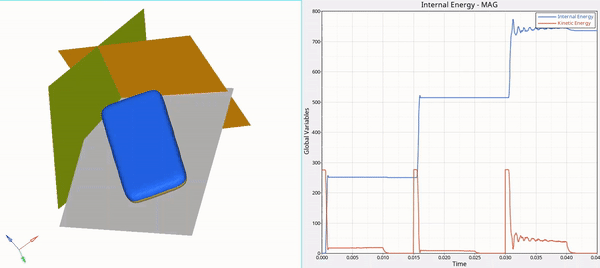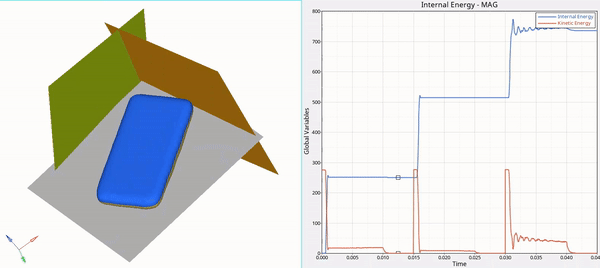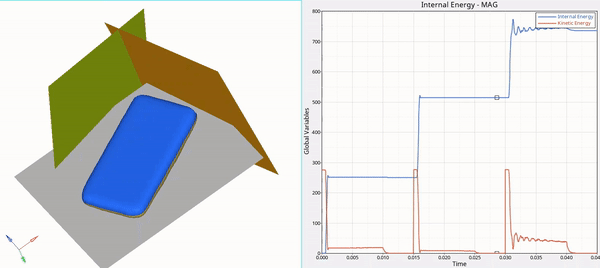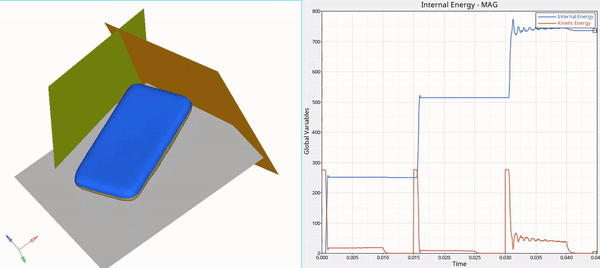
我是小米,一个喜欢分享技术的29岁程序员。如果你喜欢我的文章,欢迎关注我的微信公众号“软件求生”,获取更多技术干货!

Hello,大家好!我是小米,今天要和大家聊聊一个非常有意思的算法实战问题——在2GB内存中,如何在20亿个整数中找到出现次数最多的数。这个问题涉及到大数据处理和算法优化,特别适合喜欢钻研技术的你!让我们一起来探讨一下吧!
问题描述
我们有一个包含20亿个整数的大文件,目标是在有限的内存(2GB)内找到出现次数最多的整数。通常情况下,我们可以使用哈希表对每个出现的数进行词频统计,哈希表的key是某个整数,value记录整数出现的次数。
假设每个整数是32位(4B),每个出现次数的记录也是32位(4B),那么一条哈希表记录需要占用8B的内存。当哈希表记录数达到2亿个时,需要16亿个字节(1.6GB)内存。而我们要处理的是20亿个记录,至少需要16GB的内存,显然不符合题目要求。
解决方案
为了解决这个问题,我们可以利用哈希函数将20亿个数的大文件分成16个小文件。这样ÿ