前言
在深度学习领域,特别是在处理序列到序列的预测任务时,如语音识别和手写识别,nn.CTCLoss函数是一个非常重要的工具。本文将详细解析PyTorch中的nn.CTCLoss函数,包括其原理、原型和示例。
- 前言
- 函数原理
- CTC算法简介
- CTC Loss函数
- 函数原型
- 调用方式
- 注意事项
- 示例
- 小结
函数原理
CTC算法简介
CTC(Connectionist Temporal Classification)是一种针对序列数据的端到端训练方法,尤其适用于RNN(循环神经网络)模型。传统的RNN序列学习任务需要事先标注好输入序列和输出序列之间的映射关系,但在实际应用中,这种标注往往非常昂贵且难以获得。CTC算法通过引入多对一的映射关系,使得RNN模型能够直接对序列数据进行学习,而无需预先标注输入和输出的映射关系。
CTC Loss函数
CTC Loss函数的目标是最大化所有能够映射到正确标签序列的输出序列的概率之和。具体来说,CTC Loss通过以下步骤计算:
- 扩展字符集:在原始的字符集中增加一个空白标签(blank),用于分隔不同的字符。
- 多对一映射:定义从RNN输出层到最终标签序列的多对一映射函数,去除连续的相同字符和空白标签。
- 计算路径概率:对于每一个可能的输出序列(即路径),计算其映射到正确标签序列的概率。
- 累加概率:将所有能够映射到正确标签序列的路径概率相加。
- 取负对数:将上一步得到的概率和取负对数,作为损失值。
CTC Loss通过动态规划算法有效地计算所有路径的概率,从而避免了暴力计算的复杂性。
函数原型
PyTorch中的nn.CTCLoss函数原型如下:
torch.nn.CTCLoss(blank=0, reduction='mean', zero_infinity=False)
参数说明:
blank(int,可选):空白标签的索引,默认为0。
reduction(str,可选):指定损失的计算方式,可选值为'none'、'mean'和'sum',默认为'mean'。
zero_infinity(bool,可选):当设置为True时,任何无限或NaN的损失值将被视为0,默认为False。
调用方式
loss = ctc_loss(log_probs, targets, input_lengths, target_lengths)
参数说明:
log_probs(Tensor):模型输出的张量,形状为(T, N, C),其中T是序列长度,N是batch size,C是包括空白标签在内的字符集总长度。这个张量通常需要经过torch.nn.functional.log_softmax处理。
targets(Tensor或LongTensor):标签张量,形状为(N, S)或(sum(target_lengths)),其中N是batch size,S是标签长度。注意,标签中不能包含空白标签。
input_lengths(Tensor):形状为(N)的张量,包含每个输入序列的长度。
target_lengths(Tensor):形状为(N)的张量,包含每个目标序列的长度。
注意事项
输入形状:nn.CTCLoss期望的输入logits(或log_probs,如果logits=False)形状通常为(T, N, C),其中T是序列长度,N是batch大小,C是类别数(包括空白标签)。
目标格式:目标targets需要是长度为N的列表,其中每个元素是长度为Si的整数列表或张量(Si是第i个样本的目标序列长度),或者是一个形状为(N, S_max)的二维张量,其中S_max是所有目标序列中的最大长度,并使用特定的值(如CTC Loss期望的最小类别索引以下的值)来填充较短的序列。
序列长度:需要提供input_lengths和target_lengths,分别表示每个输入序列和目标序列的长度。
空白标签索引:在初始化nn.CTCLoss时,需要指定空白标签的索引。
示例
import torch
import torch.nn as nn
# 假设有模型输出和标签
# 假设log_probs已经通过log_softmax处理,但注意这里我们简化了形状以匹配示例
# 在实际应用中,T, N, C应该是根据你的数据来确定的
T = 50 # 序列长度
N = 20 # batch size
C = 28 # 类别数(假设有26个字母加上空格和空白标签,这里空白标签设为27)
log_probs = torch.randn(T, N, C).log_softmax(2) # [T, N, C]
# 假设标签长度不一,这里我们构造一个简化的例子
# 注意:targets应该是列表的列表或二维张量,但为了简化,我们使用二维张量并填充-100(PyTorch的CTCLoss会忽略小于等于最小类别的索引)
# 在实际应用中,你应该使用真实的标签索引,并且不需要填充(除非你使用二维张量并希望统一形状)
max_target_length = 10
targets = torch.randint(1, C-1, (N, max_target_length), dtype=torch.long) # 假设所有目标序列都不包含空白标签
# 假设有些序列较短,我们用-100填充(注意:这里使用-100只是示例,实际中应确保它小于最小的类别索引)
targets[targets == C-1] = -100 # 假设C-1不是有效的类别索引,我们用它来模拟较短的序列
# input_lengths和target_lengths
input_lengths = torch.full((N,), T, dtype=torch.long) # 每个输入序列的长度都是T
# target_lengths需要真实反映每个目标序列的长度
# 这里我们假设所有目标序列都是完整的max_target_length长度(在实际应用中,你需要计算每个序列的真实长度)
target_lengths = torch.full((N,), max_target_length, dtype=torch.long)
# 但是,由于我们使用了-100来填充较短的序列,实际上我们需要计算每个序列的真实长度
# 这里我们手动设置几个较短的序列长度作为示例
target_lengths[0:5] = torch.tensor([5, 7, 3, 8, 9], dtype=torch.long)
# 注意:如果targets是二维张量并且包含填充值,你需要确保CTCLoss能够忽略这些填充值
# PyTorch的CTCLoss通过忽略小于等于最小类别索引的值来实现这一点
# 在这个例子中,我们假设C-1(即27)不是有效的类别索引,并且所有有效的类别索引都大于它
# 初始化CTC Loss,注意设置正确的空白标签索引
ctc_loss = nn.CTCLoss(blank=C-1) # 假设空白标签的索引是C-1(即27)
# 但是,由于PyTorch的CTCLoss不直接支持二维张量作为targets(如果包含填充),
# 我们需要将targets转换为CTCLoss期望的格式:列表的列表或TensorList
# 这里我们为了简化,假设所有目标序列都没有填充,并直接传递二维张量(在实际中,你可能需要转换)
# 如果targets包含填充,并且你使用的是二维张量,你需要先处理它,或者改用列表的列表
# 这里我们假设没有填充,直接传递
loss = ctc_loss(log_probs, targets, input_lengths, target_lengths)
print(loss.item())

小结
nn.CTCLoss是处理序列到序列预测任务时的强大工具,它简化了序列数据的标注过程,并允许RNN模型直接对序列数据进行端到端的学习。通过合理利用CTC Loss,我们可以有效地训练出性能优异的序列预测模型。




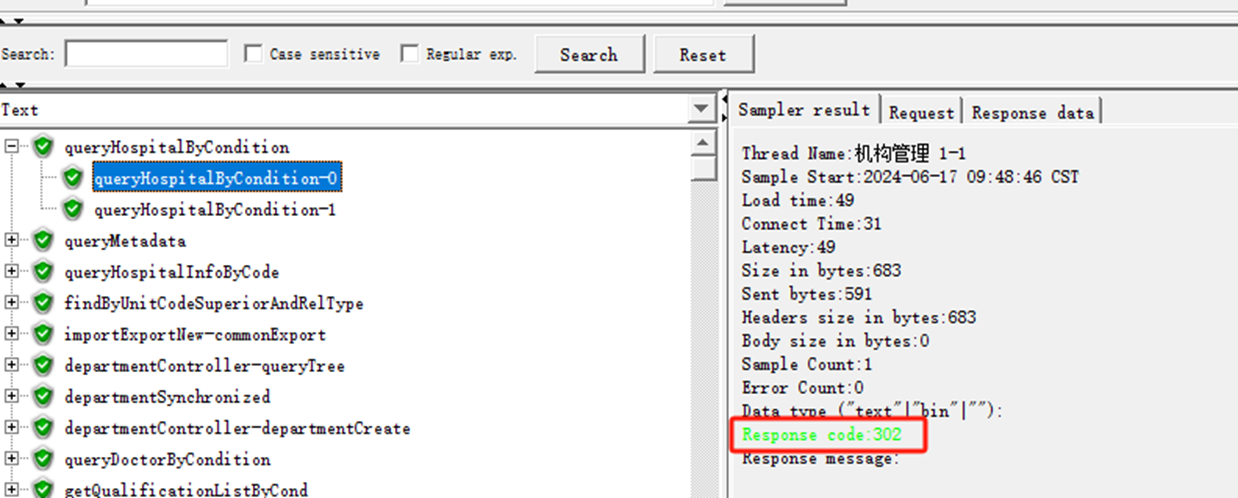
![Please refer to dump files (if any exist) [date].dump, [date]-jvmRun[N]……解决](https://i-blog.csdnimg.cn/direct/31889885e8a04291896d146eee5a2b77.png)