拍短视频,开始的时候是真人语音,之后是电脑配音,今年年初剪映上线了克隆语音,很多人都用起来了。
想要克隆别人的语音怎么办?
之前需要用 GPT-SoVITS 训练声音模型,操作复杂,对电脑配置要求较高,关键是生成时间非常长,这对小白来说还是很有挑战的。
不过,随着开源社区的努力,语音克隆已经零门槛了,一个人人有嘴替的时代已经到来。
上一篇:cosyvoice 给大家介绍了一款语音合成/克隆工具,今天再分享一款同样火爆的语音合成工具 - Fish Speech,使用起来更为方便。
有了这款语音克隆神器,再配合上其他 AI 工具,帮你哗哗涨粉,绝绝子。
本文分享,带大家在线体验 Fish Speech,并在本地部署起来,方便随时调用。
老规矩,先来简单介绍下~
1. Fish Speech 简介
且看官方是怎么宣传的:
- 开源低显存、能说绕口令、支持中英日3语种!
- 语音处理接近人类水平,效果媲美GPT-SoVITS

真的假的?我们一起探究一番!
2. 在线体验
体验地址:https://fish.audio/zh-CN/
虽是个开源项目,但是官方提供了在线网站,随手就使用,每天免费送你 50 配额,可以生成 50 条音频。
2.1 海量音色样板
官方提供了上百款音色,供你选择,其中爆火的丁真已经被配音了18w+:

此外,创作者也可以上传自己训好的音色,比如川普、邓紫棋……
搜索即用,无需自己训练。
2.2 语音合成初体验
既然川建国的粉丝这么多,给川普安排上一段绕口令怎么样?

给大家展示两段,看看效果如何?
合成文本1:
扁担长,板凳宽,扁担没有板凳宽,板凳没有扁担长。
扁担绑在板凳上,板凳不让扁担绑在板凳上。
语音合成效果:体验地址
合成文本2:
细蝉吸细竹枝汁,
细竹枝汁细蝉吸。
细蝉吸汁竹枝细,
细竹枝细汁蝉吸。
语音合成效果:体验地址
2.3 声音克隆
官网那么多音色模型,没你满意的?
来吧,自己训练一个:

注意:声音文件时长最短10秒,最长45秒,不出 2 分钟,你的声音模型就 Ready 了。
创建成功后,在 我的声音 中可以查看。

有一说一:Fish Speech 从情感、语速、语调、音色训练各方面都是OK的!速度极快!
但不要输入太长文本,否则会罢工的~
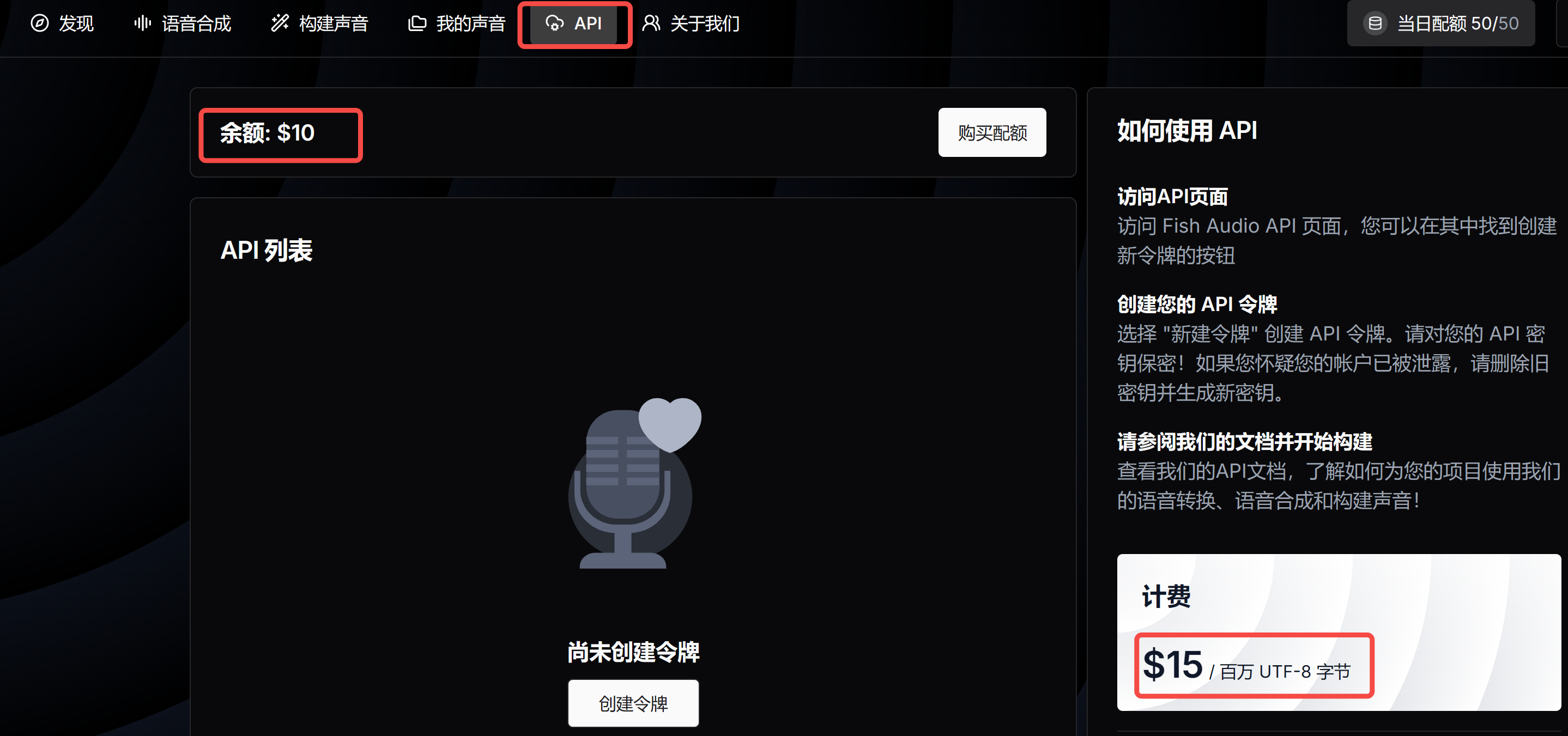
2.4 API 调用
官方给开发者也提供了 API 调用,新人注册有 10 元的免费体验额度:
当然,如果你有机器,完全可以自己本地部署一个,毕竟项目是开源的嘛!
下面,我们一起动手实操一番。
3. 本地部署
项目地址:https://github.com/fishaudio/fish-speech/
项目文档:https://speech.fish.audio/
这部分我们采用趋动云的 GPU 实例给大家做演示,申请一个 6G 显存的实例就够。
新人注册送 100 点算力,还没注册的小伙伴赶紧去薅羊毛,:趋动云注册
3.1 申请云实例
不了解项目创建流程的小伙伴可以参考这篇:CosyVoice 实测,阿里开源语音合成模型,3s极速语音克隆
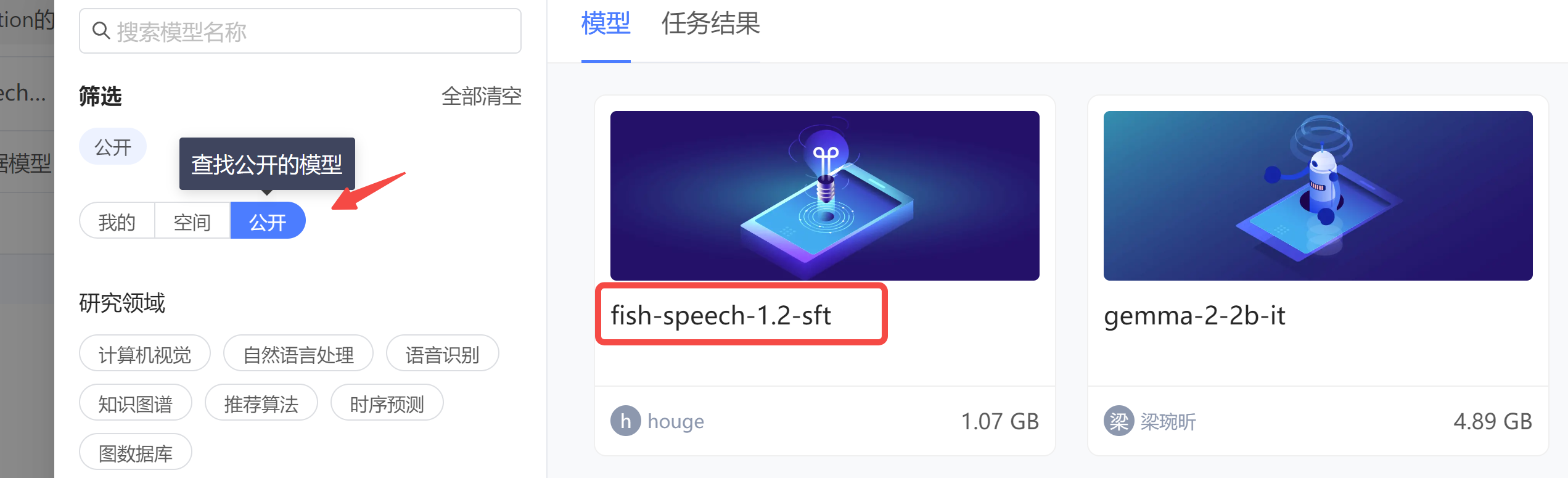
新建一个项目,把我已经建好的模型和镜像挂载进来。
模型:
镜像:

如果挂载了上面的模型和镜像,可直接跳转到 3.4 本地测试。
为了从0到1完成整个项目,3.2 和 3.3 分别带大家完成模型准备和环境准备。
3.2 模型准备(可选)
首先从 huggingface 国内镜像站下载模型到本地,记得删除其中的 .git 文件夹(占用上传空间)。
git clone https://hf-mirror.com/fishaudio/fish-speech-1.2-sft
回到趋动云控制台,点击模型,进行上传,选择 SFTP 传输方式。

上传代码:
put -r D:/data/projects/fish-speech-1.2-sft/ /upload
后面发现,这里目标路径最好带上模型名,也即/upload/fish-speech-1.2-sft,否则挂载进来时不带模型名。

实测上传速度在 10M/s 左右。
传输完成,关闭通道,刷新一下,右侧可以看到文件目录
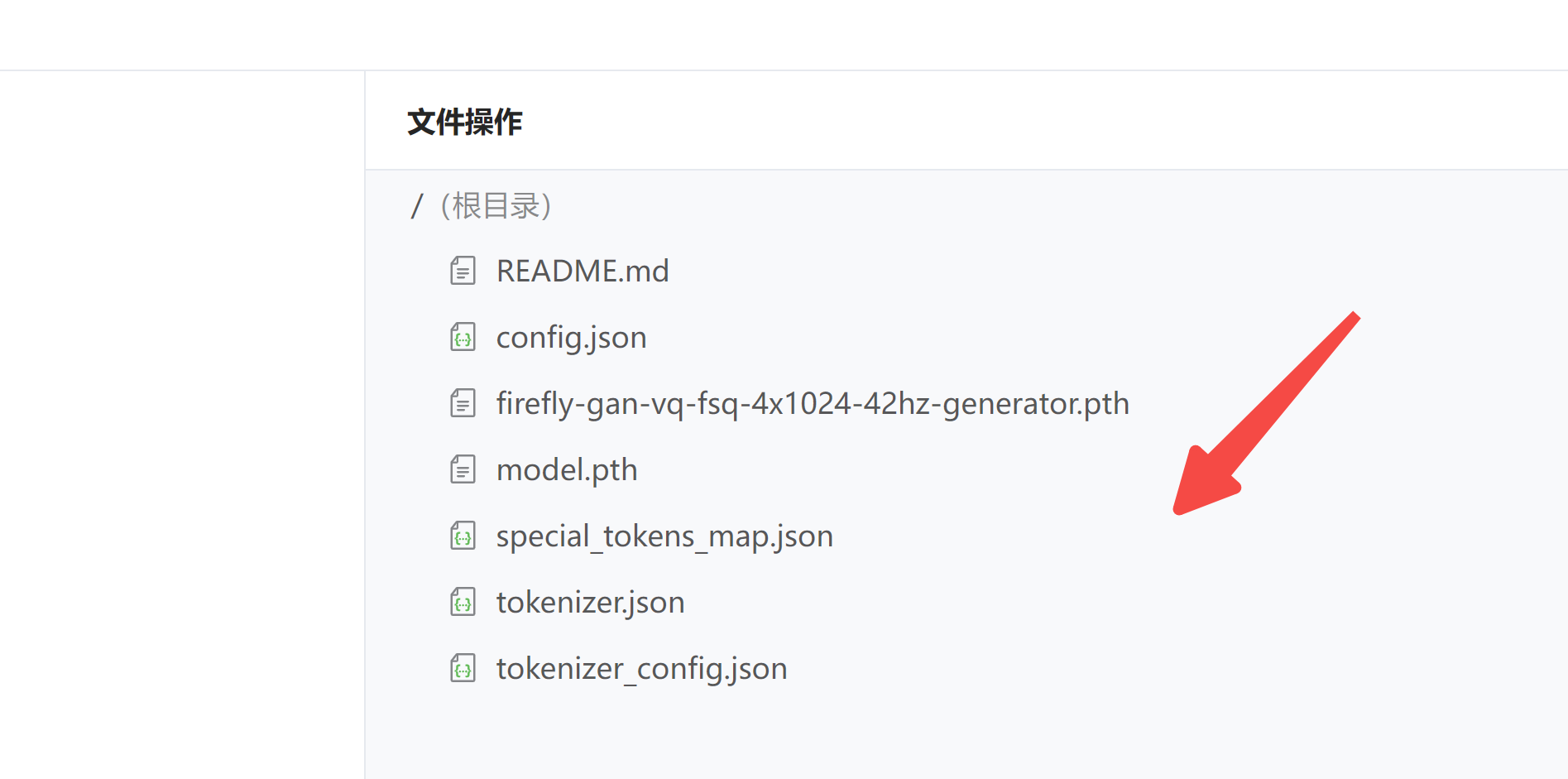
点击下方确定,生成一个模型版本。至此,我们的模型就准备好了。
PS:模型已公开,大家在项目中加载下面的模型即可:
3.3 环境准备(可选)
下载项目并安装依赖项:
git clone https://github.com/fishaudio/fish-speech.git
cd fish-speech
pip install -e .
apt update
apt install libsox-dev
会安装根目录 pyproject.toml 中指定的所有依赖项,不过安装过程实在太痛苦了(太慢了)!
有没有其他解决方案?
官方提供了 docker 镜像,不过趋动云分配的云实例本身就是个 docker 容器,当然无法在容器中安装 fish-speech 的 docker 镜像。
怎么知道的?输入下方指令试试吧~
systemd-detect-virt -c
因此,这里提供两个方案:
方案一:
找一个支持conda的镜像,在 /gemini/code 目录下创建一个 conda 虚拟环境,这个环境会持久保存。
conda create --prefix /gemini/code/envs/fish python=3.10
这样,每次重启项目后,激活这个环境即可,无需重新安装依赖了。
conda activate /gemini/code/envs/fish
方案二:用 dockerfile 在平台上构建一个镜像,项目依赖这个镜像即可:

Dockerfile 中编写内容如下:
# Install system dependencies
RUN apt-get update && apt-get install -y git curl build-essential ffmpeg libsm6 libxext6 libjpeg-dev \
zlib1g-dev aria2 zsh openssh-server sudo protobuf-compiler cmake libsox-dev && \
apt-get clean && rm -rf /var/lib/apt/lists/*
# 克隆代码库
RUN git clone https://mirror.ghproxy.com/https://github.com/fishaudio/fish-speech.git
# 设置工作目录
WORKDIR fish-speech
# 安装项目依赖
RUN pip install --no-cache-dir -e .
如果镜像加载进来后遇到如下报错:
libtorch_cuda.so: undefined symbol: ncclCommRegister
这是 PyTorch 和 NCCL 版本与 CUDA 版本不兼容的问题,建议重新使用 conda 重新安装对应 CUDA 版本的 Pytorch,比如我这里用的是 CUDA 12.1 的镜像:
# 参考:https://pytorch.org/
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia
PS:我已把所有环境依赖做好了镜像,大家在项目中加载下面的镜像即可。
3.4 本地测试
如果还没下载模型,请移步 3.1 完成模型准备。
我们这里直接使用挂载的模型文件:
mkdir checkpoints
ln -s /gemini/pretrain/ checkpoints/fish-speech-1.2-sft
模型准备好之后,推理分为几个部分:
- 给定一段 ~10 秒的语音, 将它用 VQGAN 编码;
- 将编码后的语义 token 和对应文本输入语言模型作为例子;
- 给定一段新文本, 让模型生成对应的语义 token;
- 将生成的语义 token 输入 VQGAN 解码, 生成对应的语音。
我们一步步来:
- 从语音生成 prompt,输入待克隆的音频文件,输出编码后的语义token,得到一个 fake.npy 文件:
python tools/vqgan/inference.py -i "gghy.wav" --checkpoint-path "checkpoints/fish-speech-1.2-sft/firefly-gan-vq-fsq-4x1024-42hz-generator.pth"
- 从文本生成语义 token:
--prompt-text需要和音频文件中的内容保持一致,--prompt-tokens是刚生成的 fake.npy 文件,输出生成的语义 token,得到codes_0.npy文件
python tools/llama/generate.py \
--text "要转换的文本" \
--prompt-text "你的参考文本" \
--prompt-tokens "fake.npy" \
--checkpoint-path "checkpoints/fish-speech-1.2-sft" \
--num-samples 1 \
--compile
- 从语义 token 生成人声: 对
codes_0.npy用 VQGAN 解码。
python tools/vqgan/inference.py -i "codes_0.npy" --checkpoint-path "checkpoints/fish-speech-1.2-sft/firefly-gan-vq-fsq-4x1024-42hz-generator.pth"
3.5 服务部署
3.5.1 服务端部署
项目中已经提供了部署代码,服务端一键启动代码如下:
python tools/api.py --listen 0.0.0.0:7860 --compile
3.5.2 客户端调用
客户端调用需要先安装 pyaudio:
sudo apt-get install portaudio19-dev
pip install pyaudio
然后调用tools/post_api.py,发起请求:
python tools/post_api.py --url 'http://127.0.0.1:7860/v1/invoke' --text "要输入的文本" --reference_audio gghy.wav --reference_text '随着
大军缓缓前进,他忍不住琢磨起了回京之后会被派到什么艰苦的地方。顶缸。要知道皇帝一向就是这么干的,几乎没让他过过什么安生日子。'
其中 --url 修改为服务端的 IP 地址。更多参数设置可参考 tools/post_api.py。
3.6 WebUI
项目中支持一键部署 webui:
python tools/webui.py
如果需要声音克隆,记得打开下方的 Enable Reference Audio 选项。

代码中,默认对于长文做了自动切分。Gradio 界面底部也可以看到 API 调用。
3.7 显存占用情况
给大家看下,显存占用情况:
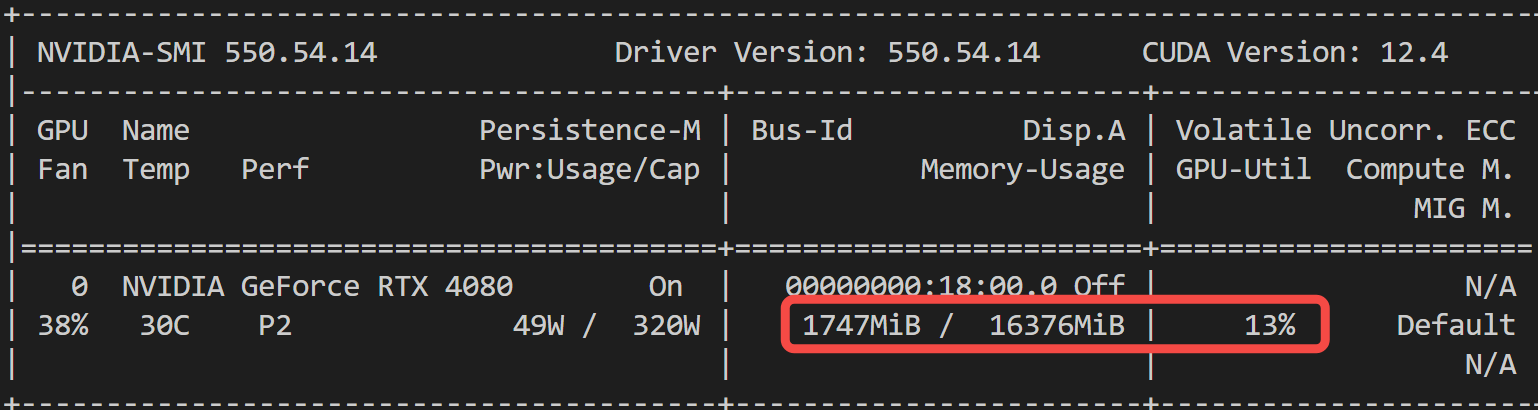
模型推理,只占用 < 2G 显存,相比 CosyVoice 的 6G 显存,优势显著~
写在最后
还记得之前克隆语音,又是训练模型又是高配电脑,小白表示压力山大啊。
现在,Fish Speech 来了,零门槛,傻瓜式操作,简直是视频创作者的新宠啊。
本文带着大家先在官网上体验了一把,海量音色任你挑!
接着从准备模型到环境配置,再到服务部署,完成了 Fish Speech 的私有化部署~
良心之作 Fish Speech 只需不到 2G 显存就能运行,赶紧去试试吧!
关于开源 AI 大模型的文章,我打算做成一个专栏,目前已收录:
- CogVideo 实测,智谱「清影」AI视频生成,全民免费,连 API 都开放了!
- 全网刷屏的 LLaMa3.1,2分钟带你尝个鲜
- SenseVoice 实测,阿里开源语音大模型,识别效果和效率优于 Whisper
- EasyAnimate-v3 实测,阿里开源视频生成模型,5 分钟带你部署体验,支持高分辨率超长视频
- 开源的语音合成项目-EdgeTTS,无需部署无需Key
- 一文梳理ChatTTS的进阶用法,手把手带你实现个性化配音
- FLUX.1 实测,堪比 Midjourney 的开源 AI 绘画模型,无需本地显卡,带你免费实战
- CosyVoice 实测,阿里开源语音合成模型,3s极速语音克隆,5分钟部署实战
定期更新,感兴趣的小伙伴欢迎关注。
如果本文对你有帮助,欢迎点赞收藏备用。






![[论文翻译] LTAChecker:利用注意力时态网络基于 Dalvik 操作码序列的轻量级安卓恶意软件检测](https://img-blog.csdnimg.cn/direct/7a38a0a2d85d4ec5a9d4a0e2c1b1c785.png)











