引言
在人工智能的飞速发展中,大型语言模型(LLM)已成为研究和应用的热点。LLM以其强大的语言理解和生成能力,在诸如自然语言处理、文本生成、问答系统等多个领域展现出巨大潜力。然而,要充分发挥LLM的能力,有效的Prompt设计变得至关重要。Prompt,或称为提示词,是用户输入给模型的指令或问题,用以引导模型生成特定的输出。Prompt工程,即Prompt的设计与优化,已成为人机交互中的一门艺术和科学。
什么是Prompt
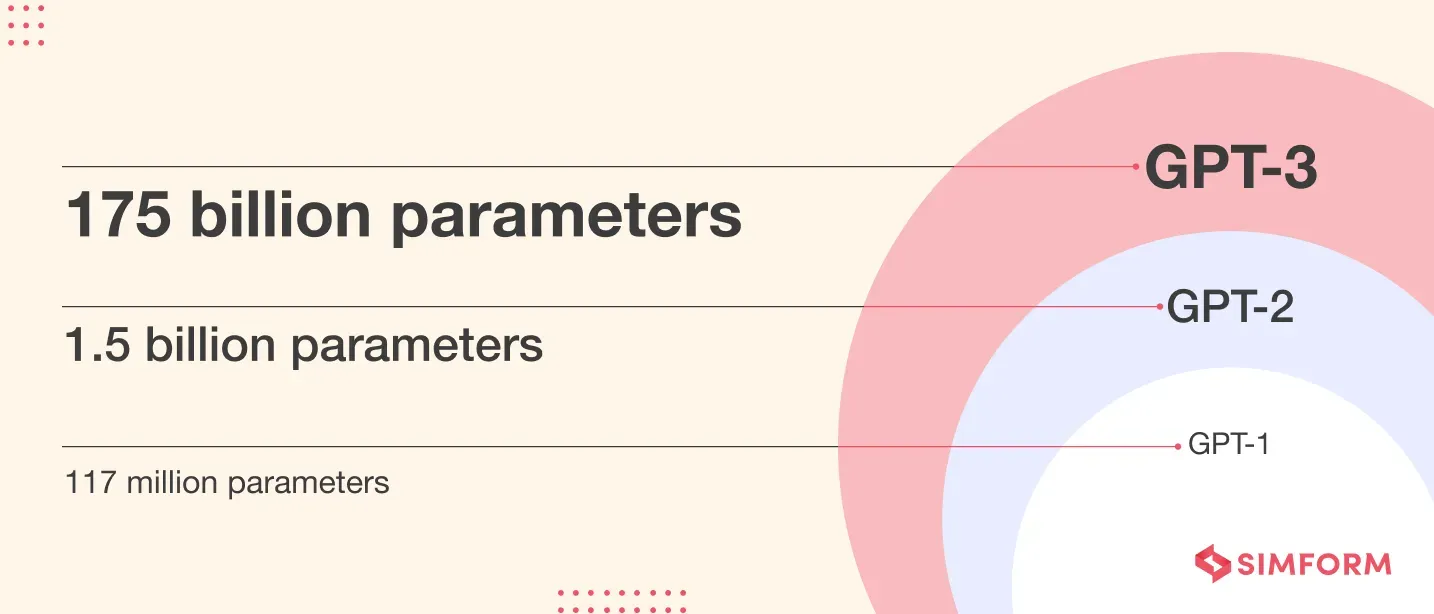
回顾GPT的发展历程可分为四个阶段:GPT-1、GPT-2、GPT-3和ChatGPT。GPT-1作为早期基于Transformer架构的模型,采用"pretrain + finetune"范式,但受限于模型规模,未被广泛应用。GPT-2引入了新范式,通过大规模预训练,无需监督数据即可完成多种任务,开启了zero-shot学习的先河。GPT-3进一步扩大了模型和数据规模,实现了在zero-shot任务中的显著效果,尤其在无需编程技能的场景下。ChatGPT作为GPT-3的优化版,专注于多轮对话,成为AI市场化的重要里程碑。随着GPT系列的发展,Prompt技术应运而生,成为提升模型性能和适应性的关键。
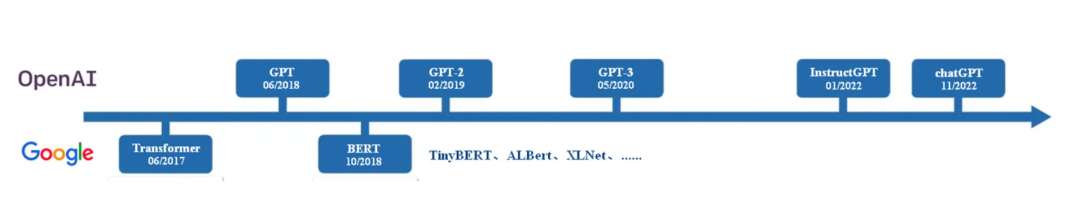
从领域发展的角度我们可以看到 3 种不同的研发范式:
- Transformer 之前:有监督训练(train)
- GPT-1 & BERT:无监督预训练(pre-train) + 有监督微调(finetune)
- GPT-2 & GPT3:无监督预训练(pre-train) + 提示词(Prompt)
模型能力的研发越来越不依赖 “训练” 的过程,而是更大程度的依赖 “预训练”,依赖 “模型” 本身的能力。在 BERT 所代表的范式下,我们还可以通过 “微调” 在参数层面影响模型。而到了以 “GPT3” 为代表的范式下,也就是我们现在用的大模型,我们不再借助 “微调” 的方式调试模型,而是通过 “输入” 直接影响 “输出” 的质量,而如何在应用中得到一个好的 “输入” 就是 “Prompt 工程” 需要做的事。
Prompt工程的重要性
Prompt工程的重要性体现在其对LLM性能的影响上。一个精心设计的Prompt可以显著提高模型的准确性、相关性和创造性。在实际应用中,Prompt工程可以帮助我们更好地利用LLM解决复杂问题,提高工作效率,甚至在某些情况下,发掘出模型潜在的能力。
Prompt设计基础
理解LLM的工作原理
在设计Prompt之前,理解LLM的工作原理至关重要。LLM通常基于变换器(Transformer)架构,通过预训练和微调来学习语言模式。模型能力的应用越来越向 “预训练” 的部分倾斜,绝大多数能力在 “预训练” 阶段形成的,而非通过进一步的训练构建。而在这种思想的基础上,Prompt 则像一个个约束条件,通过增加限制,让这些 “预训练” 阶段构成的能力更精准的调用起来。因此,Prompt 就是在提示模型回忆起自己在预训练时学习到的能力。
我们可以把 “知识” 和 “能力” 进行更进一步的分解,更多的是希望使用大模型的能力(理解,总结,生成,推理,e.t.c.),而非知识。 如同RAG 技术一样,我们更倾向于将知识通过外部注入的方式让模型试用,而能力则完全需要依赖预训练阶段。我们要做的是通过 Prompt 调用大模型的能力去解决问题,让这些能力表现的更精准,而并非把他当成一个知识库。
Prompt的结构要素
一个良好的Prompt通常包含以下几个结构要素:
明确的目标
每个Prompt都应有一个清晰的目标,告诉模型需要完成什么任务。目标的明确性直接影响到模型输出的相关性和准确性,而不是模糊地说“告诉我关于苹果的信息”,更好的方式是“列出苹果的营养价值”。
充足的上下文
上下文为模型提供了完成任务所需的背景信息。充足的上下文可以帮助模型更好地理解Prompt的意图和需求。如在询问“这个角色在故事中的作用是什么”时,提供故事的摘要或关键情节可以引导模型给出更准确的回答。
指定的风格和语气
根据任务的性质和目标受众,指定Prompt的风格和语气。这可以影响模型生成文本的正式程度、亲和力和说服力。如在撰写一个产品广告时,选择“热情和激励人心”的风格可能会比“事实陈述”的风格更能吸引用户。
预期的受众
了解目标受众可以帮助定制化Prompt,确保生成的内容能够引起受众的共鸣。如为儿童设计教育内容时,使用简单、直观的语言比使用复杂或技术性的语言更有效。
回复格式
指定模型输出的格式,如文本段落、列表、表格或JSON。这有助于将模型的输出直接应用于特定的使用场景。
Prompt设计的挑战与机遇
尽管开源小型模型和训练技术如LoRa的兴起使得在较低成本下对模型进行微调成为可能,但这并不意味着Prompt工程变得不再重要。由于大模型的体量巨大,即使是开源模型,通过LoRa等技术进行的微调对参数的影响也是有限的,更多是一种参数对齐过程,可能引发遗忘问题,且无法保证长期的知识更新。相比之下,利用超长上下文模型和RAG(Retrieval-Augmented Generation)等技术被认为是更可靠的方法。此外,大模型的智能涌现基于scaling law,其能力的提升依赖于参数量的增加,而非单一任务的训练。因此,Prompt工程作为新范式下调度和对齐模型能力的关键手段,其作用无法被传统训练和微调所取代。
Prompt设计基础是Prompt工程的起点。理解LLM的工作原理,掌握有效Prompt的结构要素,可以帮助我们更好地与模型沟通,实现更加丰富和深入的人机交互。
Prompt万能框架
静态prompt模板
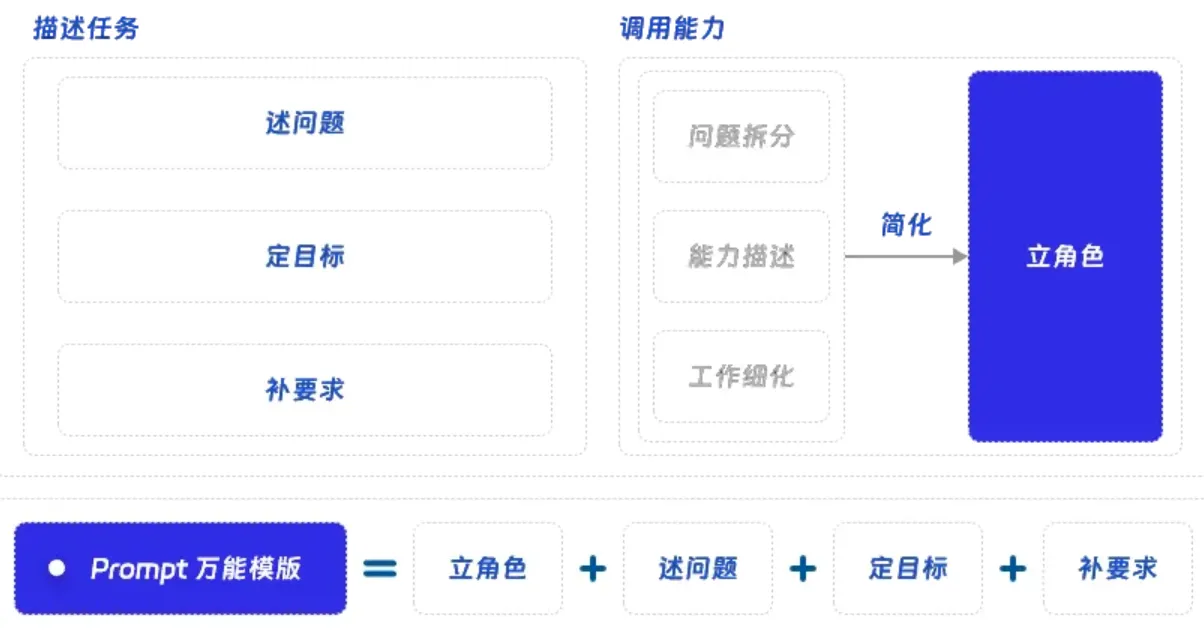
在编写 Prompt 时,从0到1的编写出第一版 Prompt 往往是最难的,而基于已有 Prompt 利用各种技巧进行优化则相对简单。为了解决这个问题,通过使用一套 “万能模版”,把一个 Prompt 拆分成了 “立角色 + 述问题 + 定目标 + 补要求” 这四个部分,希望通过结构化的拆分完成这最困难的一步,无论面对什么任务,利用这个模版都可以得到一个“及格”的 Prompt。
Prompt 的作用就是根据我们的问题调用模型的能力,用户通过提问的方式,明确的让模型知道我们想要什么,我们的目标是什么,从这个基本思想出发,Prompt 应该包含以下几点:
- 问题是什么:首先你要告诉模型你的问题是什么,你的任务是什么,要尽量描述清楚你的需求。
- 你要做什么:下面你需要告诉大模型具体要做什么,比如做一份攻略,写一段代码,对文章进行优化,等等。
- 有什么要求:最后我们往往还需求对任务补充一些要求,比如按特定格式输出,规定长度限制,只输出某些内容,等等。
描述清楚以上内容,即可让LLM理解相关任务表述,举例来说:
例1:生成产品摘要
问题是什么:你的任务是帮我生成一个产品的简短摘要。
你要做什么:我会给你产品的需求文档,及用户对产品的评价,请结合这些信息概括产品的功能及现状,为我生成一份产品摘要。有什么要求:请尽量概括产品的特点,并用轻松幽默的语言风格进行编写,摘要的字数不要超过50个字。
例2:生成代码注释
问题是什么:你的任务是帮我的代码生成注释。你要做什么:我有一段 python 代码,需要你对代码的内容进行分析,并为代码添加注释。
有什么要求:请结合代码内容,尽量详细的补充注释,不要遗漏,每条注释请以 “comment:” 作为前缀。例3:生成测试用例
问题是什么:你的任务是帮我设计一款产品的测试用例。你要做什么:我会提供给你产品的需求文档,需要你结合需求的功能描述进行测试用例的编写。
有什么要求:请结合需求中功能的结构,对测试点进行梳理,并有层级的输出测试用例,请保证每一个功能的测试点没有遗漏。
细化相关内容
初版的 Prompt 还只是一个雏形,由于各部分信息还不完整,往往不能达到我们的预期,框架提供了 Prompt 的骨架,还需要我们进一步补充相关内容,对框架的每一部分进行更详细的分解,通过内容的补全一步步的提升模型的效果。
角色
在描述清楚任务后,我们就需要调度模型的能力去完成我们的任务,不同的任务需要用到不同的能力,这往往依赖认为的拆分。角色”,他就像大模型里自带一个“能力包”,可以很容易的对模型能力进行调用。每一个角色,都对应着该角色包含的若干能力,我们可以通过设定角色,“提示”大模型使用该角色对应的能力,这与前文“Prompt 到底是什么” 中介绍的想法极其匹配,充分说明是“Prompt” 提示的作用,通过简单的“提示”调用出大模型预先训练的能力,这也就是“角色”如此有用的原因。
角色模版:
现在你是一位优秀的{{你想要的身份}},拥有{{你想要的教育水平}},并且具备{{你想要的工作年份及工作经历}},你的工作内容是{{与问题相关的工作内容}},同时你具备以下能力{{你需要的能力}}
举例来说
例:心理咨询师
现在你是一位优秀的 {{心理咨询师}},拥有 {{心理咨询、临床心理学等专业的硕士或博士学位}},并且具备 {{多年的心理咨询工作经验,在不同类型的心理咨询机构、诊所或医院积累了丰富的临床实践经验}},你的工作内容是 {{为咨询者处理各种心理问题,并帮助你的咨询者找到合适的解决方案}},同时你具备以下能力:
{{
- 专业知识:你应该拥有心理学领域的扎实知识,包括理论体系、治疗方法、心理测量等,可以为你的咨询者提供专业、有针对性的建议。
- 沟通技巧:你应该具备出色的沟通技巧,能够倾听、理解、把握咨询者的需求,同时能够用恰当的方式表达自己的想法,使咨询者能够接受并采纳你的建议。
- 同理心:你应该具备强烈的同理心,能够站在咨询者的角度去理解他们的痛苦和困惑,从而给予他们真诚的关怀和支持。
- 持续学习:你应该有持续学习的意愿,跟进心理学领域的最新研究和发展,不断更新自己的知识和技能,以便更好地服务于你的咨询者。
- 良好的职业道德:你应该具备良好的职业道德,尊重咨询者的隐私,遵循专业规范,确保咨询过程的安全和有效性。
}}
述问题 & 定目标
对问题的描述由 “述问题” 和 “定目标” 两部分组成,是 Prompt 中信息含量最大的部分,也是和任务最相关的部分,我们要明确的描述我们希望大模型做的工作,才能让大模型输出最符合预期的结果。除了要描述的清晰明确外,此部分值得强调的就是对任务的分解,这在复杂任务上尤为重要。
我们也可以把这种拆分当作一个任务维度的对齐,当我们用概括的语言描述一项任务时,隐含了大量的背景知识和预期。例如,当我们希望大模型帮我们 “制作一份旅游攻略” 时,我们希望他能帮我们 “规划行程”,“收集信息”,“预定酒店” 等等,而这些信息往往都被包含在 “旅游攻略” 当中。如果我们不明确的对任务进行拆分,大模型就不知道我们的任务具体需要包含哪些部分,因此这个任务维度的对齐十分重要。
例1:请帮我制作一份深圳的旅游攻略
请帮我制作一份深圳的旅游攻略,以下是一些基本步骤和思考方式:
- 研究和收集信息:查找关于深圳的旅游信息,包括主要的旅游景点,当地的文化和历史,美食,交通,住宿等。
- 规划行程:根据你收集的信息,规划你的行程。考虑你想要去的地方,你有多少时间,你的预算等。确保你的行程是实际和可行的。
- 预订交通和住宿:一旦你确定了你的行程,你可以开始预订你的交通和住宿。比较不同的选项,找到最适合你的。
- 准备必要的物品:根据你的行程和新疆的天气,准备你需要的物品,比如衣服,鞋子,相机,地图等。
例2:请根据需求帮我设计测试用例
请根据需求帮助我设计测试用例,测试用例的设计是一个系统化的过程,以下是一些基本步骤和思考方式:
- 理解需求:首先,你需要深入理解软件的需求和功能。这包括阅读需求文档,理解用户故事,或者与项目经理和开发人员进行讨论。
- 确定测试范围:确定你需要测试哪些功能和特性。这可能包括正常操作,边缘情况,错误处理等。
- 设计测试策略:确定你将如何测试这些功能。这可能包括单元测试,集成测试,系统测试,性能测试等。
- 编写测试用例:对于每个测试,编写一个详细的测试用例。这应该包括预期的输入,预期的输出,以及如何执行测试。
- 评审测试用例:对测试用例进行评审,以确保它们完整,准确,并且易于理解。
复杂任务的拆解往往十分有效,不仅可以提升大模型的推理能力,也可以让大模型的输出更加贴合你的要求(对齐)。如果不了解相关内容,可以让LLM直接给出相关步骤建议,在此基础上进一步调整。
任务拆分 Prompt:
{{你要做的任务}},需要哪些步骤,该如何思考?例:希望大模型帮我写一份基金财务分析报告
输入:
制作一份基金财务分析报告,需要哪些步骤,该如何思考?
输出:
制作一份基金财务分析报告是一个涉及多个步骤的过程,需要对基金的财务状况、投资策略、市场环境等进行深入的研究和理解。以下是一些主要步骤和思考方式:
- 收集数据:首先,你需要收集基金的财务数据,包括但不限于基金的净值、收益率、投资组合、费用比率等。这些数据通常可以从基金公司的年度报告或季度报告中获取。
- 数据分析:对收集到的数据进行分析,包括对基金的收益率、风险、投资组合分布等进行计算和比较。你可以使用一些财务分析工具,如 Excel,或者专门的财务分析软件来进行这些计算。
- 基金比较:将基金的表现与其同类基金或者基准指数进行比较,看看基金的表现是否超过市场平均水平。这可以帮助你理解基金的相对表现。
- 市场环境分析:考虑基金的投资环境,包括经济状况、行业趋势、政策变化等。这些因素可能会影响基金的表现。
- 基金经理分析:研究基金经理的投资策略和历史表现,看看他们是否有能力在不同的市场环境下取得良好的回报。
- 撰写报告:将你的分析结果整理成一份报告,包括你的主要发现、基金的优点和缺点、以及你对基金未来表现的预测。
补要求
以上我们通过 “述问题&定目标” 描述清楚了任务,下面还需要对我们的任务提出一些要求,告诉大模型希望他做什么以及不做什么,这与模型响应的准确率息息相关。常用的要求如下:
- 字数限制。
- 输出结构(结构化输出,Json 输出)。
- 在输出中排除 xxx。
- 在输出中仅包含 xxx。
让大模型遵循我们的要求,尤其是在“格式”层面让大模型的输出符合我们的规定,对大模型的广泛应用十分重要。
首先,我们可以把要求放在 Prompt 的最后。大语言模型的本质是在做文本补全,后文的输出会更倾向于依据距离更近的语境,距离更近的文本间权重往往更大。而且,这与大模型在预训练阶段中完成的任务也更加匹配。因此,把要求放在 Prompt 的最后可以很有效的帮助大模型变得更“听话”。
其次,我们还可以利用大模型的“编程”能力。在“立角色”的部分中,我们可以通过设定角色调用大模型的能力。通过“大模型”的“编程”能力将“模糊的文理问题”变成“准确的数理问题”,以此让大模型更加遵守我们的要求。具体而言,就是把我们的要求转换为一个 “编码” 任务,例如:
请列出 10 个国家,并以列表形式返回
请列出 10 个国家,并以列表形式返回。我需要将这个列表引入到 python 代码中,请严格遵守 python 列表的格式进行输出。
例2:请输出 10 个国家,并包含这 10 个国家的“名称”,“人口”,“位置”。
请列出 10 个国家,并包含这 10 个国家的“名称”,“人口”,“位置”。我需要将这份数据引入到 python 代码中,因此请以 Json 格式进行输出,Json 格式如下:
'''
{"name": 名称, "population": 人口, "position": 位置, }
'''
例3:请为我输出一份产品摘要,字数不要超过 50 个字。
请为我输出一份产品摘要。我需要将这个摘要引入到 python 代码中,该变量的大小为 50,因此摘要内容不要超过 50 个字符通过这样引入大模型“编程”能力的方式,我们可以对模型提出更加精准的要求,并通过将我们的任务转换为更加准确的编程问题的方式,让大模型更 “听话”。
补格式
除了输入的内容外,输入的格式也很重要,清晰的结构对大模型的效果有很大的影响。除了增加合适的 “空行” 让结构变的清晰外,还可以增加一些“标识符”来区分各个部分,例如:#, <>, ```, [], -。同时大模型也具备 MarkDown 解析的能力,我们也可以借助 MarkDown 语法进行 Prompt 结构的整理。
由于“格式”对模型效果的影响,越来越多研究聚焦在了这个方向上。LangGPT 提出了一种结构化的 Prompt 模式,可以通过一套结构化的模版构造出格式清晰的 Prompt。
例:LangGPT 示例
# Role: 设置角色名称,一级标题,作用范围为全局
## Profile: 设置角色简介,二级标题,作用范围为段落
- Author: yzfly 设置 Prompt 作者名,保护 Prompt 原作权益
- Version: 1.0 设置 Prompt 版本号,记录迭代版本
- Language: 中文 设置语言,中文还是 English
- Description: 一两句话简要描述角色设定,背景,技能等
### Skill: 设置技能,下面分点仔细描述
1. xxx
2. xxx
## Rules 设置规则,下面分点描述细节
1. xxx
2. xxx
##Workflow 设置工作流程,如何和用户交流,交互
1. 让用户以 "形式:[], 主题:[]" 的方式指定诗歌形式,主题。
2. 针对用户给定的主题,创作诗歌,包括题目和诗句。
##Initialization 设置初始化步骤,强调 prompt 各内容之间的作用和联系,定义初始化行为。
作为角色 <Role>, 严格遵守 <Rules>, 使用默认 <Language> 与用户对话。然后介绍自己,并告诉用户 <Workflow>。
从 “LangGPT” 的示例中可以看到,用各种分隔符对 Prompt 内容进行了整理,可以很清晰的看到每部分的作用与区分,可以借鉴 “LangGPT” 对分隔符的使用,通过对格式的整理让 Prompt 展现出更好的效果。
总结(框架)
我们把 “框架细化” 分成了 4 步,并在每一步中都提出了通用的实践方法:
- 角色:通过角色模版和招聘 JD 补全角色。
- 问题&目标:在大模型的辅助下拆分任务。
- 要求:借助编码能力,让大模型更好的遵守要求。
- 格式整理:结合 LangGPT 的思想合理应用分隔符,让 Prompt 结构清晰。
至此,我们已经完成了 Prompt 主体部分的编写,面对任何一个任务都可以通过这套统一的方法完成一个还不错的 Prompt,并且通过我们对 Prompt 结构化的拆分,我们现在也可以更好的管理我们的 Prompt,并为上层应用提供更好的支撑。
增加更多信息

目前已经通过 “Prompt 框架” 和 “框架的细化” 完成了 Prompt 主体部分的编写,如果我们要在这基础上进一步优化我们的 Prompt,就需要增加更多信息输入。
大模型的推理,根本上还是基于用户输入的信息进行推理,提供的信息越充分,LLM就能越好的完成推理。“框架”仅仅包含了 Prompt 中“静态”的信息,我们还需要增加因任务而异的“动态”信息,这两部分信息的补充就是进一步优化 Prompt 方向。
“增加更多信息,让效果变得更好”,但关键是要增加什么信息?如何增加这些信息呢?为了能在合适的场景下增加合适的信息,势必要包含 “检索” 的工作,以下是几种常见方法:
RAG
RAG技术因其能够赋予模型动态获取知识的能力而受到广泛关注,并在多种实际应用场景中展现出其重要性。这种技术与人类智能相似,允许模型通过检索而非仅依赖内置参数来获取知识,从而增强了模型在专业领域和通用领域中的知识扩展性和时效性。
RAG可以利用大模型能力通过语义相似度的方式,在文本数据上完成检索,并把其增加到大模型的输入当中。
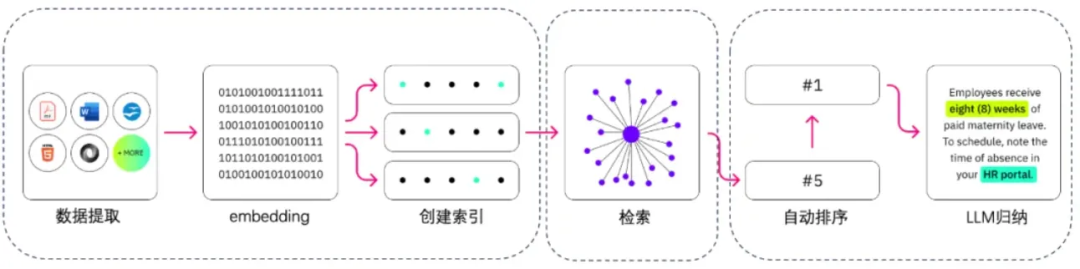
现在已经有了许多可以直接使用的 RAG 框架,如:LangChain, Milvus, LlamaIndex, Pincone 都提供了开箱即用的方案。RAG 技术也已经不仅仅局限于语义匹配本身,而诞生出了多种优化版本,也增加了例如 “Rewrite”, "Memory" 这样的模块,对于 RAG 技术感兴趣的同学可以阅读此篇:
RAG核心算法_rag项目设计算法点都有什么-CSDN博客
RAG技术简介及研究方向推荐_rag研究方向-CSDN博客
从应用角度重新看看 RAG ,不难发现其本质就是检索技术,只是 RAG 利用大模型能力实现了更强的语义维度的检索。即便利用最传统的 “关键词匹配” 也可以计算文本间的相似度,实现检索的效果。因此,RAG 并不是唯一的技术方案,在条件不足的情况下,我们可以结合场景找到最合适的检索模式,在输入中增加更多信息才是最核心的思想。
以上,结合 RAG 介绍了 “如何增加信息?”,下面具体展开 “我们要增加什么信息?”。
示例(Few-shot)

Few-shot 是无监督学习的一种基本范式,相较于直接提问的方式,One-shot 会提供一条示例,Few-shot 会提供多条量示例再进行提问,以此提升模型的效果。在不进行专项训练的情况下,通过提供示例可以很好的提升模型的准确性和稳定性,在各类大模型的论文中也可以看到这样的对比,在各类任务中均可以表现出更好的效果。
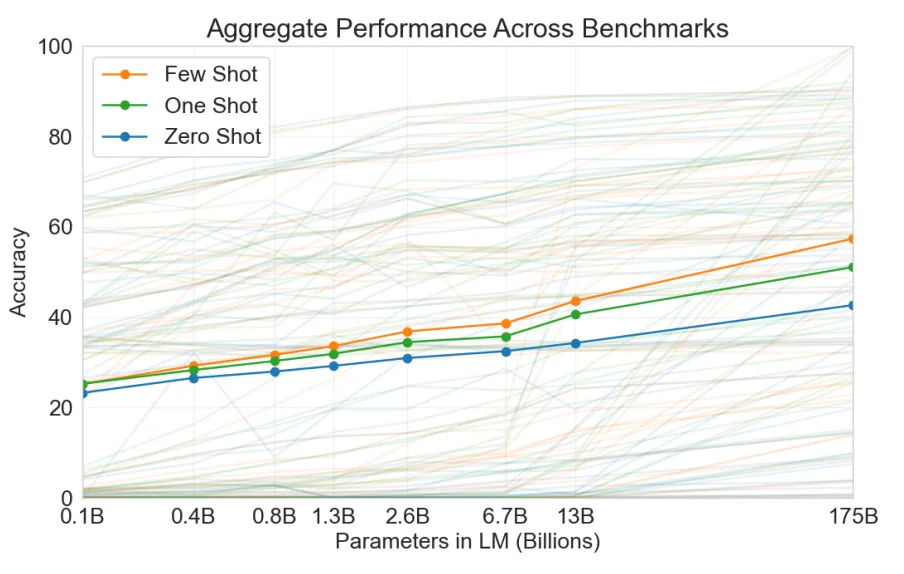
Few-shot 不足之处在于,当你提供示例后,模型会更多的参照示例回答,而在某种程度上降低了模型本身的思考能力。Few-shot中的示例提升了模型结果的确定性,自然会影响模型展现出的智能水平,特别是对于基于表征学习的大语言模型。
我们应该如何缓解这个弊端呢?除了Prompt 对模型进行引导外,让示例变得 “少而有效”。通过提供更具参考性的示例,提升每条示例的价值,同时降低示例的数量,可以尽量减少示例带来的负面影响。为了达到 “少而有效” 的效果可以借助 “RAG” 技术,通过检索,可以更精准的找到与当前任务最相近的示例(或反例),增强模型对当前任务的理解,以此提升模型在专项任务中的效果。
记忆(Memory)
除了在输入中增加“示例”外,我们还可以增加“历史记录”,为大模型增加 “记忆(memory)”, 可以弥补大模型在知识整合和长期记忆方面存在的明显短板。人脑之所以能持续不断地整合知识,为我们的思考和决策提供支持,离不开长期记忆的积累。
在一次会话的上下文可以被称作“短期记忆”,而对于历史的对话内容则可以被称为“长期记忆”,在适当的场景调用这些记忆,为当前的对话补充必要的上下文,让模型了解更多必要的背景信息,从而在当前任务中表现的更好。在更长的生命周期上,让模型可以调度历史的“对话内容”也被认为是模型不断进化的方向之一。
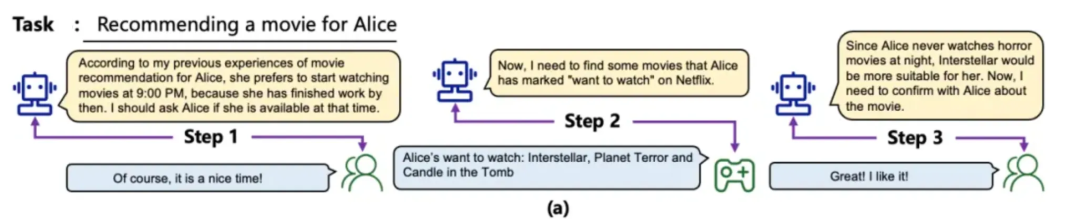
例如,在上图的例子中,当大模型进行电影推荐任务时,会调取历史记忆,确定用户倾向的电影类型和看电影的时间,这些信息会在模型推理的过程中被加入到输入中,以此推荐出更符合预期的结果。

根据每一轮对话的输入,利用“RAG”技术,动态的从记忆库中获取合适的内容加入到输入中,让大模型可以跨任务,跨周期的进行历史数据的获取,实现“通过长期记忆让模型自我进化”的目标。“记忆” 是十分重要的大模型推理模块之一,在 Agent 建设中也扮演了重要的角色。
例如,来自俄亥俄州立大学和斯坦福大学的科学家们希望让AI拥有一个类似人类海马体的"记忆大脑"。从神经科学的角度出发,模仿人脑海马体在长期记忆中的作用,设计出一个名为 HippoRAG 的模型,能够像人脑一样高效地整合和搜索知识。
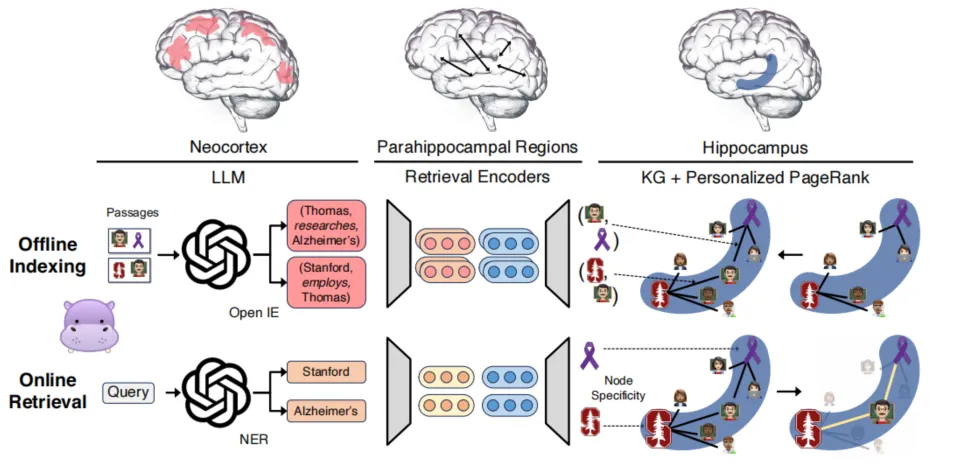
他们利用LLM处理信息,并用一个知识图谱来充当“记忆索引”,引入了检索模型来连接语言模型和知识图谱。当模型接收到一个新的查询时,它先从查询中提取关键概念,然后在知识图谱上应用 “Personalized PageRank” 算法进行概念扩展和检索,模拟海马体的联想记忆能力。最后,模型根据节点的重要性对 passage 进行排序和检索,进行“模式补全”。实验表明,这个“记忆大脑”能够在多跳问答等需要 “知识整合” 的任务上取得大幅提升。

对这个方向感兴趣的同学也可以查看以下文章:
Mem0:LLM个性化、陪伴式开源框架-CSDN博客
专业领域
大模型擅长回答通用的知识,但对于专业领域内的知识就没那么擅长,而大多数应用场景上,往往要处理某个专业领域内的专项任务,需要大模型理解必要的专业知识和专业方法,并在合适的时候调度它们,从而取得稳定的效果。
比如“测试领域”中编写测试用例,要完成该任务,就需要大模型了解足够的领域知识,例如测试用例的检查标准,常用的测试方法,各类用例设计方法,以及必要的业务背景知识。为了能让大模型具备这些支持,需要与领域专家协作,对测试域相关的知识进行整理。

同时,专业领域的知识与具体任务息息相关。例如,对 “用例检查” 任务而言,目的是通过用例检查发现用例中存在的问题。通过对漏测问题进行分析,在确定检查点的同时,结合用例现状和专业知识进行了问题定义的梳理,明确问题定义才好让大模型更贴合我们的专业领域。
除了对专业知识的整理,利用 RAG 的方法,结合具体任务动态的从知识库中引入必要的知识。例如,当用户的输入中包含某些专业词汇或业务概念时,需要动态的识别到它们,并对其进行解释和补充。
无论是 “静态知识” 还是 “动态知识”,都是通过对专业知识的整理,弥补大模型在专业领域上的不足,我们要将”专业知识“翻译成”通用知识“ 告诉模型大模型,让大模型更好的应对专业领域。这一步往往需要领域专家的介入以及对知识的人工整理,是决定大模型效果上限最重要的因素之一。
总结(增加更多信息)

我们通过进一步增加信息的方式提升模型的效果,并通过两个问题分析了增加信息的方式:
- 如何增加信息:RAG,或其他检索方式。
- 增加什么信息:
-
- 示例(Few-Shot)
- 历史记录(记忆)
- 专业知识,领域知识,业务知识
我们通过框架和额外信息的增加,在输入层面上完成了 Prompt 的调试,接下来就需要让模型根据我们的输入进行推理,而推理本身的效果也是影响模型效果很重要的因此,下面就来展开谈谈,如何在输入的基础上提升模型的推理能力。
让大模型更好的思考
什么是 CoT
2022 年,在 Google 发布的论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》中首次提出,通过让大模型逐步推理,将一个复杂问题分解为若干个子问题,并一步一步的进行推理,通过这种方式可以显著提升大模型的性能。这种推理方法就被称为思维链(Chain of Thought)。
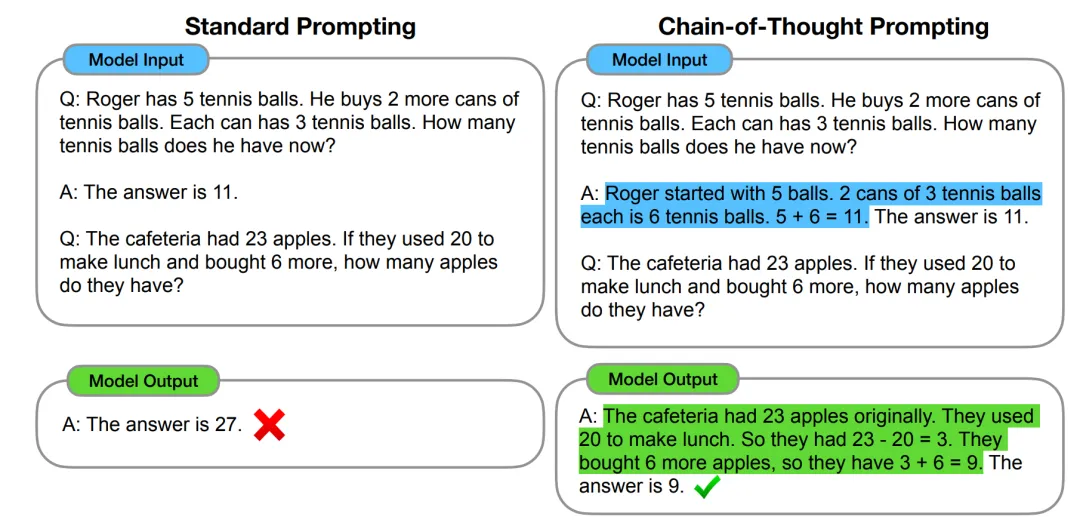
区别于传统 Prompt 通过控制输入直接端到端的得到输出,即 input ——> output 的方式,CoT 完成了从输入到思维链再到输出的映射,即 input——> reasoning chain ——> output。
自 CoT 问世以来,CoT 的能力已经被无数工作所验证,如下图所示,可以看到,相较于直接 Prompt, CoT 对所有的推理任务都带来了显著的提升
CoT 的实现

上图展示了几种不同范式下对CoT的实现。对于 Zero-Shot 而言只需要简单的一句 “Let's think step by step” 就可以让模型一步步思考;对于 Few-Shot 而言,除了在提问时引入分步的思想,还提供了逐步思考的示例,不仅可以让大模型分步思考,还可以通过示例告诉大模型应该如何分步;对于 Agent 而言,我们不光通过修改输入的方式实现 CoT,而是人为的对任务进行拆分,并通过多轮对话的方式将 CoT 引入到建模过程当中,实现整体任务维度的 CoT。
对Agent感兴趣的同学可参考如下文章:LLM+Agent技术-CSDN博客
如上图所示,CoT 的构造主要以线性为主,对任务进行线性拆分,并按先后顺序以此执行。而随着 CoT 相关研究的不断发展,思维链的形式不仅仅局限在线性的形式,而是衍生出了树状,表状,图状等多种类型,其中代表工作有 PoT,Tab-CoT,ToT,GoT-Rationale 等等,下图清晰的展示了这几种方法的异同:
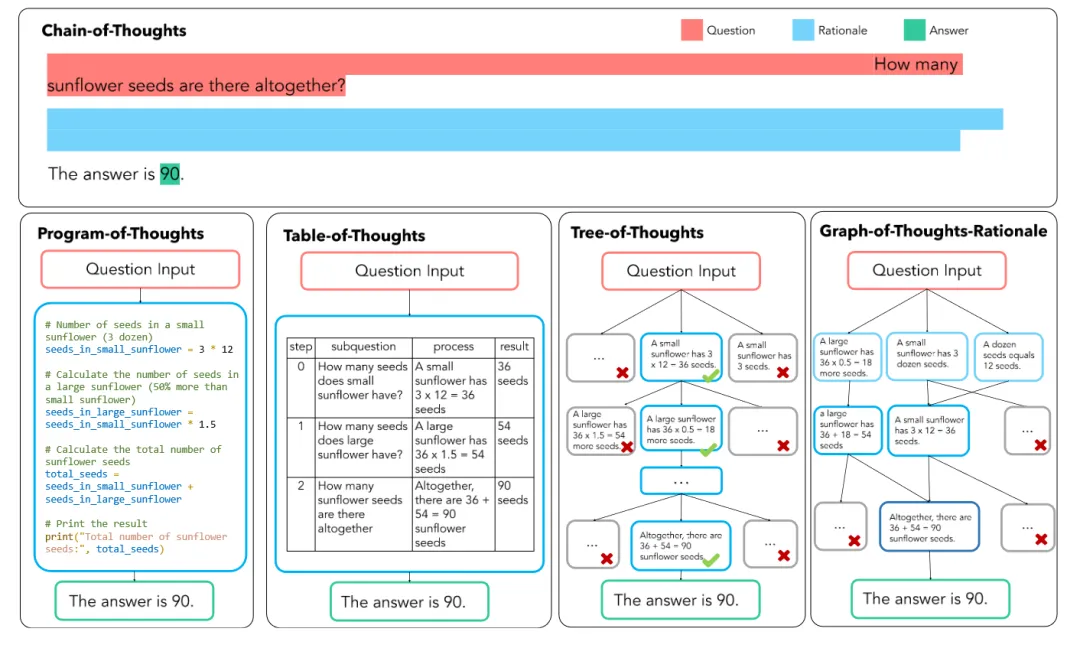
CoT 的应用
CoT 的本质是将一个高度不确定的复杂任务,拆分成若干个确定性较高的子任务,以此提升整个系统的效果和确定性。从 “zero-shot” 和 “few-shot” 范式中,CoT 这是一种推理技巧,而从 “Agent” 范式看,CoT 则更像一种建模思路,这也是 CoT 更核心的思想。当我们面对一个复杂任务时,仅对输入进行改造是不够的,我们还需要进行任务维度的分解,用 CoT 的方式进行建模。
例如,如果我需要大模型帮我完成一篇文章,我有两种做法:
- 输入信息 - 输出文章。
- 输入信息 - 输出大纲 - 完善大纲内容 - 依据要求进行调整 - 输出文章。
这个例子只是一个简单的拆分,但也能在效果上得到很大提升。下面举一个我们实际工作中的例子,我们希望大模型帮助测试同学编写“测试用例”,对于这个任务而言,最直观的做法就是把 “需求” 做为输入,让大模型根据需求进行测试设计,生成“测试用例”,而需求的复杂程度和不确定性对任务造成了极大的阻碍,因此我们引入 CoT 的思想对任务进行了拆分。
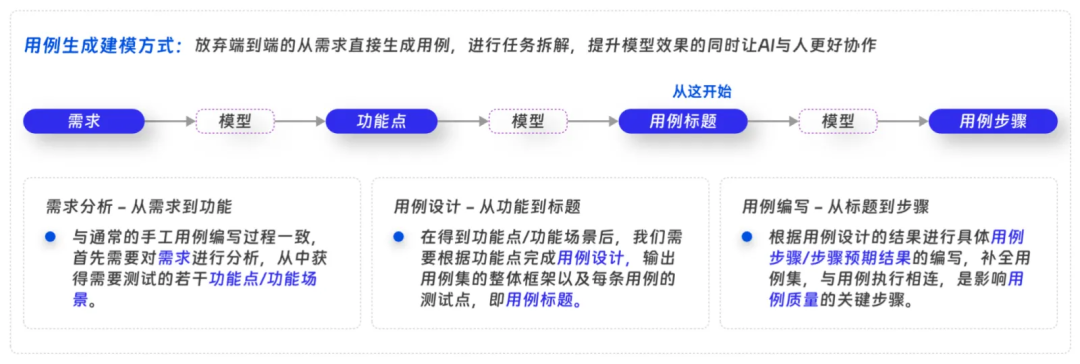
我们将复杂任务划分为三个主要阶段,以提高研发和应用的效率:
- 需求分析:首先,我们对需求进行深入分析,明确需求内容,并从中提取功能点和测试对象。
- 用例设计:接着,基于提取的功能点设计测试用例,构建用例集的结构,并为每条用例定义测试点。
- 用例补全:最后,根据需求和测试点,编写用例的具体步骤和预期结果。
这种分阶段的方法简化了任务处理,使研发团队能够快速识别并处理相对简单的阶段,如用例步骤的生成,从而加速项目进度。同时,它也适用于其他任务,如文章编写,通过优先处理简单的子任务来提高效率。
在应用方面,尽管大模型展现出强大的能力,但其局限性也日益明显。因此,“人机协同”模式被认为是更有效的应用方式。通过任务的细分,每个子任务都可以与人协作,例如,人类可以分析需求,而大模型则负责用例设计。这种协同工作模式有助于大模型更快速、更有效地应用于实际工作中。
其他优化技巧
前文中,我们已经介绍了 Prompt 调试的主要步骤,也是一条标准的工作流,可以帮助我们从 0 到 1 的完成 Prompt 的编写和调试:“Prompt 框架” - “细化框架” - “增加更多信息” - “CoT”。而正如开篇时提到的,Prompt 相关的技巧已多如牛毛,并且一直随着模型的迭代而不断更新,我们前文中讲的是 “Prompt 工程” 的主要步骤和思想,而在其之上,还是有不少技巧可以进行进一步的优化,下面我选择其中最重要的几点展开聊聊。
用参数控制模型确定性
除了调整模型的输入外,大模型还有2个参数可以调节:温度(Temperature),Top-P。这两个参数也与大模型效果息息相关,控制着大模型输出的确定性。大模型的本质是在 Token 的概率空间中进行选择,依据概率选择接下来要输出的 Token,而这 2 个参数就是在控制这个过程。
Temperature(温度)是一个正实数,用于控制生成文本的随机性和多样性。在生成过程中,模型会为每个可能的下一个词分配一个概率,而调整温度,则可以影响这些概率分布的形状。当温度接近 0 时,输出文本会变得更加确定,模型更倾向于选择具有较高概率的词,这可能导致生成的文本质量较高,多样性较低。当温度接近 1 时,输出文本的随机性增加,模型会更平衡地从概率分布中选择词汇,这可能使生成的文本具有更高的多样性,但质量可能不如较低温度时的输出。温度大于 1 时,输出文本的随机性会进一步增加,模型更可能选择具有较低概率的词。
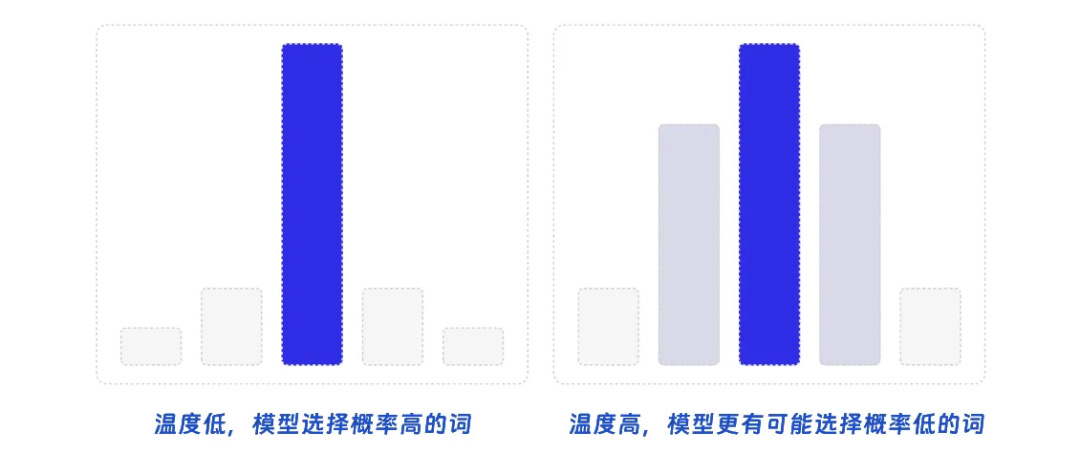
Top-p 是一个 0 到 1 之间的实数,表示另一种生成策略,它根据概率分布的累积概率来选择候选词。具体来说,模型将根据词汇的概率对其进行排序,然后选择一个子集,使得这个子集的累积概率至少为 p。当 p 接近 1 时,生成的文本将包含几乎所有可能的词汇,导致较高的随机性和多样性。当 p 较小时,生成的文本将仅包含具有较高概率的词汇,降低随机性并提高输出质量。然而,过低的 p 值可能导致模型过于保守,生成的文本过于重复或单调。
为了了便于理解,我们可以举一个抽象的例子,帮助大家理解。假设我们有一个语言模型,它正在预测句子中的下一个单词。我们输入的句子是我喜欢吃苹果和____,那么模型可能会为香蕉分配 0.4 的概率,为橙子分配 0.2 的概率,为鸭梨分配 0.2 的概率,为白菜分配 0.1 的概率,为萝卜分配 0.1 的概率。
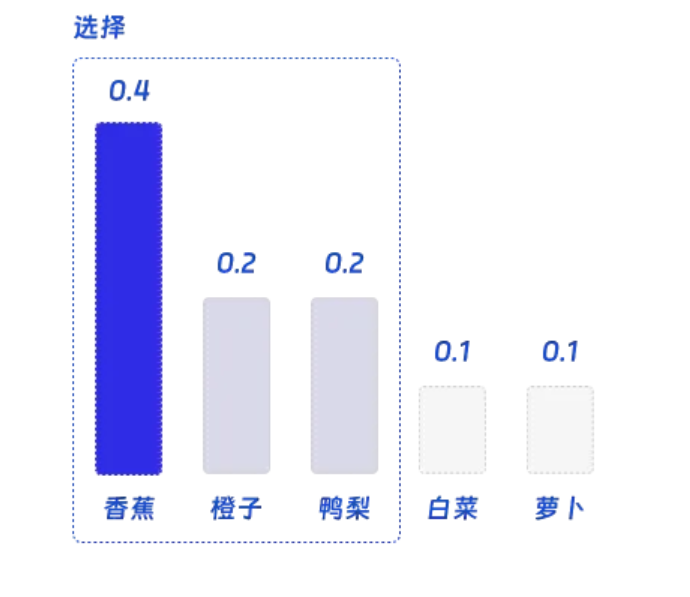
假如我们设定Top-P = 0.8,则我们会按照概率大小选择尽可能多的词,并让概率的总和小于 0.8。因此我们会选择 “香蕉”,“橙子”,“鸭梨”,而如果再加上 “白菜” 则累计概率会超过阈值 0.8。
最后模型会在 “香蕉”,“橙子”,“鸭梨” 中随机选择一个单词。在这个例子中,我们有 50% 的几率会选择 “香蕉”,25% 的几率选择 “橙子”,25% 的几率选择 “鸭梨”。这一步中的概率还会被 “Temperature(温度)” 所影响。
总结而言,温度(Temperature)和 Top-p 是对模型输出确定性的控制,我们可以根据具体的应用场景进行合理选择。
让大模型帮你优化 Prompt
我们也可以使用LLM帮我们自动优化 Prompt 。这个研究方向自 ChatGPT 以来就一直得到大量关注,且得到了诸多应用,不光可以对已有的 Prompt 进行优化,还可以自动找到一些 Prompt 语句,神奇的产生通用的效果。
例如,在 “Zero-Shot COT” 里的那句 “Let's think step by step”,谷歌就曾通过这种方式找到了更好的一句:“Take a deep breath and work on this problem step-by-step”,让 GSM8K 的结果直接从 71.8% 上升到了 80.2%。
这个研究方向诞生了多种算法,下文将挑选其中最经典的几个算法,希望可以让大家更好的了解该领域。
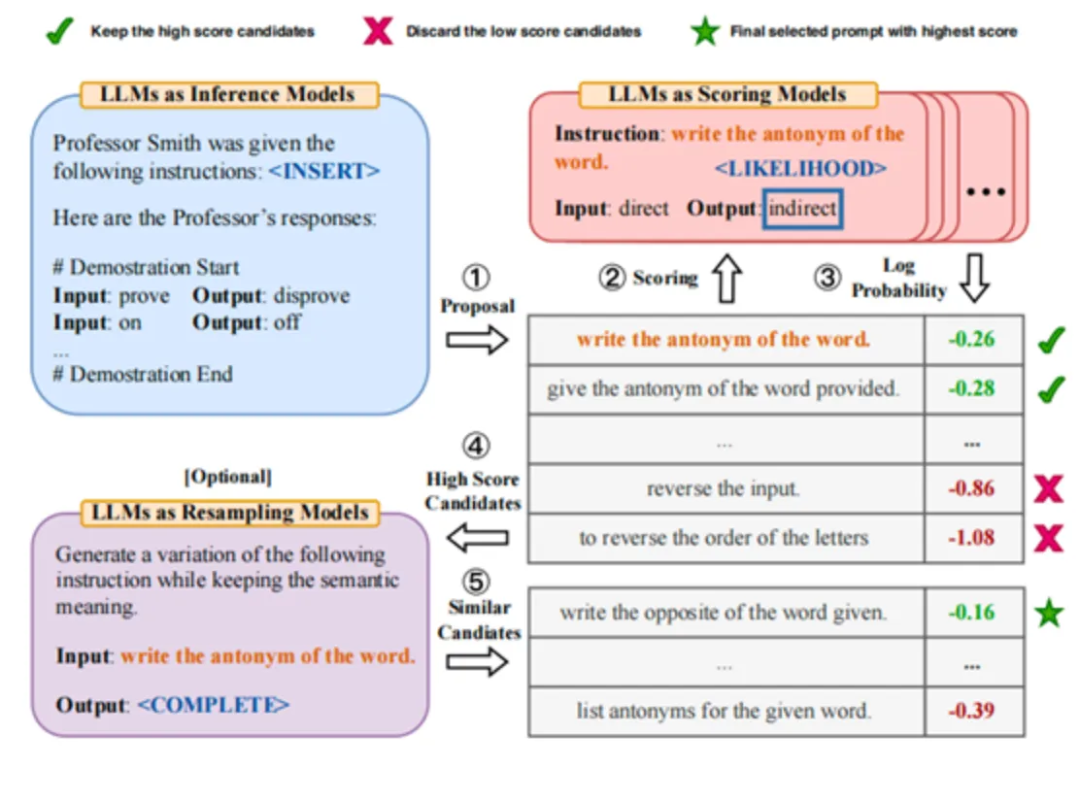
APE 是其中最经典的算法,核心思路是:从候选集中选出若干较好的 Prompt,再在这些 Prompt 附近进行 “试探性搜索”。其过程为,先通过大模型生成若干 Prompt,再在训练集上打分,保留较好若干条的 Prompt,最后在这些高分 Prompt 附近进行采样,模拟 “Monte-Carlo Search” 的过程,优化得到最理想的 Prompt。
APO 算法则是引入了 “梯度下降” 的方法,通过训练集得到当前 Prompt 的梯度,在应用“梯度下降”的方式得到新的 Prompt,最后与 APE 一样进行采样,得到最终的 Prompt。

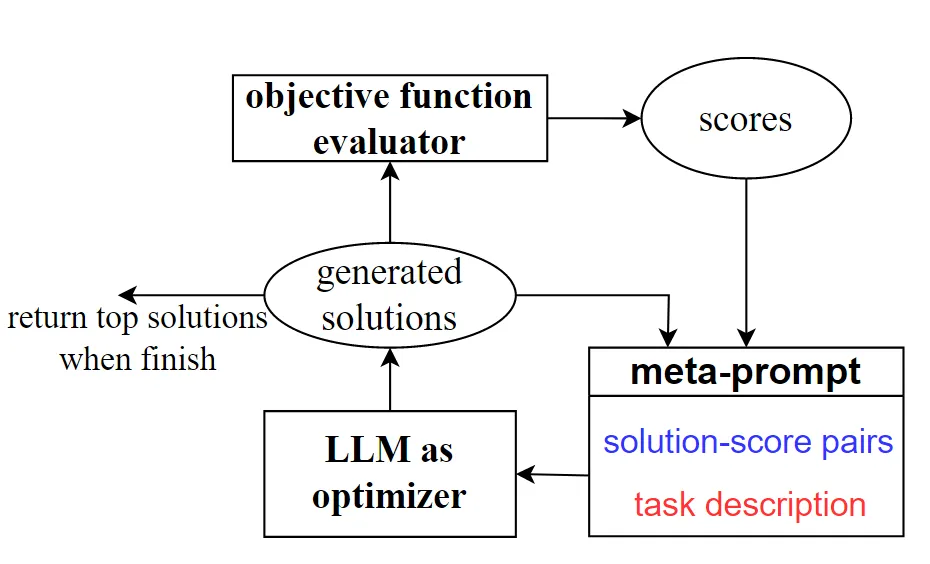
OPRO 算法则是更复杂的利用 LLMs 作为优化器。OPRO 采用自然语言描述和指引优化任务,通过 LLMs 的指导,结合先前找到的解决方案,不断生成更新的策略。
更多技巧
本文通过体系化的梳理 “Prompt” 相关工作,尝试用一套通用的框架,对 Prompt 工程的相关工作进行梳理和总结。但在统一的框架之外还有各种技巧,可以起到锦上添花的作用,此处总结其中的 3 个重要方法,在实践中起到了不小的作用:
- 自我一致性:多让模型输出多个回答,然后在 LLM 的多次回答中选择出现多次的答案。
- 反思:通过让大模型评估自己的输出进行调整,得到更优的输出。
- 知识生成:让大模型生成问题相关的知识,再提出问题,提高大模型回答的准确率。
对于这部分技巧不再展开,如果大家对这些方法感兴趣可以学习传播最广的 Prompt 知识库,Prompt Engineering Guid。
评估Prompt效果的常用指标
“Prompt 调试” 本质上是为了让模型在任务中有更好的效果,而这就涉及到效果的评估,当我们对 “Prompt” 进行了一次更新,我如何判断模型效果是不是变好了呢?要判断大模型的效果,首先需要有数据作为支撑,其次还需要确定衡量效果的指标。计算大模型在测试数据上的指标是判断大模型效果的依据,这里提供一些常用的指标,用来衡量大模型在各类任务中的效果。
分类问题
- 准确率:分类正确的样本占总样本个数的比例。
- 精确率(Precision):又称为查准率,分类正确的正样本占判定为正样本个数的比例。
- 召回率(Recall):又称为查全率,分类正确的正样本占真正的正样本个数的比例。
- F1 Score:是精确率和召回率的平衡,最常用的评价指标。
生成问题
- BLEU:比较生成数据和标注数据中 n-gram 的重合程度。
- METEOR:与 BLEU 相比不仅考虑了精确度和召回率,还考虑了生成结果的词序。
- 困惑度(Perplexity):所有测试样本的交叉熵损失求平均后取指数,用于衡量模型对测试数据的预测能力。困惑度越低,说明模型的预测能力越好。
- 采纳率:对于生成任务而言,往往没有明确的预期结果,更多采用人工采纳比例作为评价指标,更细的可以分为“直接可用率”和“修改后可用率”。
其他可参考的指标有:
相关性(Relevance)
- 定义:评估LLM输出与用户Query的相关程度。
- 评估方法:使用相关性评分系统,如余弦相似度或Jaccard相似度。
- 示例:用户询问“健康食谱”,LLM提供的食谱是否符合健康饮食的标准。
一致性(Consistency)
- 定义:评估LLM在不同时间或不同上下文中输出的稳定性。
- 评估方法:对比多次交互的输出结果,检查是否有显著差异。
- 示例:多次询问相同的问题,LLM是否给出相似的答案。
效率(Efficiency)
- 定义:评估LLM完成任务的速度和资源消耗。
- 评估方法:测量处理时间、内存使用等性能指标。
- 示例:LLM在有限的时间内生成高质量回答的能力。
用户满意度(User Satisfaction)
- 定义:评估用户对LLM输出的满意程度。
- 评估方法:通过用户调查、反馈收集和满意度评分。
- 示例:用户对LLM提供的客户服务或信息查询的满意反馈。
语言流畅性(Linguistic Fluency)
- 定义:评估LLM输出的语言自然度和流畅性。
- 评估方法:通过语言质量评分,如语法正确性、句子结构和词汇使用。
- 示例:LLM生成的文本是否读起来自然,是否符合人类的语言习惯。
通过深入探索Prompt优化技术和评估指标,为构建更加智能和高效的人工智能系统提供了重要的参考,从而可以更精确地设计和优化与LLM的交互。
对于专项任务而言,每个任务在调试前都需要准备自己独立的数据集,包含与每一个输入对应的预期结果,不同的指标代表用不同方式评估 “预期结果” 和 “实际结果” 的相似度。而对于一些通用的 NLP 能力而言,业内也有一些开源数据集,被用于衡量模型各项通用能力的效果(文本摘要,语义理解,对话,e.t.c.),如果你正在调试一项通用能力,或没有足够的任务数据,就可以利用公开数据集,如ChineseGLUE、LCQMC、Duconv、WebQA、CMRC 2018等中文数据集。
Prompt工程的高级应用
动态Prompt的构建
动态Prompt是一种可以根据用户输入或上下文信息实时调整的Prompt。这种类型的Prompt允许LLM在交互过程中自适应地改变其响应。
- 自适应学习:LLM可以根据用户的反馈或新信息调整其回答。
- 上下文融合:将新的上下文信息融合到Prompt中,以保持对话的连贯性和相关性。
- 示例:在多轮对话中,LLM可以根据用户的问题和反馈动态调整其回答,提供更加个性化的建议或信息。
利用Prompt进行数据集分析
LLM可以用于分析和解释数据集中的模式和趋势,而无需复杂的编程技能。
- 数据洞察:使用Prompt指导LLM识别数据集中的关键模式和异常。
- 可视化辅助:结合Prompt和LLM生成的描述来创建数据可视化的草图或概念。
- 示例:通过Prompt,LLM可以分析客户反馈数据集,识别最常见的问题和主题,为产品改进提供依据。
结合人类反馈进行迭代优化
将人类的专业知识和反馈整合到Prompt工程中,以实现更高层次的优化。
- 反馈循环:建立一个机制,通过用户的反馈来不断优化Prompt。
- 专家审核:让领域专家审核LLM的输出,确保专业性和准确性。
- 示例:在医疗咨询领域,医生可以审核LLM提供的健康建议,确保其符合医疗标准。
跨模态Prompt应用
跨模态Prompt允许LLM处理和生成多种类型的内容,如结合文本、图像和声音。
- 多模态理解:LLM可以同时处理文本和图像,提供更丰富的回答。
- 创意合成:结合不同模态的信息,LLM可以生成新的创意内容。
- 示例:在广告创意过程中,LLM可以根据文本描述和图像生成吸引人的广告脚本。
Prompt的可扩展性和泛化能力
开发可扩展和泛化的Prompt,使其能够适应不同的任务和领域。
- 领域适应:Prompt可以根据不同领域的特点进行调整,提高适应性。
- 任务泛化:设计能够处理多种任务的通用Prompt。
- 示例:创建一个通用的教育Prompt,可以适用于不同学科和教学场景。
结论
Prompt工程在不同领域的广泛应用和巨大潜力,从市场分析到客户服务,从内容创作到教育和法律咨询,Prompt工程通过优化人机交互,提高了效率、创造力和专业性。本文体系化的对 “Prompt 工程” 的相关工作进行了梳理,得到了一个标准化的工作流,帮助大家可以从 0 到 1 的完成一个 Prompt 的书写和调试,并通过这样结构化的拆分,增强对 Prompt 的管理。供各位读者参考
- 通过 Prompt 模版写出第一版 Prompt。
- 细化模版各部分内容,整理 Prompt 格式。
- 使用 RAG 增加更多信息(few-shot,记忆,专业知识)。
- 利用 CoT 增强模型推理能力。
- 利用更多技巧不断优化。

![NSSCTF练习记录:[SWPUCTF 2021 新生赛]caidao](https://i-blog.csdnimg.cn/direct/04375c1eadaf4f5f835b9dfc9ee33c03.png#pic_center)