1 下载Canal
Cannal下载地址如下:https://github.com/alibaba/canal/releases,这里选择Canal 1.1.4版本下载。
2 上传解压
#首先创建目录 “/software/canal”
[root@node3 ~]# mkdir -p /software/canal
#将Canal安装包解压到创建的canal目录中
[root@node3 ~]# tar -zxvf /software/canal.deployer-1.1.4.tar.gz -C /software/canal/
3 使用Canal同步Mysql数据
1. 使用Canal同步MySQL的数据可以直接使用Canal客户端API方式消费Canal同步的数据,详细api参照:https://github.com/alibaba/canal/wiki/ClientAPI
2. 也可以直接通过Canal将数据写入Kafka
4. Canal架构原理
Canal Server结构

1.server 代表一个 canal 运行实例,对应于一个 jvm。
2.instance 对应于一个数据队列 (1个 canal server 对应 1..n 个 instance )
3.instance 下的子模块:
(1) eventParser: 数据源接入,模拟 slave 协议和 master 进行交互,协议解析
(2) b.eventSink: Parser 和 Store 链接器,进行数据过滤,加工,分发的工作
(3) eventStore: 数据存储
(4) metaManager: 增量订阅 & 消费信息管理器
Canal同步MySQL数据原理
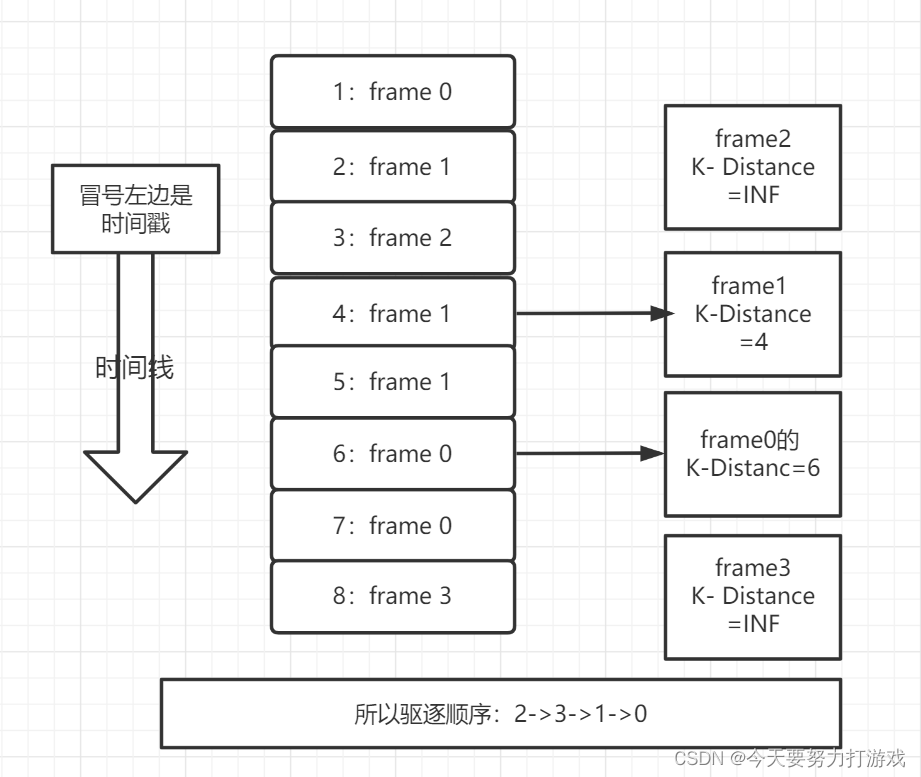
EventParser在向mysql发送dump命令之前会先从Log Position中获取上次解析成功的位置(如果是第一次启动,则获取初始指定位置或者当前数据段binlog位点)。mysql接受到dump命令后,由EventParser从mysql上pull binlog数据进行解析并传递给EventSink(传递给EventSink模块进行数据存储,是一个阻塞操作,直到存储成功),传送成功之后更新Log Position。流程图如下:

EventSink起到一个类似channel的功能,可以对数据进行过滤、分发/路由(1:n)、归并(n:1)和加工。EventSink是连接EventParser和EventStore的桥梁。
EventStore实现模式是内存模式,内存结构为环形队列,由三个指针(Put、Get和Ack)标识数据存储和读取的位置。
MetaManager是增量订阅&消费信息管理器,增量订阅和消费之间的协议包括get/ack/rollback,分别为:
(1)Message getWithoutAck(int batchSize),允许指定batchSize,一次可以获取多条,每次返回的对象为Message,包含的内容为:batch id[唯一标识]和entries[具体的数据对象]。
(2)void rollback(long batchId),顾名思义,回滚上次的get请求,重新获取数据。基于get获取的batchId进行提交,避免误操作。
(3)void ack(long batchId),顾名思义,确认已经消费成功,通知server删除数据。基于get获取的batchId进行提交,避免误操作。
5 关于同步MySQL数据配置信息

首先Canal可以是一个集群,这里以Canal单机为例解释Canal同步MySQL数据配置文件配置原理。
首先需要在Canal中配置CanalServer 对应的canal.properties,这个文件中主要配置Canal对应的同步数据实例(Canal Instance)位置信息及数据导出的模式,例如:我们需要将某个mysql中的数据同步到Kafka中,那么就可以创建一个“数据同步实例”,导出到Kafka就是一种模式。
其次,需要配置Canal Instance 实例中的instance.properties文件,指定同步到MySQL数据源及管道信息。
5.1 配置步骤
配置“canal.properties”
进入“/software/canal/conf”目录下,编辑“canal.properties”文件:
#canal将数据写入Kafka,可配:tcp, kafka, RocketMQ,tcp就是使用canal代码接收
canal.serverMode = kafka
#配置canal写入Kafka地址
canal.mq.servers = node1:9092,node2:9092,node3:9092
配置mysql slave的权限
Canal的原理是模拟自己为mysql slave,所以这里一定需要做为mysql slave的相关权限 ,授权Canal连接MySQL具有作为MySQL slave的权限:
mysql> CREATE USER canal IDENTIFIED BY 'canal';
mysql> GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
mysql> FLUSH PRIVILEGES;
mysql> show grants for 'canal' ;
配置“instance.properties”
进入“/software/canal/conf/example/”下,编辑“instance.properties”文件:
#canal伪装为一个mysql的salve,配置其id,不要和真正mysql server-id冲突,这里也可以不配置,会自动生成
canal.instance.mysql.slaveId=123456
#配置mysql master 节点及端口
canal.instance.master.address=node2:3306
#配置连接mysql的用户名和密码,就是前面复制权限的用户名和密码
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
#配置Canal将数据导入到Kafka topic
canal.mq.topic=canal_topic
启动Canal
进入“/software/canal/bin”,执行“startup.sh”脚本启动Canal。
#启动Canal
[root@node3 ~]# cd /software/canal/bin/
[root@node3 bin]# ./startup.sh
[root@node3 bin]# jps
68675 CanalLauncher #启动成功
启动zookeeper和Kafka,并监控Kafka中“canal_topic”的数据
注意:“canal_topic”不需要提前创建,默认创建就是1个分区。
[root@node2 bin]# ./kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic canal_topic
在MySQL中建表,插入语句
mysql> create database testdb;
mysql> use testdb;
mysql> create table person(id int ,name varchar(255),age int);
mysql> insert into person values (1,"zs",18),(2,"ls",19),(3,"ww",20);
对应的在Kafka中有对应的数据日志写入



关于以上json字段解析如下:
data:最新的数据,为JSON数组,如果是插入则表示最新插入的数据,如果是更新,则表示更新后的最新数据,如果是删除,则表示被删除的数据。
database:数据库名称。
es:事件时间,13位的时间戳。
id:事件操作的序列号,1,2,3…
isDdl:是否是DDL操作。
mysqlType:字段类型。
old:旧数据。
pkNames:主键名称。
sql:SQL语句。
sqlType:是经过canal转换处理的,比如unsigned int会被转化为Long,unsigned long会被转换为BigDecimal。
table:表名。
ts:日志时间。
type:操作类型,比如DELETE,UPDATE,INSERT。