背景
2023年CodeFuse完成了百亿级别的代码大模型从0到1的预训练,配合指令微调、量化部署等一系列配套技术,成功将AI大模型能力应用到多个下游研发场景,助力生产提效。在众多下游产品中,CodeFuse代码补全插件直接触及研发过程中最核心的编码场景,因此对开发效率的影响最显著。目前,CodeFuse代码补全插件是CodeFuse系列产品中用户数量最多、留存率最大,调用AI能力最多的产品。
目前,大部分代码语言模型在预训练阶段以文件为基本单位,随机选择代码文件拼接固定长度后组成训练样本。常见的代码评测数据集(HumanevalX、MBPP)也以单文件为主:基于待补全位置(Task Hole)的前缀(Prefix)使用Left-to-Right方式推理,或者同时使用前缀(Prefix)和后缀(Suffix)采用FIM(Fill In the Middle)方式推理。然而,实际的开发场景通常以代码仓库(Repository)为基本单位。在目前常见的业务设计模式下,大量与当前编辑文件存在依赖关系的内容散落在仓库内的的其他文件中,模型仅使用当前编辑文件内容预测会存在上下文不足的问题,从而导致补全结果存在幻觉、不准确等问题。目前,比较常见的解决思路是使用RAG的方法抽取一定代码片段作为上下文指导模型推理,但此方案同时会带来"上下文-延迟困境"的挑战。即丰富的上下文带来的效果提升和更长的提示内容增加的推理时间之间的权衡,这种权衡在IDE场景中可能会影响用户的实际体验。
为了解决上述问题,本文提出一种仓库级别代码补全框架RepoFuse:通过对实际编程的总结抽象,我们的方法从仓库中抽取了两种关键的跨文件上下文:基于代码相似性分析的相似上下文(Similar Context),用于识别功能相近的代码段;以及语义上下文(Semantic Context),提供类别分类和API交互的语义理解。然而,如此大量的信息可能导致模型的输入过于冗长,影响推理生成的效率。为此,RepoFuse采用了一种基于相关性引导的上下文选择策略(Relevance-Guided Context Selection)指导模型Prompt的构建。这种技术有选择地筛选出与当前任务最相关的上下文,将上下文精炼为简洁的Prompt,既能适应有限的上下文长度,又能确保高完成度的准确性。本文使用常见的开源代码模型在CrossCodeEval的Java和Python数据集上进行了实验,结果表明在完全匹配指标(Exact Match)上RepoFuse有3.01到3.97的提升(与当前主流开源工具的SOAT对比)。
相关工作
目前业界的相关工作主要沿用RAG的思路,代表工作如下表所示。具体来说,每一个方法需要回答以下三个问题:搜什么、怎么搜以及怎么用:
| 名称 | 搜什么 | 怎么搜 | 怎么用 |
|---|---|---|---|
| RLPG | 启发式搜索规则 | 判别模型选择搜索规则 | Prompt Engineering |
| RepoFusion | 同RLPG | 同RLPG | Fusion-In-Decoder |
| ReACC | 外部知识库相似片段 | 相似度搜索 | Prompt Engineering |
| RepoCoder | 仓库内相似片段 | 生成 + 相似度迭代搜索 | Prompt Engineering |
| CrossCodeEval | 仓库内相似片段 | 相似度搜索 | Prompt Engineering |
| RepoBench | 语义依赖信息 | AST | Prompt Engineering |
| Cocomic | 语义依赖信息 | Dependency Graph | Fusion-In-Decoder |
RLPG首先定义了63种启发式搜索规则,每一种搜索规则由Prompt Source和Prompt Context Type两部分组成。在补全时,使用一个分类模型判别最适合当前场景的搜索规则,为模型提供Example Specific的Context。 RepoFusion是RLPG的延续工作,差异点在Context信息的使用方式上。RepoFusion采用了Fusion-In-Decoder的模型结构使用Context信息,具体如图1所示:将不同的Context信息并行使用Encoder模型编码成Embedding表示,再将这些Embedding信息拼接起来使用DeCoder模型进行推理预测。相比目前常见的Decoder-Only的模型结构,Fusion-in-Decoder将Context信息压缩成Embedding后再处理,理论上可以使用更多Context信息,但使用此结构需要额外准备数据集进行训练。

图1:RepoFusion流程
ReACC使用待补全的代码在离线收集好的代码数据库中进行相似度检索,并利用相似片段辅助模型补全。RepoCoder提出了迭代式的“检索-生成”框架:先进行第一次检索,利用LLM生成一次补全结果。再使用生成后的结果进行二次检索并指导模型生成,反复循环直至迭代结束。结果表明迭代式搜索策略比直接搜索在效果上更好,但迭代搜索必然会带来推理耗时翻倍,难以直接用于真实的补全场景。此外,RepoCoder还提出了仓库级别代码补全数据集RepoEval,支持行、片段、方法级别的补全任务。
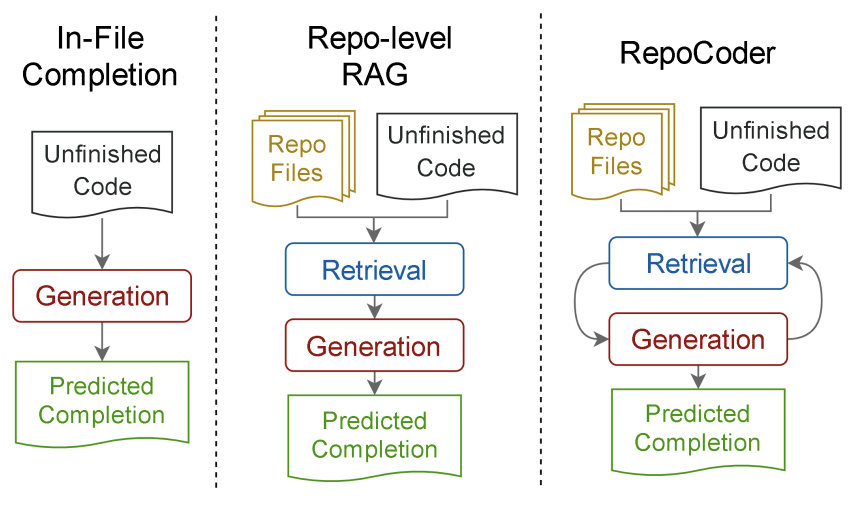
图2:RepoCoder流程
CrossCodeEval和RepoBench分别提出了仓库级别代码补全的BenchMark,区别在于CrossCodeEval使用仓库内相似代码片段辅助模型补全,而RepoBench则使用AST分析出当前文件的Import内容,并将其视作补充上下文。
CoComic使用程序分析领域的Dependency Graph搜索,图中的节点为仓库中不同粒度程序片段的抽象表示(File、Class、Method、Global Variable),边则是这些节点之间的程序依赖关系。在补全时,首先定位到待补全片段所在的节点,然后将其邻居节点视作补充上下文。由于节点数量众多,无法全量放置到Prompt中,CoComic也采用了类似Fusion-in-Decoder的方法进行训练。
方法
我们的思想源于对软件开发实践的观察:当程序员开始向一个仓库贡献代码时,必须展现两项基本技能。首先,程序员必须熟练掌握仓库的架构,包括跨文件的模块、库和API。对这些仓库级别信息的全面理解至关重要,因为它允许他们在相应的开发环境中准确编写代码,避免任何误解或错误——这在编程上下文中常被称为“幻觉”。其次,程序员应该逐渐熟悉仓库。通过借鉴仓库内类似模块的灵感,他们可以在为特定任务编写代码时模仿之前的设计和实现。
为了与人类编程的逻辑过程保持一致,我们提出了一种仓库级别的代码方案RepoFuse,利用仓库内其他文件的信息提高代码补全准确率。具体来说,我们引入两类上下文信息:Semantic Context和Similar Context,它们分别指示当前补全环境中可用的程序依赖语义信息和仓库中与之相关的相似代码片段。如图3所示,模型补全左上角的代码片段时,在Semantic Context(红色)和Similar Context(绿色)的指导下,可以正确的补全出答案。
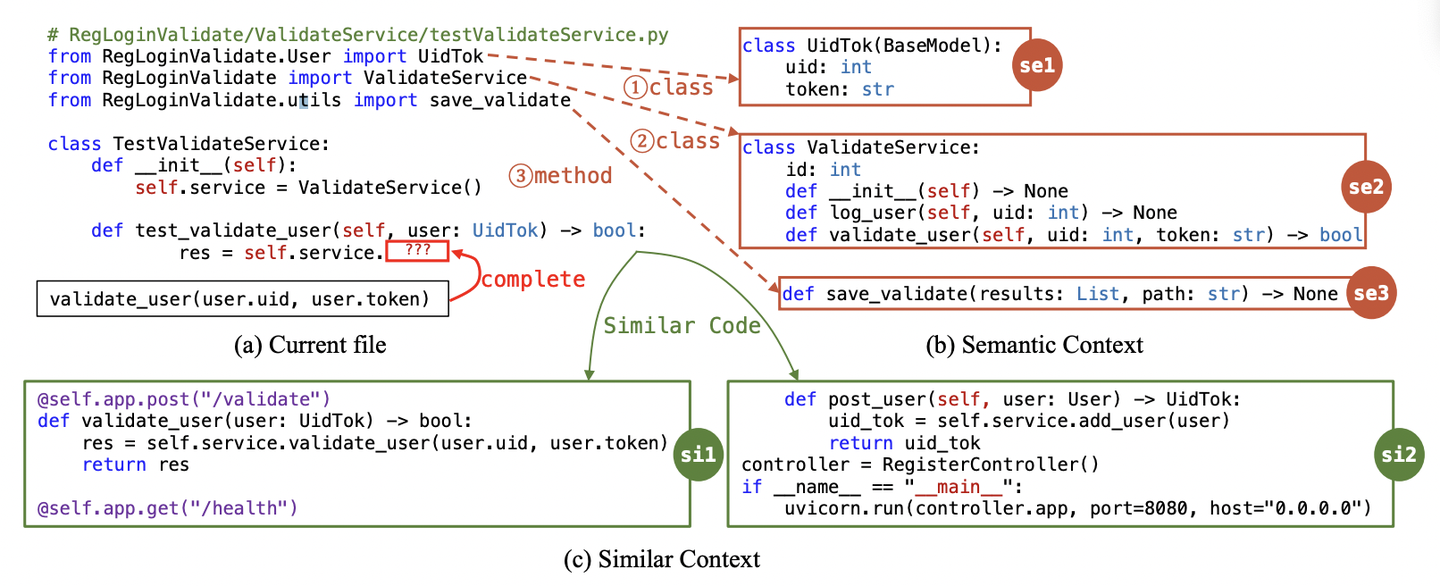
图3:Semantic和Similar Context的示例
RepoFuse的工作流程如图4所示,分为三个阶段:Semantic Context Analysis、Similar Context Retrieval和Relevance-Guided Context Selection,下面的章节将分别进行详细介绍。
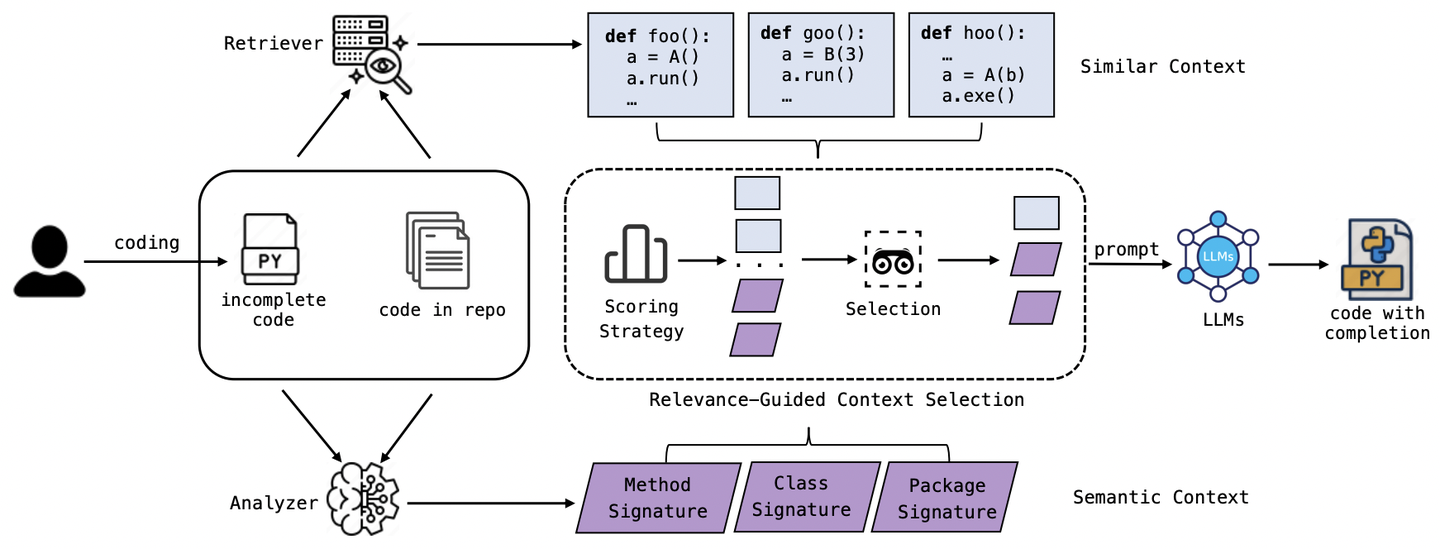
图4:RepoFuse工作流程
Semantic Context Analysis
在软件开发中,我们通常使用Import语句引入包、模块或头文件等内容,表明了当前文件可用的类及方法。如果缺少这些信息,模型在补全相关内容时只能靠猜测,从而产生幻觉问题,我们认为这些信息对当前文件的代码补全具有“理性”指导的意义。假设我们将代码补全的过程视作做数学题题的过程,那这些跨文件的依赖信息可以视作这道题背后的数据公式、数学定理等。具体来说,我们采用了一种专门的工具,称为Repo-specific Semantic Graph。这种图结构是对传统代码依赖图的扩展,用于分析和展示代码库中不同实体(如函数、类、模块等)之间的关系。它使用图数据结构来呈现这些实体及其相互之间的依赖关系,并以多重有向图的形式存储这些信息,它的基本结构信息如下:
-
图(Graph):由节点和边构成
-
节点(Node): 具体包括Module、Class、Function和Variable
-
边(Edge): 具体包括Constructs、Imports、BaseClassOf、Overrides、Calls、Instantiates、Uses
在这个设计中,Repo-specific Semantic Graph会使用Graph类来存储代码实体(Node对象)和它们之间的依赖关系(Edge对象)。每个节点都会记录其在代码库中的位置,以及它的类型和名称。每条边则标识了两个节点之间的关系类型,以及关系在代码中的位置。
举一个简单的例子,如果一个函数A调用了另一个函数B,则可以在Repo-specific Semantic Graph中创建两个Node对象来表示这两个函数,并创建一个Edge对象来表示Calls关系,并在这个Edge对象存储下调用点(Call site)的位置。同样道理,如果一个函数A实例化了一个类X,则可以在依赖图中创建两个Node对象来表示A和X,并创建一个Edge对象来表示Instantiates关系,并在这个Edge对象存储下发生A实例化X(Object instantiation statement)的位置信息。Repo-specific Semantic Graph将这些对象组织成一个多重有向图,使得可以高效地查询任何代码元素的依赖关系。
这里以TinyDB的代码仓库为例,构建的Repo-specific Semantic Graph可以表示成下面这样的图。这里把不同关系表示成不同的边的颜色,节点的大小根据节点的度(degree)而定。
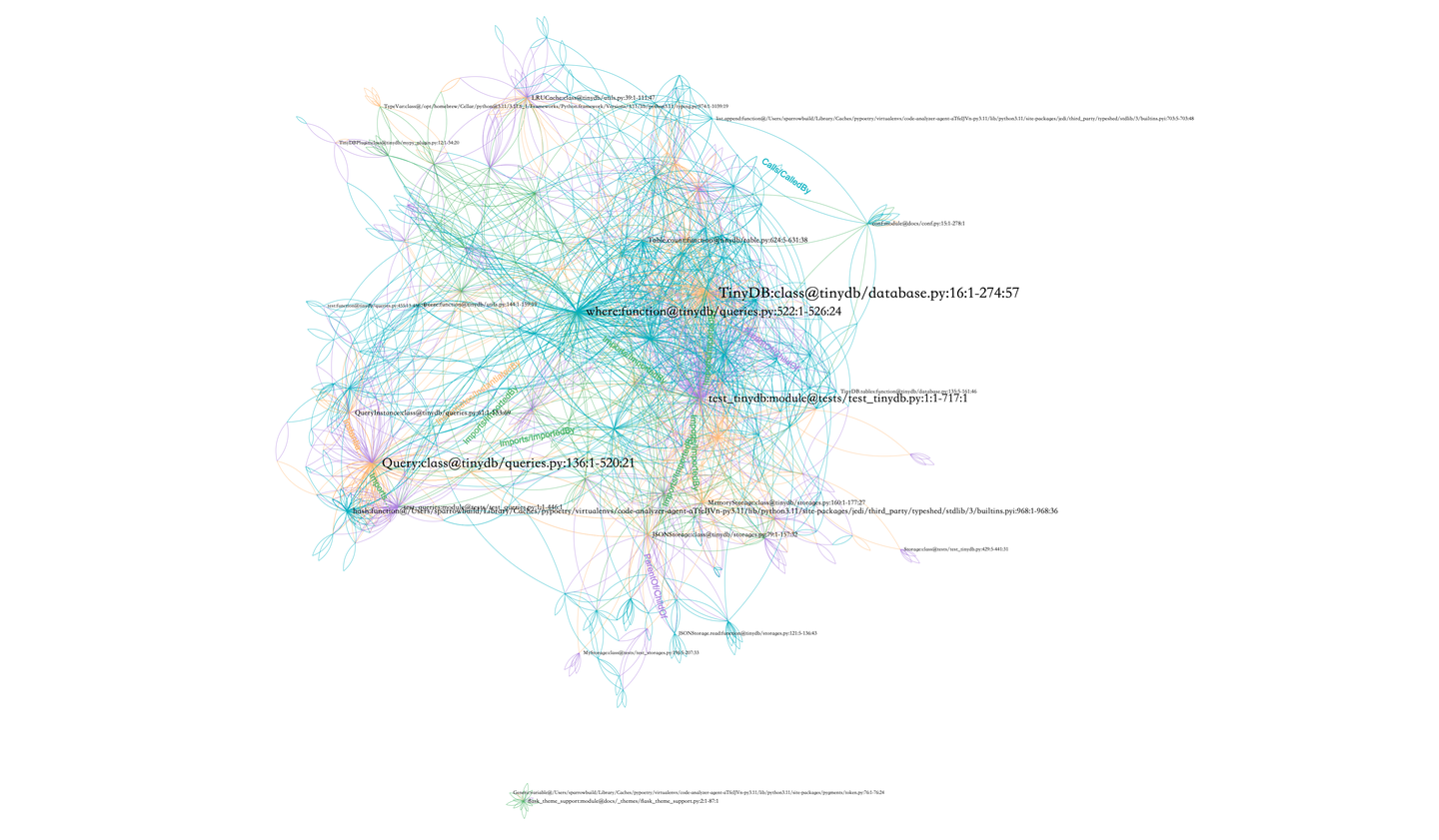
图5:Repo-specific Semantic Graph示例
Similar Context Retrieval
在程序开发中,我们如果要续写代码,时常会参考与当前正在编辑的代码片段相似的代码。如图3所示,图中的 se1 和 se2 均与当前代码片段 ck∗ 中出现大量重复的token,如user和service。这很可能意味着它们实现了与当前代码块相似甚至相同的功能,对代码补全过程有较大的指导意义。
所以,根据当前编辑文件中未完成的代码块 ck∗ ,我们可以通过一系列技术(如文本检索,向量检索),在其他源文件中发现几个相似的代码块(我们称为Analogy Context),并引入代码补全过程中。
Relevance-Guided Context Selection
Semantic Context和Similar Context都提供了比较有价值的信息。然而,在现实场景中,代码补全对于时间性能非常敏感。如果我们直接拼接这两类上下文(Dual Context),会导致Prompt过长,从而在LLM推理阶段引入额外的时间开销。为了有效地利用这两种上下文,我们提出了一种基于相关性的上下文选择技术,称为Relevance-Guided Context Selection(RCS),旨在通过相关性指导选择对模型补全最有益的上下文,我们将RCS策略选择出来的Context称为Optimal Dual Context(ODC)。
定义一个相关性打分方式 rck∗ ,规定 rck∗(e) 表示上下文片段 ck∗ 与待补全代码片段 e 之间的某种相关程度。在实践过程中,我们首先使用 rck∗ 对集合 U 中的候选代码片段从高到低进行排序,然后依次选择代码片段,直至达到长度上限 L 为止。以图2中的情况为例,我们的RTG策略选择了 se1 , se2 , si1 来加入prompt中。然后RepoFuse生成的代码中就借鉴了 ec1 中的代码validate user(user.uid, user.token)。与此同时,方法validate user的方法头,以及变量uid和token在类UidTok中的定义,都包含在了Semantic context中。在RepoFuse框架的引导下,大模型不仅看到了相似的代码实现,而且倾向于生成语法语义正确的调用,因此能在仓库级别代码补全任务中得到了更好的效果。
具体来说,我们设置了以下4种相关性函数 rck∗ :
-
Oracle:在这个理想化的场景中,候选集合 U 中的每个代码片段 e 分别与待补全的代码片段 ck∗ 拼接成Prompt输入给语言模型,而生成代码与真实代码(Ground Truth)之间的编辑相似性指标被作为其得分。该方法本质上是使用后验的方式评估候选集合 U 中每个代码片段的相关性,但由于需要巨大的计算需求,无法在实际场景中应用。
-
Semantic Similarity:我们使用Embedding模型对每个上下文 e 以及未完成的代码块 ck∗ 的语义表示进行编码。这些Embedding的余弦相似度用作得分。具体来说,我们采用了Unixcoder和CodeBert作为Embedding模型。
-
Lexical Similarity:使用了Jaccard Similarity和Edit Similarity进行相似度打分。
-
Random:随机打分,作为Baseline。
实验结果
实验设置
数据集:我们使用了目前的Sota数据集CrossCodeEval。CrossCodeEval是一个全面的数据集,专为评估仓库级别的代码补全框架而设计。它包括Python、Java、TS和C#的代码片段,并专注于理解跨文件上下文以进行准确的代码预测。我们采用EM(Exact Match)和ES(Edit Similarity)作为评估指标,遵循CrossCodeEval提供的定义。
模型选择:为了避免数据泄露,我们选择了三个2023年中之前发布的,模型最大长度支持8k的模型:StarCoder、CodeLlama、DeepSeek-Coder三个模型。考虑到实际补全场景很少使用参数量过大的模型,我们的实验聚焦在大小处于1B和7B之间的模型。由于上述模型都支持Fill-In-The-Middle(FIM)方式补全,为了贴近真实场景,本文所有的实验均采用FIM方式进行推理。
Baseline选择:为了评估RepoFuse的整体性能,我们选择了三种开源的、基于检索增强的仓库级代码补全方法进行对比。由于RepoFuse不涉及任何模型二次预训练或微调流程,为了保证公平对比,我们排除掉一些需要引入模型训练的工作,如[2], [3], [9]。具体来说,我们对比的Baseline有:
-
RLPG[1]:RLPG使用Repo-Level Prompt Generator和Repo-Level Prompt Proposals生成特定于示例的提示。在我们的实现中,我们直接利用RLPG生成的提示,尽可能多地将上下文输入到大语言模型中。这种方法仅支持Java语言。
-
RG-1和RepoCoder[4]:这种方法使用固定的Chunk size将代码仓库分割成代码块,并基于文本相似度检索相关上下文。然后,它迭代执行检索-生成循环,使用前一次生成的结果去检索下一次生成的上下文。RG-1代表循环中的第一次检索和生成步骤,而RepoCoder代表标准的迭代过程。在我们的实现中,迭代次数设为2。RG-1和RepoCoder都支持Java和Python语言。
-
CCFinder[7]:这是一个跨文件上下文查找工具,它通过Import语句从预构建的Project Context Graph中检索相关的跨文件上下文。我们使用了CCFinder-k(k = 2),将待补全代码实体的2跳邻居作为上下文。CCFinder仅支持Python语言。
补全性能
图6展示了RepoFuse与其他Baseline方法在CCeval数据集上Python和Java子集上的效果,其中方法名称后面的数字表示允许的上下文最大长度。如图6所示,结果表明RepoFuse在性能上表现卓越。具体而言,在Python数据集中,RepoFuse在EM指标提高了3.964%,ID-F1分数提升了3.786%。在Java数据集中,EM提高了3.014%,ID-F1分数提升了2%。值得注意的是,即使在1024的上下文长度下,RepoFuse的表现仍然超过了所有使用4096 上下文长度的Baseline方法。这凸显了RCS策略的重要性,即使在严格的输入限制下,也能提高代码补全的准确性。
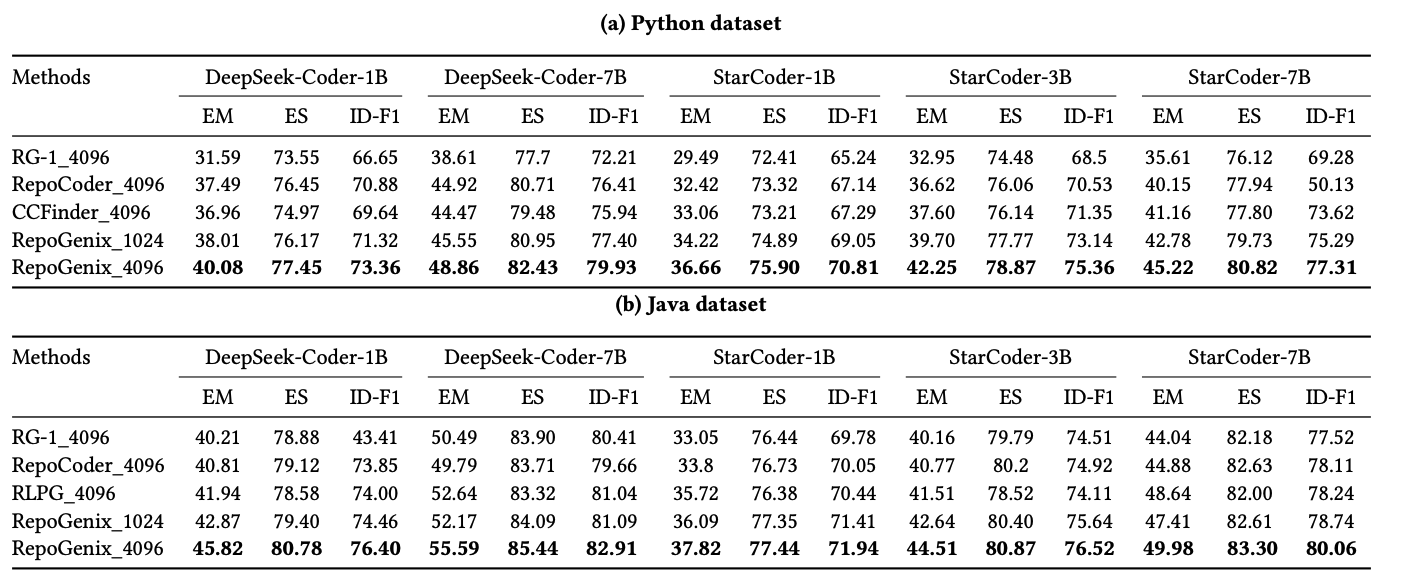
图6:RepoFuse与Baseline方法在Cceval数据集上的结果
此外,我们还评估了多个模型使用不同类型Context时,在各种Context长度(从256到4096)下的性能表现。结果如图7所示,在绝大部分实验设置下,使用RCS策略得到的ODC(Optimal Dual Context)的效果均优于单独使用SE(Semantic Context)或SI(Similar Context),说明两种类型的数据之间存在互补性。值得注意的是:ODC在1024长度的表现超过了SE和SI在4096长度下的表现。这说明了在有限的Token长度下,利用ODC的重要性:不仅提高了性能,还提高了推理速度。此外,DeepSeek-Coder模型在与其大小相当的其他语言模型中表现突出,这意味着在预训练期间整合跨文件数据显著提高了仓库级代码补全任务的性能。
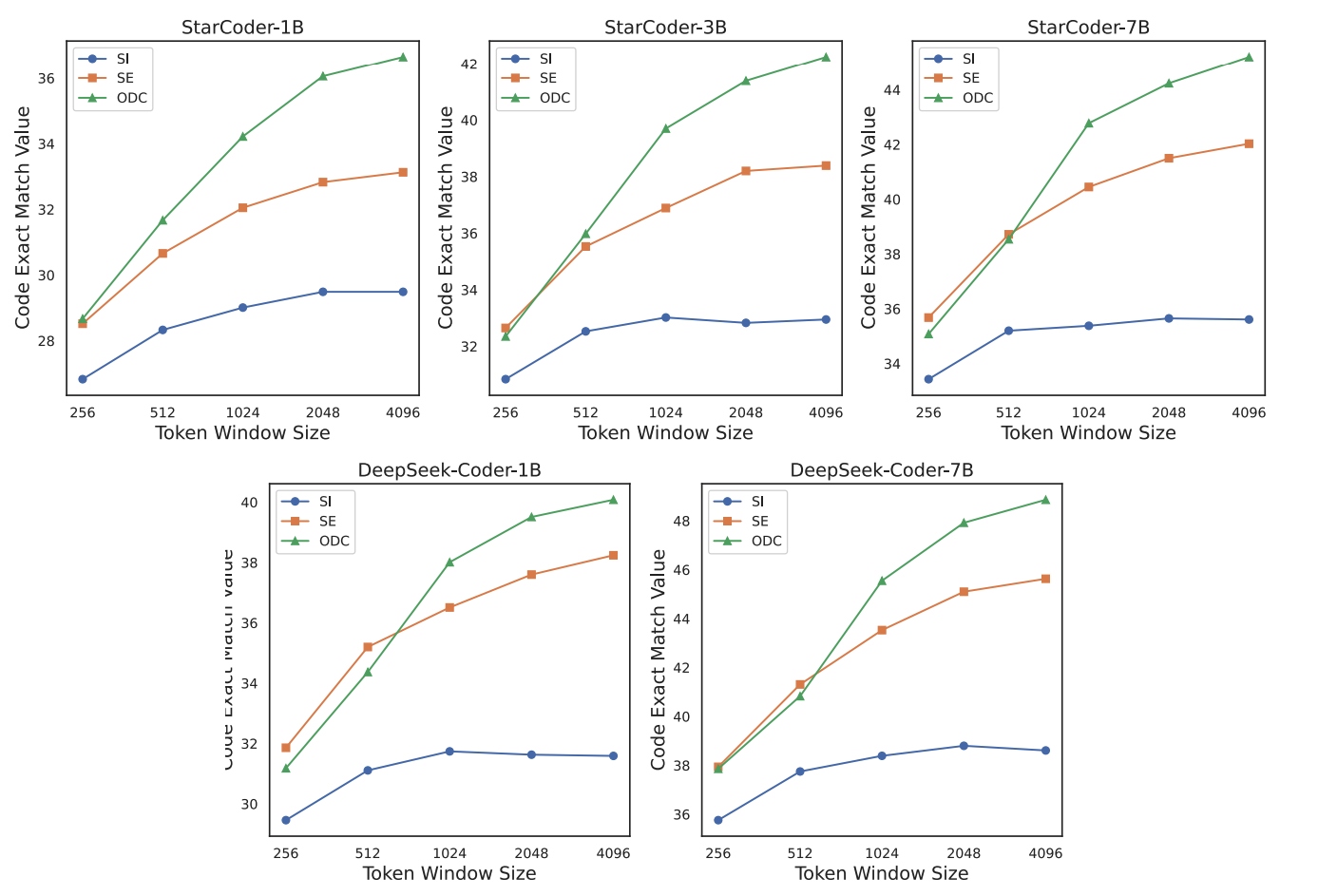
图6:不同Context设置在多个模型上的性能比较
推理效率
RCS带来的推理性能提升:尽管在使用ODC + 4096 Context长度的配置能达到最好的效果,但它会显著降低推理速度。为了更好地适应需要快速响应的环境,我们使用StarCoder-1B模型上评估了使用不同Context设置在推理效率和性能上的表现。如图7所示,ODC(ODC_1024)不仅在EM性能上保持优于SI和SE,还提高了推理速度并降低了延迟。雷达图表明,RepoFuse(ODC_1024)相比SE实现了13.89%的吞吐量增加,并将延迟降低了33.3%。由于在CrossCodeEval Python数据集上检索到的SI上下文数量有限,SI的实际令牌长度与ODC_1024的长度相近,因此它们的吞吐量和延迟性能接近,而ODC_1024比SI提高了15.9%的EM。因此,ODC_1024这种配置证明RepoFuse有效地平衡了高准确率和优化的推理速度。
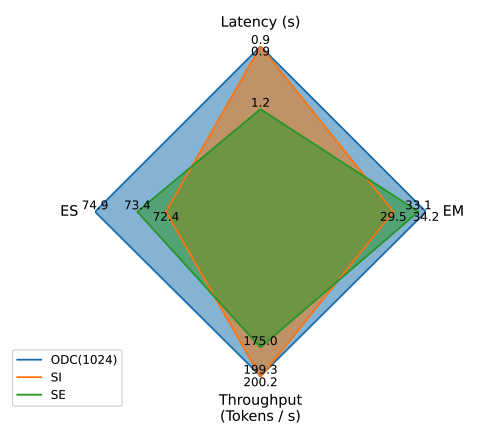
图7:不同Context设置在StarCoder-1B上的推理效率与性能
不同相关度函数的比较
本节我们评估在使用Semantic & Similar两类上下文信息时(Dual Context),RCS策略中不同相关度函数的效果,具体如图8所示。从图中可以看到,在上下文长度较小(256、512)时,Oracle效果明显优于其他相关函数。随着上下文长度增长,各策略间没有显著的性能差异。这证明了在有限的Token长度 L 下,相关性分数函数对补全效果的重要性。在Oracle之外的策略中,基于UniXcoder的相似度分数表现最佳,而随机策略的效果最差,这与RepoBench的见解相印证。Jacarrd Similarity的效果略低于UniXcoder,但却有显著的计算性能优势,可以考虑应用在实际补全场景中。同样的结论在单独使用Semantic或Similar上下文时也可以观察到,由于篇幅限制此处不过多赘述。

图8:RCS不同相关度函数的效果
未来工作展望
本文介绍了一种新颖的仓库级别代码补全技术RepoFuse,通过引入两类不同视角的上下文信息辅助模型进行补全,显著提升了补全的效果。并且提出基于相关性指导的上下文选择技术,在保证效果的前提下限制Prompt长度,提升推理效率。目前,我们已经将相关技术应用到CodeFuse插件中。在未来,RepoFuse会继续在以下方向进行探索:1. 更轻量的程序分析技术,有助于提升准确性和效率;2. 更精细的上下文选择策略设计:例如更细的上下文选择粒度和更好的相关性度量分数。
此处仅列出关键参考文献,详细参考文献请查看原论文
[1]. RLPG:Repository-Level Prompt Generation for Large Language Models of Code
[2]. RepoFusion: Training Code Models to Understand Your Repository
[3]. ReACC: A Retrieval-Augmented Code Completion Framework
[4]. RepoCoder: Repository-Level Code Completion Through Iterative Retrieval and Generation
[5]. CROSSCODEEVAL: A Diverse and Multilingual Benchmark for Cross-File Code Completion
[6]. RepoBench: Benchmarking Repository-Level Code Auto-Completion Systems
[7]. COCOMIC: Code Completion By Jointly Modeling In-file and Cross-file Context
[8]. CodePlan: Repository-level Coding using LLMs and Planning
[9]. Repoformer: Selective Retrieval for Repository-Level Code Completion