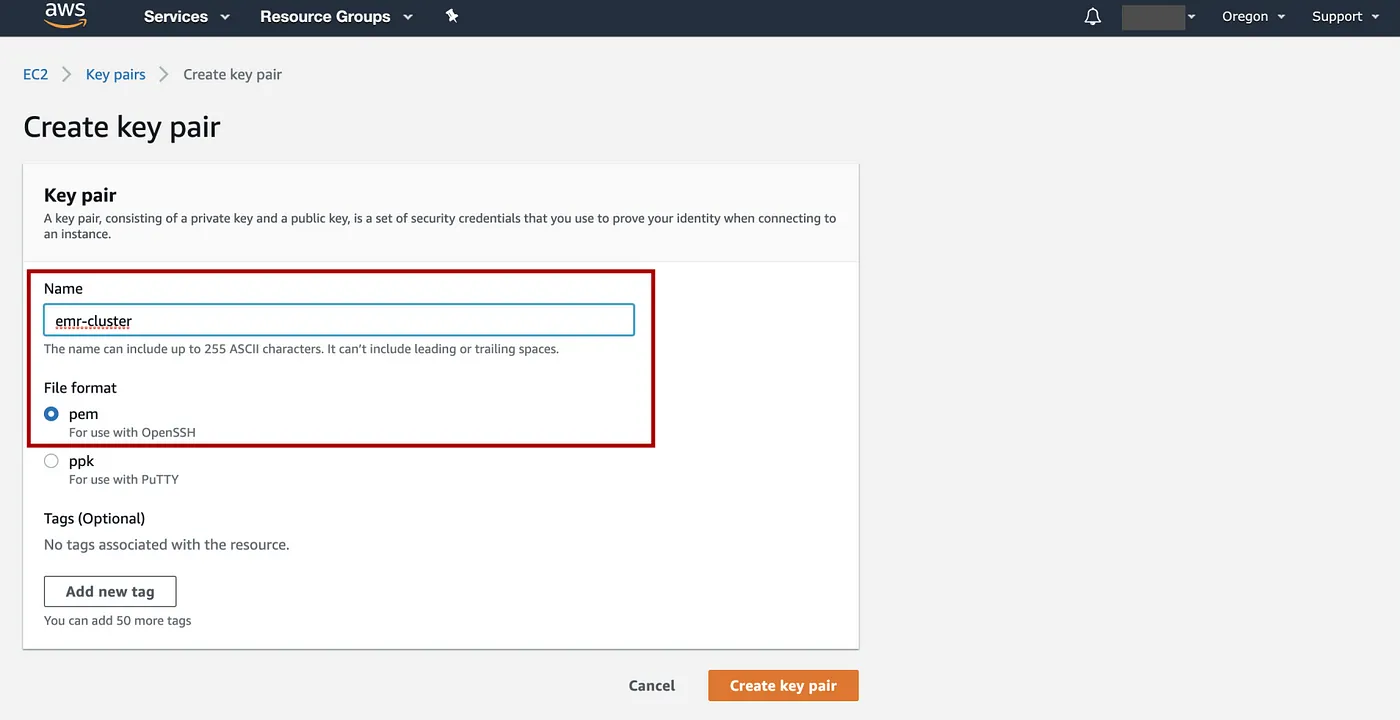
添加图片注释,不超过 140 字(可选)
步骤 4(可选):创建 S3 存储桶来存储集群生成的日志文件
-
这将是用于存储我们将要创建和设置的集群所生成的日志文件的 AWS 存储桶。如果我们不指定 S3 存储桶,则在创建和运行 EMR 集群时将自动为我们创建一个 S3 存储桶。
-
在 AWS 控制台中,单击Service,键入“S3”并转到 S3 控制台 => 选择Create bucket=> 输入存储桶的名称(例如“s3-for-emr-cluster”),选择您喜欢的区域,例如“美国西部(俄勒冈州)”。保留其他选项的默认设置以创建存储桶。
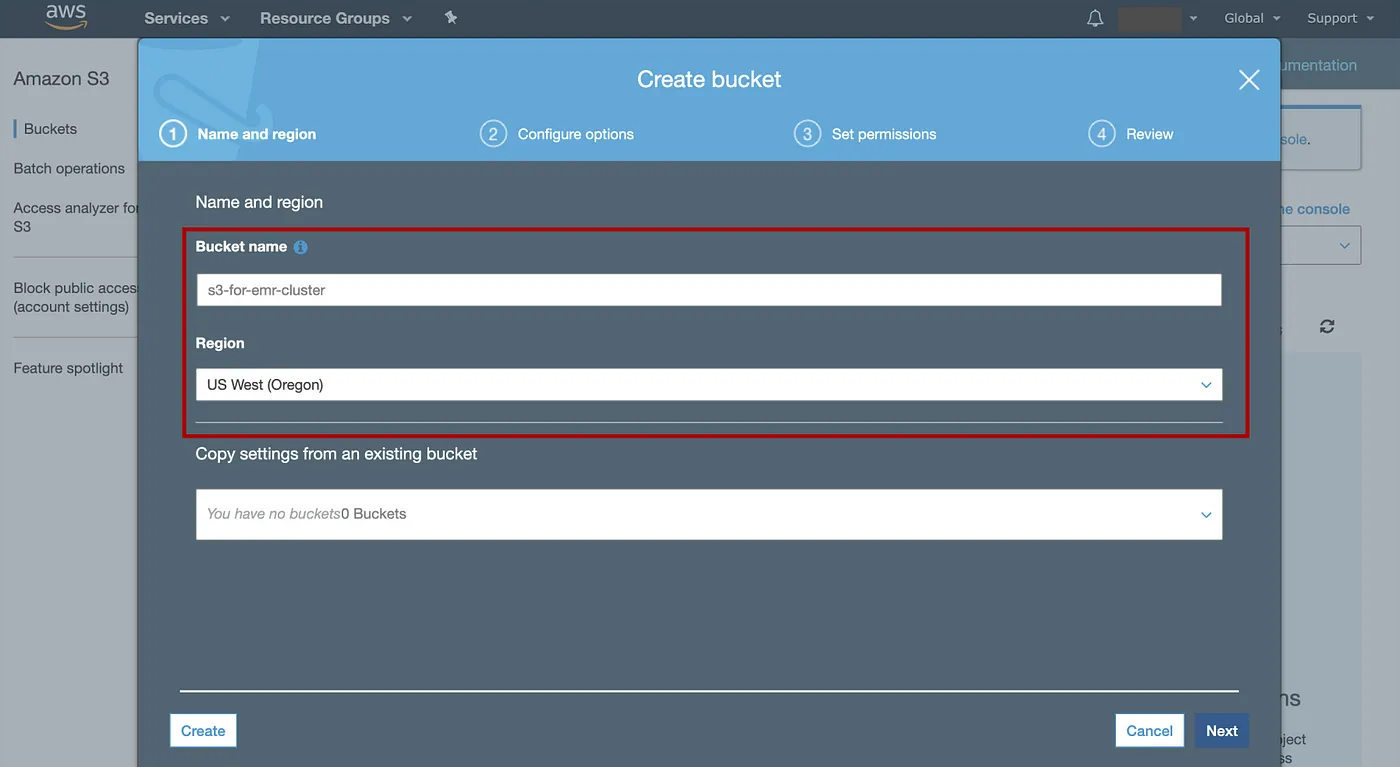
添加图片注释,不超过 140 字(可选)
-
请注意,为了获得最佳性能并避免任何错误,请记住对所有工作使用相同的 AWS 区域/子区域(在 S3、EC2、EMR 等上)
步骤 5:安装 awscli 包
-
在终端上,awscli使用命令安装pip install awscli
-
输入以下命令aws help检查安装是否正确,如果输出如下则表示安装成功:
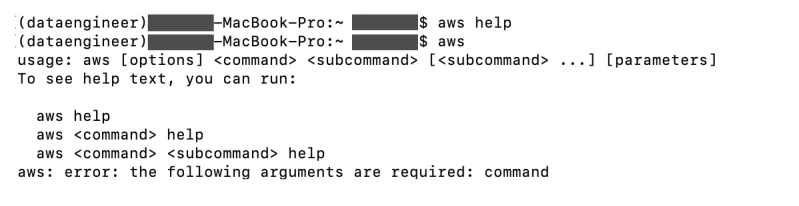
添加图片注释,不超过 140 字(可选)
步骤 6:设置 AWS CLI 环境(创建凭证和配置文件)
此步骤将帮助我们使用上面第 2 步中获得的用户凭证自动访问 awscli 环境上的 AWS。
此设置有两种方法:手动创建凭据和配置文件(方法 1)或使用命令创建这些文件aws(方法 2)。您可以使用其中任何一种。
方法 1:
credentials按照如下方式在终端上创建文件(您可以使用nano或您选择的任何其他文本编辑器):
-
在终端上,导航到所需文件夹(通常是根目录)并创建一个隐藏目录,例如aws:
$mkdir .aws(句点表示隐藏目录)
-
更改至该目录$cd .aws
-
credentials使用 nano创建文件:$nano credentials输入文件内容credentials如下(将密钥“EXAMPLE_ID”和密钥“EXAMPle_Key”替换为步骤 2 中为用户“emr-user”生成的密钥):
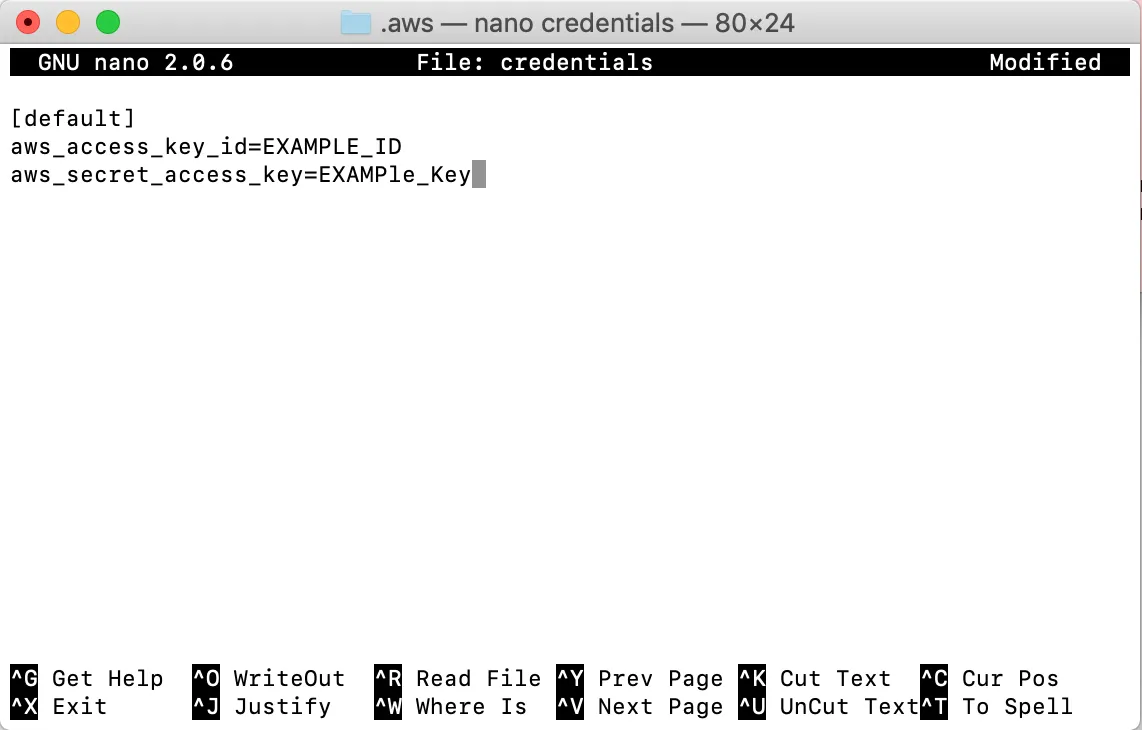
添加图片注释,不超过 140 字(可选)
-
使用Ctrl + X,然后Y保存文件并退出nano。
创建配置文件:
-
$nano config 按如下方式输入文件内容config(我们使用的区域与步骤 4 中创建 S3 存储桶所使用的区域相同):
[默认] 区域 = us-west-2
-
使用Ctrl + X,然后Y保存文件并退出nano。
方法 2:
在终端上,输入$aws configure所需的信息,如下所示:
AWS 访问密钥 ID [无]:(输入您在步骤 2 中创建的用户“emr-user”的访问密钥) AWS 秘密访问密钥 [无]:(输入您在步骤 2 中创建的用户“emr-user”的秘密密钥) 默认区域名称 [无]:us-west-2(与步骤 4 中使用的区域相同) 默认输出格式 [无]:
这 2 个文件将自动创建在隐藏文件夹 .aws 中,通常位于根目录下,如下所示:
-
$cd ~/.aws
-
键入$ls 以验证这两个文件是否存在。信息应与方法 1 中的信息相同,我们可以通过键入以下内容来检查内容:
-
$cat credentials
-
$cat config
准备步骤3中生成的.pem文件
要连接到集群,我们需要在步骤 3 中创建的 .pem 文件。将我们在步骤 3 中下载的 .pem 文件移动到项目所需的位置。对我来说,我将其放在与位于根目录的隐藏文件夹 .aws 中的凭证和配置文件相同的位置~/.aws/emr-cluster.pem)
$ mv ~/Downloads/emr-cluster.pem 。
-
当使用此 .pem 文件设置 ssh 时,如果 .pem 文件过于开放,则会出现错误。警告的示例如下:“ Permissions 0644 for '~/.aws/emr-cluster.pem' are too open. It is required that your private key files are NOT accessible by others. This private key will be ignore. ”
-
在这种情况下,我们需要使用以下命令更改此.pem 文件的权限:sudo chmod 600 ~/.aws/emr-cluster.pem
验证我们是否成功安装了 awscli 包并设置了凭证
要验证我们是否成功安装 awscli 并设置凭证,请输入一些 aws 命令,例如
-
列出所有 IAM 用户:$aws iam list-users
-
列出 s3 中的所有存储桶:$aws s3 ls此命令将列出我们在 AWS 中拥有的所有 s3 存储桶:

添加图片注释,不超过 140 字(可选)
步骤 7:创建 EMR 集群
现在我们准备在终端上创建我们的 EMR 集群。在终端上,输入以下命令:
aws emr create-cluster --name test-emr-cluster --use-default-roles --release-label emr-5.28.0 --instance-count 3 --instance-type m5.xlarge --applications Name=JupyterHub Name=Spark Name=Hadoop --ec2-attributes KeyName=emr-cluster --log-uri s3://s3-for-emr-cluster/
EMR脚本组件的解释:
-
--name:集群的名称,在本例中为“test-emr-cluster”
-
--use-default-roles:使用默认服务角色 (EMR_DefaultRole) 和实例配置文件 (EMR_EC2_DefaultRole) 获得访问其他 AWS 服务的权限
-
--release-label emr-5.28.0:使用EMR版本5.28.0构建集群
-
--instance-count 3和--instance-type m5.xlarge:构建 1 个主节点和 2 个 m5.xlarge 类型的核心节点
-
--applications Name=JupyterHub Name=Spark Name=Hadoop:在此集群上安装 JupyterHub、Spark 和 Hadoop
-
--ec2-attributes KeyName=emr-cluster:配置 Amazon EC2 实例配置,KeyName 是我们在步骤 3(Set up credentials in EC2并获取 .pem 文件)中设置的 EC2 实例名称。在本例中,名称为emr-cluster。
-
--log-uri s3://s3-for-emr-cluster/:指定要存储日志文件的 S3 存储桶。在本例中,S3 存储桶为“s3-for-emr-cluster”。此字段是可选的(如步骤 4 中所述)。
-
由于 EMR 集群价格昂贵,我们可以选择--auto-terminate在集群上的所有操作完成后自动终止集群。要使其工作,我们还需要在命令中使用 指定引导操作--bootstrap-actions Path="s3://bootstrap.sh"。当您使用自动终止时,集群将启动,运行您指定的任何引导操作,然后执行通常输入数据、处理数据然后生成和保存输出的步骤。步骤完成后,Amazon EMR 会自动终止集群 Amazon EC2 实例。如果我们不设置任何引导操作,我们应该删除此字段。可以在AWS 站点上详细找到有关引导的参考。
创建 EMR 集群后的期望输出是:
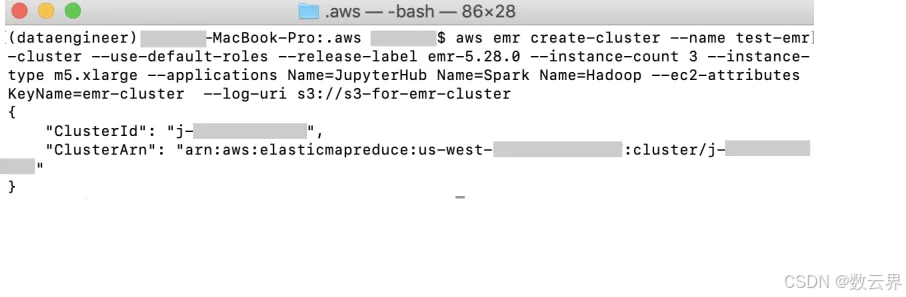
使用 ClusterId 检查集群的状态和信息(j- EXAMPLECLUSTERID)使用以下命令:
aws emr describe-cluster --cluster-id j-EXAMPLECLUSTERID
我们应该等待几分钟直到集群可用(状态变为“可用”)然后再继续下一步。
***更新 1:如果您在创建 Amazon EMR 集群时遇到问题"EMR_DefaultRole is invalid" or "EMR_EC2_DefaultRole is invalid" error,则可能必须删除角色和实例配置文件;然后按照此说明重新创建角色。
***更新 2:为了使集群可供 EMR 上的笔记本使用,我们可能需要在 —ec2-attributes 中包含 SubnetIds:
aws emr create-cluster --name test-emr-cluster --use-default-roles --release-label emr-5.28.0 --instance-count 3 --instance-type m5.xlarge --applications Name=JupyterHub Name=Spark Name=Hadoop --ec2-attributes SubnetIds=subnet-YOURSUBNET, KeyName=emr-cluster --log-uri s3://s3-for-emr-cluster/
如何查找 SubnetIds?
单击EMR 控制台上的VPCSubnets选项卡,从列表中进行选择。
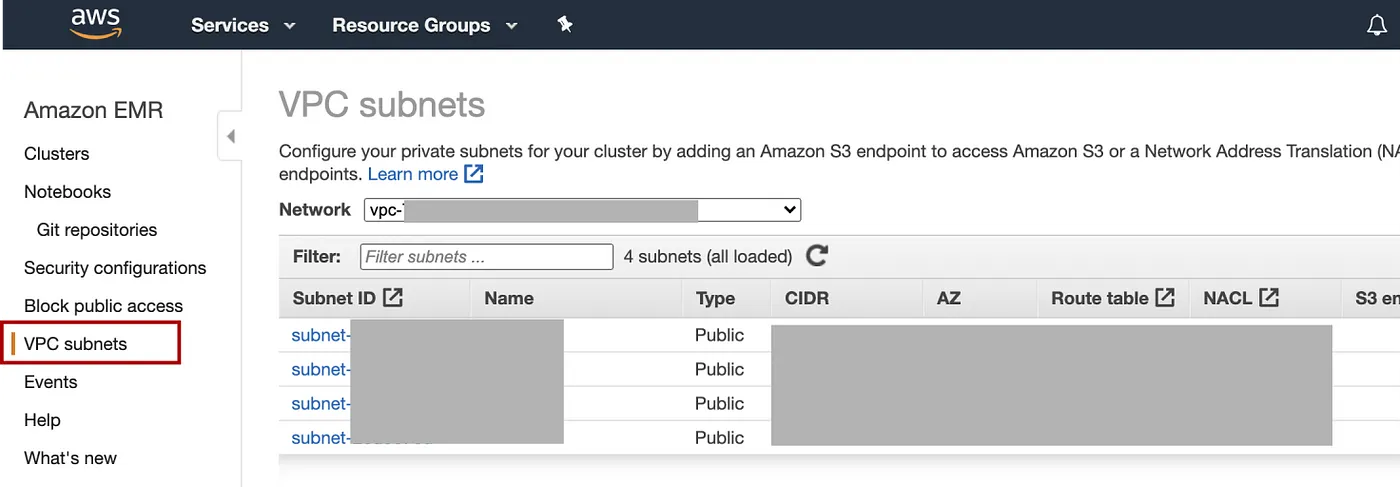
添加图片注释,不超过 140 字(可选)
对于初学者来说,另一种安全的方法:使用 AWS 控制台创建类似的 EMR 集群。然后查看该集群的“摘要”页面上的“网络和硬件”会话以查看子网 ID:
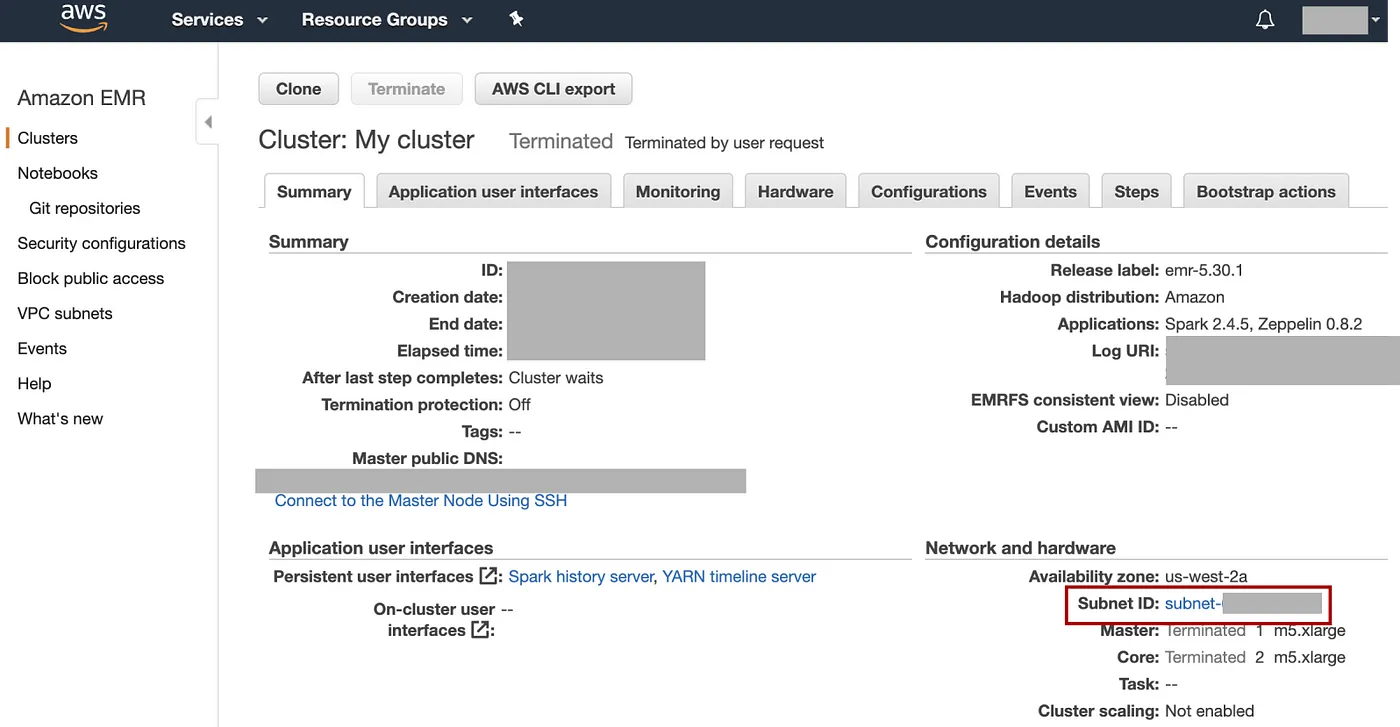
添加图片注释,不超过 140 字(可选)
您可以通过AWS 上的 VPC 仪表板访问子网。有关子网和 VPC 的更多信息,请参阅AWS 站点。
步骤8:允许SSH访问
在 AWS 控制台中,单击Service,输入 EMR,然后转到 EMR 控制台。
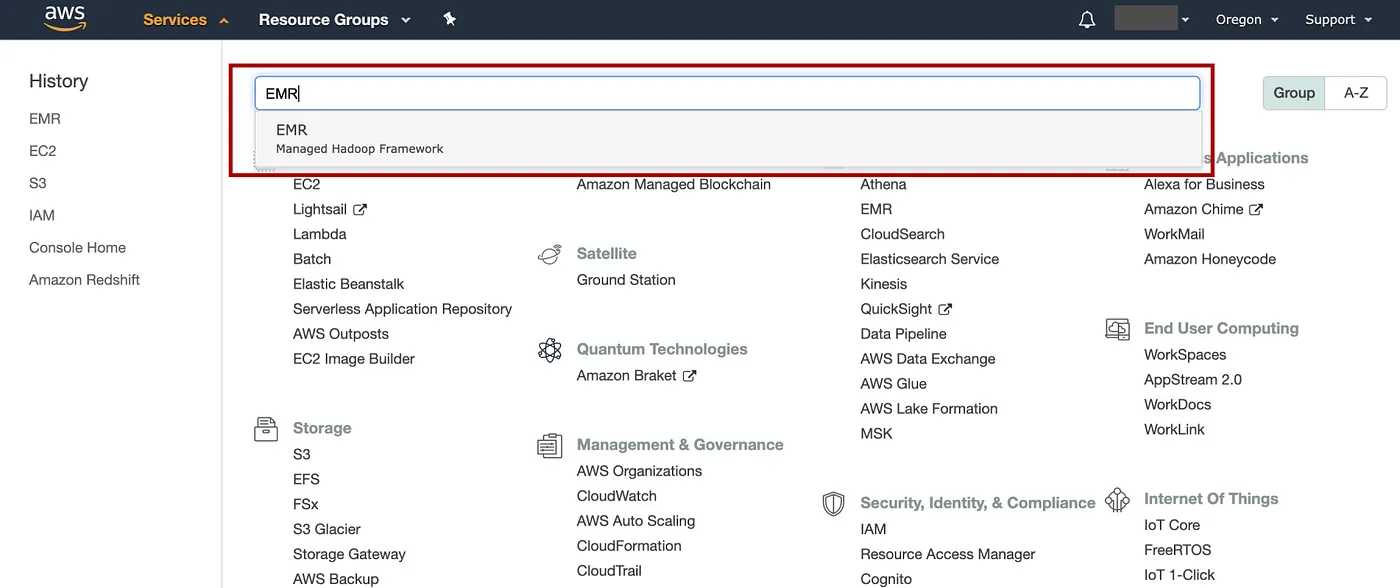
添加图片注释,不超过 140 字(可选)
=> 选择Clusters=> 在列表中选择集群的名称,在本例中为test-emr-cluster
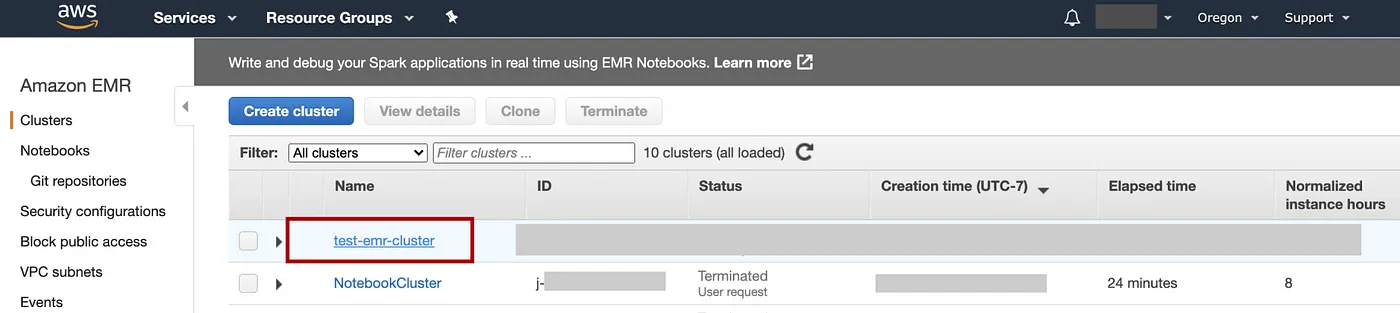
添加图片注释,不超过 140 字(可选)
在Summary标签上,向下滚动以查看部分Security and access,选择Security groups for Master链接
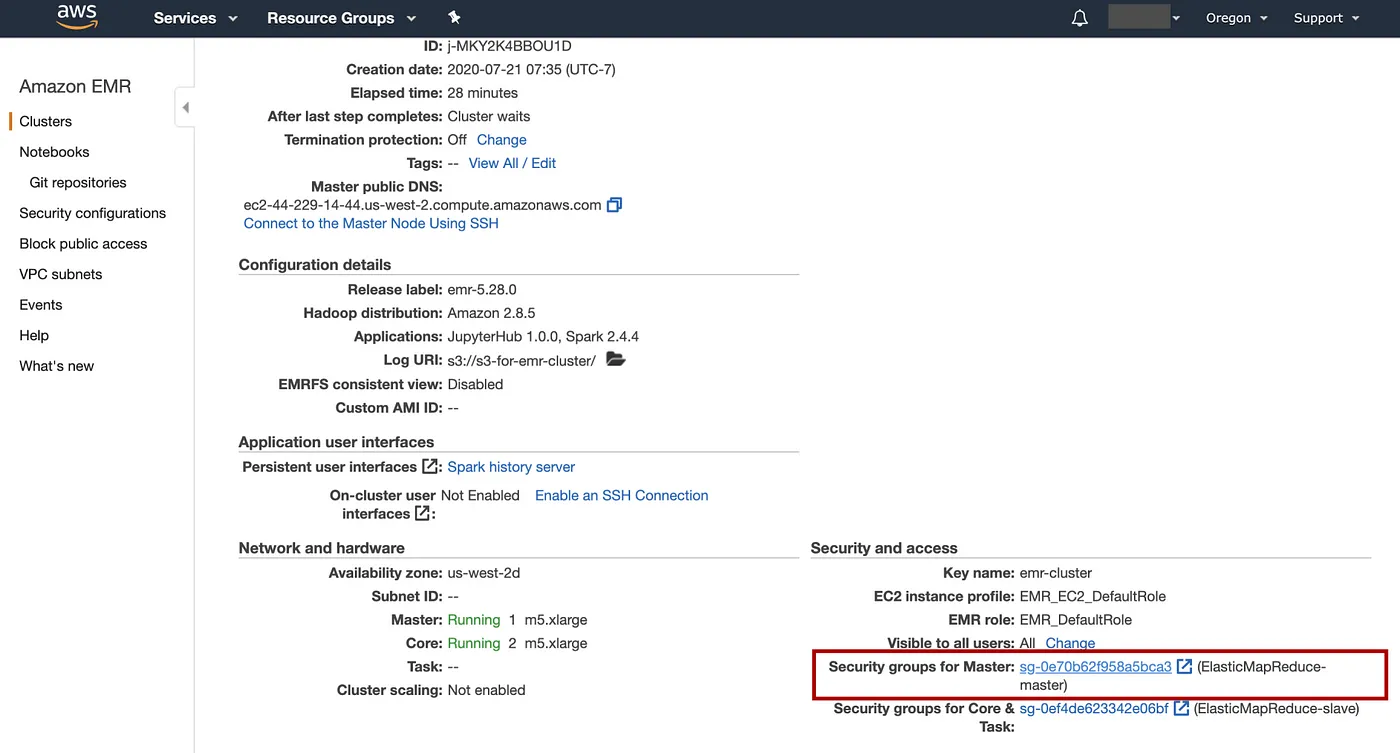
选择Security group IDElasticMapReduce-master
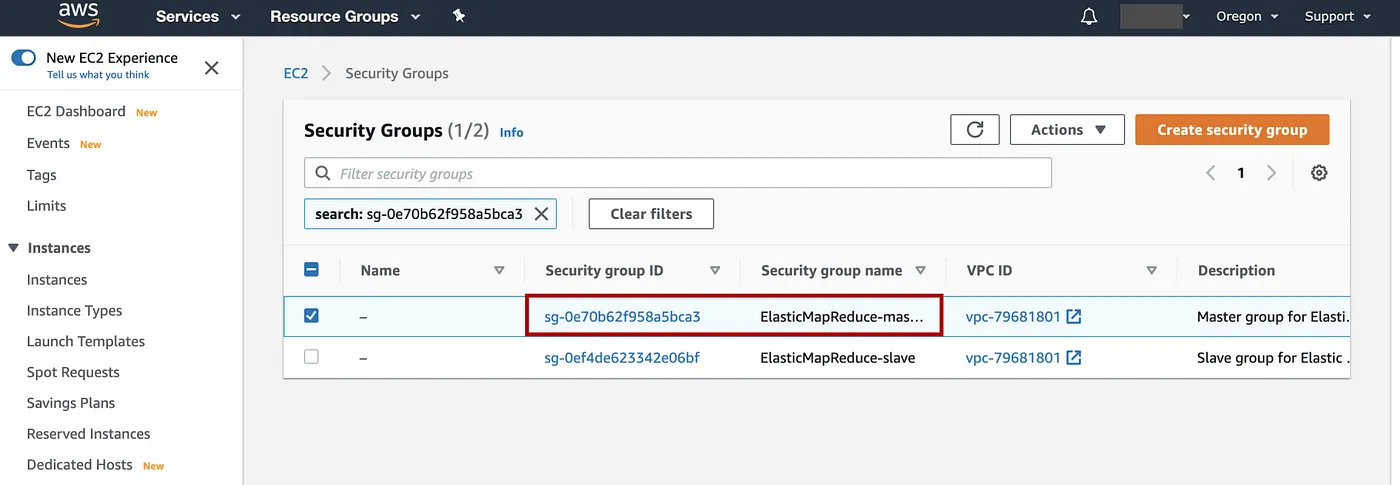
添加图片注释,不超过 140 字(可选)
向下滚动到Inbound rules,Edit inbound rules=> 为了安全起见,删除任何 SSH 规则(如果有),然后选择Add Rule=> 选择类型:SSH,协议为 TCP,端口范围为 22 => 对于源,选择我的 IP => 选择Save。
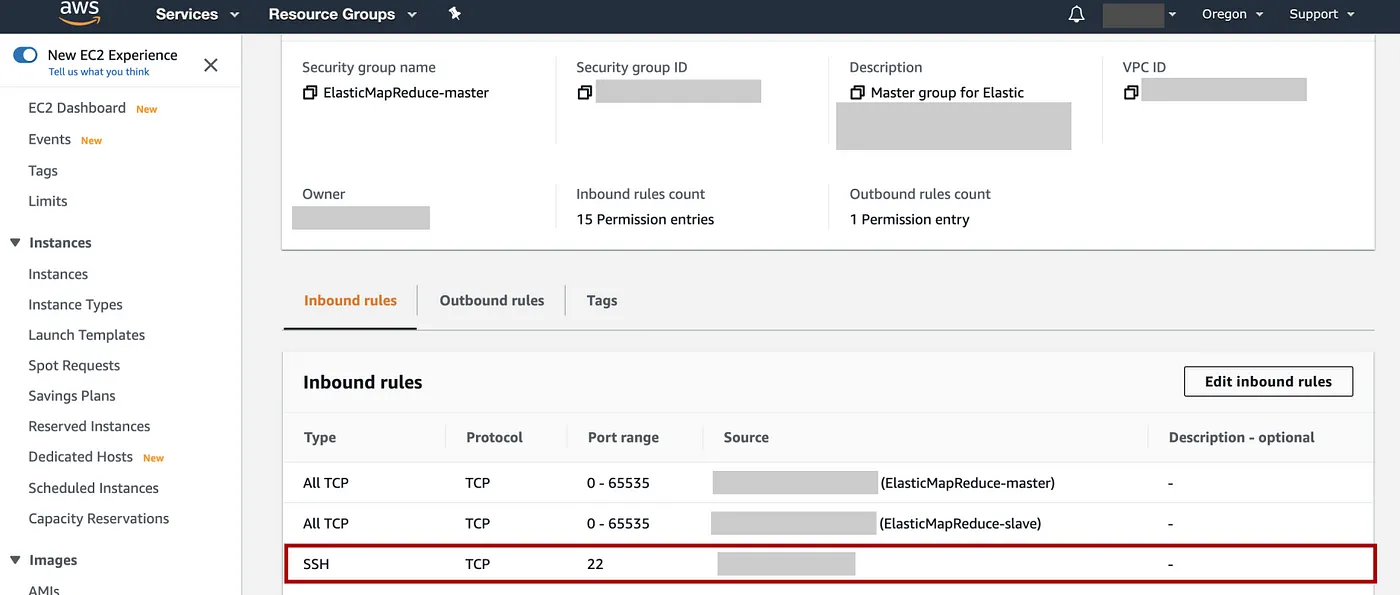
步骤 9:与集群的主节点创建 SSH 连接
方法 1:
-
在终端上,使用以下命令检查集群的 ID
aws emr list-clusters
-
使用此命令连接到集群。请记住指定 .pem 文件的正确路径:
aws emr ssh --cluster-id j-EXAMPLECLUSTERID --key-pair-file ~/.aws/emr-cluster.pem
如果我们看到如下所示的带有 EMR 字母的屏幕,那么恭喜您,您已成功使用 AWS CLI 创建、设置和连接到 EMR 集群 !!!!
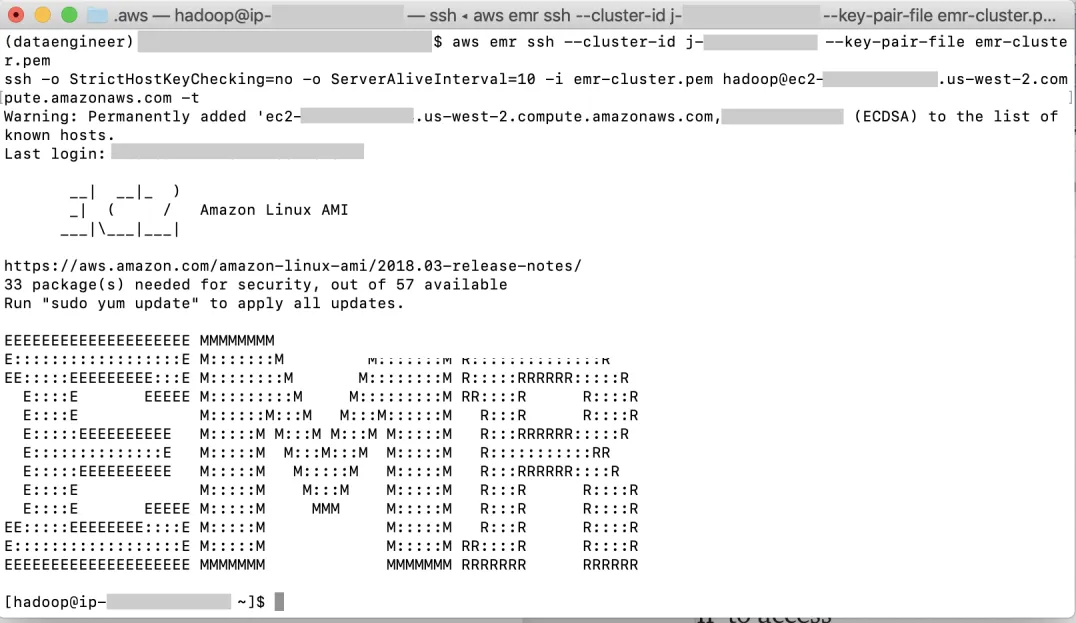
添加图片注释,不超过 140 字(可选)
使用命令关闭与集群的连接$logout。
方法 2:
-
在 AWS 控制台中,单击Service,输入 EMR,然后转到 EMR 控制台。
-
选择Clusters=> 单击列表上的集群名称,在本例中test-emr-cluster=> 在“摘要”选项卡上,单击链接“使用 SSH 连接到主节点”。
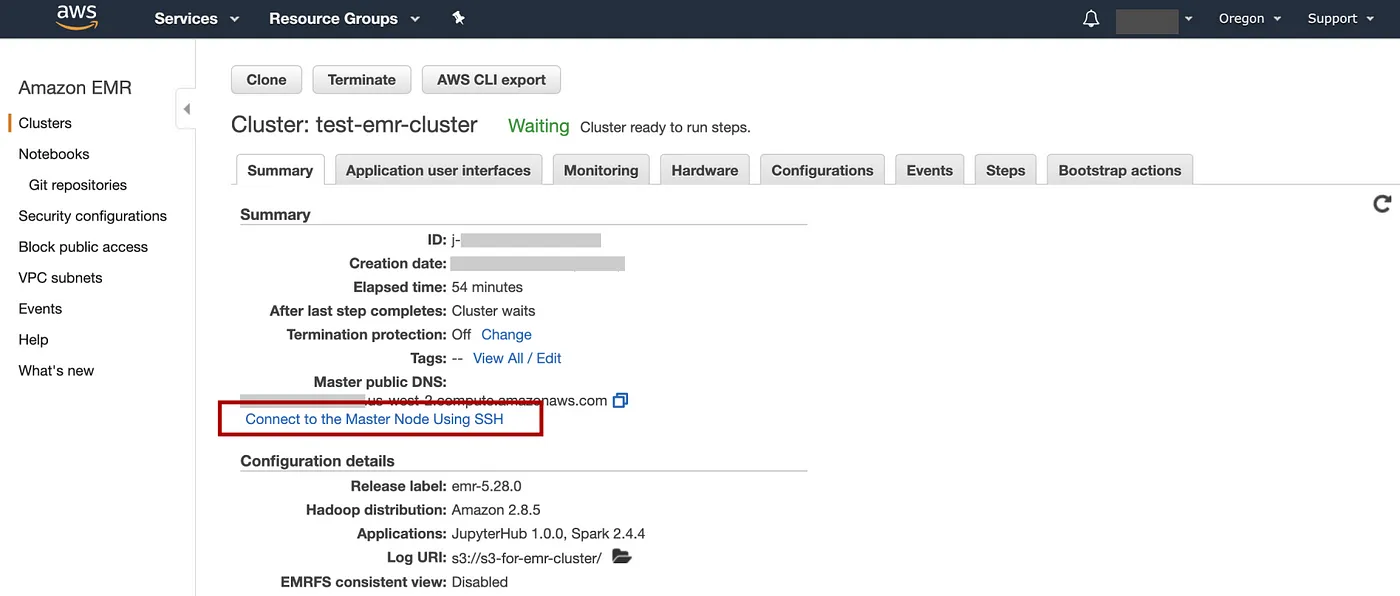
添加图片注释,不超过 140 字(可选)
-
复制弹出窗口上显示的命令并将其粘贴到终端上。
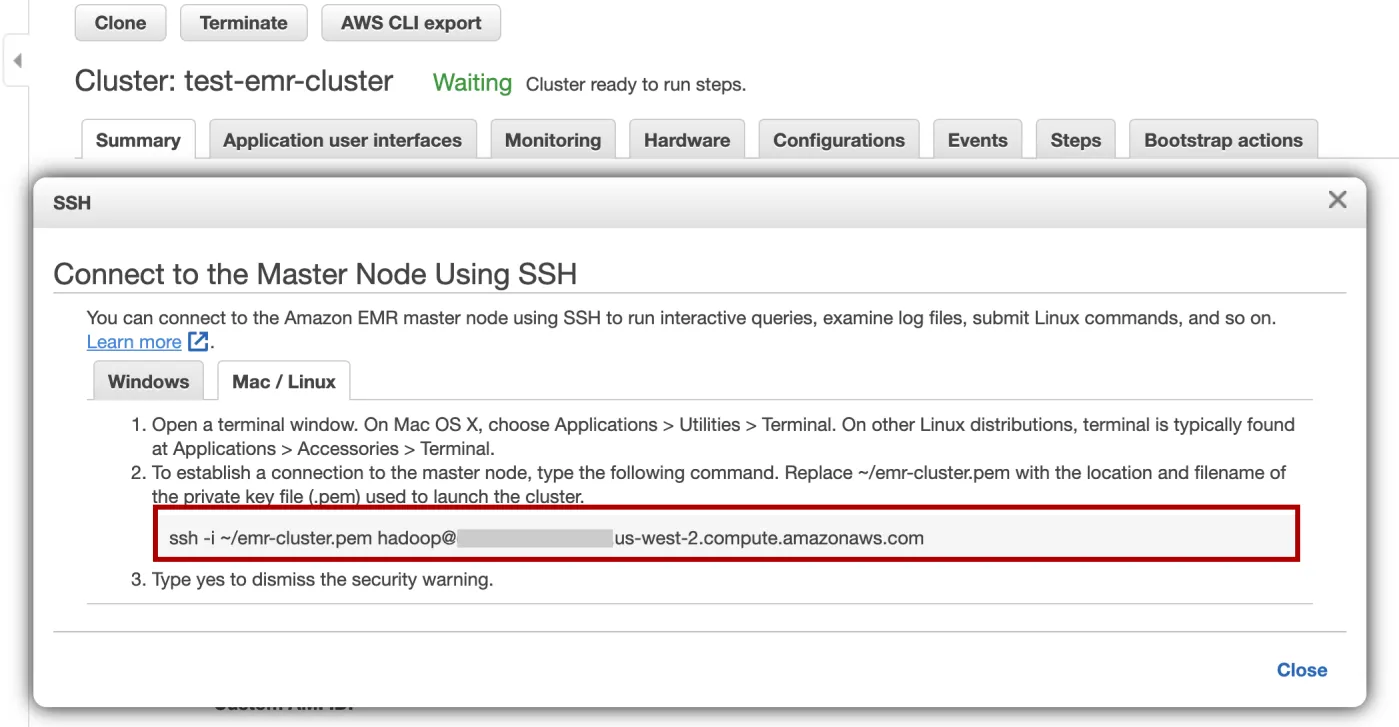
-
记得将 ~/emr-cluster.pem 替换为我们设置的私钥文件 (.pem) 的位置和文件名。例如
ssh -i ~/.aws/emr-cluster.pem hadoop@ec2-xx-xxx-xx-xx.us-west-2.compute.amazonaws.com
如果我们看到带有 EMR 信件的屏幕,那么恭喜您,您已成功使用 AWS CLI 创建、设置并连接到 EMR 集群!!!!
现在您可以开始使用 EMR 集群
创建一个简单的 Spark 任务,例如,创建一个包含时间类型字符串的 Spark 数据框,然后将该列转换为不同的格式。
在集群终端上,创建文件test_emr.py
$nano 测试_emr.py
将此脚本复制并粘贴到 test_emr.py
### 文件“test_emr.py”的内容从 pyspark.sql 导入 SparkSession,功能与 F 相同if __name__ == "__main__": """ 提交给spark集群的脚本示例 """ spark = SparkSession.builder.getOrCreate() df = spark.createDataFrame([('01/Jul/1995:00:00:01 -0400', ),('01/Jul/1995:00:00:11 -0400',),('26/Jul/1995:17$ ('19/Jul/1995:01:56:43 -0400',), ('11/Jul/1995:12:50:18 -0400',)], ['TIME']) df = df.withColumn("date", F.unix_timestamp(F.col('TIME'), 'dd/MMM/yyyy:HH:mm:ss Z').cast('timestamp')) # 显示数据框 df.show() ####停止spark,否则程序将被挂起 spark.stop()
该文件的内容在nano文本编辑器中显示:
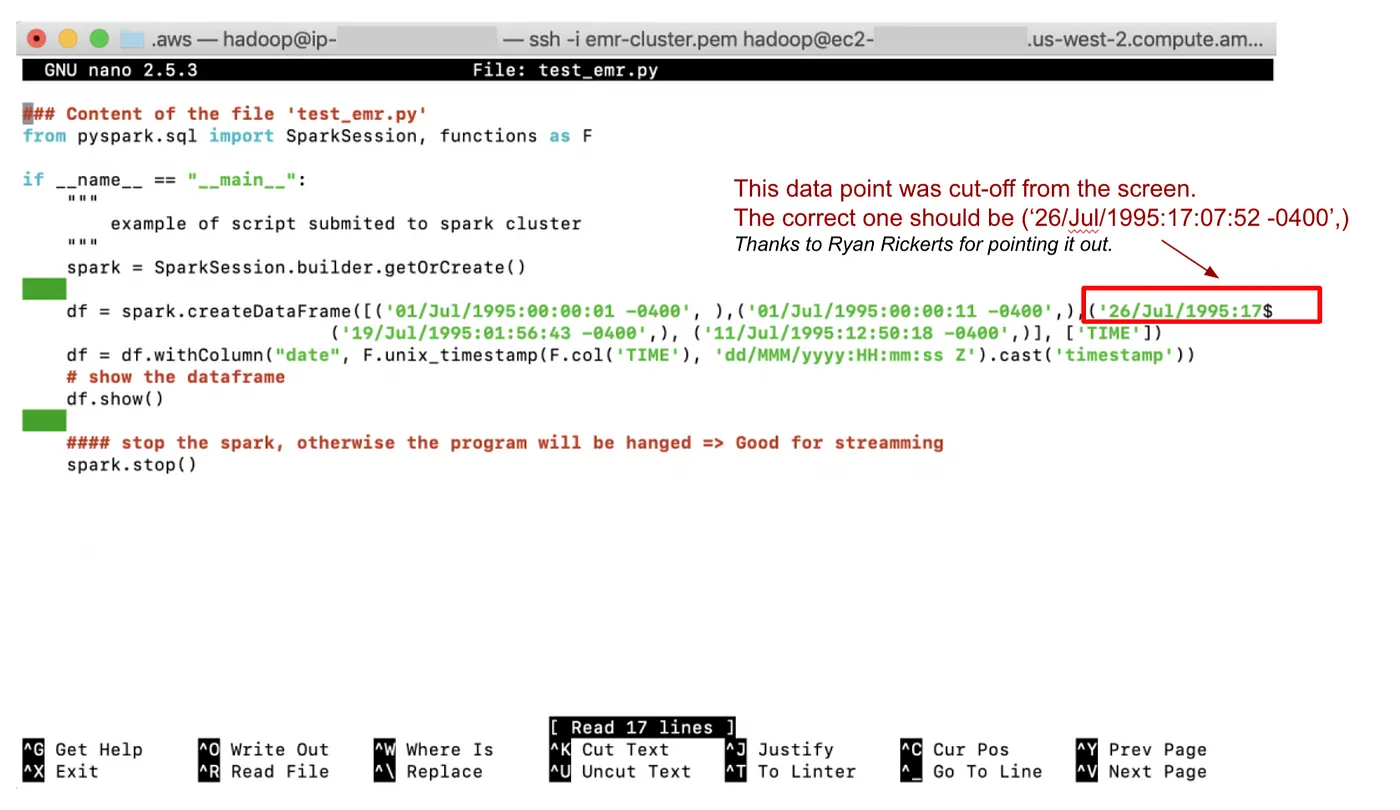
添加图片注释,不超过 140 字(可选)
使用以下命令在集群终端上提交脚本:
$spark-submit --master yarn ./test_emr.py
当任务运行时,终端上可能会出现大量信息,这在 Spark 中很正常。输出可以在信息日志中找到:
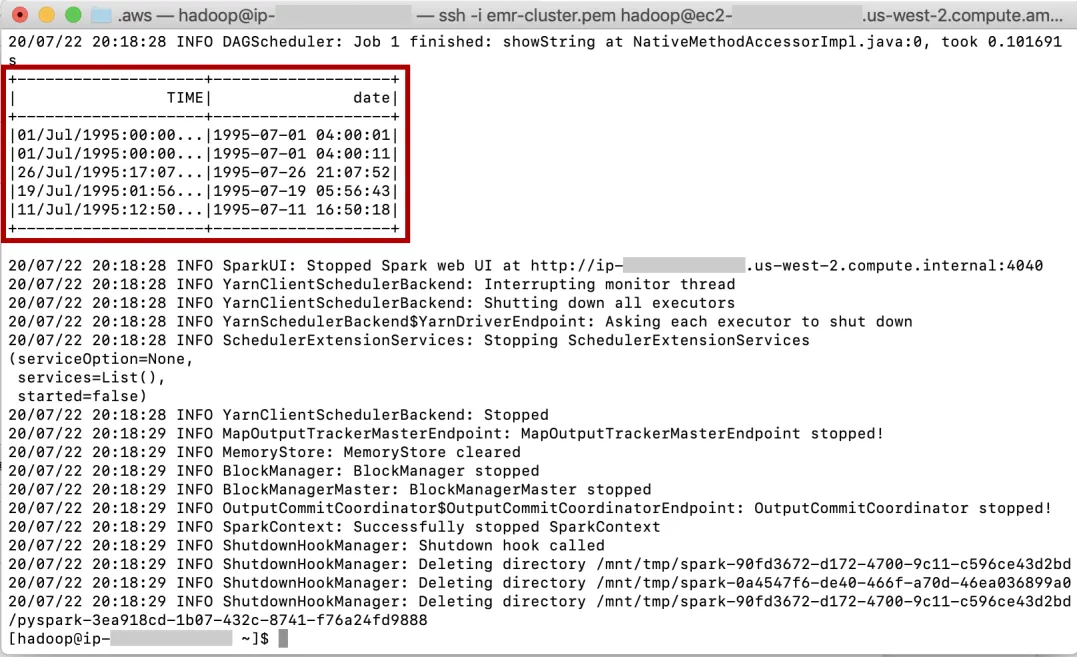
添加图片注释,不超过 140 字(可选)
恭喜!你成功了!
当不再使用集群时,请记得终止它。
键入logout以退出集群。然后使用以下命令终止集群:
$a ws emr 终止集群--cluster-id j-EXAMPLECLUSTERID
请注意,我们可以使用 AWS CLI 命令轻松地再次创建具有相同配置的集群AWS CLI export,在 EMR 控制台上选择已终止的集群“test-emr-cluster”时单击选项卡即可找到该命令:
添加图片注释,不超过 140 字(可选)
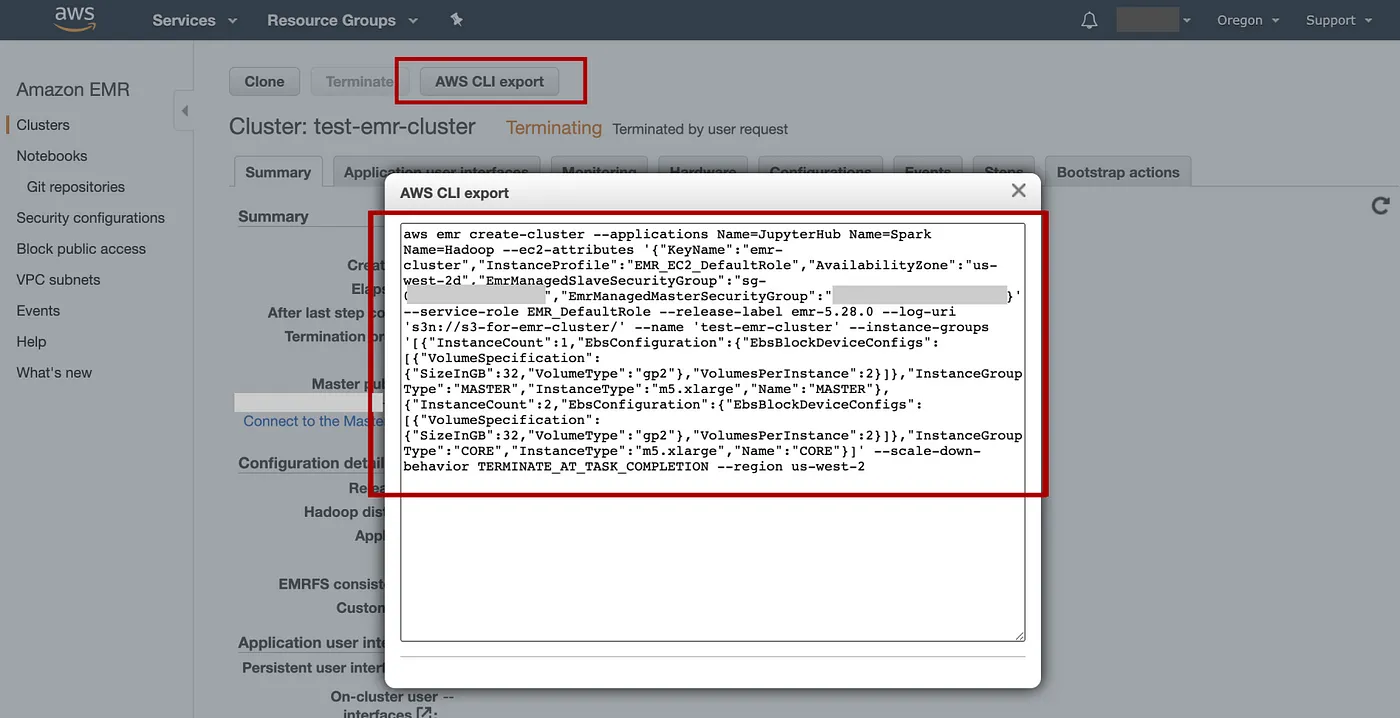
添加图片注释,不超过 140 字(可选)
我希望大家不再需要费力使用 AWS CLI 在 EMR 上创建、设置和运行 Spark 集群。如果您遇到任何问题或发现本教程有任何错误,请告诉我。
感谢关注雲闪世界。(Aws解决方案架构师vs开发人员&GCP解决方案架构师vs开发人员)
订阅频道(https://t.me/awsgoogvps_Host) TG交流群(t.me/awsgoogvpsHost)
#aws CLI cheat sheet #aws cli Debug #aws cli get S3 object #aws cli login with access key #aws cli to download from s3 #aws command line download from s3 #homebrew install aws cli#aws sdk get caller identity #aws s3 cli get object #aws s3 put object#aws s3 headobject#aws s3 put-object #aws s3 sync vs cp