从零入门CV图像竞赛(2024全球Deepfake攻防挑战赛)
Deepfake是什么?
Deepfake是一种利用深度学习技术,特别是生成对抗网络(GANs)来实现视频、音频等多媒体内容的伪造技术。这项技术可以实现对视频中人物的面部、表情、口型甚至身体动作的精确替换和模仿,让一个人在视频中看起来像另一个人,或者做出他们实际上并未做出的动作和表情。
Deepfake的制作流程大致如下:
- 数据收集:收集大量的目标人物图片和视频资料,用于训练模型。
- 模型训练:使用生成对抗网络(GAN)进行训练。GAN包含两部分,生成器(Generator)和判别器(Discriminator)。生成器的任务是生成逼真的假视频或图片,而判别器的任务是区分生成的假视频或图片和真实的视频或图片。
- 迭代优化:通过不断迭代,生成器生成的假视频或图片越来越难以被判别器识别,最终达到以假乱真的效果。
Deepfake技术具有以下特点:
- 高仿真性:经过精心制作的Deepfake内容可以达到非常高的真实度,对于普通观众来说,很难分辨其真伪。
- 多样性:不仅可以应用于视频,也可以应用于音频、图片等多种媒介。
Deepfake技术带来的潜在问题: - 伦理道德问题:Deepfake可能被用于制作虚假信息、色情内容、侵犯他人隐私等,对个人名誉和社会秩序造成负面影响。
- 安全问题:在政治、经济、社会等领域,Deepfake可能被用作虚假信息传播的工具,误导公众,影响选举和决策过程。
针对Deepfake技术的潜在风险,各国政府、技术社区和社会组织正在努力制定相应的法律法规和对策,以防止其滥用。同时,也在开发检测和识别Deepfake内容的技术,以保护信息的真实性和社会的稳定。
如何区分Deepfake?
区分Deepfake内容与真实内容是一个挑战性的任务,但随着技术的发展,已经有一些方法可以用来检测Deepfake。以下是一些常见的检测Deepfake的方法:
- 视觉不一致性检查:
- 光线和阴影:检查视频中的光线和阴影是否自然,Deepfake内容可能在光线变化和阴影上存在不一致。
- 面部特征:观察面部特征是否在不同角度和表情下保持一致,Deepfake可能在某些角度下出现面部扭曲或异常。
- 眨眼和眼球运动:人类在说话时会自然眨眼和移动眼球,Deepfake可能无法准确模拟这些细节。
- 图像质量分析:
- 分辨率不一致:Deepfake视频可能在某些部分分辨率较低,尤其是当面部被合成到不同背景上时。
- 模糊和锐化:检查图像中是否有不自然的模糊或过度锐化的区域。
- 生物特征检测:
- 心跳和呼吸:通过分析视频中的心跳和呼吸模式,可以检测出与人类生理特征不符的情况。
- 面部微表情:人类的面部微表情很难被Deepfake技术完美复制,检测微表情的不自然可能揭示Deepfake。
- 一致性检查:
- 口型和声音:检查视频中人物的口型是否与声音匹配,Deepfake可能在这方面存在不一致。
- 身体动作:分析身体动作是否协调,Deepfake可能在模拟复杂的身体动作时出现不自然的情况。
- 深度学习检测工具:
- 专门的深度学习模型:已经有一些深度学习模型被训练来专门检测Deepfake内容,这些模型可以识别视频中的异常模式。
- 元数据分析:
- 视频元数据:检查视频文件的元数据,如创建日期、编辑历史等,以查找可能的篡改痕迹。
- 第三方验证:
- 专业机构:对于重要的视频内容,可以提交给专业的检测机构进行验证
需要注意的是,随着Deepfake技术的不断进步,检测Deepfake的难度也在增加。因此,上述方法可能需要结合使用,并且需要不断更新检测工具和技术以应对新的挑战。此外,公众也应提高对Deepfake内容的警觉性,对来源不明的视频内容保持怀疑态度。
基于深度学习的Deepfake检测
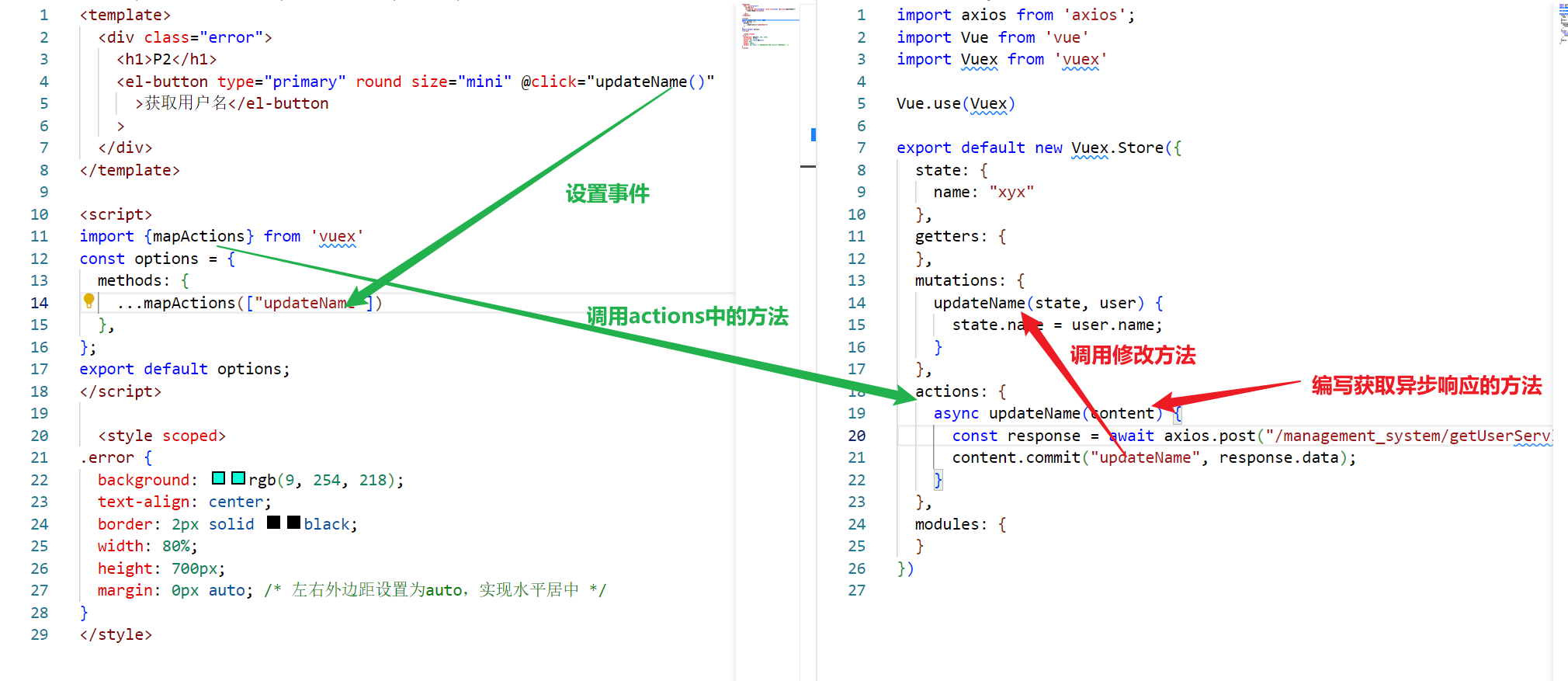
代码流程
- 模型定义:使用
timm库创建一个预训练的resnet18模型。 - 训练/验证数据加载:使用
torch.utils.data.DataLoader来加载训练集和验证集数据,并通过定义的transforms进行数据增强。 - 训练与验证过程:
- 定义了
train函数来执行模型在一个epoch上的训练过程,包括前向传播、损失计算、反向传播和参数更新。 - 定义了
validate函数来评估模型在验证集上的性能,计算准确率。
- 定义了
- 性能评估:使用准确率(Accuracy)作为性能评估的主要指标,并在每个epoch后输出验证集上的准确率。
- 提交:最后,将预测结果保存到CSV文件中,准备提交到Kaggle比赛。
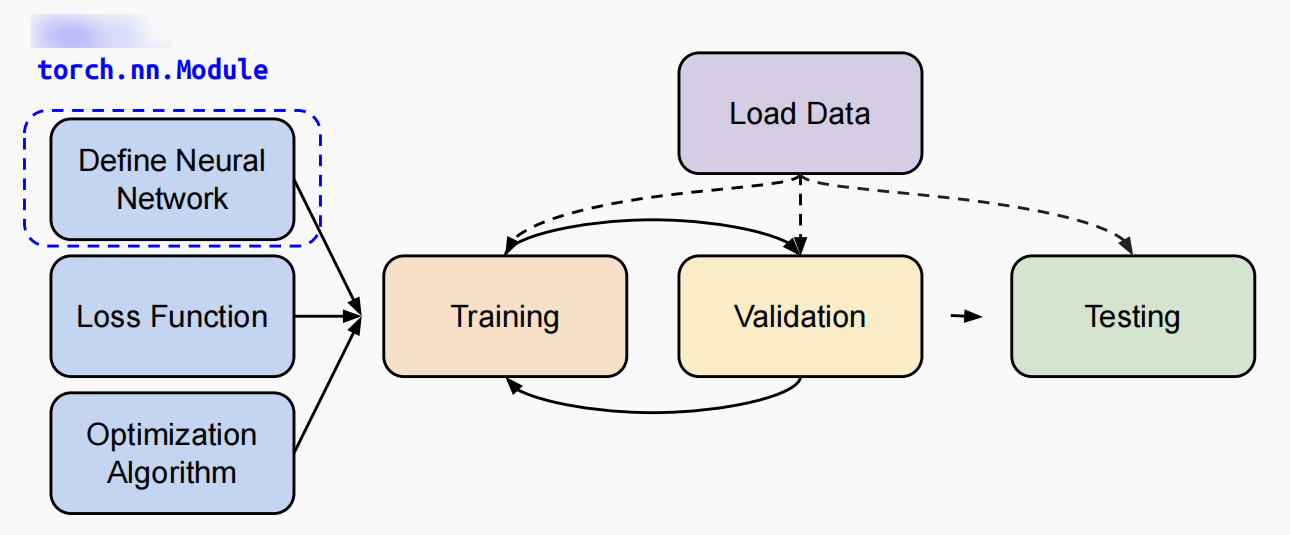
模型网络定义-加载预训练模型
预训练模型是指在特定的大型数据集(如ImageNet)上预先训练好的神经网络模型。这些模型已经学习到了丰富的特征表示,能够识别和处理图像中的多种模式。使用预训练模型的好处是,它们可以在新数据集或新任务上进行微调(Fine-tuning),从而加快训练过程并提高模型性能,尤其是当可用的数据量有限时。
在下面代码中,timm.create_model('resnet18', pretrained=True, num_classes=2)这行代码就是加载了一个预训练的ResNet-18模型,其中pretrained=True表示使用在ImageNet数据集上预训练的权重,num_classes=2表示模型的输出层被修改为有2个类别的输出,以适应二分类任务(例如区分真实和Deepfake图像)。通过model = model.cuda()将模型移动到GPU上进行加速。
import timm
model = timm.create_model('resnet18', pretrained=True, num_classes=2)
model = model.cuda()
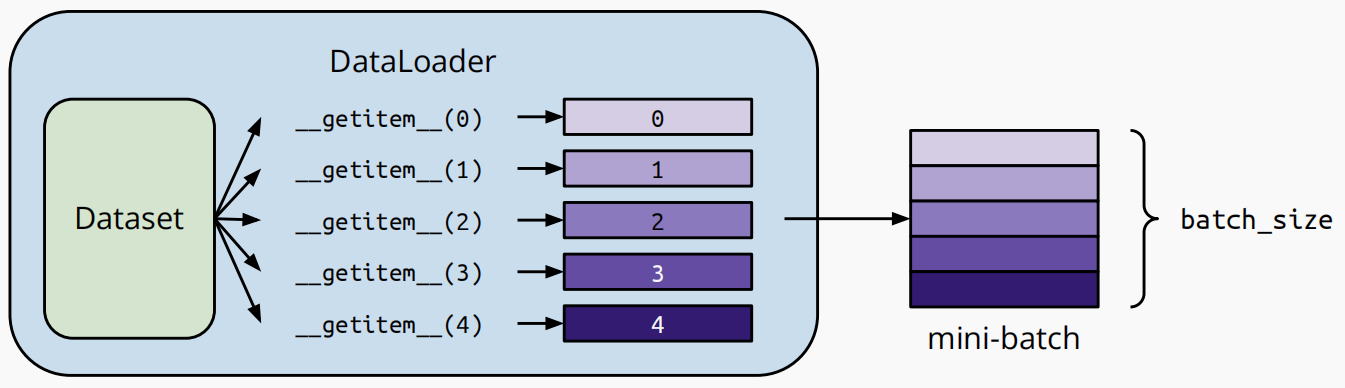
训练/验证集数据加载
-
自定义
FFDIDataset类,继承Pytorch的Dataset类。__init__:读取数据集并处理__getitem__:每次返回一个样本__len__:返回数据集大小 -
使用
DataLoader将数据分组。如果设置shuffle=True,Dataloader会自动排列所有样本的索引。我们在训练时经常设置shuffle=True。 -
数据增强操作
数据增强是一种在机器学习和深度学习中提升模型性能的重要技术。它通过应用一系列随机变换来增加训练数据的多样性,从而提高模型的泛化能力。增加数据多样性是数据增强的核心目的。通过对原始图像进行如旋转、缩放、翻转等操作,可以生成新的训练样本,使模型学习到更丰富的特征表示。
transforms.Compose: 这是一个转换操作的组合,它将多个图像预处理步骤串联起来:transforms.Resize((256, 256)):将所有图像调整为256x256像素的大小。transforms.RandomHorizontalFlip():随机水平翻转图像。transforms.RandomVerticalFlip():随机垂直翻转图像。transforms.ToTensor():将PIL图像或Numpy数组转换为torch.FloatTensor类型,并除以255以将像素值范围从[0, 255]缩放到[0, 1]。transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]):对图像进行标准化,使用ImageNet数据集的均值和标准差。
from torch.utils.data import Dataset, DataLoader
class FFDIDataset(Dataset):
def __init__(self, img_path, img_label, transform=None):
self.img_path = img_path
self.img_label = img_label
if transform is not None:
self.transform = transform
else:
self.transform = None
def __getitem__(self, index):
img = Image.open(self.img_path[index]).convert('RGB')
if self.transform is not None:
img = self.transform(img)
return img, torch.from_numpy(np.array(self.img_label[index]))
def __len__(self):
return len(self.img_path)
train_loader = torch.utils.data.DataLoader(
FFDIDataset(train_label['path'], train_label['target'],
transforms.Compose([
transforms.Resize((256, 256)),
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.RandomVerticalFlip(), # 随机垂直翻转
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
), batch_size=bs_value, shuffle=True, num_workers=4, pin_memory=True, collate_fn=collate_fn, drop_last=False
)
val_loader = torch.utils.data.DataLoader(
FFDIDataset(val_label['path'], val_label['target'],
transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
), batch_size=bs_value, shuffle=False, num_workers=4, pin_memory=True
)
训练与验证过程
在深度学习中,模型训练通常需要进行多次迭代,而不是单次完成。深度学习模型的训练本质上是一个优化问题,目标是最小化损失函数。梯度下降算法通过计算损失函数相对于模型参数的梯度来更新参数。由于每次参数更新只能基于一个数据批次来计算梯度,因此需要多次迭代,每次处理一个新的数据批次,以确保模型在整个数据集上都能得到优化。
模型训练的流程如下:
- 设置训练模式:通过调用
model.train()将模型设置为训练模式。在训练模式下,模型的某些层(如BatchNorm和Dropout)会按照它们在训练期间应有的方式运行。 - 遍历数据加载器:使用
enumerate(train_loader)遍历train_loader提供的数据批次。input是批次中的图像数据,target是对应的标签。 - 数据移动到GPU:通过
.cuda(non_blocking=True)将数据和标签移动到GPU上。non_blocking参数设置为True意味着如果数据正在被复制到GPU,此操作会立即返回,不会等待数据传输完成。 - 前向传播:通过
output = model(input)进行前向传播,计算模型对输入数据的预测。 - 计算损失:使用损失函数
loss = criterion(output, target)计算预测输出和目标标签之间的差异。 - 梯度归零:在每次迭代开始前,通过
optimizer.zero_grad()清空(重置)之前的梯度,以防止梯度累积。 - 反向传播:调用
loss.backward()计算损失相对于模型参数的梯度。 - 参数更新:通过
optimizer.step()根据计算得到的梯度更新模型的参数。
def train(train_loader, model, criterion, optimizer, epoch):
batch_time = AverageMeter('Time', ':6.3f')
losses = AverageMeter('Loss', ':.4e')
top1 = AverageMeter('Acc@1', ':6.2f')
progress = ProgressMeter(len(train_loader), batch_time, losses, top1)
# switch to train mode
model.train()
end = time.time()
for i, (input, target) in enumerate(train_loader):
input = input.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
# compute output
output = model(input)
loss = criterion(output, target)
# measure accuracy and record loss
losses.update(loss.item(), input.size(0))
# print(f"{output.shape = },{target.shape = }")
# output.shape = torch.Size([32, 2]),target.shape = torch.Size([32])
acc = (output.argmax(1).view(-1) == target.float().view(-1)).float().mean() * 100
top1.update(acc, input.size(0))
# compute gradient and do SGD step
optimizer.zero_grad()
loss.backward()
optimizer.step()
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
if i % 100 == 0:
progress.pr2int(i)
def validate(val_loader, model, criterion):
batch_time = AverageMeter('Time', ':6.3f')
losses = AverageMeter('Loss', ':.4e')
top1 = AverageMeter('Acc@1', ':6.2f')
progress = ProgressMeter(len(val_loader), batch_time, losses, top1)
# switch to evaluate mode
model.eval()
with torch.no_grad():
end = time.time()
for i, (input, target) in tqdm_notebook(enumerate(val_loader), total=len(val_loader)):
input = input.cuda()
target = target.cuda()
# compute output
output = model(input)
loss = criterion(output, target)
# measure accuracy and record loss
acc = (output.argmax(1).view(-1) == target.float().view(-1)).float().mean() * 100
losses.update(loss.item(), input.size(0))
top1.update(acc, input.size(0))
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
# TODO: this should also be done with the ProgressMeter
print(' * Acc@1 {top1.avg:.3f}'
.format(top1=top1))
return top1
性能评估
使用准确率(Accuracy)作为性能评估的主要指标,并在每个epoch后输出验证集上的准确率。
# 定义损失函数
criterion = nn.CrossEntropyLoss().cuda()
# 定义优化算法
optimizer = torch.optim.Adam(model.parameters(), 0.005)
# 定义学习率
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=4, gamma=0.85)
best_acc = 0.0
for epoch in range(epoch_num):
scheduler.step()
print('Epoch: ', epoch)
train_mix(train_loader, model, criterion, optimizer, epoch)
val_acc = validate(val_loader, model, criterion)
if val_acc.avg.item() > best_acc:
best_acc = round(val_acc.avg.item(), 2)
torch.save(model.state_dict(), f'./model_{best_acc}.pt')
测试集上预测并提交结果
定义predict函数,使用训练好的模型预测结果,将预测结果保存到CSV文件中,准备提交到Kaggle比赛。
def predict(test_loader, model, tta=10):
# switch to evaluate mode
model.eval()
test_pred_tta = None
for _ in range(tta):
test_pred = []
with torch.no_grad():
end = time.time()
for i, (input, target) in tqdm_notebook(enumerate(test_loader), total=len(test_loader)):
input = input.cuda()
target = target.cuda()
# compute output
output = model(input)
output = F.softmax(output, dim=1)
output = output.data.cpu().numpy()
test_pred.append(output)
test_pred = np.vstack(test_pred)
if test_pred_tta is None:
test_pred_tta = test_pred
else:
test_pred_tta += test_pred
return test_pred_tta
test_loader = torch.utils.data.DataLoader(
FFDIDataset(val_label['path'], val_label['target'],
transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
), batch_size=bs_value, shuffle=False, num_workers=4, pin_memory=True
)
val_label['y_pred'] = predict(test_loader, model, 1)[:, 1]
val_label[['img_name', 'y_pred']].to_csv('submit.csv', index=None)
改进方向

更多数据集增强
- 几何变换
- 调整大小:
Resize可以将图像调整到指定的大小。 - 随机裁剪:
RandomCrop和RandomResizedCrop可以随机裁剪图像。 - 中心裁剪:
CenterCrop从图像的中心裁剪出指定大小。 - 五裁剪和十裁剪:
FiveCrop和TenCrop分别裁剪出图像的四个角和中心区域。 - 翻转:
RandomHorizontalFlip和RandomVerticalFlip可以水平或垂直翻转图像。 - 旋转:
RandomRotation可以随机旋转图像。 - 仿射变换:
RandomAffine可以进行随机的仿射变换。 - 透视变换:
RandomPerspective可以进行随机的透视变换。
-
颜色变换
- 颜色抖动:
ColorJitter可以随机改变图像的亮度、对比度、饱和度和色调。 - 灰度化:
Grayscale和RandomGrayscale可以将图像转换为灰度图。 - 高斯模糊:
GaussianBlur可以对图像进行高斯模糊。 - 颜色反转:
RandomInvert可以随机反转图像的颜色。 - 颜色 posterize:
RandomPosterize可以减少图像中每个颜色通道的位数。 - 颜色 solarize:
RandomSolarize可以反转图像中所有高于阈值的像素值。
- 颜色抖动:
-
自动增强
- 自动增强:
AutoAugment可以根据数据集自动学习数据增强策略。 - 随机增强:
RandAugment可以随机应用一系列数据增强操作。 TrivialAugmentWide:提供与数据集无关的数据增强。AugMix:通过混合多个增强操作进行数据增强。
transforms.Compose([ ####几何变换#### transforms.Resize((256, 256)), transforms.RandomPerspective(distortion_scale=0.6, p=1.0), # 随机透视转换 transforms.RandomRotation(degrees=(0, 180)), # 随机旋转 transforms.RandomAffine(degrees=(30, 70), translate=(0.1, 0.3), scale=(0.5, 0.75)), # 随机仿射 transforms.RandomHorizontalFlip(), # 随机水平翻转 transforms.RandomVerticalFlip(), # 随机垂直翻转 ####颜色变换 transforms.RandomInvert(), # 随机反转颜色 transforms.GaussianBlur(kernel_size=(5, 9), sigma=(0.1, 5.)), # 高斯模糊变换 transforms.ColorJitter(brightness=.5, hue=.3), # 颜色抖动 transforms.RandomPosterize(bits=2), # 减少图像中每个颜色通道的位数 transforms.RandomSolarize(threshold=192.0), # 反转图像中所有高于阈值的像素值 transforms.RandomAdjustSharpness(sharpness_factor=2), # 随机锐度 transforms.RandomEqualize(), # 随机均衡 transforms.RandomAutocontrast(), # 随机自动对比 ####自动增强#### transforms.AugMix(), # 混合多个增强操作进行数据增强 transforms.AutoAugment(transforms.AutoAugmentPolicy.IMAGENET), # 根据给定的自动增强策略自动增强数据 transforms.RandAugment(), # 随机策略增强 transforms.TrivialAugmentWide() # AutoAugment 的替代实现 transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]) - 自动增强:
-
Mixup
MixUp是一种数据增强技术,其原理是通过将两个不同的图像及其标签按照一定的比例混合,从而创建一个新的训练样本。这种方法可以增加训练数据的多样性,提高模型的泛化能力,并减少过拟合的风险。MixUp方法中混合比例是一个超参数,通常称为
alpha。alpha是一个在0到1之间的值,表示混合的比例。例如,alpha=0.5意味着两个图像各占新图像的一半。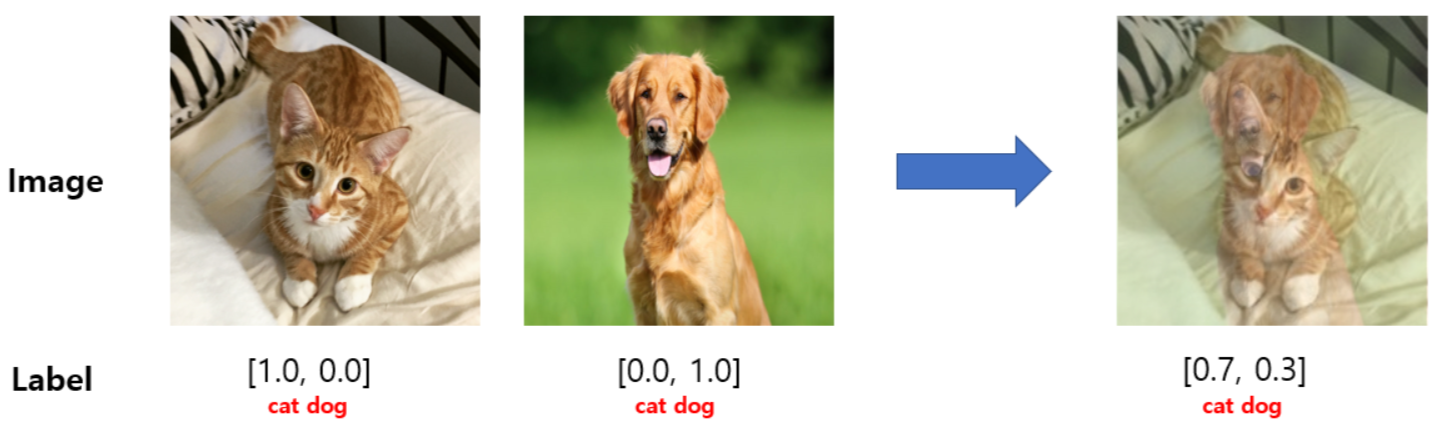
MixUp的混合过程包括以下步骤:
- 从训练集中随机选择两个图像和它们的标签。
- 将这两个图像按照
alpha的比例混合,得到一个新的图像。 - 将这两个标签按照相同的
alpha比例混合,得到一个新的标签。
MixUp方法具有以下几个优点:
- 增加数据多样性:通过混合不同的图像和标签,MixUp可以创建更多样化的训练样本,帮助模型学习到更加鲁棒的特征表示。
- 减少过拟合:MixUp可以减少模型对特定训练样本的依赖,从而降低过拟合的风险。
- 提高泛化能力:MixUp可以帮助模型学习到更加泛化的特征表示,从而提高模型在未见过的数据上的表现。
-
Cutmix
CutMix是一种数据增强技术,它通过将一个图像的一部分剪切并粘贴到另一个图像上来创建新的训练样本。同时,它也会根据剪切区域的大小来调整两个图像的标签。
CutMix方法中,剪切和粘贴操作是关键步骤。
具体来说,剪切和粘贴过程包括以下步骤:
- 从训练集中随机选择两个图像和它们的标签。
- 随机选择一个剪切区域的大小和位置。
- 将第一个图像的剪切区域粘贴到第二个图像上,得到一个新的图像。
- 根据剪切区域的大小,计算两个图像的标签的加权平均值,得到一个新的标签。
Mixup和Cutmix具体代码(参考文档:如何使用 CutMix 和 MixUp — Torchvision 0.18 文档 - PyTorch 中文)
from torchvision.transforms import v2 from torch.utils.data import default_collate NUM_CLASSES = 2 cutmix = v2.CutMix(num_classes=NUM_CLASSES) mixup = v2.MixUp(num_classes=NUM_CLASSES) cutmix_or_mixup = v2.RandomChoice([cutmix, mixup]) def collate_fn(batch): return cutmix_or_mixup(*default_collate(batch)) # 需重新定义train方法 def train_mix(train_loader, model, criterion, optimizer, epoch): batch_time = AverageMeter('Time', ':6.3f') losses = AverageMeter('Loss', ':.4e') top1 = AverageMeter('Acc@1', ':6.2f') progress = ProgressMeter(len(train_loader), batch_time, losses, top1) # switch to train mode model.train() end = time.time() for i, (input, target) in enumerate(train_loader): input = input.cuda(non_blocking=True) target = target.cuda(non_blocking=True) # compute output output = model(input) loss = criterion(output, target) # measure accuracy and record loss losses.update(loss.item(), input.size(0)) # print(f"{output.shape = },{target.shape = }") # output.shape = torch.Size([32, 2]),target.shape = torch.Size([32, 2]) # 与不带cutmix、mixup的代码差别,cutmix、mixup操作会增加target的维度,需要选取指定维度 acc = (output.argmax(1).view(-1) == target.argmax(dim=1).float().view(-1)).float().mean() * 100 top1.update(acc, input.size(0)) # compute gradient and do SGD step optimizer.zero_grad() loss.backward() optimizer.step() # measure elapsed time batch_time.update(time.time() - end) end = time.time() if i % 100 == 0: progress.pr2int(i) #######################添加cutmix&mixup############################################ train_loader = torch.utils.data.DataLoader( FFDIDataset(train_label['path'], train_label['target'], transforms.Compose([ ####几何变换#### transforms.Resize((256, 256)), ####颜色变换 transforms.ColorJitter(brightness=.5, hue=.3), # 颜色抖动 transforms.RandomEqualize(), # 随机均衡 transforms.RandomAutocontrast(), # 随机自动对比 ####自动增强#### transforms.AugMix(), # 混合多个增强操作进行数据增强 transforms.AutoAugment(transforms.AutoAugmentPolicy.IMAGENET), # 根据给定的增强策略自动增强数据 transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]) ), batch_size=bs_value, shuffle=True, num_workers=4, pin_memory=True, collate_fn=collate_fn, drop_last=False ) # 添加collate_fn参数。 它允许您定义一个自定义的函数,该函数用于处理和组合来自不同数据源的样本,以便它们可以被有效地批量处理。 # 验证集数据加载不需要变化 val_loader = torch.utils.data.DataLoader( FFDIDataset(val_label['path'], val_label['target'], transforms.Compose([ transforms.Resize((256, 256)), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]) ), batch_size=bs_value, shuffle=False, num_workers=4, pin_memory=True )
cutmix、mixup数据增强的得分正在跑,后续会更新
更换模型
使用比resnet18更大的预训练模型(⚠️只允许使用 ImageNet1K 的预训练模型)
不同模型得分表
| model | epoch | score |
|---|---|---|
| efficientnet_b0 | 10 | 0.9921364049 |
| efficientnet_b4 | 5 | 0.9874735502 |
| mobilenetv3_large_100.miil_in21k_ft_in1k | 5 | 0.9492682898 |
其他
探究验证集和训练集产生逻辑&缩放数据集:暂时没有想到如何的实现,感兴趣的可以在评论区讨论,大家一起学习。
致谢
感谢Datawhaler开源学习组织提供的组队学习平台和经验分享会,感谢九月大佬的代码分享。欢迎大家来组队一起学习。
完整代码地址:Deepfake-FFDI-how to imporve socres | Kaggle
Datawhaler学习手册:从零入门CV图像竞赛(Deepfake攻防) - 飞书云文档 (feishu.cn)
九月大佬的代码:[九月0.98766]Deepfake-FFDI-Way to Get Top Scores | Kaggle