【ML】multi head 自注意力机制self-attention
- 0. Transformer
- 1. multi head self-attention
- 2. positional encoding
- 3. transform 可以应用的其他领域
- 3.1 语音识别 变体 truncated self-attention
- 3.2 self-attention for image
- 3.3 self-attention v.s. CNN差异
- 3.4 self-attention v.s. RNN
- 3.5 GNN
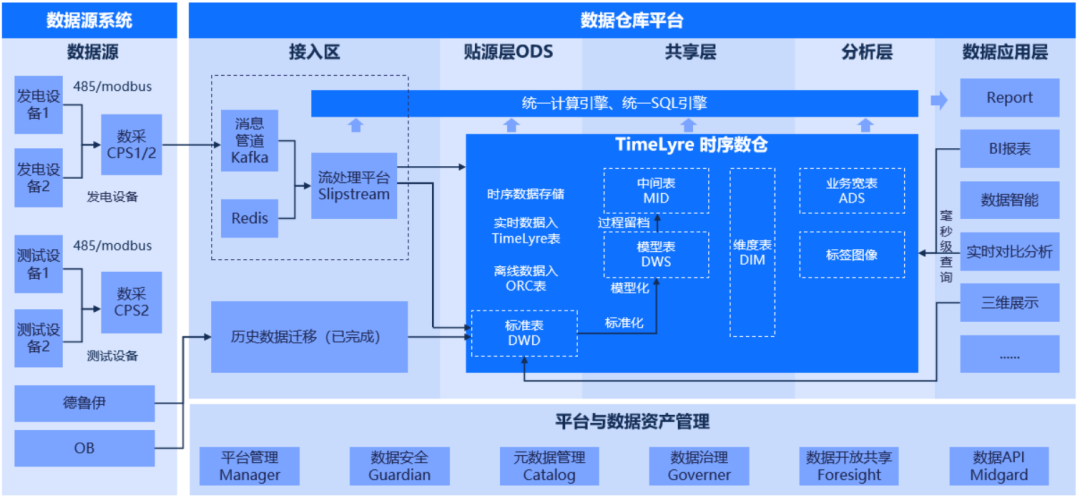
0. Transformer
自注意力机制,也称为内部注意力机制,是 Transformer 模型的核心组成部分。它允许模型在处理序列数据时,计算序列中每个元素相对于其他所有元素的注意力权重。以下是自注意力机制的计算过程和公式推导:
-
输入表示:
假设我们有一个序列,其中每个元素(例如单词或特征点)由一个 d 维向量表示。记第 i 个元素的状态向量为 ( x_i )。 -
分解为查询(Q)、键(K)、值(V):
对于序列中的每个元素,我们通过不同的线性变换将其分解为查询向量 ( q_i )、键向量 ( k_i ) 和值向量 ( v_i )。即:
[ q_i = W^Q x_i, \quad k_i = W^K x_i, \quad v_i = W^V x_i ]
其中 ( W^Q, W^K, W^V ) 是可学习的权重矩阵。 -
计算注意力得分:
对于序列中的每个元素 ( x_i ),我们计算其与序列中所有其他元素的注意力得分 ( a_{ij} ),通常使用点积操作:
[ a_{ij} = \frac{q_i^T k_j}{\sqrt{d_k}} ]
其中 ( d_k ) 是键向量的维度,除以 ( \sqrt{d_k} ) 是为了稳定梯度。 -
应用 softmax 函数:
使用 softmax 函数对注意力得分进行归一化,得到归一化的注意力权重:
[ \alpha_{ij} = \text{softmax}(a_{ij}) = \frac{\exp(a_{ij})}{\sum_{l=1}^{n} \exp(a_{il})} ]
其中 n 是序列的长度。 -
加权值向量:
使用归一化的注意力权重对值向量 ( v_j ) 进行加权求和,得到最终的输出向量 ( o_i ):
[ o_i = \sum_{j=1}^{n} \alpha_{ij} v_j ] -
多头注意力:
Transformer 模型通常使用多头注意力机制,其中每个头学习不同的表示子空间。上述过程被独立地应用到多个头(h 个),然后将结果拼接起来,并通过一个线性层进行投影,以得到最终的输出:
[ \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, …, \text{head}_h) W^O ]
其中每个头的计算为:
[ \text{head}_h = \text{Attention}(Q W_h^Q, K W_h^K, V W_h^V) ]
( W_h^Q, W_h^K, W_h^V ) 和 ( W^O ) 是可学习的权重矩阵。 -
位置编码:
由于 Transformer 模型本身不具备捕捉序列顺序的能力,通常会将位置编码添加到输入向量中,以便模型能够利用序列中元素的位置信息。
自注意力机制允许模型在序列的每个位置集中注意力于不同的部分,这使得它非常适合处理长距离依赖问题。在 LightGlue 模型中,自注意力机制被用来更新局部特征点的表示,以便于在图像匹配任务中找到更好的特征对应关系。
1. multi head self-attention
只需要把不同的
q
i
,
1
q^{i,1}
qi,1 与
q
i
,
2
q^{i,2}
qi,2
q
i
,
3
q^{i,3}
qi,3
q
i
,
4
q^{i,4}
qi,4 分别当做四个 self-attention 计算即可,具体计算步骤参考 blog:【ML】自注意力机制selfattention



2. positional encoding
不管是 self-attention 还是 multi head self-attention都是位置无关的算法(举例:根据self-attention,a1 和 a4 或者 a1 与 a2 的举例相关性是一样的,并没有将位置信息编码到 O的的输出中,不反应位置相干的信息,因此为位置无关),这里通过 positional encoding 加入位置信息

positional encoding 实现方式,上面是其中的一种实现方式,通过认为复制实现

3. transform 可以应用的其他领域
3.1 语音识别 变体 truncated self-attention



3.2 self-attention for image


3.3 self-attention v.s. CNN差异
-
数据依赖性:
- 自注意力:不依赖于数据的固定大小的局部感受野,可以捕捉序列中任意两个元素之间的关系,无论它们在序列中的位置如何。
- CNN:依赖于固定大小的卷积核来捕捉局部空间特征,适合处理具有强烈局部相关性的数据,如图像。
-
参数共享:
- 自注意力:在计算注意力权重时,参数(如查询、键、值的投影矩阵)在整个序列上共享。
- CNN:卷积核的参数在整个输入数据上共享,但在不同的卷积层上有不同的参数集。
-
时间/空间复杂度:
- 自注意力:计算复杂度与序列长度的平方成正比((O(n^2))),其中 (n) 是序列长度,因为需要计算序列中每个元素对其他所有元素的注意力。
- CNN:计算复杂度通常与卷积核的数量和大小成正比,以及输入数据的维度((O(k^2 \cdot h \cdot w))),其中 (k) 是卷积核的大小,(h) 和 (w) 是输入数据的高度和宽度。
-
并行化能力:
- 自注意力:可以很容易地并行化,因为序列中任意两个元素的注意力计算是独立的。
- CNN:虽然卷积操作可以并行化,但在处理序列数据时,可能需要考虑时间维度上的依赖性。
-
长距离依赖:
- 自注意力:能够直接捕捉长距离依赖,因为它可以计算序列中任意两点之间的关系。
- CNN:在捕捉长距离依赖方面可能受限,尤其是在没有使用额外结构(如残差连接)的情况下。
-
可解释性:
- 自注意力:通过注意力权重提供了一定程度的可解释性,可以直观地看到模型关注输入的哪些部分。
- CNN:通常较难解释,因为特征检测是通过多层卷积和非线性激活函数抽象得到的。
-
应用领域:
- 自注意力:广泛应用于自然语言处理(NLP)、序列标注、机器翻译等序列建模任务。
- CNN:在图像和视频识别、图像分割、物体检测等计算机视觉任务中非常流行。
-
变体和扩展:
- 自注意力:有多头注意力等变体,可以并行地学习输入数据的不同表示。
- CNN:有多种扩展,如残差网络(ResNet)、卷积LSTM等,用于改善性能和解决特定问题。
-
内存使用:
- 自注意力:可能需要更多的内存,特别是对于长序列,因为它需要存储完整的注意力矩阵。
- CNN:内存使用相对较低,尤其是当使用稀疏连接和深度可分离卷积等技术时。



3.4 self-attention v.s. RNN
自注意力(Self-Attention)机制和递归神经网络(RNN)是两种不同的序列处理方法,它们在处理数据时有以下主要差异:
-
时间复杂度:
- 自注意力:计算复杂度与序列长度的平方成正比,即 (O(n^2 \cdot d)),其中 (n) 是序列长度,(d) 是特征维度。这是因为自注意力机制需要计算序列中每个元素对其他所有元素的注意力得分。
- RNN:计算复杂度与序列长度线性相关,即 (O(n \cdot d))。RNN通过递归地处理序列中的每个元素,每次只处理一个元素及其在序列中之前的元素。
-
并行化能力:
- 自注意力:由于自注意力机制独立于序列中元素之间的相对位置,它可以很容易地并行化处理整个序列,这使得它在现代硬件上更高效。
- RNN:由于其递归性质,RNN 在处理序列时需要按顺序逐步进行,这限制了其并行化的能力,尤其是在长序列上。
-
长距离依赖:
- 自注意力:能够捕捉长距离依赖关系,因为它直接计算序列中任意两个元素之间的关系,不受它们之间距离的限制。
- RNN:在长序列上可能会遇到梯度消失或梯度爆炸的问题,这使得它难以捕捉长距离依赖。
-
内存使用:
- 自注意力:需要存储整个序列的注意力矩阵,这可能导致较高的内存消耗,尤其是在长序列上。
- RNN:通常只需要存储前一时刻的隐藏状态,因此内存使用相对较低。
-
模型参数:
- 自注意力:参数数量与序列长度无关,只与特征维度有关。
- RNN:参数数量同样与序列长度无关,但与隐藏层的维度有关。
-
灵活性和可解释性:
- 自注意力:通过注意力权重提供了一定程度的可解释性,可以直观地看到模型关注序列中哪些部分。
- RNN:其内部状态更新机制通常较难解释。
-
变体和扩展:
- 自注意力:有多种变体,如多头注意力(Multi-Head Attention),可以并行地学习序列的不同表示。
- RNN:有多种扩展,如长短期记忆网络(LSTM)和门控循环单元(GRU),这些模型通过引入门控机制来解决梯度消失问题。
-
应用领域:
- 自注意力:广泛应用于自然语言处理(NLP)、图像处理和其他序列建模任务,特别是在 Transformer 模型中。
- RNN:在序列到序列(Seq2Seq)模型、语言模型和时间序列预测等领域有广泛应用。


3.5 GNN