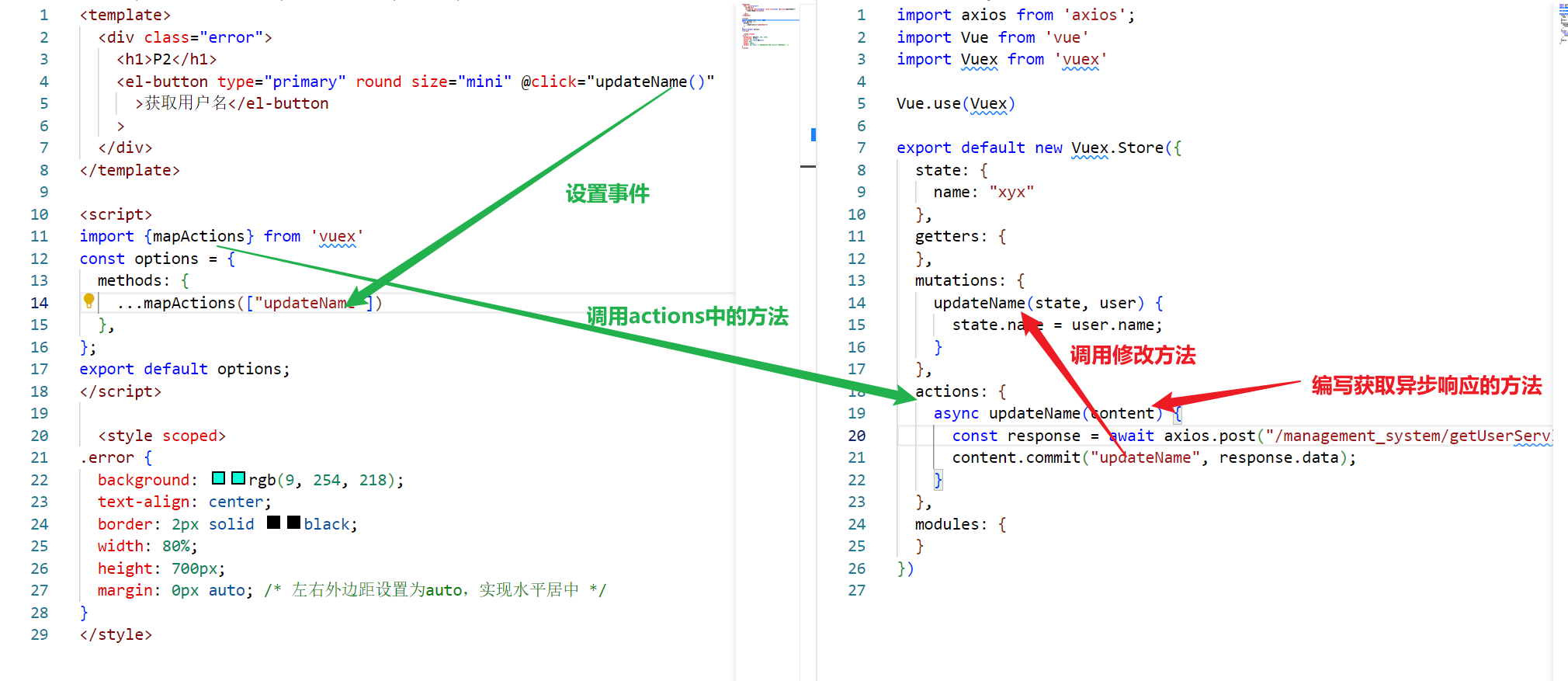
序言
本文以 LLaMA-Factory 为例,在超算互联网平台SCNet上使用异构加速卡AI 显存64GB PCIE,私有化部署Llama3模型,并对 Llama3-8B-Instruct 模型进行 LoRA 微调、推理和合并。
快速体验基础版本,请参考另一篇博客:快速体验LLaMA3模型微调(曙光超算互联网平台国产异构加速卡DCU)
一、参考资料
github仓库代码:LLaMA-Factory,使用最新的代码分支:v0.8.3
超算互联网平台
异构加速卡AI 显存64GB PCIE
Llama3本地部署与高效微调入门
快速体验LLaMA3模型微调(曙光超算互联网平台国产异构加速卡DCU)
二、准备环境
1. 系统镜像
异构加速卡AI为国产加速卡,基于DTK软件栈(对标NVIDIA的CUDA),请选择 dtk24.04 版本的镜像环境。
以jupyterlab-pytorch:2.1.0-ubuntu20.04-dtk24.04-py310 镜像为例。
2. 软硬件依赖
特别注意:要求最低版本 transformers 4.41.2,vllm 0.4.3 。
| 必需项 | 至少 | 推荐 |
|---|---|---|
| python | 3.8 | 3.11 |
| torch | 1.13.1 | 2.3.0 |
| transformers | 4.41.2 | 4.41.2 |
| datasets | 2.16.0 | 2.19.2 |
| accelerate | 0.30.1 | 0.30.1 |
| peft | 0.11.1 | 0.11.1 |
| trl | 0.8.6 | 0.9.4 |
| 可选项 | 至少 | 推荐 |
|---|---|---|
| CUDA | 11.6 | 12.2 |
| deepspeed | 0.10.0 | 0.14.0 |
| bitsandbytes | 0.39.0 | 0.43.1 |
| vllm | 0.4.3 | 0.4.3 |
| flash-attn | 2.3.0 | 2.5.9 |
3. 克隆base环境
root@notebook-1813389960667746306-scnlbe5oi5-20553:/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory# conda create -n llama_factory_torch --clone base
Retrieving notices: ...working... done
Source: /opt/conda
Destination: /opt/conda/envs/llama_factory_torch
The following packages cannot be cloned out of the root environment:
- https://repo.anaconda.com/pkgs/main/linux-64::conda-23.7.4-py310h06a4308_0
Packages: 44
Files: 53489
Downloading and Extracting Packages
Downloading and Extracting Packages
Preparing transaction: done
Verifying transaction: done
Executing transaction: done
#
# To activate this environment, use
#
# $ conda activate llama_factory_torch
#
# To deactivate an active environment, use
#
# $ conda deactivate
4. 安装 LLaMA Factory
root@notebook-1813389960667746306-scnlbe5oi5-20553:/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory# source activate llama_factory_torch
(llama_factory_torch) root@notebook-1813389960667746306-scnlbe5oi5-20553:/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory# pip install -e ".[torch,metrics]"
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Obtaining file:///public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory
Installing build dependencies ... done
Checking if build backend supports build_editable ... done
Getting requirements to build editable ... done
Preparing editable metadata (pyproject.toml) ... done
...
Checking if build backend supports build_editable ... done
Building wheels for collected packages: llamafactory, jieba
Building editable for llamafactory (pyproject.toml) ... done
Created wheel for llamafactory: filename=llamafactory-0.8.4.dev0-0.editable-py3-none-any.whl size=20781 sha256=85d430f487d58b0358c4332a21e07f316114d6c9997c8b6e1d88d3831a826b54
Stored in directory: /tmp/pip-ephem-wheel-cache-gmhnwt2w/wheels/e9/b4/89/f13e921e37904ee0c839434aad2d7b2951c2c68e596667c7ef
Building wheel for jieba (setup.py) ... done
Created wheel for jieba: filename=jieba-0.42.1-py3-none-any.whl size=19314459 sha256=49056fbfc2f07fc007494b9193edaa4c8f47119f1790b6ef8b769b7c994b7bf4
Stored in directory: /root/.cache/pip/wheels/b2/9b/80/7537177f75993c29af08e0d00c753724c7f06c646352be50a3
Successfully built llamafactory jieba
DEPRECATION: lmdeploy 0.1.0-git782048c.abi0.dtk2404.torch2.1. has a non-standard version number. pip 24.1 will enforce this behaviour change. A possible replacement is to upgrade to a newer version of lmdeploy or contact the author to suggest that they release a version with a conforming version number. Discussion can be found at https://github.com/pypa/pip/issues/12063
DEPRECATION: mmcv 2.0.1-gitc0ccf15.abi0.dtk2404.torch2.1. has a non-standard version number. pip 24.1 will enforce this behaviour change. A possible replacement is to upgrade to a newer version of mmcv or contact the author to suggest that they release a version with a conforming version number. Discussion can be found at https://github.com/pypa/pip/issues/12063
Installing collected packages: pydub, jieba, urllib3, tomlkit, shtab, semantic-version, scipy, ruff, rouge-chinese, joblib, importlib-resources, ffmpy, docstring-parser, aiofiles, nltk, tyro, sse-starlette, tokenizers, gradio-client, transformers, trl, peft, gradio, llamafactory
Attempting uninstall: urllib3
Found existing installation: urllib3 1.26.13
Uninstalling urllib3-1.26.13:
Successfully uninstalled urllib3-1.26.13
Attempting uninstall: tokenizers
Found existing installation: tokenizers 0.15.0
Uninstalling tokenizers-0.15.0:
Successfully uninstalled tokenizers-0.15.0
Attempting uninstall: transformers
Found existing installation: transformers 4.38.0
Uninstalling transformers-4.38.0:
Successfully uninstalled transformers-4.38.0
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
lmdeploy 0.1.0-git782048c.abi0.dtk2404.torch2.1. requires transformers==4.33.2, but you have transformers 4.43.3 which is incompatible.
Successfully installed aiofiles-23.2.1 docstring-parser-0.16 ffmpy-0.4.0 gradio-4.40.0 gradio-client-1.2.0 importlib-resources-6.4.0 jieba-0.42.1 joblib-1.4.2 llamafactory-0.8.4.dev0 nltk-3.8.1 peft-0.12.0 pydub-0.25.1 rouge-chinese-1.0.3 ruff-0.5.5 scipy-1.14.0 semantic-version-2.10.0 shtab-1.7.1 sse-starlette-2.1.3 tokenizers-0.19.1 tomlkit-0.12.0 transformers-4.43.3 trl-0.9.6 tyro-0.8.5 urllib3-2.2.2
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
[notice] A new release of pip is available: 24.0 -> 24.2
[notice] To update, run: pip install --upgrade pip
5. 解决依赖包冲突
(llama_factory_torch) root@notebook-1813389960667746306-scnlbe5oi5-20553:/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory# pip install --no-deps -e .
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Obtaining file:///public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory
Installing build dependencies ... done
Checking if build backend supports build_editable ... done
Getting requirements to build editable ... done
Preparing editable metadata (pyproject.toml) ... done
Building wheels for collected packages: llamafactory
Building editable for llamafactory (pyproject.toml) ... done
Created wheel for llamafactory: filename=llamafactory-0.8.4.dev0-0.editable-py3-none-any.whl size=20781 sha256=3a2c017ba41af3a1cd3f2482bbc71cae820fe1d2708a0b642899c64a8a3b3461
Stored in directory: /tmp/pip-ephem-wheel-cache-_abegaoi/wheels/e9/b4/89/f13e921e37904ee0c839434aad2d7b2951c2c68e596667c7ef
Successfully built llamafactory
Installing collected packages: llamafactory
Attempting uninstall: llamafactory
Found existing installation: llamafactory 0.8.4.dev0
Uninstalling llamafactory-0.8.4.dev0:
Successfully uninstalled llamafactory-0.8.4.dev0
Successfully installed llamafactory-0.8.4.dev0
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
[notice] A new release of pip is available: 24.0 -> 24.2
[notice] To update, run: pip install --upgrade pip
6. 安装 vllm==0.4.3
(llama_factory_torch) root@notebook-1813389960667746306-scnlbe5oi5-20553:/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory# ^C
(llama_factory_torch) root@notebook-1813389960667746306-scnlbe5oi5-20553:/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory# pip install --no-dependencies vllm==0.4.3
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting vllm==0.4.3
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/1a/1e/10bcb6566f4fa8b95ff85bddfd1675ff7db33ba861f59bd70aa3b92a46b7/vllm-0.4.3-cp310-cp310-manylinux1_x86_64.whl (131.1 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 131.1/131.1 MB 28.9 MB/s eta 0:00:00
Installing collected packages: vllm
Attempting uninstall: vllm
Found existing installation: vllm 0.3.3+git3380931.abi0.dtk2404.torch2.1
Uninstalling vllm-0.3.3+git3380931.abi0.dtk2404.torch2.1:
Successfully uninstalled vllm-0.3.3+git3380931.abi0.dtk2404.torch2.1
Successfully installed vllm-0.4.3
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
[notice] A new release of pip is available: 24.0 -> 24.2
[notice] To update, run: pip install --upgrade pip
7. requirements.txt
accelerate==0.32.1
addict==2.4.0
aiofiles==23.2.1
aiohttp==3.9.5
aiosignal==1.3.1
annotated-types==0.7.0
anyio==4.4.0
apex @ https://cancon.hpccube.com:65024/directlink/4/apex/DAS1.0/apex-1.1.0+das1.0+0dd7f68.abi0.dtk2404.torch2.1-cp310-cp310-manylinux2014_x86_64.whl#sha256=fdeb7c8a0b354a6a2faa61ae2055b2c2e7deb07bfa4aa7811068c5e02455ee1e
argon2-cffi==23.1.0
argon2-cffi-bindings==21.2.0
arrow==1.3.0
asttokens==2.4.1
async-lru==2.0.4
async-timeout==4.0.3
attrs==23.2.0
Babel==2.15.0
beautifulsoup4==4.12.3
bitsandbytes @ https://cancon.hpccube.com:65024/directlink/4/bitsandbytes/DAS1.0/bitsandbytes-0.37.0+das1.0+gitd3d888f.abi0.dtk2404.torch2.1-py3-none-any.whl#sha256=c46eb3f1555f2153424c3c0297e6645c0881cb76965cf5f3d11f77b52d80c19c
bleach==6.1.0
boltons @ file:///croot/boltons_1677628692245/work
brotlipy==0.7.0
certifi @ file:///croot/certifi_1707229174982/work/certifi
cffi @ file:///tmp/abs_98z5h56wf8/croots/recipe/cffi_1659598650955/work
charset-normalizer @ file:///tmp/build/80754af9/charset-normalizer_1630003229654/work
click==8.1.7
coloredlogs==15.0.1
comm==0.2.2
conda-content-trust @ file:///tmp/abs_5952f1c8-355c-4855-ad2e-538535021ba5h26t22e5/croots/recipe/conda-content-trust_1658126371814/work
conda-package-handling @ file:///croot/conda-package-handling_1666940373510/work
contourpy==1.2.1
cryptography @ file:///croot/cryptography_1665612644927/work
cycler==0.12.1
datasets==2.19.2
debugpy==1.8.1
decorator==5.1.1
deepspeed @ https://cancon.hpccube.com:65024/directlink/4/deepspeed/DAS1.0/deepspeed-0.12.3+das1.0+gita724046.abi0.dtk2404.torch2.1.0-cp310-cp310-manylinux2014_x86_64.whl#sha256=726d64f73ab2ed7bcd716dcb2af53bb3c790ab4a24180b1b9319e7a7ab2cc569
defusedxml==0.7.1
diffusers==0.29.2
dill==0.3.8
dnspython==2.6.1
docstring_parser==0.16
einops==0.8.0
email_validator==2.1.1
exceptiongroup==1.2.1
executing==2.0.1
fastapi==0.111.0
fastapi-cli==0.0.4
fastjsonschema==2.19.1
ffmpy==0.4.0
filelock==3.14.0
fire==0.6.0
flash-attn @ https://cancon.hpccube.com:65024/directlink/4/flash_attn/DAS1.0/flash_attn-2.0.4+das1.0+82379d7.abi0.dtk2404.torch2.1-cp310-cp310-manylinux2014_x86_64.whl#sha256=2facc1831d95b55bf1bca88c7f23163751f4c749e4f7fc9256d8311ddbb5d399
flatbuffers==24.3.25
fonttools==4.52.4
fqdn==1.5.1
frozenlist==1.4.1
fsspec==2024.3.1
gradio==4.40.0
gradio_client==1.2.0
h11==0.14.0
hjson==3.1.0
httpcore==1.0.5
httptools==0.6.1
httpx==0.27.0
huggingface==0.0.1
huggingface-hub==0.23.2
humanfriendly==10.0
hypothesis==5.35.1
idna @ file:///croot/idna_1666125576474/work
importlib_metadata==7.1.0
importlib_resources==6.4.0
invisible-watermark==0.2.0
ipykernel==6.29.4
ipython==8.24.0
ipywidgets==8.1.3
isoduration==20.11.0
jedi==0.19.1
jieba==0.42.1
Jinja2==3.1.4
joblib==1.4.2
json5==0.9.25
jsonpatch @ file:///croot/jsonpatch_1714483231291/work
jsonpointer==2.1
jsonschema==4.22.0
jsonschema-specifications==2023.12.1
jupyter-events==0.10.0
jupyter-lsp==2.2.5
jupyter_client==8.6.2
jupyter_core==5.7.2
jupyter_ext_dataset==0.1.0
jupyter_ext_logo==0.1.0
jupyter_server==2.14.0
jupyter_server_terminals==0.5.3
jupyterlab==4.2.1
jupyterlab-language-pack-zh-CN==4.0.post6
jupyterlab_pygments==0.3.0
jupyterlab_server==2.27.2
jupyterlab_widgets==3.0.11
kiwisolver==1.4.5
lightop @ https://cancon.hpccube.com:65024/directlink/4/lightop/DAS1.0/lightop-0.3+das1.0+837dbb7.abi0.dtk2404.torch2.1-cp310-cp310-manylinux2014_x86_64.whl#sha256=7f4eb1190a570c05a63a4aade326c87367c4e5ccf6ff82ad5e92220790817e5c
-e git+https://github.com/hiyouga/LLaMA-Factory.git@668654b5adae3f897d5291b81410226e1304eff9#egg=llamafactory
lmdeploy @ https://cancon.hpccube.com:65024/directlink/4/lmdeploy/DAS1.0/lmdeploy-0.1.0_das1.0+git782048c.abi0.dtk2404.torch2.1.-cp310-cp310-manylinux2014_x86_64.whl#sha256=499940e022de16b3f1211a52c2daa3a603b109a015487499c9e11a53c6d5ad2c
markdown-it-py==3.0.0
MarkupSafe==2.1.5
matplotlib==3.9.0
matplotlib-inline==0.1.7
mdurl==0.1.2
mistune==3.0.2
mmcv @ https://cancon.hpccube.com:65024/directlink/4/mmcv/DAS1.0/mmcv-2.0.1_das1.0+gitc0ccf15.abi0.dtk2404.torch2.1.-cp310-cp310-manylinux2014_x86_64.whl#sha256=4fc5ff39d232e5ca1efebf7cfdfcf9bc0675308cf40e5f17237c4f2eec66f210
mmengine==0.10.4
mmengine-lite==0.10.4
modelscope==1.17.0
mpmath==1.3.0
msgpack==1.0.8
multidict==6.0.5
multiprocess==0.70.16
nbclient==0.10.0
nbconvert==7.16.4
nbformat==5.10.4
nest-asyncio==1.6.0
networkx==3.3
ninja==1.11.1.1
nltk==3.8.1
notebook_shim==0.2.4
numpy==1.24.3
onnxruntime @ https://cancon.hpccube.com:65024/directlink/4/onnxruntime/DAS1.0/onnxruntime-1.15.0+das1.0+gita9ca438.abi0.dtk2404-cp310-cp310-manylinux2014_x86_64.whl#sha256=509446b41adb89e7507700482cb99e2c399ab3164bc9ea6d9a50e11f84a2406e
opencv-python==4.9.0.80
orjson==3.10.3
overrides==7.7.0
packaging @ file:///croot/packaging_1710807400464/work
pandas==2.2.2
pandocfilters==1.5.1
parso==0.8.4
peft==0.12.0
pexpect==4.9.0
pillow==10.3.0
platformdirs==4.2.2
pluggy @ file:///tmp/build/80754af9/pluggy_1648024709248/work
prometheus_client==0.20.0
prompt_toolkit==3.0.45
protobuf==5.27.0
psutil==5.9.8
ptyprocess==0.7.0
pure-eval==0.2.2
py-cpuinfo==9.0.0
pyarrow==16.1.0
pyarrow-hotfix==0.6
pycosat @ file:///croot/pycosat_1666805502580/work
pycparser @ file:///tmp/build/80754af9/pycparser_1636541352034/work
pydantic==2.7.2
pydantic_core==2.18.3
pydub==0.25.1
Pygments==2.18.0
pynvml==11.5.0
pyOpenSSL @ file:///opt/conda/conda-bld/pyopenssl_1643788558760/work
pyparsing==3.1.2
PySocks @ file:///home/builder/ci_310/pysocks_1640793678128/work
python-dateutil==2.9.0.post0
python-dotenv==1.0.1
python-json-logger==2.0.7
python-multipart==0.0.9
pytz==2024.1
PyWavelets==1.6.0
PyYAML==6.0.1
pyzmq==26.0.3
ray==2.9.3
referencing==0.35.1
regex==2024.5.15
requests==2.32.3
rfc3339-validator==0.1.4
rfc3986-validator==0.1.1
rich==13.7.1
rouge-chinese==1.0.3
rpds-py==0.18.1
ruamel.yaml @ file:///croot/ruamel.yaml_1666304550667/work
ruamel.yaml.clib @ file:///croot/ruamel.yaml.clib_1666302247304/work
ruff==0.5.5
safetensors==0.4.3
scipy==1.14.0
semantic-version==2.10.0
Send2Trash==1.8.3
sentencepiece==0.2.0
shellingham==1.5.4
shtab==1.7.1
six @ file:///tmp/build/80754af9/six_1644875935023/work
sniffio==1.3.1
sortedcontainers==2.4.0
soupsieve==2.5
sse-starlette==2.1.3
stack-data==0.6.3
starlette==0.37.2
sympy==1.12.1
termcolor==2.4.0
terminado==0.18.1
tiktoken==0.7.0
tinycss2==1.3.0
tokenizers==0.19.1
tomli==2.0.1
tomlkit==0.12.0
toolz @ file:///croot/toolz_1667464077321/work
torch @ https://cancon.hpccube.com:65024/directlink/4/pytorch/DAS1.0/torch-2.1.0+das1.0+git00661e0.abi0.dtk2404-cp310-cp310-manylinux2014_x86_64.whl#sha256=0b5f4be74ffdd6fe7540a844bf4f02e432b7d267b5e9fdd7f9448192d93bf3b6
torchaudio @ https://cancon.hpccube.com:65024/directlink/4/torchaudio/DAS1.0/torchaudio-2.1.2+das1.0+253903e.abi0.dtk2404.torch2.1.0-cp310-cp310-manylinux2014_x86_64.whl#sha256=2a7b3bbe8b558f48784f302900fd1dff3ff9d10a3c139e00f2b136a76d6d7f1c
torchvision @ https://cancon.hpccube.com:65024/directlink/4/vision/DAS1.0/torchvision-0.16.0+das1.0+gitc9e7141.abi0.dtk2404.torch2.1-cp310-cp310-manylinux2014_x86_64.whl#sha256=4d5e5071e89892cccb24c3ee0216cd79b3c22bc5cf1eb0eb49c2792d9f49fb62
tornado==6.4
tqdm @ file:///opt/conda/conda-bld/tqdm_1664392687731/work
traitlets==5.14.3
transformers==4.43.3
triton @ https://cancon.hpccube.com:65024/directlink/4/triton/DAS1.0/triton-2.1.0+das1.0+git3841f975.abi0.dtk2404-cp310-cp310-manylinux2014_x86_64.whl#sha256=0dda810eb171af0b3f5cf90a1a4b2f41c9ef0ef08453762a798c86dd01fe976f
trl==0.9.6
typer==0.12.3
types-python-dateutil==2.9.0.20240316
typing_extensions==4.12.0
tyro==0.8.5
tzdata==2024.1
ujson==5.10.0
uri-template==1.3.0
urllib3==2.2.2
uvicorn==0.30.0
uvloop==0.19.0
vllm==0.4.3
watchfiles==0.22.0
wcwidth==0.2.13
webcolors==1.13
webencodings==0.5.1
websocket-client==1.8.0
websockets==12.0
widgetsnbextension==4.0.11
xformers @ https://cancon.hpccube.com:65024/directlink/4/xformers/DAS1.0/xformers-0.0.25+das1.0+gitd11e899.abi0.dtk2404.torch2.1-cp310-cp310-manylinux2014_x86_64.whl#sha256=b086d1bd50bd19c82ca44c424fe193dfcdd48bdd6695d3e6a58f53764c64f428
xxhash==3.4.1
yapf==0.40.2
yarl==1.9.4
zipp==3.19.0
8. envs.yaml
name: llama_factory_torch
channels:
- https://repo.anaconda.com/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- defaults
dependencies:
- _libgcc_mutex=0.1=main
- _openmp_mutex=5.1=1_gnu
- boltons=23.0.0=py310h06a4308_0
- brotlipy=0.7.0=py310h7f8727e_1002
- bzip2=1.0.8=h7b6447c_0
- ca-certificates=2024.3.11=h06a4308_0
- certifi=2024.2.2=py310h06a4308_0
- cffi=1.15.1=py310h74dc2b5_0
- charset-normalizer=2.0.4=pyhd3eb1b0_0
- conda-content-trust=0.1.3=py310h06a4308_0
- conda-package-handling=1.9.0=py310h5eee18b_1
- cryptography=38.0.1=py310h9ce1e76_0
- idna=3.4=py310h06a4308_0
- jsonpatch=1.33=py310h06a4308_1
- ld_impl_linux-64=2.38=h1181459_1
- libffi=3.3=he6710b0_2
- libgcc-ng=11.2.0=h1234567_1
- libgomp=11.2.0=h1234567_1
- libstdcxx-ng=11.2.0=h1234567_1
- libuuid=1.41.5=h5eee18b_0
- ncurses=6.3=h5eee18b_3
- openssl=1.1.1w=h7f8727e_0
- pluggy=1.0.0=py310h06a4308_1
- pycosat=0.6.4=py310h5eee18b_0
- pycparser=2.21=pyhd3eb1b0_0
- pyopenssl=22.0.0=pyhd3eb1b0_0
- pysocks=1.7.1=py310h06a4308_0
- python=3.10.8=haa1d7c7_0
- readline=8.2=h5eee18b_0
- ruamel.yaml=0.17.21=py310h5eee18b_0
- ruamel.yaml.clib=0.2.6=py310h5eee18b_1
- setuptools=65.5.0=py310h06a4308_0
- six=1.16.0=pyhd3eb1b0_1
- sqlite=3.40.0=h5082296_0
- tk=8.6.12=h1ccaba5_0
- toolz=0.12.0=py310h06a4308_0
- tqdm=4.64.1=py310h06a4308_0
- wheel=0.37.1=pyhd3eb1b0_0
- xz=5.2.8=h5eee18b_0
- zlib=1.2.13=h5eee18b_0
- pip:
- accelerate==0.32.1
- addict==2.4.0
- aiofiles==23.2.1
- aiohttp==3.9.5
- aiosignal==1.3.1
- annotated-types==0.7.0
- anyio==4.4.0
- apex==1.1.0+0dd7f68.abi0.dtk2404.torch2.1
- argon2-cffi==23.1.0
- argon2-cffi-bindings==21.2.0
- arrow==1.3.0
- asttokens==2.4.1
- async-lru==2.0.4
- async-timeout==4.0.3
- attrs==23.2.0
- babel==2.15.0
- beautifulsoup4==4.12.3
- bitsandbytes==0.37.0+gitd3d888f.abi0.dtk2404.torch2.1
- bleach==6.1.0
- click==8.1.7
- coloredlogs==15.0.1
- comm==0.2.2
- contourpy==1.2.1
- cycler==0.12.1
- datasets==2.19.2
- debugpy==1.8.1
- decorator==5.1.1
- deepspeed==0.12.3+gita724046.abi0.dtk2404.torch2.1.0
- defusedxml==0.7.1
- diffusers==0.29.2
- dill==0.3.8
- dnspython==2.6.1
- docstring-parser==0.16
- einops==0.8.0
- email-validator==2.1.1
- exceptiongroup==1.2.1
- executing==2.0.1
- fastapi==0.111.0
- fastapi-cli==0.0.4
- fastjsonschema==2.19.1
- ffmpy==0.4.0
- filelock==3.14.0
- fire==0.6.0
- flash-attn==2.0.4+82379d7.abi0.dtk2404.torch2.1
- flatbuffers==24.3.25
- fonttools==4.52.4
- fqdn==1.5.1
- frozenlist==1.4.1
- fsspec==2024.3.1
- gradio==4.40.0
- gradio-client==1.2.0
- h11==0.14.0
- hjson==3.1.0
- httpcore==1.0.5
- httptools==0.6.1
- httpx==0.27.0
- huggingface==0.0.1
- huggingface-hub==0.23.2
- humanfriendly==10.0
- hypothesis==5.35.1
- importlib-metadata==7.1.0
- importlib-resources==6.4.0
- invisible-watermark==0.2.0
- ipykernel==6.29.4
- ipython==8.24.0
- ipywidgets==8.1.3
- isoduration==20.11.0
- jedi==0.19.1
- jieba==0.42.1
- jinja2==3.1.4
- joblib==1.4.2
- json5==0.9.25
- jsonpointer==2.4
- jsonschema==4.22.0
- jsonschema-specifications==2023.12.1
- jupyter-client==8.6.2
- jupyter-core==5.7.2
- jupyter-events==0.10.0
- jupyter-ext-dataset==0.1.0
- jupyter-ext-logo==0.1.0
- jupyter-lsp==2.2.5
- jupyter-server==2.14.0
- jupyter-server-terminals==0.5.3
- jupyterlab==4.2.1
- jupyterlab-language-pack-zh-cn==4.0.post6
- jupyterlab-pygments==0.3.0
- jupyterlab-server==2.27.2
- jupyterlab-widgets==3.0.11
- kiwisolver==1.4.5
- lightop==0.3+837dbb7.abi0.dtk2404.torch2.1
- llamafactory==0.8.4.dev0
- lmdeploy==0.1.0-git782048c.abi0.dtk2404.torch2.1.
- markdown-it-py==3.0.0
- markupsafe==2.1.5
- matplotlib==3.9.0
- matplotlib-inline==0.1.7
- mdurl==0.1.2
- mistune==3.0.2
- mmcv==2.0.1-gitc0ccf15.abi0.dtk2404.torch2.1.
- mmengine==0.10.4
- mmengine-lite==0.10.4
- modelscope==1.17.0
- mpmath==1.3.0
- msgpack==1.0.8
- multidict==6.0.5
- multiprocess==0.70.16
- nbclient==0.10.0
- nbconvert==7.16.4
- nbformat==5.10.4
- nest-asyncio==1.6.0
- networkx==3.3
- ninja==1.11.1.1
- nltk==3.8.1
- notebook-shim==0.2.4
- numpy==1.24.3
- onnxruntime==1.15.0+gita9ca438.abi0.dtk2404
- opencv-python==4.9.0.80
- orjson==3.10.3
- overrides==7.7.0
- packaging==24.0
- pandas==2.2.2
- pandocfilters==1.5.1
- parso==0.8.4
- peft==0.12.0
- pexpect==4.9.0
- pillow==10.3.0
- pip==24.0
- platformdirs==4.2.2
- prometheus-client==0.20.0
- prompt-toolkit==3.0.45
- protobuf==5.27.0
- psutil==5.9.8
- ptyprocess==0.7.0
- pure-eval==0.2.2
- py-cpuinfo==9.0.0
- pyarrow==16.1.0
- pyarrow-hotfix==0.6
- pydantic==2.7.2
- pydantic-core==2.18.3
- pydub==0.25.1
- pygments==2.18.0
- pynvml==11.5.0
- pyparsing==3.1.2
- python-dateutil==2.9.0.post0
- python-dotenv==1.0.1
- python-json-logger==2.0.7
- python-multipart==0.0.9
- pytz==2024.1
- pywavelets==1.6.0
- pyyaml==6.0.1
- pyzmq==26.0.3
- ray==2.9.3
- referencing==0.35.1
- regex==2024.5.15
- requests==2.32.3
- rfc3339-validator==0.1.4
- rfc3986-validator==0.1.1
- rich==13.7.1
- rouge-chinese==1.0.3
- rpds-py==0.18.1
- ruff==0.5.5
- safetensors==0.4.3
- scipy==1.14.0
- semantic-version==2.10.0
- send2trash==1.8.3
- sentencepiece==0.2.0
- shellingham==1.5.4
- shtab==1.7.1
- sniffio==1.3.1
- sortedcontainers==2.4.0
- soupsieve==2.5
- sse-starlette==2.1.3
- stack-data==0.6.3
- starlette==0.37.2
- sympy==1.12.1
- termcolor==2.4.0
- terminado==0.18.1
- tiktoken==0.7.0
- tinycss2==1.3.0
- tokenizers==0.19.1
- tomli==2.0.1
- tomlkit==0.12.0
- torch==2.1.0+git00661e0.abi0.dtk2404
- torchaudio==2.1.2+253903e.abi0.dtk2404.torch2.1.0
- torchvision==0.16.0+gitc9e7141.abi0.dtk2404.torch2.1
- tornado==6.4
- traitlets==5.14.3
- transformers==4.43.3
- triton==2.1.0+git3841f975.abi0.dtk2404
- trl==0.9.6
- typer==0.12.3
- types-python-dateutil==2.9.0.20240316
- typing-extensions==4.12.0
- tyro==0.8.5
- tzdata==2024.1
- ujson==5.10.0
- uri-template==1.3.0
- urllib3==2.2.2
- uvicorn==0.30.0
- uvloop==0.19.0
- vllm==0.4.3
- watchfiles==0.22.0
- wcwidth==0.2.13
- webcolors==1.13
- webencodings==0.5.1
- websocket-client==1.8.0
- websockets==12.0
- widgetsnbextension==4.0.11
- xformers==0.0.25+gitd11e899.abi0.dtk2404.torch2.1
- xxhash==3.4.1
- yapf==0.40.2
- yarl==1.9.4
- zipp==3.19.0
prefix: /opt/conda/envs/llama_factory_torch
三、服务器信息

1. CPU
root@notebook-1819288410202615810-scnlbe5oi5-43560:~# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 45 bits physical, 48 bits virtual
CPU(s): 256
On-line CPU(s) list: 0-254
Off-line CPU(s) list: 255
Thread(s) per core: 1
Core(s) per socket: 64
Socket(s): 2
NUMA node(s): 8
Vendor ID: HygonGenuine
CPU family: 24
Model: 4
Model name: Hygon C86 7490 64-core Processor
Stepping: 1
Frequency boost: enabled
CPU MHz: 1600.000
CPU max MHz: 2700.0000
CPU min MHz: 1600.0000
BogoMIPS: 5400.11
Virtualization: AMD-V
L1d cache: 2 MiB
L1i cache: 2 MiB
L2 cache: 32 MiB
L3 cache: 256 MiB
NUMA node0 CPU(s): 0-15,128-143
NUMA node1 CPU(s): 16-31,144-159
NUMA node2 CPU(s): 32-47,160-175
NUMA node3 CPU(s): 48-63,176-191
NUMA node4 CPU(s): 64-79,192-207
NUMA node5 CPU(s): 80-95,208-223
NUMA node6 CPU(s): 96-111,224-239
NUMA node7 CPU(s): 112-127,240-254
Vulnerability L1tf: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; Load fences, __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Full retpoline
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht
syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc art rep_good nopl xtopology nonstop_tsc ext
d_apicid amd_dcm aperfmperf eagerfpu pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 x2apic movbe
popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dno
wprefetch osvw skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_l2 cpb hw_pstate sme retp
oline_amd ssbd ibrs ibpb stibp vmmcall fsgsbase bmi1 avx2 smep bmi2 rdseed adx smap clflushopt sha_ni
xsaveopt xsavec xgetbv1 clzero irperf xsaveerptr arat npt lbrv svm_lock nrip_save tsc_scale vmcb_cle
an flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif umip overflow_recov su
ccor smca
2. 显卡
单卡环境

Every 1.0s: rocm-smi notebook-1813389960667746306-scnlbe5oi5-20553: Fri Aug 2 21:26:42 2024
============================ System Management Interface =============================
======================================================================================
DCU Temp AvgPwr Perf PwrCap VRAM% DCU% Mode
0 59.0C 108.0W auto 300.0W 0% 0% Normal
======================================================================================
=================================== End of SMI Log ===================================
多卡环境

Every 1.0s: rocm-smi notebook-1819288410202615810-scnlbe5oi5-43560: Fri Aug 2 16:33:17 2024
============================ System Management Interface =============================
======================================================================================
DCU Temp AvgPwr Perf PwrCap VRAM% DCU% Mode
0 69.0C 112.0W auto 300.0W 0% 0% Normal
1 68.0C 114.0W auto 300.0W 0% 0% Normal
2 66.0C 113.0W auto 300.0W 0% 0% Normal
======================================================================================
=================================== End of SMI Log ===================================
3. 内存
root@notebook-1819288410202615810-scnlbe5oi5-43560:~# free -h
total used free shared buff/cache available
Mem: 1.0Ti 79Gi 20Gi 11Mi 907Gi 926Gi
Swap: 0B 0B 0B
4. 硬盘
root@notebook-1819288410202615810-scnlbe5oi5-43560:~# df -h
Filesystem Size Used Avail Use% Mounted on
overlay 11T 2.2T 7.8T 22% /
tmpfs 64M 0 64M 0% /dev
tmpfs 504G 0 504G 0% /sys/fs/cgroup
ks_p300s_public 53P 37P 16P 71% /etc/sugon_motd
/dev/md0 11T 2.2T 7.8T 22% /etc/hosts
/dev/mapper/centos-root 3.5T 20G 3.5T 1% /etc/tmp
tmpfs 330G 32K 330G 1% /dev/shm
tmpfs 330G 12K 330G 1% /run/secrets/kubernetes.io/serviceaccount
tmpfs 504G 0 504G 0% /proc/acpi
tmpfs 504G 0 504G 0% /proc/scsi
tmpfs 504G 0 504G 0% /sys/firmware
5. 系统信息
root@notebook-1819288410202615810-scnlbe5oi5-43560:~# cat /etc/*release
DISTRIB_ID=Ubuntu
DISTRIB_RELEASE=20.04
DISTRIB_CODENAME=focal
DISTRIB_DESCRIPTION="Ubuntu 20.04.6 LTS"
NAME="Ubuntu"
VERSION="20.04.6 LTS (Focal Fossa)"
ID=ubuntu
ID_LIKE=debian
PRETTY_NAME="Ubuntu 20.04.6 LTS"
VERSION_ID="20.04"
HOME_URL="https://www.ubuntu.com/"
SUPPORT_URL="https://help.ubuntu.com/"
BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/"
PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy"
VERSION_CODENAME=focal
UBUNTU_CODENAME=focal
四、私有化部署Llama 3模型
官网文章:Meet Your New Assistant: Meta AI, Built With Llama 3 | Meta
GitHub仓库代码:https://github.com/meta-llama/llama3
文档地址:https://llama.meta.com/docs/model-cards-and-prompt-formats/meta-llama-3
在线体验地址:https://llama.meta.com/llama3/
1. 环境准备
# 创建虚拟环境
conda create -n llama_factory_torch python=3.10
# 激活虚拟环境
conda activate llama_factory_torch
# 如果报错,执行以下指令
source activate llama_factory_torch
# 下载LLama_Factory源码
git clone https://github.com/hiyouga/LLaMA-Factory.git
# 升级pip
# 建议在执行项目的依赖安装之前升级 pip 的版本,如果使用的是旧版本的 pip,可能无法安装一些最新的包,或者可能无法正确解析依赖关系。
python -m pip install --upgrade pip
# 如果失败,执行以下指令
pip install --upgrade pip
# 安装requirements.txt
pip install -r requirements.txt --index-url https://mirrors.huaweicloud.com/repository/pypi/simple
2. 下载Llama3模型
mkdir models
cd models
# 以 Llama3-8b 为例
git clone https://www.modelscope.cn/LLM-Research/Meta-Llama-3-8B-Instruct.git
- huggingface Llama3模型主页:https://huggingface.co/meta-llama/
- Github主页:https://github.com/meta-llama/llama3/tree/main
- ModelScope Llama3-8b模型主页:https://www.modelscope.cn/models/LLM-Research/Meta-Llama-3-8B-Instruct/summary
3. 启动web服务
python src/webui.py \
--model_name_or_path "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/models/Meta-Llama-3-8B-Instruct" \
--template llama3 \
--infer_backend vllm \
--vllm_enforce_eager
# 后台启动
nohup python src/webui.py \
--model_name_or_path "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/models/Meta-Llama-3-8B-Instruct/" \
--template llama3 \
--infer_backend vllm \
--vllm_enforce_eager \
> out.log 2>&1 &
服务启动成功,输出结果如下:
(llama_factory_torch) root@notebook-1813389960667746306-scnlbe5oi5-50216:/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory# python src/webui.py --model_name_or_path "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/models/Meta-Llama-3-8B-Instruct/" --template llama3 --infer_backend vllm --vllm_enforce_eager
gradio_share: False
Running on local URL: http://0.0.0.0:7860
Running on public URL: https://36dfc90e71a7e8c548.gradio.live
This share link expires in 72 hours. For free permanent hosting and GPU upgrades, run `gradio deploy` from Terminal to deploy to Spaces (https://huggingface.co/spaces)
4. 访问服务
访问 http://127.0.0.1:8000。

通过上述步骤就已经完成了LLaMA-Factory模型的完整私有化部署过程。
五、微调Llama 3模型
github仓库代码:LLaMA-Factory
1. 引言
LLaMA Factory是一个在GitHub上开源的项目,该项目给自身的定位是:提供一个易于使用的大语言模型(LLM)微调框架,支持LLaMA、Baichuan、Qwen、ChatGLM等架构的大模型。更细致的看,该项目提供了从预训练、指令微调到RLHF阶段的开源微调解决方案。截止目前(2024年7月30日)支持约20+种不同的模型和内置了60+的数据集,同时封装出了非常高效和易用的开发者使用方法。而其中最让人喜欢的是其开发的LLaMA Board,这是一个零代码、可视化的一站式网页微调界面,它允许我们通过Web UI轻松设置各种微调过程中的超参数,且整个训练过程的实时进度都会在Web UI中进行同步更新。
简单理解,通过该项目我们只需下载相应的模型,并根据项目要求准备符合标准的微调数据集,即可快速开始微调过程,而这样的操作可以有效地将特定领域的知识注入到通用模型中,增强模型对特定知识领域的理解和认知能力,以达到“通用模型到垂直模型的快速转变”。
前一章节私有化部署的Llama 3模型还不具备中文处理能力,本章将用中文数据集对模型进行微调。
2. 整体流程
基于LLaMA-Factory的Llama3中文能力微调过程,如下图所示:

3. 查看数据字典
文件路径:"LLaMA-Factory/data/dataset_info.json",该文件是数据集的注册文件,包含了所有可用的数据集。
查看中文数据集的数据字典:alpaca_zh。

4. 创建微调脚本
所谓高效微调框架,我们可以将其理解为很多功能都进行了高层封装的工具库,为了使用这些工具完成大模型微调,我们需要编写一些脚本(也就是操作系统可以执行的命令集),来调用这些工具完成大模型微调。
切换到 ./LLaMA-Factory 目录,创建一个名为 single_lora_llama3.sh 脚本文件(该文件任意取名)。
#!/bin/bash
export CUDA_DEVICE_MAX_CONNECTIONS=1
export NCCL_P2P_DISABLE="1"
export NCCL_IB_DISABLE="1"
# 如果是预训练,添加参数 --stage pt \
# 如果是指令监督微调,添加参数 --stage sft \
# 如果是奖励模型训练,添加参数 --stage rm \
# 添加 --quantization_bit 4 就是4bit量化的QLoRA微调,不添加此参数就是LoRA微调 \
python src/train.py \ ## 单卡运行
--stage sft \ ## --stage pt (预训练模式) --stage sft(指令监督模式)
--do_train True \ ## 执行训练模型
--model_name_or_path models/Meta-Llama-3-8B-Instruct \ ## 模型的存储路径
--dataset alpaca_zh \ ## 训练数据的存储路径,存放在 LLaMA-Factory/data路径下
--template llama3 \ ## 选择llama3模版
--lora_target q_proj,v_proj \ ## 默认模块应作为
--output_dir saves/llama3-8b/lora/sft \ ## 微调后的模型保存路径
--overwrite_cache \ ## 是否忽略并覆盖已存在的缓存数据
--per_device_train_batch_size 1 \ ## 用于训练的批处理大小。可根据 GPU 显存大小自行设置。
--gradient_accumulation_steps 8 \ ## 梯度累加次数
--lr_scheduler_type cosine \ ## 指定学习率调度器的类型
--logging_steps 5 \ ## 指定了每隔多少训练步骤记录一次日志。这包括损失、学习率以及其他重要的训练指标,有助于监控训练过程。
--save_steps 100 \ ## 每隔多少训练步骤保存一次模型。这是模型保存和检查点创建的频率,允许你在训练过程中定期保存模型的状态
--learning_rate 5.0e-5 \ ## 学习率
--num_train_epochs 1.0 \ ## 指定了训练过程将遍历整个数据集的次数。一个epoch表示模型已经看过一次所有的训练数据。
--finetuning_type lora \ ## 参数指定了微调的类型,lora代表使用LoRA(Low-Rank Adaptation)技术进行微调。
--fp16 \ ## 开启半精度浮点数训练
--lora_rank 4 \ ## 在使用LoRA微调时设置LoRA适应层的秩。
注意:实际脚本文件不要出现中文备注,否则运行失败。
此外,为了保险起见,我们需要对齐格式内容进行调整,以满足Ubuntu操作系统运行需要(此前是从Windows系统上复制过去的文件,一般都需要进行如此操作):
sed -i 's/\r$//' ./single_lora_llama3.sh
5. 运行微调脚本
运行微调脚本,获取模型微调权重。
5.1 单卡运行
# 修改权限
chmod +x ./single_lora_llama3.sh
# 执行脚本
./single_lora_llama3.sh
单卡显存不足,导致模型加载失败,请参考下文FAQ。
5.2 多卡运行(单机多卡)
使用 llamafactory-cli 启动 DeepSpeed 引擎进行单机多卡训练。
# 拷贝一份
cp examples/train_lora/llama3_lora_sft.yaml examples/train_lora/llama3_lora_sft.yaml.bak
根据 single_lora_llama3.sh 脚本内容,修改 LLaMA-Factory/examples/train_lora/llama3_lora_sft.yaml 文件。为了启动 DeepSpeed 引擎,配置文件中 deepspeed 参数指定 DeepSpeed 配置文件的路径。
### model
# model_name_or_path: meta-llama/Meta-Llama-3-8B-Instruct
model_name_or_path: models/Meta-Llama-3-8B-Instruct
### deepspeed
deepspeed: examples/deepspeed/ds_z3_config.json
### method
stage: sft
do_train: true
finetuning_type: lora
lora_target: q_proj,v_proj
### dataset
dataset: alpaca_zh
template: llama3
cutoff_len: 1024
max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 16
### output
output_dir: saves/llama3-8b/lora/sft
logging_steps: 5
save_steps: 100
plot_loss: true
overwrite_output_dir: true
### train
per_device_train_batch_size: 2
gradient_accumulation_steps: 64
learning_rate: 5.0e-5
num_train_epochs: 1.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
### eval
val_size: 0.1
per_device_eval_batch_size: 1
eval_strategy: steps
eval_steps: 500
执行微调
FORCE_TORCHRUN=1 llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml
输出结果
(llama_factory_torch) root@notebook-1813389960667746306-scnlbe5oi5-12495:/public/home/scnlbe5oillama3_lora_sft.yaml
[2024-08-04 16:23:38,886] [INFO] [real_accelerator.py:158:get_accelerator] Setting ds_accelerat
08/04/2024 16:23:42 - INFO - llamafactory.cli - Initializing distributed tasks at: 127.0.0.1:20
[2024-08-04 16:23:44,249] torch.distributed.run: [WARNING]
[2024-08-04 16:23:44,249] torch.distributed.run: [WARNING] ************************************
[2024-08-04 16:23:44,249] torch.distributed.run: [WARNING] Setting OMP_NUM_THREADS environment rther tune the variable for optimal performance in your application as needed.
[2024-08-04 16:23:44,249] torch.distributed.run: [WARNING] ************************************
[2024-08-04 16:23:48,750] [INFO] [real_accelerator.py:158:get_accelerator] Setting ds_accelerat
[2024-08-04 16:23:48,796] [INFO] [real_accelerator.py:158:get_accelerator] Setting ds_accelerat
[2024-08-04 16:23:48,827] [INFO] [real_accelerator.py:158:get_accelerator] Setting ds_accelerat
[2024-08-04 16:23:49,156] [INFO] [real_accelerator.py:158:get_accelerator] Setting ds_accelerat
[2024-08-04 16:23:51,967] [INFO] [comm.py:637:init_distributed] cdb=None
WARNING: Logging before InitGoogleLogging() is written to STDERR
I0804 16:23:51.968763 217828 ProcessGroupNCCL.cpp:686] [Rank 3] ProcessGroupNCCL initializationING_WAIT: 0, TIMEOUT(ms): 180000000000, USE_HIGH_PRIORITY_STREAM: 0, TORCH_DISTRIBUTED_DEBUG: O
08/04/2024 16:23:51 - WARNING - llamafactory.hparams.parser - `ddp_find_unused_parameters` need
08/04/2024 16:23:51 - INFO - llamafactory.hparams.parser - Process rank: 3, device: cuda:3, n_g
[2024-08-04 16:23:52,047] [INFO] [comm.py:637:init_distributed] cdb=None
WARNING: Logging before InitGoogleLogging() is written to STDERR
I0804 16:23:52.048951 217827 ProcessGroupNCCL.cpp:686] [Rank 2] ProcessGroupNCCL initializationING_WAIT: 0, TIMEOUT(ms): 180000000000, USE_HIGH_PRIORITY_STREAM: 0, TORCH_DISTRIBUTED_DEBUG: O
[2024-08-04 16:23:52,054] [INFO] [comm.py:637:init_distributed] cdb=None
[2024-08-04 16:23:52,054] [INFO] [comm.py:668:init_distributed] Initializing TorchBackend in De
WARNING: Logging before InitGoogleLogging() is written to STDERR
I0804 16:23:52.055722 217825 ProcessGroupNCCL.cpp:686] [Rank 0] ProcessGroupNCCL initializationING_WAIT: 0, TIMEOUT(ms): 180000000000, USE_HIGH_PRIORITY_STREAM: 0, TORCH_DISTRIBUTED_DEBUG: O
08/04/2024 16:23:52 - WARNING - llamafactory.hparams.parser - `ddp_find_unused_parameters` need
08/04/2024 16:23:52 - INFO - llamafactory.hparams.parser - Process rank: 2, device: cuda:2, n_g
08/04/2024 16:23:52 - WARNING - llamafactory.hparams.parser - `ddp_find_unused_parameters` need
08/04/2024 16:23:52 - INFO - llamafactory.hparams.parser - Process rank: 0, device: cuda:0, n_g
[INFO|tokenization_auto.py:682] 2024-08-04 16:23:52,065 >> Could not locate the tokenizer confi
[INFO|configuration_utils.py:731] 2024-08-04 16:23:52,065 >> loading configuration file models/
[INFO|configuration_utils.py:800] 2024-08-04 16:23:52,066 >> Model config LlamaConfig {
"_name_or_path": "models/Meta-Llama-3-8B-Instruct",
"architectures": [
"LlamaForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 128000,
"eos_token_id": 128001,
"hidden_act": "silu",
"hidden_size": 8192,
"initializer_range": 0.02,
"intermediate_size": 28672,
"max_position_embeddings": 8192,
"mlp_bias": false,
"model_type": "llama",
"num_attention_heads": 64,
"num_hidden_layers": 80,
"num_key_value_heads": 8,
"pretraining_tp": 1,
"rms_norm_eps": 1e-05,
"rope_scaling": null,
"rope_theta": 500000.0,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.43.3",
"use_cache": true,
"vocab_size": 128256
}
[INFO|tokenization_utils_base.py:2287] 2024-08-04 16:23:52,068 >> loading file tokenizer.model
[INFO|tokenization_utils_base.py:2287] 2024-08-04 16:23:52,068 >> loading file tokenizer.json
[INFO|tokenization_utils_base.py:2287] 2024-08-04 16:23:52,068 >> loading file added_tokens.jso
[INFO|tokenization_utils_base.py:2287] 2024-08-04 16:23:52,068 >> loading file special_tokens_m
[INFO|tokenization_utils_base.py:2287] 2024-08-04 16:23:52,068 >> loading file tokenizer_config
[INFO|configuration_utils.py:731] 2024-08-04 16:23:52,069 >> loading configuration file models/
[INFO|configuration_utils.py:800] 2024-08-04 16:23:52,069 >> Model config LlamaConfig {
"_name_or_path": "models/Meta-Llama-3-8B-Instruct",
"architectures": [
"LlamaForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 128000,
"eos_token_id": 128001,
"hidden_act": "silu",
"hidden_size": 8192,
"initializer_range": 0.02,
"intermediate_size": 28672,
"max_position_embeddings": 8192,
"mlp_bias": false,
"model_type": "llama",
"num_attention_heads": 64,
"num_hidden_layers": 80,
"num_key_value_heads": 8,
"pretraining_tp": 1,
"rms_norm_eps": 1e-05,
"rope_scaling": null,
"rope_theta": 500000.0,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.43.3",
"use_cache": true,
"vocab_size": 128256
}
You are using the default legacy behaviour of the <class 'transformers.models.llama.tokenizatioous) behavior will be used so nothing changes for you. If you want to use the new behaviour, se the reason why this was added as explained in https://github.com/huggingface/transformers/pull
You are using the default legacy behaviour of the <class 'transformers.models.llama.tokenizatioous) behavior will be used so nothing changes for you. If you want to use the new behaviour, se the reason why this was added as explained in https://github.com/huggingface/transformers/pull
[WARNING|logging.py:328] 2024-08-04 16:23:52,209 >> You are using the default legacy behaviour expected, and simply means that the `legacy` (previous) behavior will be used so nothing changif you understand what it means, and thoroughly read the reason why this was added as explainedrom a GGUF file you can ignore this message.
[2024-08-04 16:23:52,374] [INFO] [comm.py:637:init_distributed] cdb=None
WARNING: Logging before InitGoogleLogging() is written to STDERR
I0804 16:23:52.375600 217826 ProcessGroupNCCL.cpp:686] [Rank 1] ProcessGroupNCCL initializationING_WAIT: 0, TIMEOUT(ms): 180000000000, USE_HIGH_PRIORITY_STREAM: 0, TORCH_DISTRIBUTED_DEBUG: O
08/04/2024 16:23:52 - WARNING - llamafactory.hparams.parser - `ddp_find_unused_parameters` need
08/04/2024 16:23:52 - INFO - llamafactory.hparams.parser - Process rank: 1, device: cuda:1, n_g
08/04/2024 16:23:52 - INFO - llamafactory.data.template - Replace eos token: <|eot_id|>
08/04/2024 16:23:52 - INFO - llamafactory.data.template - Add pad token: <|eot_id|>
08/04/2024 16:23:52 - INFO - llamafactory.data.template - Replace eos token: <|eot_id|>
08/04/2024 16:23:52 - INFO - llamafactory.data.template - Add pad token: <|eot_id|>
You are using the default legacy behaviour of the <class 'transformers.models.llama.tokenizatioous) behavior will be used so nothing changes for you. If you want to use the new behaviour, se the reason why this was added as explained in https://github.com/huggingface/transformers/pull
[INFO|tokenization_utils_base.py:2533] 2024-08-04 16:23:52,524 >> Special tokens have been adde
08/04/2024 16:23:52 - INFO - llamafactory.data.template - Replace eos token: <|eot_id|>
08/04/2024 16:23:52 - INFO - llamafactory.data.template - Add pad token: <|eot_id|>
08/04/2024 16:23:52 - INFO - llamafactory.data.loader - Loading dataset llamafactory/alpaca_zh.
I0804 16:23:52.711570 217828 ProcessGroupNCCL.cpp:2780] Rank 3 using GPU 3 to perform barrier as rank to GPU mapping is incorrect.Specify device_ids in barrier() to force use of a particular
I0804 16:23:52.759332 217827 ProcessGroupNCCL.cpp:2780] Rank 2 using GPU 2 to perform barrier as rank to GPU mapping is incorrect.Specify device_ids in barrier() to force use of a particular
08/04/2024 16:23:52 - INFO - llamafactory.data.template - Replace eos token: <|eot_id|>
08/04/2024 16:23:52 - INFO - llamafactory.data.template - Add pad token: <|eot_id|>
I0804 16:23:53.070227 217826 ProcessGroupNCCL.cpp:2780] Rank 1 using GPU 1 to perform barrier as rank to GPU mapping is incorrect.Specify device_ids in barrier() to force use of a particular
Converting format of dataset (num_proc=16): 100%|██████████████████████████████████████████████
I0804 16:24:00.898221 217825 ProcessGroupNCCL.cpp:2780] Rank 0 using GPU 0 to perform barrier as rank to GPU mapping is incorrect.Specify device_ids in barrier() to force use of a particular
I0804 16:24:01.550724 217825 ProcessGroupNCCL.cpp:1340] NCCL_DEBUG: N/A
08/04/2024 16:24:01 - INFO - llamafactory.data.loader - Loading dataset llamafactory/alpaca_zh.
08/04/2024 16:24:01 - INFO - llamafactory.data.loader - Loading dataset llamafactory/alpaca_zh.
08/04/2024 16:24:01 - INFO - llamafactory.data.loader - Loading dataset llamafactory/alpaca_zh.
Running tokenizer on dataset (num_proc=16): 100%|██████████████████████████████████████████████
training example:
input_ids:
[128000, 128006, 882, 128007, 271, 98739, 109425, 19000, 9080, 40053, 104654, 16325, 111689, 83128, 116051, 56602, 53610, 85315, 233, 118959, 83601, 115, 65455, 34208, 53610, 104432, 65455, , 53610, 3922, 78657, 108914, 81802, 245, 34208, 108914, 118959, 1811, 720, 18, 13, 74662, 117434208, 66285, 234, 36117, 231, 73548, 9554, 118487, 53610, 106041, 91495, 82317, 13646, 23951, 103167, 111155, 85315, 233, 118959, 65455, 56602, 95337, 11883, 53610, 1811, 720, 21, 13, 11453173, 1811, 720, 22, 13, 20033, 115, 109895, 58291, 125405, 46034, 13646, 30356, 111110, 53610, 21082, 1811, 720, 24, 13, 59330, 121, 88367, 43240, 30590, 30358, 59464, 38129, 118954, 53610, 233, 118959, 9554, 53610, 75376, 720, 605, 13, 127609, 125025, 126369, 60455, 96455, 45736, 95
inputs:
<|begin_of_text|><|start_header_id|>user<|end_header_id|>
我们如何在日常生活中减少用水?<|eot_id|><|start_header_id|>assistant<|end_header_id|>
1. 使用节水装置,如节水淋浴喷头和水龙头。
2. 使用水箱或水桶收集家庭废水,例如洗碗和洗浴。
3. 在社区中提高节水意识。
4. 检查水管和灌溉系统的漏水情况,并及时修复它们。
5. 洗澡时间缩短,使用低流量淋浴头节约用水。
6. 收集雨水,用于园艺或其他非饮用目的。
7. 刷牙或擦手时关掉水龙头。
8. 减少浇水草坪的时间。
9. 尽可能多地重复使用灰水(来自洗衣机、浴室水槽和淋浴的水)。
10. 只购买能源效率高的洗碗机和洗衣机。<|eot_id|>
label_ids:
[-100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -1000, 85315, 233, 118959, 83601, 115, 65455, 34208, 53610, 104432, 65455, 1811, 720, 17, 13, 867588914, 81802, 245, 34208, 108914, 118959, 1811, 720, 18, 13, 74662, 117481, 16325, 115890, 56602, 231, 73548, 9554, 118487, 53610, 106041, 91495, 82317, 13646, 23951, 59464, 127150, 1811, 720233, 118959, 65455, 56602, 95337, 11883, 53610, 1811, 720, 21, 13, 114524, 43167, 106786, 53610 20033, 115, 109895, 58291, 125405, 46034, 13646, 30356, 111110, 53610, 104432, 65455, 1811, 723, 59330, 121, 88367, 43240, 30590, 30358, 59464, 38129, 118954, 53610, 10110, 124714, 108914, 0, 75376, 720, 605, 13, 127609, 125025, 126369, 60455, 96455, 45736, 9554, 108914, 81802, 245,
labels:
1. 使用节水装置,如节水淋浴喷头和水龙头。
2. 使用水箱或水桶收集家庭废水,例如洗碗和洗浴。
3. 在社区中提高节水意识。
4. 检查水管和灌溉系统的漏水情况,并及时修复它们。
5. 洗澡时间缩短,使用低流量淋浴头节约用水。
6. 收集雨水,用于园艺或其他非饮用目的。
7. 刷牙或擦手时关掉水龙头。
8. 减少浇水草坪的时间。
9. 尽可能多地重复使用灰水(来自洗衣机、浴室水槽和淋浴的水)。
10. 只购买能源效率高的洗碗机和洗衣机。<|eot_id|>
[INFO|configuration_utils.py:731] 2024-08-04 16:24:08,252 >> loading configuration file models/
[INFO|configuration_utils.py:800] 2024-08-04 16:24:08,254 >> Model config LlamaConfig {
"_name_or_path": "models/Meta-Llama-3-8B-Instruct",
"architectures": [
"LlamaForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 128000,
"eos_token_id": 128001,
"hidden_act": "silu",
"hidden_size": 8192,
"initializer_range": 0.02,
"intermediate_size": 28672,
"max_position_embeddings": 8192,
"mlp_bias": false,
"model_type": "llama",
"num_attention_heads": 64,
"num_hidden_layers": 80,
"num_key_value_heads": 8,
"pretraining_tp": 1,
"rms_norm_eps": 1e-05,
"rope_scaling": null,
"rope_theta": 500000.0,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.43.3",
"use_cache": true,
"vocab_size": 128256
}
[INFO|modeling_utils.py:3631] 2024-08-04 16:24:08,284 >> loading weights file models/Meta-Llama
[INFO|modeling_utils.py:3776] 2024-08-04 16:24:08,285 >> Detected DeepSpeed ZeRO-3: activating
[INFO|configuration_utils.py:1038] 2024-08-04 16:24:08,295 >> Generate config GenerationConfig
"bos_token_id": 128000,
"eos_token_id": 128001
}
[2024-08-04 16:24:31,568] [INFO] [partition_parameters.py:348:__exit__] finished initializing m
Loading checkpoint shards: 100%|███████████████████████████████████████████████████████████████
Loading checkpoint shards: 100%|███████████████████████████████████████████████████████████████
08/04/2024 16:33:37 - INFO - llamafactory.model.model_utils.checkpointing - Gradient checkpoint
08/04/2024 16:33:37 - INFO - llamafactory.model.model_utils.attention - Using vanilla attention
08/04/2024 16:33:37 - INFO - llamafactory.model.adapter - ZeRO3 / FSDP detected, remaining trai
08/04/2024 16:33:37 - INFO - llamafactory.model.adapter - Fine-tuning method: LoRA
Loading checkpoint shards: 100%|███████████████████████████████████████████████████████████████
08/04/2024 16:33:37 - INFO - llamafactory.model.model_utils.checkpointing - Gradient checkpoint
08/04/2024 16:33:37 - INFO - llamafactory.model.model_utils.attention - Using vanilla attention
08/04/2024 16:33:37 - INFO - llamafactory.model.adapter - ZeRO3 / FSDP detected, remaining trai
08/04/2024 16:33:37 - INFO - llamafactory.model.adapter - Fine-tuning method: LoRA
08/04/2024 16:33:37 - INFO - llamafactory.model.model_utils.checkpointing - Gradient checkpoint
08/04/2024 16:33:37 - INFO - llamafactory.model.model_utils.attention - Using vanilla attention
08/04/2024 16:33:37 - INFO - llamafactory.model.adapter - ZeRO3 / FSDP detected, remaining trai
08/04/2024 16:33:37 - INFO - llamafactory.model.adapter - Fine-tuning method: LoRA
Loading checkpoint shards: 100%|███████████████████████████████████████████████████████████████
[INFO|modeling_utils.py:4463] 2024-08-04 16:33:40,310 >> All model checkpoint weights were used
[INFO|modeling_utils.py:4471] 2024-08-04 16:33:40,310 >> All the weights of LlamaForCausalLM we
If your task is similar to the task the model of the checkpoint was trained on, you can already
[INFO|configuration_utils.py:991] 2024-08-04 16:33:40,317 >> loading configuration file models/
[INFO|configuration_utils.py:1038] 2024-08-04 16:33:40,317 >> Generate config GenerationConfig
"bos_token_id": 128000,
"eos_token_id": 128001
}
08/04/2024 16:33:40 - INFO - llamafactory.model.model_utils.checkpointing - Gradient checkpoint
08/04/2024 16:33:40 - INFO - llamafactory.model.model_utils.attention - Using vanilla attention
08/04/2024 16:33:40 - INFO - llamafactory.model.adapter - ZeRO3 / FSDP detected, remaining trai
08/04/2024 16:33:40 - INFO - llamafactory.model.adapter - Fine-tuning method: LoRA
08/04/2024 16:33:40 - INFO - llamafactory.model.loader - trainable params: 16,384,000 || all pa
08/04/2024 16:33:40 - INFO - llamafactory.model.loader - trainable params: 16,384,000 || all pa
08/04/2024 16:33:40 - INFO - llamafactory.model.loader - trainable params: 16,384,000 || all pa
08/04/2024 16:33:40 - INFO - llamafactory.model.loader - trainable params: 16,384,000 || all pa
Detected kernel version 3.10.0, which is below the recommended minimum of 5.5.0; this can cause.
[INFO|trainer.py:648] 2024-08-04 16:33:40,641 >> Using auto half precision backend
08/04/2024 16:33:40 - WARNING - llamafactory.train.callbacks - Previous trainer log in this fol
[2024-08-04 16:33:40,949] [INFO] [logging.py:96:log_dist] [Rank 0] DeepSpeed info: version=0.12
I0804 16:33:40.972015 217827 ProcessGroupNCCL.cpp:686] [Rank 2] ProcessGroupNCCL initializationING_WAIT: 0, TIMEOUT(ms): 1800000, USE_HIGH_PRIORITY_STREAM: 0, TORCH_DISTRIBUTED_DEBUG: OFF, N
I0804 16:33:40.973978 217826 ProcessGroupNCCL.cpp:686] [Rank 1] ProcessGroupNCCL initializationING_WAIT: 0, TIMEOUT(ms): 1800000, USE_HIGH_PRIORITY_STREAM: 0, TORCH_DISTRIBUTED_DEBUG: OFF, N
I0804 16:33:40.976128 217828 ProcessGroupNCCL.cpp:686] [Rank 3] ProcessGroupNCCL initializationING_WAIT: 0, TIMEOUT(ms): 1800000, USE_HIGH_PRIORITY_STREAM: 0, TORCH_DISTRIBUTED_DEBUG: OFF, N
I0804 16:33:40.994406 217825 ProcessGroupNCCL.cpp:686] [Rank 0] ProcessGroupNCCL initializationING_WAIT: 0, TIMEOUT(ms): 1800000, USE_HIGH_PRIORITY_STREAM: 0, TORCH_DISTRIBUTED_DEBUG: OFF, N
[2024-08-04 16:33:40,994] [INFO] [logging.py:96:log_dist] [Rank 0] DeepSpeed Flops Profiler Ena
[2024-08-04 16:33:40,999] [INFO] [logging.py:96:log_dist] [Rank 0] Using client Optimizer as ba
[2024-08-04 16:33:40,999] [INFO] [logging.py:96:log_dist] [Rank 0] Removing param_group that ha
[2024-08-04 16:33:41,033] [INFO] [logging.py:96:log_dist] [Rank 0] DeepSpeed Basic Optimizer =
[2024-08-04 16:33:41,033] [INFO] [utils.py:56:is_zero_supported_optimizer] Checking ZeRO suppor
[2024-08-04 16:33:41,033] [INFO] [logging.py:96:log_dist] [Rank 0] Creating fp16 ZeRO stage 3 o
[2024-08-04 16:33:41,034] [INFO] [logging.py:96:log_dist] [Rank 0] Creating torch.bfloat16 ZeRO
[2024-08-04 16:33:41,237] [INFO] [utils.py:802:see_memory_usage] Stage 3 initialize beginning
[2024-08-04 16:33:41,238] [INFO] [utils.py:803:see_memory_usage] MA 32.88 GB Max_MA 38.
[2024-08-04 16:33:41,241] [INFO] [utils.py:810:see_memory_usage] CPU Virtual Memory: used = 11
[2024-08-04 16:33:41,250] [INFO] [stage3.py:127:__init__] Reduce bucket size 67108864
[2024-08-04 16:33:41,250] [INFO] [stage3.py:128:__init__] Prefetch bucket size 60397977
[2024-08-04 16:33:41,454] [INFO] [utils.py:802:see_memory_usage] DeepSpeedZeRoOffload initializ
[2024-08-04 16:33:41,455] [INFO] [utils.py:803:see_memory_usage] MA 32.88 GB Max_MA 32.
[2024-08-04 16:33:41,457] [INFO] [utils.py:810:see_memory_usage] CPU Virtual Memory: used = 11
Parameter Offload: Total persistent parameters: 17702912 in 481 params
[2024-08-04 16:33:41,878] [INFO] [utils.py:802:see_memory_usage] DeepSpeedZeRoOffload initializ
[2024-08-04 16:33:41,878] [INFO] [utils.py:803:see_memory_usage] MA 32.86 GB Max_MA 32.
[2024-08-04 16:33:41,881] [INFO] [utils.py:810:see_memory_usage] CPU Virtual Memory: used = 11
[2024-08-04 16:33:42,100] [INFO] [utils.py:802:see_memory_usage] Before creating fp16 partition
[2024-08-04 16:33:42,101] [INFO] [utils.py:803:see_memory_usage] MA 32.86 GB Max_MA 32.
[2024-08-04 16:33:42,103] [INFO] [utils.py:810:see_memory_usage] CPU Virtual Memory: used = 11
[2024-08-04 16:33:42,557] [INFO] [utils.py:802:see_memory_usage] After creating fp16 partitions
[2024-08-04 16:33:42,558] [INFO] [utils.py:803:see_memory_usage] MA 32.86 GB Max_MA 32.
[2024-08-04 16:33:42,560] [INFO] [utils.py:810:see_memory_usage] CPU Virtual Memory: used = 11
[2024-08-04 16:33:42,779] [INFO] [utils.py:802:see_memory_usage] Before creating fp32 partition
[2024-08-04 16:33:42,779] [INFO] [utils.py:803:see_memory_usage] MA 32.86 GB Max_MA 32.
[2024-08-04 16:33:42,782] [INFO] [utils.py:810:see_memory_usage] CPU Virtual Memory: used = 11
[2024-08-04 16:33:43,000] [INFO] [utils.py:802:see_memory_usage] After creating fp32 partitions
[2024-08-04 16:33:43,001] [INFO] [utils.py:803:see_memory_usage] MA 32.88 GB Max_MA 32.
[2024-08-04 16:33:43,003] [INFO] [utils.py:810:see_memory_usage] CPU Virtual Memory: used = 11
[2024-08-04 16:33:43,246] [INFO] [utils.py:802:see_memory_usage] Before initializing optimizer
[2024-08-04 16:33:43,247] [INFO] [utils.py:803:see_memory_usage] MA 32.88 GB Max_MA 32.
[2024-08-04 16:33:43,249] [INFO] [utils.py:810:see_memory_usage] CPU Virtual Memory: used = 11
[2024-08-04 16:33:43,535] [INFO] [utils.py:802:see_memory_usage] After initializing optimizer s
[2024-08-04 16:33:43,536] [INFO] [utils.py:803:see_memory_usage] MA 32.91 GB Max_MA 32.
[2024-08-04 16:33:43,538] [INFO] [utils.py:810:see_memory_usage] CPU Virtual Memory: used = 11
[2024-08-04 16:33:43,539] [INFO] [stage3.py:479:_setup_for_real_optimizer] optimizer state init
[2024-08-04 16:33:43,913] [INFO] [utils.py:802:see_memory_usage] After initializing ZeRO optimi
[2024-08-04 16:33:43,914] [INFO] [utils.py:803:see_memory_usage] MA 33.04 GB Max_MA 33.
[2024-08-04 16:33:43,916] [INFO] [utils.py:810:see_memory_usage] CPU Virtual Memory: used = 11
[2024-08-04 16:33:43,916] [INFO] [logging.py:96:log_dist] [Rank 0] DeepSpeed Final Optimizer =
[2024-08-04 16:33:43,916] [INFO] [logging.py:96:log_dist] [Rank 0] DeepSpeed using client LR sc
[2024-08-04 16:33:43,917] [INFO] [logging.py:96:log_dist] [Rank 0] DeepSpeed LR Scheduler = Non
[2024-08-04 16:33:43,917] [INFO] [logging.py:96:log_dist] [Rank 0] step=0, skipped=0, lr=[0.0],
[2024-08-04 16:33:43,922] [INFO] [config.py:974:print] DeepSpeedEngine configuration:
[2024-08-04 16:33:43,922] [INFO] [config.py:978:print] activation_checkpointing_config {
"partition_activations": false,
"contiguous_memory_optimization": false,
"cpu_checkpointing": false,
"number_checkpoints": null,
"synchronize_checkpoint_boundary": false,
"profile": false
}
[2024-08-04 16:33:43,922] [INFO] [config.py:978:print] aio_config ................... {'block: True}
[2024-08-04 16:33:43,923] [INFO] [config.py:978:print] amp_enabled .................. False
[2024-08-04 16:33:43,923] [INFO] [config.py:978:print] amp_params ................... False
[2024-08-04 16:33:43,923] [INFO] [config.py:978:print] autotuning_config ............ {
"enabled": false,
"start_step": null,
"end_step": null,
"metric_path": null,
"arg_mappings": null,
"metric": "throughput",
"model_info": null,
"results_dir": "autotuning_results",
"exps_dir": "autotuning_exps",
"overwrite": true,
"fast": true,
"start_profile_step": 3,
"end_profile_step": 5,
"tuner_type": "gridsearch",
"tuner_early_stopping": 5,
"tuner_num_trials": 50,
"model_info_path": null,
"mp_size": 1,
"max_train_batch_size": null,
"min_train_batch_size": 1,
"max_train_micro_batch_size_per_gpu": 1.024000e+03,
"min_train_micro_batch_size_per_gpu": 1,
"num_tuning_micro_batch_sizes": 3
}
[2024-08-04 16:33:43,923] [INFO] [config.py:978:print] bfloat16_enabled ............. True
[2024-08-04 16:33:43,923] [INFO] [config.py:978:print] checkpoint_parallel_write_pipeline Fa
[2024-08-04 16:33:43,923] [INFO] [config.py:978:print] checkpoint_tag_validation_enabled Tru
[2024-08-04 16:33:43,923] [INFO] [config.py:978:print] checkpoint_tag_validation_fail False
[2024-08-04 16:33:43,923] [INFO] [config.py:978:print] comms_config ................. <deepsp
[2024-08-04 16:33:43,923] [INFO] [config.py:978:print] communication_data_type ...... None
[2024-08-04 16:33:43,923] [INFO] [config.py:978:print] compression_config ........... {'weigh_offset': 0, 'quantize_groups': 1, 'quantize_verbose': False, 'quantization_type': 'symmetric',antize_change_ratio': 0.001}, 'different_groups': {}}, 'activation_quantization': {'shared_para'schedule_offset': 1000}, 'different_groups': {}}, 'sparse_pruning': {'shared_parameters': {'en': {'shared_parameters': {'enabled': False, 'method': 'l1', 'schedule_offset': 1000}, 'differenhedule_offset': 1000}, 'different_groups': {}}, 'channel_pruning': {'shared_parameters': {'enabon': {'enabled': False}}
[2024-08-04 16:33:43,924] [INFO] [config.py:978:print] curriculum_enabled_legacy .... False
[2024-08-04 16:33:43,924] [INFO] [config.py:978:print] curriculum_params_legacy ..... False
[2024-08-04 16:33:43,924] [INFO] [config.py:978:print] data_efficiency_config ....... {'enabl': 0, 'curriculum_learning': {'enabled': False}}, 'data_routing': {'enabled': False, 'random_lt
[2024-08-04 16:33:43,924] [INFO] [config.py:978:print] data_efficiency_enabled ...... False
[2024-08-04 16:33:43,924] [INFO] [config.py:978:print] dataloader_drop_last ......... False
[2024-08-04 16:33:43,924] [INFO] [config.py:978:print] disable_allgather ............ False
[2024-08-04 16:33:43,924] [INFO] [config.py:978:print] dump_state ................... False
[2024-08-04 16:33:43,924] [INFO] [config.py:978:print] dynamic_loss_scale_args ...... None
[2024-08-04 16:33:43,924] [INFO] [config.py:978:print] eigenvalue_enabled ........... False
[2024-08-04 16:33:43,924] [INFO] [config.py:978:print] eigenvalue_gas_boundary_resolution 1
[2024-08-04 16:33:43,924] [INFO] [config.py:978:print] eigenvalue_layer_name ........ bert.en
[2024-08-04 16:33:43,924] [INFO] [config.py:978:print] eigenvalue_layer_num ......... 0
[2024-08-04 16:33:43,924] [INFO] [config.py:978:print] eigenvalue_max_iter .......... 100
[2024-08-04 16:33:43,924] [INFO] [config.py:978:print] eigenvalue_stability ......... 1e-06
[2024-08-04 16:33:43,924] [INFO] [config.py:978:print] eigenvalue_tol ............... 0.01
[2024-08-04 16:33:43,924] [INFO] [config.py:978:print] eigenvalue_verbose ........... False
[2024-08-04 16:33:43,924] [INFO] [config.py:978:print] elasticity_enabled ........... False
[2024-08-04 16:33:43,924] [INFO] [config.py:978:print] flops_profiler_config ........ {
"enabled": false,
"recompute_fwd_factor": 0.0,
"profile_step": 1,
"module_depth": -1,
"top_modules": 1,
"detailed": true,
"output_file": null
}
[2024-08-04 16:33:43,925] [INFO] [config.py:978:print] fp16_auto_cast ............... None
[2024-08-04 16:33:43,925] [INFO] [config.py:978:print] fp16_enabled ................. False
[2024-08-04 16:33:43,925] [INFO] [config.py:978:print] fp16_master_weights_and_gradients Fal
[2024-08-04 16:33:43,925] [INFO] [config.py:978:print] global_rank .................. 0
[2024-08-04 16:33:43,925] [INFO] [config.py:978:print] grad_accum_dtype ............. None
[2024-08-04 16:33:43,925] [INFO] [config.py:978:print] gradient_accumulation_steps .. 16
[2024-08-04 16:33:43,925] [INFO] [config.py:978:print] gradient_clipping ............ 1.0
[2024-08-04 16:33:43,925] [INFO] [config.py:978:print] gradient_predivide_factor .... 1.0
[2024-08-04 16:33:43,925] [INFO] [config.py:978:print] hybrid_engine ................ enablede tp_gather_partition_size=8
[2024-08-04 16:33:43,925] [INFO] [config.py:978:print] initial_dynamic_scale ........ 1
[2024-08-04 16:33:43,925] [INFO] [config.py:978:print] load_universal_checkpoint .... False
[2024-08-04 16:33:43,925] [INFO] [config.py:978:print] loss_scale ................... 1.0
[2024-08-04 16:33:43,925] [INFO] [config.py:978:print] memory_breakdown ............. False
[2024-08-04 16:33:43,925] [INFO] [config.py:978:print] mics_hierarchial_params_gather False
[2024-08-04 16:33:43,925] [INFO] [config.py:978:print] mics_shard_size .............. -1
[2024-08-04 16:33:43,926] [INFO] [config.py:978:print] monitor_config ............... tensorbConfig(enabled=False, group=None, team=None, project='deepspeed') csv_monitor=CSVConfig(enabled
[2024-08-04 16:33:43,926] [INFO] [config.py:978:print] nebula_config ................ {
"enabled": false,
"persistent_storage_path": null,
"persistent_time_interval": 100,
"num_of_version_in_retention": 2,
"enable_nebula_load": true,
"load_path": null
}
[2024-08-04 16:33:43,926] [INFO] [config.py:978:print] optimizer_legacy_fusion ...... False
[2024-08-04 16:33:43,926] [INFO] [config.py:978:print] optimizer_name ............... None
[2024-08-04 16:33:43,926] [INFO] [config.py:978:print] optimizer_params ............. None
[2024-08-04 16:33:43,926] [INFO] [config.py:978:print] pipeline ..................... {'stageipe_partitioned': True, 'grad_partitioned': True}
[2024-08-04 16:33:43,926] [INFO] [config.py:978:print] pld_enabled .................. False
[2024-08-04 16:33:43,926] [INFO] [config.py:978:print] pld_params ................... False
[2024-08-04 16:33:43,926] [INFO] [config.py:978:print] prescale_gradients ........... False
[2024-08-04 16:33:43,926] [INFO] [config.py:978:print] scheduler_name ............... None
[2024-08-04 16:33:43,926] [INFO] [config.py:978:print] scheduler_params ............. None
[2024-08-04 16:33:43,926] [INFO] [config.py:978:print] seq_parallel_communication_data_type
[2024-08-04 16:33:43,926] [INFO] [config.py:978:print] sparse_attention ............. None
[2024-08-04 16:33:43,926] [INFO] [config.py:978:print] sparse_gradients_enabled ..... False
[2024-08-04 16:33:43,926] [INFO] [config.py:978:print] steps_per_print .............. inf
[2024-08-04 16:33:43,926] [INFO] [config.py:978:print] train_batch_size ............. 128
[2024-08-04 16:33:43,926] [INFO] [config.py:978:print] train_micro_batch_size_per_gpu 2
[2024-08-04 16:33:43,926] [INFO] [config.py:978:print] use_node_local_storage ....... False
[2024-08-04 16:33:43,926] [INFO] [config.py:978:print] wall_clock_breakdown ......... False
[2024-08-04 16:33:43,926] [INFO] [config.py:978:print] weight_quantization_config ... None
[2024-08-04 16:33:43,926] [INFO] [config.py:978:print] world_size ................... 4
[2024-08-04 16:33:43,926] [INFO] [config.py:978:print] zero_allow_untested_optimizer True
[2024-08-04 16:33:43,926] [INFO] [config.py:978:print] zero_config .................. stage=3s=True allgather_bucket_size=500,000,000 overlap_comm=True load_from_fp32_weights=True elastic_ad_param=None cpu_offload_use_pin_memory=None cpu_offload=None prefetch_bucket_size=60397977 pa00000000 max_reuse_distance=1000000000 gather_16bit_weights_on_model_save=True stage3_gather_fpradients=False zero_hpz_partition_size=1 zero_quantized_weights=False zero_quantized_nontrainabther=False memory_efficient_linear=True pipeline_loading_checkpoint=False override_module_apply
[2024-08-04 16:33:43,926] [INFO] [config.py:978:print] zero_enabled ................. True
[2024-08-04 16:33:43,926] [INFO] [config.py:978:print] zero_force_ds_cpu_optimizer .. True
[2024-08-04 16:33:43,926] [INFO] [config.py:978:print] zero_optimization_stage ...... 3
[2024-08-04 16:33:43,927] [INFO] [config.py:964:print_user_config] json = {
"train_batch_size": 128,
"train_micro_batch_size_per_gpu": 2,
"gradient_accumulation_steps": 16,
"gradient_clipping": 1.0,
"zero_allow_untested_optimizer": true,
"fp16": {
"enabled": false,
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"bf16": {
"enabled": true
},
"zero_optimization": {
"stage": 3,
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1.000000e+09,
"reduce_bucket_size": 6.710886e+07,
"stage3_prefetch_bucket_size": 6.039798e+07,
"stage3_param_persistence_threshold": 8.192000e+04,
"stage3_max_live_parameters": 1.000000e+09,
"stage3_max_reuse_distance": 1.000000e+09,
"stage3_gather_16bit_weights_on_model_save": true
},
"steps_per_print": inf
}
[INFO|trainer.py:2134] 2024-08-04 16:33:43,927 >> ***** Running training *****
[INFO|trainer.py:2135] 2024-08-04 16:33:43,927 >> Num examples = 900
[INFO|trainer.py:2136] 2024-08-04 16:33:43,927 >> Num Epochs = 1
[INFO|trainer.py:2137] 2024-08-04 16:33:43,927 >> Instantaneous batch size per device = 2
[INFO|trainer.py:2140] 2024-08-04 16:33:43,927 >> Total train batch size (w. parallel, distri
[INFO|trainer.py:2141] 2024-08-04 16:33:43,927 >> Gradient Accumulation steps = 16
[INFO|trainer.py:2142] 2024-08-04 16:33:43,927 >> Total optimization steps = 7
[INFO|trainer.py:2143] 2024-08-04 16:33:43,933 >> Number of trainable parameters = 16,384,000
0%| I0804 16:35:01.682166 217825 ProcessGroupNCCL.cpp:1340] NCCL_DEBUG: N/A
57%|█████████████████████████████████▋ | 4/7 [52:09<38:56, 778.93s/it]{'loss': 2.5489, 'grad_norm': 0.4693255388026263, 'learning_rate': 1.2500000000000006e-05, 'epoch': 0.71}
100%|█████████████████████████████████████████████████████████| 7/7 [1:30:50<00:00, 775.03s/it][INFO|trainer.py:3503] 2024-08-04 18:06:05,692 >> Saving model checkpoint to saves/llama3-8b/lora/sft/checkpoint-7
[INFO|configuration_utils.py:731] 2024-08-04 18:06:05,718 >> loading configuration file models/Meta-Llama-3-8B-Instruct/config.json
[INFO|configuration_utils.py:800] 2024-08-04 18:06:05,718 >> Model config LlamaConfig {
"architectures": [
"LlamaForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 128000,
"eos_token_id": 128001,
"hidden_act": "silu",
"hidden_size": 8192,
"initializer_range": 0.02,
"intermediate_size": 28672,
"max_position_embeddings": 8192,
"mlp_bias": false,
"model_type": "llama",
"num_attention_heads": 64,
"num_hidden_layers": 80,
"num_key_value_heads": 8,
"pretraining_tp": 1,
"rms_norm_eps": 1e-05,
"rope_scaling": null,
"rope_theta": 500000.0,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.43.3",
"use_cache": true,
"vocab_size": 128256
}
[INFO|tokenization_utils_base.py:2702] 2024-08-04 18:06:05,789 >> tokenizer config file saved in saves/llama3-8b/lora/sft/checkpoint-7/tokenizer_config.json
[INFO|tokenization_utils_base.py:2711] 2024-08-04 18:06:05,791 >> Special tokens file saved in saves/llama3-8b/lora/sft/checkpoint-7/special_tokens_map.json
[2024-08-04 18:06:05,997] [INFO] [logging.py:96:log_dist] [Rank 0] [Torch] Checkpoint global_step7 is about to be saved!
/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/torch/nn/modules/module.py:1879: UserWarning: Positional args are being deprecated, use kwargs instead. Refer to https://pytorch.org/docs/master/generated/torch.nn.Module.html#torch.nn.Module.state_dict for details.
warnings.warn(
/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/torch/nn/modules/module.py:1879: UserWarning: Positional args are being deprecated, use kwargs instead. Refer to https://pytorch.org/docs/master/generated/torch.nn.Module.html#torch.nn.Module.state_dict for details.
warnings.warn(
/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/torch/nn/modules/module.py:1879: UserWarning: Positional args are being deprecated, use kwargs instead. Refer to https://pytorch.org/docs/master/generated/torch.nn.Module.html#torch.nn.Module.state_dict for details.
warnings.warn(
/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/torch/nn/modules/module.py:1879: UserWarning: Positional args are being deprecated, use kwargs instead. Refer to https://pytorch.org/docs/master/generated/torch.nn.Module.html#torch.nn.Module.state_dict for details.
warnings.warn(
[2024-08-04 18:06:06,033] [INFO] [logging.py:96:log_dist] [Rank 0] Saving model checkpoint: saves/llama3-8b/lora/sft/checkpoint-7/global_step7/zero_pp_rank_0_mp_rank_00_model_states.pt
[2024-08-04 18:06:06,033] [INFO] [torch_checkpoint_engine.py:21:save] [Torch] Saving saves/llama3-8b/lora/sft/checkpoint-7/global_step7/zero_pp_rank_0_mp_rank_00_model_states.pt...
[2024-08-04 18:06:14,181] [INFO] [torch_checkpoint_engine.py:23:save] [Torch] Saved saves/llama3-8b/lora/sft/checkpoint-7/global_step7/zero_pp_rank_0_mp_rank_00_model_states.pt.
[2024-08-04 18:06:14,186] [INFO] [torch_checkpoint_engine.py:21:save] [Torch] Saving saves/llama3-8b/lora/sft/checkpoint-7/global_step7/bf16_zero_pp_rank_0_mp_rank_00_optim_states.pt...
[2024-08-04 18:06:14,244] [INFO] [torch_checkpoint_engine.py:23:save] [Torch] Saved saves/llama3-8b/lora/sft/checkpoint-7/global_step7/bf16_zero_pp_rank_0_mp_rank_00_optim_states.pt.
[2024-08-04 18:06:14,246] [INFO] [engine.py:3417:_save_zero_checkpoint] zero checkpoint saved saves/llama3-8b/lora/sft/checkpoint-7/global_step7/bf16_zero_pp_rank_0_mp_rank_00_optim_states.pt
[2024-08-04 18:06:14,295] [INFO] [torch_checkpoint_engine.py:33:commit] [Torch] Checkpoint global_step7 is ready now!
[INFO|trainer.py:2394] 2024-08-04 18:06:14,306 >>
Training completed. Do not forget to share your model on huggingface.co/models =)
{'train_runtime': 5550.3733, 'train_samples_per_second': 0.162, 'train_steps_per_second': 0.001, 'train_loss': 2.529838357652937, 'epoch': 0.99}
100%|█████████████████████████████████████████████████████████| 7/7 [1:32:30<00:00, 792.91s/it]
[INFO|trainer.py:3503] 2024-08-04 18:07:41,020 >> Saving model checkpoint to saves/llama3-8b/lora/sft
[INFO|configuration_utils.py:731] 2024-08-04 18:07:41,043 >> loading configuration file models/Meta-Llama-3-8B-Instruct/config.json
[INFO|configuration_utils.py:800] 2024-08-04 18:07:41,044 >> Model config LlamaConfig {
"architectures": [
"LlamaForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 128000,
"eos_token_id": 128001,
"hidden_act": "silu",
"hidden_size": 8192,
"initializer_range": 0.02,
"intermediate_size": 28672,
"max_position_embeddings": 8192,
"mlp_bias": false,
"model_type": "llama",
"num_attention_heads": 64,
"num_hidden_layers": 80,
"num_key_value_heads": 8,
"pretraining_tp": 1,
"rms_norm_eps": 1e-05,
"rope_scaling": null,
"rope_theta": 500000.0,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.43.3",
"use_cache": true,
"vocab_size": 128256
}
[INFO|tokenization_utils_base.py:2702] 2024-08-04 18:07:41,105 >> tokenizer config file saved in saves/llama3-8b/lora/sft/tokenizer_config.json
[INFO|tokenization_utils_base.py:2711] 2024-08-04 18:07:41,113 >> Special tokens file saved in saves/llama3-8b/lora/sft/special_tokens_map.json
***** train metrics *****
epoch = 0.9912
total_flos = 11588GF
train_loss = 2.5298
train_runtime = 1:32:30.37
train_samples_per_second = 0.162
train_steps_per_second = 0.001
Figure saved at: saves/llama3-8b/lora/sft/training_loss.png
08/04/2024 18:07:48 - WARNING - llamafactory.extras.ploting - No metric eval_loss to plot.
08/04/2024 18:07:48 - WARNING - llamafactory.extras.ploting - No metric eval_accuracy to plot.
[INFO|trainer.py:3819] 2024-08-04 18:07:48,373 >>
***** Running Evaluation *****
[INFO|trainer.py:3821] 2024-08-04 18:07:48,373 >> Num examples = 100
[INFO|trainer.py:3824] 2024-08-04 18:07:48,373 >> Batch size = 1
100%|██████████████████████████████████████████████████████████| 25/25 [09:51<00:00, 23.67s/it]
***** eval metrics *****
epoch = 0.9912
eval_loss = 2.6695
eval_runtime = 0:10:16.56
eval_samples_per_second = 0.162
eval_steps_per_second = 0.041
[INFO|modelcard.py:449] 2024-08-04 18:18:04,958 >> Dropping the following result as it does not have all the necessary fields:
{'task': {'name': 'Causal Language Modeling', 'type': 'text-generation'}}
微调结束后,得到新的模型权重文件:
(llama_factory_torch) root@notebook-1813389960667746306-scnlbe5oi5-12495:/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory# tree -L 3 /public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/saves/llama3-8b/lora/sft/
/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/saves/llama3-8b/lora/sft/
|-- README.md
|-- adapter_config.json
|-- adapter_model.safetensors
|-- all_results.json
|-- checkpoint-120
| |-- README.md
| |-- adapter_config.json
| |-- adapter_model.safetensors
| |-- optimizer.pt
| |-- rng_state_0.pth
| |-- rng_state_1.pth
| |-- rng_state_2.pth
| |-- scheduler.pt
| |-- special_tokens_map.json
| |-- tokenizer.json
| |-- tokenizer_config.json
| |-- trainer_state.json
| `-- training_args.bin
|-- checkpoint-366
| |-- README.md
| |-- adapter_config.json
| |-- adapter_model.safetensors
| |-- optimizer.pt
| |-- rng_state.pth
| |-- scheduler.pt
| |-- special_tokens_map.json
| |-- tokenizer.json
| |-- tokenizer_config.json
| |-- trainer_state.json
| `-- training_args.bin
|-- checkpoint-90
| |-- README.md
| |-- adapter_config.json
| |-- adapter_model.safetensors
| |-- global_step90
| | |-- bf16_zero_pp_rank_0_mp_rank_00_optim_states.pt
| | |-- bf16_zero_pp_rank_1_mp_rank_00_optim_states.pt
| | |-- bf16_zero_pp_rank_2_mp_rank_00_optim_states.pt
| | |-- bf16_zero_pp_rank_3_mp_rank_00_optim_states.pt
| | |-- zero_pp_rank_0_mp_rank_00_model_states.pt
| | |-- zero_pp_rank_1_mp_rank_00_model_states.pt
| | |-- zero_pp_rank_2_mp_rank_00_model_states.pt
| | `-- zero_pp_rank_3_mp_rank_00_model_states.pt
| |-- latest
| |-- rng_state_0.pth
| |-- rng_state_1.pth
| |-- rng_state_2.pth
| |-- rng_state_3.pth
| |-- scheduler.pt
| |-- special_tokens_map.json
| |-- tokenizer.json
| |-- tokenizer_config.json
| |-- trainer_state.json
| |-- training_args.bin
| `-- zero_to_fp32.py
|-- eval_results.json
|-- special_tokens_map.json
|-- tokenizer.json
|-- tokenizer_config.json
|-- train_results.json
|-- trainer_state.json
|-- training_args.bin
`-- training_loss.png
运行时的资源占用情况

6. 合并模型权重
合并模型权重在CPU上进行。将微调后的模型权重文件和此前的原始模型权重文件进行合并,以获得最终的微调模型。
cp examples/merge_lora/llama3_lora_sft.yaml examples/merge_lora/llama3_lora_sft.yaml.bak
修改 examples/merge_lora/llama3_lora_sft.yaml 文件:
### Note: DO NOT use quantized model or quantization_bit when merging lora adapters
### model
# model_name_or_path: meta-llama/Meta-Llama-3-8B-Instruct
# model_name_or_path: LLM-Research/Meta-Llama-3-8B-Instruct
model_name_or_path: models/Meta-Llama-3-8B-Instruct
adapter_name_or_path: saves/llama3-8b/lora/sft
template: llama3
finetuning_type: lora
### export
export_dir: output/llama3_lora_sft
export_size: 2
export_device: cpu
export_legacy_format: false
执行合并
llamafactory-cli export examples/merge_lora/llama3_lora_sft.yaml
(llama_factory_torch) root@notebook-1813389960667746306-scnlbe5oi5-12495:/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory# llamafactory-cli export examples/merge_lora/llama3_lora_sft.yaml
[2024-08-04 18:32:12,686] [INFO] [real_accelerator.py:158:get_accelerator] Setting ds_accelerator to cuda (auto detect)
[INFO|tokenization_auto.py:682] 2024-08-04 18:32:16,059 >> Could not locate the tokenizer configuration file, will try to use the model config instead.
[INFO|configuration_utils.py:731] 2024-08-04 18:32:16,063 >> loading configuration file /public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/models/Meta-Llama-3-8B-Instruct/config.json
[INFO|configuration_utils.py:800] 2024-08-04 18:32:16,064 >> Model config LlamaConfig {
"_name_or_path": "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/models/Meta-Llama-3-8B-Instruct/",
"architectures": [
"LlamaForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 128000,
"eos_token_id": 128001,
"hidden_act": "silu",
"hidden_size": 8192,
"initializer_range": 0.02,
"intermediate_size": 28672,
"max_position_embeddings": 8192,
"mlp_bias": false,
"model_type": "llama",
"num_attention_heads": 64,
"num_hidden_layers": 80,
"num_key_value_heads": 8,
"pretraining_tp": 1,
"rms_norm_eps": 1e-05,
"rope_scaling": null,
"rope_theta": 500000.0,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.43.3",
"use_cache": true,
"vocab_size": 128256
}
[INFO|tokenization_utils_base.py:2287] 2024-08-04 18:32:16,066 >> loading file tokenizer.model
[INFO|tokenization_utils_base.py:2287] 2024-08-04 18:32:16,066 >> loading file tokenizer.json
[INFO|tokenization_utils_base.py:2287] 2024-08-04 18:32:16,066 >> loading file added_tokens.json
[INFO|tokenization_utils_base.py:2287] 2024-08-04 18:32:16,066 >> loading file special_tokens_map.json
[INFO|tokenization_utils_base.py:2287] 2024-08-04 18:32:16,066 >> loading file tokenizer_config.json
[INFO|configuration_utils.py:731] 2024-08-04 18:32:16,067 >> loading configuration file /public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/models/Meta-Llama-3-8B-Instruct/config.json
[INFO|configuration_utils.py:800] 2024-08-04 18:32:16,067 >> Model config LlamaConfig {
"_name_or_path": "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/models/Meta-Llama-3-8B-Instruct/",
"architectures": [
"LlamaForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 128000,
"eos_token_id": 128001,
"hidden_act": "silu",
"hidden_size": 8192,
"initializer_range": 0.02,
"intermediate_size": 28672,
"max_position_embeddings": 8192,
"mlp_bias": false,
"model_type": "llama",
"num_attention_heads": 64,
"num_hidden_layers": 80,
"num_key_value_heads": 8,
"pretraining_tp": 1,
"rms_norm_eps": 1e-05,
"rope_scaling": null,
"rope_theta": 500000.0,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.43.3",
"use_cache": true,
"vocab_size": 128256
}
[WARNING|logging.py:328] 2024-08-04 18:32:16,209 >> You are using the default legacy behaviour of the <class 'transformers.models.llama.tokenization_llama_fast.LlamaTokenizerFast'>. This is expected, and simply means that the `legacy` (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set `legacy=False`. This should only be set if you understand what it means, and thoroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565 - if you loaded a llama tokenizer from a GGUF file you can ignore this message.
[INFO|tokenization_utils_base.py:2533] 2024-08-04 18:32:16,498 >> Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
08/04/2024 18:32:16 - INFO - llamafactory.data.template - Replace eos token: <|eot_id|>
08/04/2024 18:32:16 - INFO - llamafactory.data.template - Add pad token: <|eot_id|>
[INFO|configuration_utils.py:731] 2024-08-04 18:32:16,519 >> loading configuration file /public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/models/Meta-Llama-3-8B-Instruct/config.json
[INFO|configuration_utils.py:800] 2024-08-04 18:32:16,520 >> Model config LlamaConfig {
"_name_or_path": "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/models/Meta-Llama-3-8B-Instruct/",
"architectures": [
"LlamaForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 128000,
"eos_token_id": 128001,
"hidden_act": "silu",
"hidden_size": 8192,
"initializer_range": 0.02,
"intermediate_size": 28672,
"max_position_embeddings": 8192,
"mlp_bias": false,
"model_type": "llama",
"num_attention_heads": 64,
"num_hidden_layers": 80,
"num_key_value_heads": 8,
"pretraining_tp": 1,
"rms_norm_eps": 1e-05,
"rope_scaling": null,
"rope_theta": 500000.0,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.43.3",
"use_cache": true,
"vocab_size": 128256
}
08/04/2024 18:32:16 - INFO - llamafactory.model.patcher - Using KV cache for faster generation.
[INFO|modeling_utils.py:3631] 2024-08-04 18:32:16,548 >> loading weights file /public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/models/Meta-Llama-3-8B-Instruct/model.safetensors.index.json
[INFO|modeling_utils.py:1572] 2024-08-04 18:32:16,553 >> Instantiating LlamaForCausalLM model under default dtype torch.bfloat16.
[INFO|configuration_utils.py:1038] 2024-08-04 18:32:16,554 >> Generate config GenerationConfig {
"bos_token_id": 128000,
"eos_token_id": 128001
}
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 30/30 [00:38<00:00, 1.29s/it]
[INFO|modeling_utils.py:4463] 2024-08-04 18:32:55,856 >> All model checkpoint weights were used when initializing LlamaForCausalLM.
[INFO|modeling_utils.py:4471] 2024-08-04 18:32:55,856 >> All the weights of LlamaForCausalLM were initialized from the model checkpoint at /public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/models/Meta-Llama-3-8B-Instruct/.
If your task is similar to the task the model of the checkpoint was trained on, you can already use LlamaForCausalLM for predictions without further training.
[INFO|configuration_utils.py:991] 2024-08-04 18:32:55,868 >> loading configuration file /public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/models/Meta-Llama-3-8B-Instruct/generation_config.json
[INFO|configuration_utils.py:1038] 2024-08-04 18:32:55,869 >> Generate config GenerationConfig {
"bos_token_id": 128000,
"eos_token_id": 128001
}
08/04/2024 18:32:55 - INFO - llamafactory.model.model_utils.attention - Using vanilla attention implementation.
08/04/2024 18:35:43 - INFO - llamafactory.model.adapter - Merged 1 adapter(s).
08/04/2024 18:35:43 - INFO - llamafactory.model.adapter - Loaded adapter(s): /public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/saves/llama3-8b/lora/sft/
08/04/2024 18:35:43 - INFO - llamafactory.model.loader - all params: 70,553,706,496
08/04/2024 18:35:43 - INFO - llamafactory.train.tuner - Convert model dtype to: torch.bfloat16.
[INFO|configuration_utils.py:472] 2024-08-04 18:35:43,295 >> Configuration saved in /public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/output/llama3_lora_sft/config.json
[INFO|configuration_utils.py:807] 2024-08-04 18:35:43,298 >> Configuration saved in /public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/output/llama3_lora_sft/generation_config.json
[INFO|modeling_utils.py:2763] 2024-08-04 18:43:36,708 >> The model is bigger than the maximum size per checkpoint (2GB) and is going to be split in 82 checkpoint shards. You can find where each parameters has been saved in the index located at /public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/output/llama3_lora_sft/model.safetensors.index.json.
[INFO|tokenization_utils_base.py:2702] 2024-08-04 18:43:36,717 >> tokenizer config file saved in /public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/output/llama3_lora_sft/tokenizer_config.json
[INFO|tokenization_utils_base.py:2711] 2024-08-04 18:43:36,719 >> Special tokens file saved in /public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/output/llama3_lora_sft/special_tokens_map.json
模型权重合并后,得到新的模型权重文件:
(llama_factory_torch) root@notebook-1813389960667746306-scnlbe5oi5-12495:/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory# tree -L 6 models/llama3_lora_sft/
models/llama3_lora_sft/
|-- config.json
|-- generation_config.json
|-- model-00001-of-00009.safetensors
|-- model-00002-of-00009.safetensors
|-- model-00003-of-00009.safetensors
|-- model-00004-of-00009.safetensors
|-- model-00005-of-00009.safetensors
|-- model-00006-of-00009.safetensors
|-- model-00007-of-00009.safetensors
|-- model-00008-of-00009.safetensors
|-- model-00009-of-00009.safetensors
|-- model.safetensors.index.json
|-- special_tokens_map.json
|-- tokenizer.json
`-- tokenizer_config.json
六、FAQ
Q:ImportError: libcuda.so.1: cannot open shared object file: No such file or directory
(llama_factory_torch) root@notebook-1813389960667746306-scnlbe5oi5-20553:/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory# python src/webui.py \
> --model_name_or_path "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/models/Meta-Llama-3-8B-Instruct" \
> --template llama3 \
> --infer_backend vllm \
> --vllm_enforce_eager
No ROCm runtime is found, using ROCM_HOME='/opt/dtk'
/opt/conda/envs/llama3/lib/python3.10/site-packages/torchvision/io/image.py:13: UserWarning: Failed to load image Python extension: 'libc10_hip.so: cannot open shared object file: No such file or directory'If you don't plan on using image functionality from `torchvision.io`, you can ignore this warning. Otherwise, there might be something wrong with your environment. Did you have `libjpeg` or `libpng` installed before building `torchvision` from source?
warn(
[2024-08-02 14:02:58,860] [INFO] [real_accelerator.py:158:get_accelerator] Setting ds_accelerator to cuda (auto detect)
Traceback (most recent call last):
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/webui.py", line 17, in <module>
from llamafactory.webui.interface import create_ui
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/__init__.py", line 38, in <module>
from .cli import VERSION
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/cli.py", line 22, in <module>
from .api.app import run_api
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/api/app.py", line 21, in <module>
from ..chat import ChatModel
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/chat/__init__.py", line 16, in <module>
from .chat_model import ChatModel
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/chat/chat_model.py", line 26, in <module>
from .vllm_engine import VllmEngine
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/chat/vllm_engine.py", line 29, in <module>
from vllm import AsyncEngineArgs, AsyncLLMEngine, RequestOutput, SamplingParams
File "/opt/conda/envs/llama3/lib/python3.10/site-packages/vllm/__init__.py", line 4, in <module>
from vllm.engine.async_llm_engine import AsyncLLMEngine
File "/opt/conda/envs/llama3/lib/python3.10/site-packages/vllm/engine/async_llm_engine.py", line 12, in <module>
from vllm.engine.llm_engine import LLMEngine
File "/opt/conda/envs/llama3/lib/python3.10/site-packages/vllm/engine/llm_engine.py", line 16, in <module>
from vllm.model_executor.model_loader import get_architecture_class_name
File "/opt/conda/envs/llama3/lib/python3.10/site-packages/vllm/model_executor/model_loader.py", line 10, in <module>
from vllm.model_executor.models.llava import LlavaForConditionalGeneration
File "/opt/conda/envs/llama3/lib/python3.10/site-packages/vllm/model_executor/models/llava.py", line 11, in <module>
from vllm.model_executor.layers.activation import get_act_fn
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/vllm/model_executor/layers/activation.py", line 9, in <module>
from vllm._C import ops
ImportError: libcuda.so.1: cannot open shared object file: No such file or directory
(llama_factory_torch) root@notebook-1813389960667746306-scnlbe5oi5-20553:/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory# python
Python 3.10.8 (main, Nov 4 2022, 13:48:29) [GCC 11.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> torch.cuda.is_available()
False
错误原因:当前PyTorch不支持DCU。
解决方法:在光合社区中查询并下载安装PyTorch。以 torch-2.1.0+das1.1.git3ac1bdd.abi1.dtk2404-cp310-cp310-manylinux_2_31_x86_64 为例,尝试安装 torch-2.1.0。
Q: ValueError: When localhost is not accessible, a shareable link must be created. Please set share=True or check your proxy settings to allow access to localhost.
Running on local URL: http://0.0.0.0:7860
Traceback (most recent call last):
File "/public/home/scnlbe5oi5/LLaMA-Factory/src/webui.py", line 27, in <module>
main()
File "/public/home/scnlbe5oi5/LLaMA-Factory/src/webui.py", line 23, in main
create_ui().queue().launch(share=gradio_share, server_name=server_name, inbrowser=True)
File "/opt/conda/envs/llama_factory_torch/lib/python3.11/site-packages/gradio/blocks.py", line 2446, in launch
raise ValueError(
ValueError: When localhost is not accessible, a shareable link must be created. Please set share=True or check your proxy settings to allow access to localhost.
# 解决方法
create_ui(True).queue().launch(share=gradio_share, server_name=server_name, inbrowser=True)
改为
create_ui(True).queue().launch(share=True, server_name=server_name, inbrowser=True)
Q:单卡显存不足
(llama_factory_torch) root@notebook-1813389960667746306-scnlbe5oi5-20553:/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory# ./single_lora_llama3.sh
[2024-08-02 15:22:58,956] [INFO] [real_accelerator.py:158:get_accelerator] Setting ds_accelerator to cuda (auto detect)
08/02/2024 15:23:02 - WARNING - llamafactory.hparams.parser - We recommend enable mixed precision training.
08/02/2024 15:23:02 - INFO - llamafactory.hparams.parser - Process rank: 0, device: cuda:0, n_gpu: 1, distributed training: False, compute dtype: None
[INFO|tokenization_auto.py:682] 2024-08-02 15:23:02,665 >> Could not locate the tokenizer configuration file, will try to use the model config instead.
[INFO|configuration_utils.py:731] 2024-08-02 15:23:02,690 >> loading configuration file /public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/models/Meta-Llama-3-8B-Instruct/config.json
[INFO|configuration_utils.py:800] 2024-08-02 15:23:02,692 >> Model config LlamaConfig {
"_name_or_path": "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/models/Meta-Llama-3-8B-Instruct/",
"architectures": [
"LlamaForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 128000,
"eos_token_id": 128001,
"hidden_act": "silu",
"hidden_size": 8192,
"initializer_range": 0.02,
"intermediate_size": 28672,
"max_position_embeddings": 8192,
"mlp_bias": false,
"model_type": "llama",
"num_attention_heads": 64,
"num_hidden_layers": 80,
"num_key_value_heads": 8,
"pretraining_tp": 1,
"rms_norm_eps": 1e-05,
"rope_scaling": null,
"rope_theta": 500000.0,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.43.3",
"use_cache": true,
"vocab_size": 128256
}
[INFO|tokenization_utils_base.py:2287] 2024-08-02 15:23:02,698 >> loading file tokenizer.model
[INFO|tokenization_utils_base.py:2287] 2024-08-02 15:23:02,698 >> loading file tokenizer.json
[INFO|tokenization_utils_base.py:2287] 2024-08-02 15:23:02,698 >> loading file added_tokens.json
[INFO|tokenization_utils_base.py:2287] 2024-08-02 15:23:02,698 >> loading file special_tokens_map.json
[INFO|tokenization_utils_base.py:2287] 2024-08-02 15:23:02,698 >> loading file tokenizer_config.json
[INFO|configuration_utils.py:731] 2024-08-02 15:23:02,699 >> loading configuration file /public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/models/Meta-Llama-3-8B-Instruct/config.json
[INFO|configuration_utils.py:800] 2024-08-02 15:23:02,699 >> Model config LlamaConfig {
"_name_or_path": "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/models/Meta-Llama-3-8B-Instruct/",
"architectures": [
"LlamaForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 128000,
"eos_token_id": 128001,
"hidden_act": "silu",
"hidden_size": 8192,
"initializer_range": 0.02,
"intermediate_size": 28672,
"max_position_embeddings": 8192,
"mlp_bias": false,
"model_type": "llama",
"num_attention_heads": 64,
"num_hidden_layers": 80,
"num_key_value_heads": 8,
"pretraining_tp": 1,
"rms_norm_eps": 1e-05,
"rope_scaling": null,
"rope_theta": 500000.0,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.43.3",
"use_cache": true,
"vocab_size": 128256
}
[WARNING|logging.py:328] 2024-08-02 15:23:02,907 >> You are using the default legacy behaviour of the <class 'transformers.models.llama.tokenization_llama_fast.LlamaTokenizerFast'>. This is expected, and simply means that the `legacy` (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set `legacy=False`. This should only be set if you understand what it means, and thoroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565 - if you loaded a llama tokenizer from a GGUF file you can ignore this message.
[INFO|tokenization_utils_base.py:2533] 2024-08-02 15:23:03,240 >> Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
08/02/2024 15:23:03 - INFO - llamafactory.data.template - Replace eos token: <|eot_id|>
08/02/2024 15:23:03 - INFO - llamafactory.data.template - Add pad token: <|eot_id|>
08/02/2024 15:23:03 - INFO - llamafactory.data.loader - Loading dataset llamafactory/alpaca_zh...
Downloading readme: 100%|██████████████████████████████████████████████████████████████████████████████████████████| 507/507 [00:00<00:00, 1.98MB/s]
Downloading data: 100%|█████████████████████████████████████████████████████████████████████████████████████████| 18.7M/18.7M [00:52<00:00, 354kB/s]
Generating train split: 51155 examples [00:00, 81737.09 examples/s]
Converting format of dataset: 100%|█████████████████████████████████████████████████████████████████| 51155/51155 [00:00<00:00, 87369.27 examples/s]
Running tokenizer on dataset: 100%|██████████████████████████████████████████████████████████████████| 51155/51155 [00:17<00:00, 2914.66 examples/s]
training example:
input_ids:
[128000, 128006, 882, 128007, 271, 98739, 109425, 19000, 9080, 40053, 104654, 16325, 111689, 83747, 11883, 53610, 11571, 128009, 128006, 78191, 128007, 271, 16, 13, 86758, 56602, 53610, 123128, 116051, 56602, 53610, 85315, 233, 118959, 83601, 115, 65455, 34208, 53610, 104432, 65455, 1811, 720, 17, 13, 86758, 53610, 74396, 58291, 53610, 44559, 114, 51109, 43167, 118006, 123641, 53610, 3922, 78657, 108914, 81802, 245, 34208, 108914, 118959, 1811, 720, 18, 13, 74662, 117481, 16325, 115890, 56602, 53610, 126966, 1811, 720, 19, 13, 111909, 222, 33976, 53610, 36651, 34208, 66285, 234, 36117, 231, 73548, 9554, 118487, 53610, 106041, 91495, 82317, 13646, 23951, 59464, 127150, 1811, 720, 20, 13, 107934, 245, 105444, 94, 21082, 118504, 106649, 3922, 38129, 103167, 111155, 85315, 233, 118959, 65455, 56602, 95337, 11883, 53610, 1811, 720, 21, 13, 114524, 43167, 106786, 53610, 3922, 114593, 106143, 108309, 58291, 93994, 66776, 120522, 11883, 113173, 1811, 720, 22, 13, 20033, 115, 109895, 58291, 125405, 46034, 13646, 30356, 111110, 53610, 104432, 65455, 1811, 720, 23, 13, 66827, 237, 83747, 27699, 229, 53610, 105301, 117027, 9554, 21082, 1811, 720, 24, 13, 59330, 121, 88367, 43240, 30590, 30358, 59464, 38129, 118954, 53610, 10110, 124714, 108914, 105060, 33748, 5486, 118959, 102452, 53610, 101837, 121, 34208, 85315, 233, 118959, 9554, 53610, 75376, 720, 605, 13, 127609, 125025, 126369, 60455, 96455, 45736, 9554, 108914, 81802, 245, 33748, 34208, 108914, 105060, 33748, 1811, 128009]
inputs:
<|begin_of_text|><|start_header_id|>user<|end_header_id|>
我们如何在日常生活中减少用水?<|eot_id|><|start_header_id|>assistant<|end_header_id|>
1. 使用节水装置,如节水淋浴喷头和水龙头。
2. 使用水箱或水桶收集家庭废水,例如洗碗和洗浴。
3. 在社区中提高节水意识。
4. 检查水管和灌溉系统的漏水情况,并及时修复它们。
5. 洗澡时间缩短,使用低流量淋浴头节约用水。
6. 收集雨水,用于园艺或其他非饮用目的。
7. 刷牙或擦手时关掉水龙头。
8. 减少浇水草坪的时间。
9. 尽可能多地重复使用灰水(来自洗衣机、浴室水槽和淋浴的水)。
10. 只购买能源效率高的洗碗机和洗衣机。<|eot_id|>
label_ids:
[-100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, 16, 13, 86758, 56602, 53610, 123128, 116051, 56602, 53610, 85315, 233, 118959, 83601, 115, 65455, 34208, 53610, 104432, 65455, 1811, 720, 17, 13, 86758, 53610, 74396, 58291, 53610, 44559, 114, 51109, 43167, 118006, 123641, 53610, 3922, 78657, 108914, 81802, 245, 34208, 108914, 118959, 1811, 720, 18, 13, 74662, 117481, 16325, 115890, 56602, 53610, 126966, 1811, 720, 19, 13, 111909, 222, 33976, 53610, 36651, 34208, 66285, 234, 36117, 231, 73548, 9554, 118487, 53610, 106041, 91495, 82317, 13646, 23951, 59464, 127150, 1811, 720, 20, 13, 107934, 245, 105444, 94, 21082, 118504, 106649, 3922, 38129, 103167, 111155, 85315, 233, 118959, 65455, 56602, 95337, 11883, 53610, 1811, 720, 21, 13, 114524, 43167, 106786, 53610, 3922, 114593, 106143, 108309, 58291, 93994, 66776, 120522, 11883, 113173, 1811, 720, 22, 13, 20033, 115, 109895, 58291, 125405, 46034, 13646, 30356, 111110, 53610, 104432, 65455, 1811, 720, 23, 13, 66827, 237, 83747, 27699, 229, 53610, 105301, 117027, 9554, 21082, 1811, 720, 24, 13, 59330, 121, 88367, 43240, 30590, 30358, 59464, 38129, 118954, 53610, 10110, 124714, 108914, 105060, 33748, 5486, 118959, 102452, 53610, 101837, 121, 34208, 85315, 233, 118959, 9554, 53610, 75376, 720, 605, 13, 127609, 125025, 126369, 60455, 96455, 45736, 9554, 108914, 81802, 245, 33748, 34208, 108914, 105060, 33748, 1811, 128009]
labels:
1. 使用节水装置,如节水淋浴喷头和水龙头。
2. 使用水箱或水桶收集家庭废水,例如洗碗和洗浴。
3. 在社区中提高节水意识。
4. 检查水管和灌溉系统的漏水情况,并及时修复它们。
5. 洗澡时间缩短,使用低流量淋浴头节约用水。
6. 收集雨水,用于园艺或其他非饮用目的。
7. 刷牙或擦手时关掉水龙头。
8. 减少浇水草坪的时间。
9. 尽可能多地重复使用灰水(来自洗衣机、浴室水槽和淋浴的水)。
10. 只购买能源效率高的洗碗机和洗衣机。<|eot_id|>
[INFO|configuration_utils.py:731] 2024-08-02 15:24:20,727 >> loading configuration file /public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/models/Meta-Llama-3-8B-Instruct/config.json
[INFO|configuration_utils.py:800] 2024-08-02 15:24:20,728 >> Model config LlamaConfig {
"_name_or_path": "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/models/Meta-Llama-3-8B-Instruct/",
"architectures": [
"LlamaForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 128000,
"eos_token_id": 128001,
"hidden_act": "silu",
"hidden_size": 8192,
"initializer_range": 0.02,
"intermediate_size": 28672,
"max_position_embeddings": 8192,
"mlp_bias": false,
"model_type": "llama",
"num_attention_heads": 64,
"num_hidden_layers": 80,
"num_key_value_heads": 8,
"pretraining_tp": 1,
"rms_norm_eps": 1e-05,
"rope_scaling": null,
"rope_theta": 500000.0,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.43.3",
"use_cache": true,
"vocab_size": 128256
}
[INFO|modeling_utils.py:3631] 2024-08-02 15:24:20,758 >> loading weights file /public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/models/Meta-Llama-3-8B-Instruct/model.safetensors.index.json
[INFO|modeling_utils.py:1572] 2024-08-02 15:24:20,824 >> Instantiating LlamaForCausalLM model under default dtype torch.bfloat16.
[INFO|configuration_utils.py:1038] 2024-08-02 15:24:20,825 >> Generate config GenerationConfig {
"bos_token_id": 128000,
"eos_token_id": 128001
}
Loading checkpoint shards: 0%| | 0/30 [00:00<?, ?it/s]Loading checkpoint shards: 47%|███████████████████████████████████████▏ | 14/30 [03:14<03:41, 13.87s/it]
Traceback (most recent call last):
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/train.py", line 28, in <module>
main()
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/train.py", line 19, in main
run_exp()
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/train/tuner.py", line 50, in run_exp
run_sft(model_args, data_args, training_args, finetuning_args, generating_args, callbacks)
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/train/sft/workflow.py", line 47, in run_sft
model = load_model(tokenizer, model_args, finetuning_args, training_args.do_train)
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/model/loader.py", line 153, in load_model
model = AutoModelForCausalLM.from_pretrained(**init_kwargs)
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/models/auto/auto_factory.py", line 564, in from_pretrained
return model_class.from_pretrained(
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/modeling_utils.py", line 3916, in from_pretrained
) = cls._load_pretrained_model(
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/modeling_utils.py", line 4390, in _load_pretrained_model
new_error_msgs, offload_index, state_dict_index = _load_state_dict_into_meta_model(
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/modeling_utils.py", line 936, in _load_state_dict_into_meta_model
set_module_tensor_to_device(model, param_name, param_device, **set_module_kwargs)
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/accelerate/utils/modeling.py", line 404, in set_module_tensor_to_device
new_value = value.to(device)
torch.cuda.OutOfMemoryError: HIP out of memory. Tried to allocate 448.00 MiB. GPU 0 has a total capacty of 63.98 GiB of which 0 bytes is free. Of the allocated memory 63.40 GiB is allocated by PyTorch, and 816.00 KiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_HIP_ALLOC_CONF
错误原因:异构加速卡的显存不足,导致模型加载失败。
解决方法:减小batch_size,或者增加异构加速卡数量。


Q:多卡显存不足
(llama_factory_torch) root@notebook-1813389960667746306-scnlbe5oi5-12495:/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory# torchrun --standalone --nnodes=1 --nproc-per-node=4 src/train.py \
> --stage sft \
> --do_train True \
> --model_name_or_path /public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/models/Meta-Llama-3-8B-Instruct/ \
--output_dir /public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/out> --dataset alpaca_zh \
> --template llama3 \
> --lora_target q_proj,v_proj \
> --output_dir /public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/output \
> --overwrite_cache \
> --per_device_train_batch_size 2 \
> --gradient_accumulation_steps 64 \
> --lr_scheduler_type cosine \
> --logging_steps 5 \
> --save_steps 100 \
> --learning_rate 5e-5 \
> --num_train_epochs 1.0 \
> --finetuning_type lora \
> --lora_rank 4
[2024-08-03 07:36:41,589] torch.distributed.run: [WARNING] master_addr is only used for static rdzv_backend and when rdzv_endpoint is not specified.
[2024-08-03 07:36:41,590] torch.distributed.run: [WARNING]
[2024-08-03 07:36:41,590] torch.distributed.run: [WARNING] *****************************************
[2024-08-03 07:36:41,590] torch.distributed.run: [WARNING] Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
[2024-08-03 07:36:41,590] torch.distributed.run: [WARNING] *****************************************
[2024-08-03 07:36:46,569] [INFO] [real_accelerator.py:158:get_accelerator] Setting ds_accelerator to cuda (auto detect)
[2024-08-03 07:36:46,647] [INFO] [real_accelerator.py:158:get_accelerator] Setting ds_accelerator to cuda (auto detect)
[2024-08-03 07:36:46,649] [INFO] [real_accelerator.py:158:get_accelerator] Setting ds_accelerator to cuda (auto detect)
[2024-08-03 07:36:46,656] [INFO] [real_accelerator.py:158:get_accelerator] Setting ds_accelerator to cuda (auto detect)
WARNING: Logging before InitGoogleLogging() is written to STDERR
I0803 07:36:50.128130 169256 ProcessGroupNCCL.cpp:686] [Rank 1] ProcessGroupNCCL initialization options:NCCL_ASYNC_ERROR_HANDLING: 1, NCCL_DESYNC_DEBUG: 0, NCCL_ENABLE_TIMING: 0, NCCL_BLOCKING_WAIT: 0, TIMEOUT(ms): 1800000, USE_HIGH_PRIORITY_STREAM: 0, TORCH_DISTRIBUTED_DEBUG: OFF, NCCL_DEBUG: OFF, ID=369040736
08/03/2024 07:36:50 - WARNING - llamafactory.hparams.parser - We recommend enable mixed precision training.
08/03/2024 07:36:50 - WARNING - llamafactory.hparams.parser - `ddp_find_unused_parameters` needs to be set as False for LoRA in DDP training.
08/03/2024 07:36:50 - INFO - llamafactory.hparams.parser - Process rank: 1, device: cuda:1, n_gpu: 1, distributed training: True, compute dtype: None
You are using the default legacy behaviour of the <class 'transformers.models.llama.tokenization_llama_fast.LlamaTokenizerFast'>. This is expected, and simply means that the `legacy` (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set `legacy=False`. This should only be set if you understand what it means, and thoroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565 - if you loaded a llama tokenizer from a GGUF file you can ignore this message.
08/03/2024 07:36:50 - INFO - llamafactory.data.template - Replace eos token: <|eot_id|>
08/03/2024 07:36:50 - INFO - llamafactory.data.template - Add pad token: <|eot_id|>
I0803 07:36:50.887167 169256 ProcessGroupNCCL.cpp:2780] Rank 1 using GPU 1 to perform barrier as devices used by this process are currently unknown. This can potentially cause a hang if this rank to GPU mapping is incorrect.Specify device_ids in barrier() to force use of a particular device.
WARNING: Logging before InitGoogleLogging() is written to STDERR
I0803 07:36:50.981253 169258 ProcessGroupNCCL.cpp:686] [Rank 3] ProcessGroupNCCL initialization options:NCCL_ASYNC_ERROR_HANDLING: 1, NCCL_DESYNC_DEBUG: 0, NCCL_ENABLE_TIMING: 0, NCCL_BLOCKING_WAIT: 0, TIMEOUT(ms): 1800000, USE_HIGH_PRIORITY_STREAM: 0, TORCH_DISTRIBUTED_DEBUG: OFF, NCCL_DEBUG: OFF, ID=371077680
08/03/2024 07:36:50 - WARNING - llamafactory.hparams.parser - We recommend enable mixed precision training.
08/03/2024 07:36:50 - WARNING - llamafactory.hparams.parser - `ddp_find_unused_parameters` needs to be set as False for LoRA in DDP training.
08/03/2024 07:36:50 - INFO - llamafactory.hparams.parser - Process rank: 3, device: cuda:3, n_gpu: 1, distributed training: True, compute dtype: None
WARNING: Logging before InitGoogleLogging() is written to STDERR
I0803 07:36:50.989648 169257 ProcessGroupNCCL.cpp:686] [Rank 2] ProcessGroupNCCL initialization options:NCCL_ASYNC_ERROR_HANDLING: 1, NCCL_DESYNC_DEBUG: 0, NCCL_ENABLE_TIMING: 0, NCCL_BLOCKING_WAIT: 0, TIMEOUT(ms): 1800000, USE_HIGH_PRIORITY_STREAM: 0, TORCH_DISTRIBUTED_DEBUG: OFF, NCCL_DEBUG: OFF, ID=360123488
WARNING: Logging before InitGoogleLogging() is written to STDERR
I0803 07:36:50.994580 169255 ProcessGroupNCCL.cpp:686] [Rank 0] ProcessGroupNCCL initialization options:NCCL_ASYNC_ERROR_HANDLING: 1, NCCL_DESYNC_DEBUG: 0, NCCL_ENABLE_TIMING: 0, NCCL_BLOCKING_WAIT: 0, TIMEOUT(ms): 1800000, USE_HIGH_PRIORITY_STREAM: 0, TORCH_DISTRIBUTED_DEBUG: OFF, NCCL_DEBUG: OFF, ID=380578768
08/03/2024 07:36:50 - WARNING - llamafactory.hparams.parser - We recommend enable mixed precision training.
08/03/2024 07:36:50 - WARNING - llamafactory.hparams.parser - `ddp_find_unused_parameters` needs to be set as False for LoRA in DDP training.
08/03/2024 07:36:50 - INFO - llamafactory.hparams.parser - Process rank: 2, device: cuda:2, n_gpu: 1, distributed training: True, compute dtype: None
08/03/2024 07:36:51 - WARNING - llamafactory.hparams.parser - We recommend enable mixed precision training.
08/03/2024 07:36:51 - WARNING - llamafactory.hparams.parser - `ddp_find_unused_parameters` needs to be set as False for LoRA in DDP training.
08/03/2024 07:36:51 - INFO - llamafactory.hparams.parser - Process rank: 0, device: cuda:0, n_gpu: 1, distributed training: True, compute dtype: None
[INFO|tokenization_auto.py:682] 2024-08-03 07:36:51,003 >> Could not locate the tokenizer configuration file, will try to use the model config instead.
[INFO|configuration_utils.py:731] 2024-08-03 07:36:51,003 >> loading configuration file /public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/models/Meta-Llama-3-8B-Instruct/config.json
[INFO|configuration_utils.py:800] 2024-08-03 07:36:51,004 >> Model config LlamaConfig {
"_name_or_path": "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/models/Meta-Llama-3-8B-Instruct/",
"architectures": [
"LlamaForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 128000,
"eos_token_id": 128001,
"hidden_act": "silu",
"hidden_size": 8192,
"initializer_range": 0.02,
"intermediate_size": 28672,
"max_position_embeddings": 8192,
"mlp_bias": false,
"model_type": "llama",
"num_attention_heads": 64,
"num_hidden_layers": 80,
"num_key_value_heads": 8,
"pretraining_tp": 1,
"rms_norm_eps": 1e-05,
"rope_scaling": null,
"rope_theta": 500000.0,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.43.3",
"use_cache": true,
"vocab_size": 128256
}
[INFO|tokenization_utils_base.py:2287] 2024-08-03 07:36:51,008 >> loading file tokenizer.model
[INFO|tokenization_utils_base.py:2287] 2024-08-03 07:36:51,008 >> loading file tokenizer.json
[INFO|tokenization_utils_base.py:2287] 2024-08-03 07:36:51,008 >> loading file added_tokens.json
[INFO|tokenization_utils_base.py:2287] 2024-08-03 07:36:51,008 >> loading file special_tokens_map.json
[INFO|tokenization_utils_base.py:2287] 2024-08-03 07:36:51,008 >> loading file tokenizer_config.json
[INFO|configuration_utils.py:731] 2024-08-03 07:36:51,008 >> loading configuration file /public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/models/Meta-Llama-3-8B-Instruct/config.json
[INFO|configuration_utils.py:800] 2024-08-03 07:36:51,009 >> Model config LlamaConfig {
"_name_or_path": "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/models/Meta-Llama-3-8B-Instruct/",
"architectures": [
"LlamaForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 128000,
"eos_token_id": 128001,
"hidden_act": "silu",
"hidden_size": 8192,
"initializer_range": 0.02,
"intermediate_size": 28672,
"max_position_embeddings": 8192,
"mlp_bias": false,
"model_type": "llama",
"num_attention_heads": 64,
"num_hidden_layers": 80,
"num_key_value_heads": 8,
"pretraining_tp": 1,
"rms_norm_eps": 1e-05,
"rope_scaling": null,
"rope_theta": 500000.0,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.43.3",
"use_cache": true,
"vocab_size": 128256
}
You are using the default legacy behaviour of the <class 'transformers.models.llama.tokenization_llama_fast.LlamaTokenizerFast'>. This is expected, and simply means that the `legacy` (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set `legacy=False`. This should only be set if you understand what it means, and thoroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565 - if you loaded a llama tokenizer from a GGUF file you can ignore this message.
You are using the default legacy behaviour of the <class 'transformers.models.llama.tokenization_llama_fast.LlamaTokenizerFast'>. This is expected, and simply means that the `legacy` (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set `legacy=False`. This should only be set if you understand what it means, and thoroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565 - if you loaded a llama tokenizer from a GGUF file you can ignore this message.
[WARNING|logging.py:328] 2024-08-03 07:36:51,135 >> You are using the default legacy behaviour of the <class 'transformers.models.llama.tokenization_llama_fast.LlamaTokenizerFast'>. This is expected, and simply means that the `legacy` (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set `legacy=False`. This should only be set if you understand what it means, and thoroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565 - if you loaded a llama tokenizer from a GGUF file you can ignore this message.
08/03/2024 07:36:51 - INFO - llamafactory.data.template - Replace eos token: <|eot_id|>
08/03/2024 07:36:51 - INFO - llamafactory.data.template - Add pad token: <|eot_id|>
[INFO|tokenization_utils_base.py:2533] 2024-08-03 07:36:51,399 >> Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
08/03/2024 07:36:51 - INFO - llamafactory.data.template - Replace eos token: <|eot_id|>
08/03/2024 07:36:51 - INFO - llamafactory.data.template - Add pad token: <|eot_id|>
08/03/2024 07:36:51 - INFO - llamafactory.data.template - Replace eos token: <|eot_id|>
08/03/2024 07:36:51 - INFO - llamafactory.data.template - Add pad token: <|eot_id|>
08/03/2024 07:36:51 - INFO - llamafactory.data.loader - Loading dataset llamafactory/alpaca_zh...
I0803 07:36:51.659898 169258 ProcessGroupNCCL.cpp:2780] Rank 3 using GPU 3 to perform barrier as devices used by this process are currently unknown. This can potentially cause a hang if this rank to GPU mapping is incorrect.Specify device_ids in barrier() to force use of a particular device.
I0803 07:36:51.715169 169257 ProcessGroupNCCL.cpp:2780] Rank 2 using GPU 2 to perform barrier as devices used by this process are currently unknown. This can potentially cause a hang if this rank to GPU mapping is incorrect.Specify device_ids in barrier() to force use of a particular device.
Converting format of dataset: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████| 51155/51155 [00:01<00:00, 45265.18 examples/s]
I0803 07:36:57.874289 169255 ProcessGroupNCCL.cpp:2780] Rank 0 using GPU 0 to perform barrier as devices used by this process are currently unknown. This can potentially cause a hang if this rank to GPU mapping is incorrect.Specify device_ids in barrier() to force use of a particular device.
I0803 07:36:58.349363 169255 ProcessGroupNCCL.cpp:1340] NCCL_DEBUG: N/A
08/03/2024 07:36:58 - INFO - llamafactory.data.loader - Loading dataset llamafactory/alpaca_zh...
08/03/2024 07:36:58 - INFO - llamafactory.data.loader - Loading dataset llamafactory/alpaca_zh...
08/03/2024 07:36:58 - INFO - llamafactory.data.loader - Loading dataset llamafactory/alpaca_zh...
Running tokenizer on dataset: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████| 51155/51155 [00:17<00:00, 2973.65 examples/s]
training example:
input_ids:
[128000, 128006, 882, 128007, 271, 98739, 109425, 19000, 9080, 40053, 104654, 16325, 111689, 83747, 11883, 53610, 11571, 128009, 128006, 78191, 128007, 271, 16, 13, 86758, 56602, 53610, 123128, 116051, 56602, 53610, 85315, 233, 118959, 83601, 115, 65455, 34208, 53610, 104432, 65455, 1811, 720, 17, 13, 86758, 53610, 74396, 58291, 53610, 44559, 114, 51109, 43167, 118006, 123641, 53610, 3922, 78657, 108914, 81802, 245, 34208, 108914, 118959, 1811, 720, 18, 13, 74662, 117481, 16325, 115890, 56602, 53610, 126966, 1811, 720, 19, 13, 111909, 222, 33976, 53610, 36651, 34208, 66285, 234, 36117, 231, 73548, 9554, 118487, 53610, 106041, 91495, 82317, 13646, 23951, 59464, 127150, 1811, 720, 20, 13, 107934, 245, 105444, 94, 21082, 118504, 106649, 3922, 38129, 103167, 111155, 85315, 233, 118959, 65455, 56602, 95337, 11883, 53610, 1811, 720, 21, 13, 114524, 43167, 106786, 53610, 3922, 114593, 106143, 108309, 58291, 93994, 66776, 120522, 11883, 113173, 1811, 720, 22, 13, 20033, 115, 109895, 58291, 125405, 46034, 13646, 30356, 111110, 53610, 104432, 65455, 1811, 720, 23, 13, 66827, 237, 83747, 27699, 229, 53610, 105301, 117027, 9554, 21082, 1811, 720, 24, 13, 59330, 121, 88367, 43240, 30590, 30358, 59464, 38129, 118954, 53610, 10110, 124714, 108914, 105060, 33748, 5486, 118959, 102452, 53610, 101837, 121, 34208, 85315, 233, 118959, 9554, 53610, 75376, 720, 605, 13, 127609, 125025, 126369, 60455, 96455, 45736, 9554, 108914, 81802, 245, 33748, 34208, 108914, 105060, 33748, 1811, 128009]
inputs:
<|begin_of_text|><|start_header_id|>user<|end_header_id|>
我们如何在日常生活中减少用水?<|eot_id|><|start_header_id|>assistant<|end_header_id|>
1. 使用节水装置,如节水淋浴喷头和水龙头。
2. 使用水箱或水桶收集家庭废水,例如洗碗和洗浴。
3. 在社区中提高节水意识。
4. 检查水管和灌溉系统的漏水情况,并及时修复它们。
5. 洗澡时间缩短,使用低流量淋浴头节约用水。
6. 收集雨水,用于园艺或其他非饮用目的。
7. 刷牙或擦手时关掉水龙头。
8. 减少浇水草坪的时间。
9. 尽可能多地重复使用灰水(来自洗衣机、浴室水槽和淋浴的水)。
10. 只购买能源效率高的洗碗机和洗衣机。<|eot_id|>
label_ids:
[-100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, 16, 13, 86758, 56602, 53610, 123128, 116051, 56602, 53610, 85315, 233, 118959, 83601, 115, 65455, 34208, 53610, 104432, 65455, 1811, 720, 17, 13, 86758, 53610, 74396, 58291, 53610, 44559, 114, 51109, 43167, 118006, 123641, 53610, 3922, 78657, 108914, 81802, 245, 34208, 108914, 118959, 1811, 720, 18, 13, 74662, 117481, 16325, 115890, 56602, 53610, 126966, 1811, 720, 19, 13, 111909, 222, 33976, 53610, 36651, 34208, 66285, 234, 36117, 231, 73548, 9554, 118487, 53610, 106041, 91495, 82317, 13646, 23951, 59464, 127150, 1811, 720, 20, 13, 107934, 245, 105444, 94, 21082, 118504, 106649, 3922, 38129, 103167, 111155, 85315, 233, 118959, 65455, 56602, 95337, 11883, 53610, 1811, 720, 21, 13, 114524, 43167, 106786, 53610, 3922, 114593, 106143, 108309, 58291, 93994, 66776, 120522, 11883, 113173, 1811, 720, 22, 13, 20033, 115, 109895, 58291, 125405, 46034, 13646, 30356, 111110, 53610, 104432, 65455, 1811, 720, 23, 13, 66827, 237, 83747, 27699, 229, 53610, 105301, 117027, 9554, 21082, 1811, 720, 24, 13, 59330, 121, 88367, 43240, 30590, 30358, 59464, 38129, 118954, 53610, 10110, 124714, 108914, 105060, 33748, 5486, 118959, 102452, 53610, 101837, 121, 34208, 85315, 233, 118959, 9554, 53610, 75376, 720, 605, 13, 127609, 125025, 126369, 60455, 96455, 45736, 9554, 108914, 81802, 245, 33748, 34208, 108914, 105060, 33748, 1811, 128009]
labels:
1. 使用节水装置,如节水淋浴喷头和水龙头。
2. 使用水箱或水桶收集家庭废水,例如洗碗和洗浴。
3. 在社区中提高节水意识。
4. 检查水管和灌溉系统的漏水情况,并及时修复它们。
5. 洗澡时间缩短,使用低流量淋浴头节约用水。
6. 收集雨水,用于园艺或其他非饮用目的。
7. 刷牙或擦手时关掉水龙头。
8. 减少浇水草坪的时间。
9. 尽可能多地重复使用灰水(来自洗衣机、浴室水槽和淋浴的水)。
10. 只购买能源效率高的洗碗机和洗衣机。<|eot_id|>
[INFO|configuration_utils.py:731] 2024-08-03 07:37:15,793 >> loading configuration file /public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/models/Meta-Llama-3-8B-Instruct/config.json
[INFO|configuration_utils.py:800] 2024-08-03 07:37:15,794 >> Model config LlamaConfig {
"_name_or_path": "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/models/Meta-Llama-3-8B-Instruct/",
"architectures": [
"LlamaForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 128000,
"eos_token_id": 128001,
"hidden_act": "silu",
"hidden_size": 8192,
"initializer_range": 0.02,
"intermediate_size": 28672,
"max_position_embeddings": 8192,
"mlp_bias": false,
"model_type": "llama",
"num_attention_heads": 64,
"num_hidden_layers": 80,
"num_key_value_heads": 8,
"pretraining_tp": 1,
"rms_norm_eps": 1e-05,
"rope_scaling": null,
"rope_theta": 500000.0,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.43.3",
"use_cache": true,
"vocab_size": 128256
}
[INFO|modeling_utils.py:3631] 2024-08-03 07:37:15,822 >> loading weights file /public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/models/Meta-Llama-3-8B-Instruct/model.safetensors.index.json
[INFO|modeling_utils.py:1572] 2024-08-03 07:37:15,823 >> Instantiating LlamaForCausalLM model under default dtype torch.bfloat16.
[INFO|configuration_utils.py:1038] 2024-08-03 07:37:15,824 >> Generate config GenerationConfig {
"bos_token_id": 128000,
"eos_token_id": 128001
}
Loading checkpoint shards: 47%|██████████████████████████████████████████████████████████▎ | 14/30 [06:13<07:07, 26.71s/it]
Traceback (most recent call last):
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/train.py", line 28, in <module>
Loading checkpoint shards: 47%|██████████████████████████████████████████████████████████▎ | 14/30 [06:14<07:07, 26.73s/it]
Traceback (most recent call last):
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/train.py", line 28, in <module>
Loading checkpoint shards: 47%|██████████████████████████████████████████████████████████▎ | 14/30 [06:13<07:07, 26.71s/it]
Traceback (most recent call last):
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/train.py", line 28, in <module>
Loading checkpoint shards: 47%|██████████████████████████████████████████████████████████▎ | 14/30 [06:13<07:07, 26.71s/it]
Traceback (most recent call last):
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/train.py", line 28, in <module>
main()
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/train.py", line 19, in main
main()
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/train.py", line 19, in main
main()
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/train.py", line 19, in main
run_exp()
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/train/tuner.py", line 50, in run_exp
main()
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/train.py", line 19, in main
run_exp()run_exp()
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/train/tuner.py", line 50, in run_exp
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/train/tuner.py", line 50, in run_exp
run_sft(model_args, data_args, training_args, finetuning_args, generating_args, callbacks) run_exp()
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/train/sft/workflow.py", line 47, in run_sft
run_sft(model_args, data_args, training_args, finetuning_args, generating_args, callbacks)
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/train/sft/workflow.py", line 47, in run_sft
run_sft(model_args, data_args, training_args, finetuning_args, generating_args, callbacks) model = load_model(tokenizer, model_args, finetuning_args, training_args.do_train)
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/model/loader.py", line 153, in load_model
model = load_model(tokenizer, model_args, finetuning_args, training_args.do_train)
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/model/loader.py", line 153, in load_model
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/train/sft/workflow.py", line 47, in run_sft
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/train/tuner.py", line 50, in run_exp
run_sft(model_args, data_args, training_args, finetuning_args, generating_args, callbacks)
model = load_model(tokenizer, model_args, finetuning_args, training_args.do_train)
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/model/loader.py", line 153, in load_model
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/train/sft/workflow.py", line 47, in run_sft
model = load_model(tokenizer, model_args, finetuning_args, training_args.do_train)
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/model/loader.py", line 153, in load_model
model = AutoModelForCausalLM.from_pretrained(**init_kwargs)
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/models/auto/auto_factory.py", line 564, in from_pretrained
model = AutoModelForCausalLM.from_pretrained(**init_kwargs)
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/models/auto/auto_factory.py", line 564, in from_pretrained
model = AutoModelForCausalLM.from_pretrained(**init_kwargs)
model = AutoModelForCausalLM.from_pretrained(**init_kwargs) File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/models/auto/auto_factory.py", line 564, in from_pretrained
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/models/auto/auto_factory.py", line 564, in from_pretrained
return model_class.from_pretrained(
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/modeling_utils.py", line 3916, in from_pretrained
return model_class.from_pretrained(
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/modeling_utils.py", line 3916, in from_pretrained
return model_class.from_pretrained(
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/modeling_utils.py", line 3916, in from_pretrained
return model_class.from_pretrained(
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/modeling_utils.py", line 3916, in from_pretrained
) = cls._load_pretrained_model(
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/modeling_utils.py", line 4390, in _load_pretrained_model
) = cls._load_pretrained_model(
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/modeling_utils.py", line 4390, in _load_pretrained_model
) = cls._load_pretrained_model(
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/modeling_utils.py", line 4390, in _load_pretrained_model
) = cls._load_pretrained_model(
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/modeling_utils.py", line 4390, in _load_pretrained_model
new_error_msgs, offload_index, state_dict_index = _load_state_dict_into_meta_model(
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/modeling_utils.py", line 936, in _load_state_dict_into_meta_model
new_error_msgs, offload_index, state_dict_index = _load_state_dict_into_meta_model(
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/modeling_utils.py", line 936, in _load_state_dict_into_meta_model
new_error_msgs, offload_index, state_dict_index = _load_state_dict_into_meta_model(new_error_msgs, offload_index, state_dict_index = _load_state_dict_into_meta_model(
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/modeling_utils.py", line 936, in _load_state_dict_into_meta_model
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/modeling_utils.py", line 936, in _load_state_dict_into_meta_model
set_module_tensor_to_device(model, param_name, param_device, **set_module_kwargs)
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/accelerate/utils/modeling.py", line 404, in set_module_tensor_to_device
set_module_tensor_to_device(model, param_name, param_device, **set_module_kwargs)
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/accelerate/utils/modeling.py", line 404, in set_module_tensor_to_device
new_value = value.to(device)
torch.cuda.OutOfMemoryError: HIP out of memory. Tried to allocate 448.00 MiB. GPU 3 has a total capacty of 63.98 GiB of which 0 bytes is free. Of the allocated memory 63.40 GiB is allocated by PyTorch, and 815.50 KiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_HIP_ALLOC_CONF
set_module_tensor_to_device(model, param_name, param_device, **set_module_kwargs)
set_module_tensor_to_device(model, param_name, param_device, **set_module_kwargs) File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/accelerate/utils/modeling.py", line 404, in set_module_tensor_to_device
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/accelerate/utils/modeling.py", line 404, in set_module_tensor_to_device
new_value = value.to(device)
torch.cuda.OutOfMemoryError: HIP out of memory. Tried to allocate 448.00 MiB. GPU 1 has a total capacty of 63.98 GiB of which 0 bytes is free. Of the allocated memory 63.40 GiB is allocated by PyTorch, and 815.50 KiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_HIP_ALLOC_CONF
new_value = value.to(device)
new_value = value.to(device)
torch.cuda.OutOfMemoryError: HIP out of memory. Tried to allocate 448.00 MiB. GPU 2 has a total capacty of 63.98 GiB of which 0 bytes is free. Of the allocated memory 63.40 GiB is allocated by PyTorch, and 815.50 KiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_HIP_ALLOC_CONF
torch.cuda.OutOfMemoryError: HIP out of memory. Tried to allocate 448.00 MiB. GPU 0 has a total capacty of 63.98 GiB of which 0 bytes is free. Of the allocated memory 63.40 GiB is allocated by PyTorch, and 815.50 KiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_HIP_ALLOC_CONF
[2024-08-03 07:43:37,156] torch.distributed.elastic.multiprocessing.api: [ERROR] failed (exitcode: 1) local_rank: 0 (pid: 169255) of binary: /opt/conda/envs/llama_factory_torch/bin/python
Traceback (most recent call last):
File "/opt/conda/envs/llama_factory_torch/bin/torchrun", line 8, in <module>
sys.exit(main())
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/torch/distributed/elastic/multiprocessing/errors/__init__.py", line 346, in wrapper
return f(*args, **kwargs)
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/torch/distributed/run.py", line 806, in main
run(args)
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/torch/distributed/run.py", line 797, in run
elastic_launch(
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/torch/distributed/launcher/api.py", line 134, in __call__
return launch_agent(self._config, self._entrypoint, list(args))
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/torch/distributed/launcher/api.py", line 264, in launch_agent
raise ChildFailedError(
torch.distributed.elastic.multiprocessing.errors.ChildFailedError:
============================================================
src/train.py FAILED
------------------------------------------------------------
Failures:
[1]:
time : 2024-08-03_07:43:37
host : notebook-1813389960667746306-scnlbe5oi5-12495
rank : 1 (local_rank: 1)
exitcode : 1 (pid: 169256)
error_file: <N/A>
traceback : To enable traceback see: https://pytorch.org/docs/stable/elastic/errors.html
[2]:
time : 2024-08-03_07:43:37
host : notebook-1813389960667746306-scnlbe5oi5-12495
rank : 2 (local_rank: 2)
exitcode : 1 (pid: 169257)
error_file: <N/A>
traceback : To enable traceback see: https://pytorch.org/docs/stable/elastic/errors.html
[3]:
time : 2024-08-03_07:43:37
host : notebook-1813389960667746306-scnlbe5oi5-12495
rank : 3 (local_rank: 3)
exitcode : 1 (pid: 169258)
error_file: <N/A>
traceback : To enable traceback see: https://pytorch.org/docs/stable/elastic/errors.html
------------------------------------------------------------
Root Cause (first observed failure):
[0]:
time : 2024-08-03_07:43:37
host : notebook-1813389960667746306-scnlbe5oi5-12495
rank : 0 (local_rank: 0)
exitcode : 1 (pid: 169255)
error_file: <N/A>
traceback : To enable traceback see: https://pytorch.org/docs/stable/elastic/errors.html
============================================================

错误原因:LLaMA-Factory 支持 DDP , DeepSpeed 和 FSDP 三种分布式引擎。其中,DDP引擎不支持模型切分,每张卡都加载一份模型,导致显存不足。
| 引擎 | 数据切分 | 模型切分 | 优化器切分 | 参数卸载 |
|---|---|---|---|---|
| DDP | 支持 | 不支持 | 不支持 | 不支持 |
| DeepSpeed | 支持 | 支持 | 支持 | 支持 |
| FSDP | 支持 | 支持 | 支持 | 支持 |
解决方法:采用DeepSpeed 或者 FSDP引擎进行分布式训练。
Q:ValueError: Please launch distributed training with llamafactory-cli or torchrun.
(llama_factory_torch) root@notebook-1819291427828183041-scnlbe5oi5-51898:/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory# ./single_lora_llama3.sh
[2024-08-02 16:55:03,538] [INFO] [real_accelerator.py:158:get_accelerator] Setting ds_accelerator to cuda (auto detect)
Traceback (most recent call last):
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/train.py", line 28, in <module>
main()
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/train.py", line 19, in main
run_exp()
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/train/tuner.py", line 45, in run_exp
model_args, data_args, training_args, finetuning_args, generating_args = get_train_args(args)
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/hparams/parser.py", line 195, in get_train_args
raise ValueError("Please launch distributed training with `llamafactory-cli` or `torchrun`.")
ValueError: Please launch distributed training with `llamafactory-cli` or `torchrun`.
错误原因:多卡的服务器环境中,默认使用多卡,该脚本不支持多卡运行。
解决方法:使用单卡运行。
CUDA_VISIBLE_DEVICES=0 ./single_lora_llama3.sh
Q:RuntimeError: Failed to import modelscope.msdatasets because of the following error (look up to see its traceback): No module named 'oss2'
(llama_factory_torch) root@notebook-1813389960667746306-scnlbe5oi5-12495:/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory# FORCE_TORCHRUN=1 llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml
[2024-08-04 09:24:42,724] [INFO] [real_accelerator.py:158:get_accelerator] Setting ds_accelerator to cuda (auto detect)
08/04/2024 09:24:45 - INFO - llamafactory.cli - Initializing distributed tasks at: 127.0.0.1:24626
[2024-08-04 09:24:47,796] torch.distributed.run: [WARNING]
[2024-08-04 09:24:47,796] torch.distributed.run: [WARNING] *****************************************
[2024-08-04 09:24:47,796] torch.distributed.run: [WARNING] Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
[2024-08-04 09:24:47,796] torch.distributed.run: [WARNING] *****************************************
[2024-08-04 09:24:52,280] [INFO] [real_accelerator.py:158:get_accelerator] Setting ds_accelerator to cuda (auto detect)
[2024-08-04 09:24:52,298] [INFO] [real_accelerator.py:158:get_accelerator] Setting ds_accelerator to cuda (auto detect)
[2024-08-04 09:24:52,462] [INFO] [real_accelerator.py:158:get_accelerator] Setting ds_accelerator to cuda (auto detect)
[2024-08-04 09:24:52,612] [INFO] [real_accelerator.py:158:get_accelerator] Setting ds_accelerator to cuda (auto detect)
[2024-08-04 09:24:55,341] [INFO] [comm.py:637:init_distributed] cdb=None
WARNING: Logging before InitGoogleLogging() is written to STDERR
I0804 09:24:55.342823 38022 ProcessGroupNCCL.cpp:686] [Rank 2] ProcessGroupNCCL initialization options:NCCL_ASYNC_ERROR_HANDLING: 1, NCCL_DESYNC_DEBUG: 0, NCCL_ENABLE_TIMING: 0, NCCL_BLOCKING_WAIT: 0, TIMEOUT(ms): 180000000000, USE_HIGH_PRIORITY_STREAM: 0, TORCH_DISTRIBUTED_DEBUG: OFF, NCCL_DEBUG: OFF, ID=374876544
08/04/2024 09:24:55 - WARNING - llamafactory.hparams.parser - `ddp_find_unused_parameters` needs to be set as False for LoRA in DDP training.
08/04/2024 09:24:55 - INFO - llamafactory.hparams.parser - Process rank: 2, device: cuda:2, n_gpu: 1, distributed training: True, compute dtype: torch.bfloat16
[2024-08-04 09:24:55,492] [INFO] [comm.py:637:init_distributed] cdb=None
WARNING: Logging before InitGoogleLogging() is written to STDERR
I0804 09:24:55.493716 38021 ProcessGroupNCCL.cpp:686] [Rank 1] ProcessGroupNCCL initialization options:NCCL_ASYNC_ERROR_HANDLING: 1, NCCL_DESYNC_DEBUG: 0, NCCL_ENABLE_TIMING: 0, NCCL_BLOCKING_WAIT: 0, TIMEOUT(ms): 180000000000, USE_HIGH_PRIORITY_STREAM: 0, TORCH_DISTRIBUTED_DEBUG: OFF, NCCL_DEBUG: OFF, ID=357873744
08/04/2024 09:24:55 - WARNING - llamafactory.hparams.parser - `ddp_find_unused_parameters` needs to be set as False for LoRA in DDP training.
08/04/2024 09:24:55 - INFO - llamafactory.hparams.parser - Process rank: 1, device: cuda:1, n_gpu: 1, distributed training: True, compute dtype: torch.bfloat16
[2024-08-04 09:24:55,594] [INFO] [comm.py:637:init_distributed] cdb=None
WARNING: Logging before InitGoogleLogging() is written to STDERR
I0804 09:24:55.595580 38023 ProcessGroupNCCL.cpp:686] [Rank 3] ProcessGroupNCCL initialization options:NCCL_ASYNC_ERROR_HANDLING: 1, NCCL_DESYNC_DEBUG: 0, NCCL_ENABLE_TIMING: 0, NCCL_BLOCKING_WAIT: 0, TIMEOUT(ms): 180000000000, USE_HIGH_PRIORITY_STREAM: 0, TORCH_DISTRIBUTED_DEBUG: OFF, NCCL_DEBUG: OFF, ID=381227184
08/04/2024 09:24:55 - WARNING - llamafactory.hparams.parser - `ddp_find_unused_parameters` needs to be set as False for LoRA in DDP training.
08/04/2024 09:24:55 - INFO - llamafactory.hparams.parser - Process rank: 3, device: cuda:3, n_gpu: 1, distributed training: True, compute dtype: torch.bfloat16
[2024-08-04 09:24:55,753] [INFO] [comm.py:637:init_distributed] cdb=None
[2024-08-04 09:24:55,753] [INFO] [comm.py:668:init_distributed] Initializing TorchBackend in DeepSpeed with backend nccl
WARNING: Logging before InitGoogleLogging() is written to STDERR
I0804 09:24:55.755142 38020 ProcessGroupNCCL.cpp:686] [Rank 0] ProcessGroupNCCL initialization options:NCCL_ASYNC_ERROR_HANDLING: 1, NCCL_DESYNC_DEBUG: 0, NCCL_ENABLE_TIMING: 0, NCCL_BLOCKING_WAIT: 0, TIMEOUT(ms): 180000000000, USE_HIGH_PRIORITY_STREAM: 0, TORCH_DISTRIBUTED_DEBUG: OFF, NCCL_DEBUG: OFF, ID=372711472
08/04/2024 09:24:55 - WARNING - llamafactory.hparams.parser - `ddp_find_unused_parameters` needs to be set as False for LoRA in DDP training.
08/04/2024 09:24:55 - INFO - llamafactory.hparams.parser - Process rank: 0, device: cuda:0, n_gpu: 1, distributed training: True, compute dtype: torch.bfloat16
2024-08-04 09:24:55,854 - modelscope - WARNING - Using branch: master as version is unstable, use with caution
2024-08-04 09:24:55,960 - modelscope - WARNING - Using branch: master as version is unstable, use with caution
2024-08-04 09:24:56,206 - modelscope - WARNING - Using branch: master as version is unstable, use with caution
2024-08-04 09:24:56,383 - modelscope - WARNING - Using branch: master as version is unstable, use with caution
08/04/2024 09:24:56 - INFO - llamafactory.data.template - Replace eos token: <|eot_id|>
08/04/2024 09:24:56 - INFO - llamafactory.data.template - Add pad token: <|eot_id|>
[INFO|tokenization_utils_base.py:2287] 2024-08-04 09:24:56,643 >> loading file tokenizer.json
[INFO|tokenization_utils_base.py:2287] 2024-08-04 09:24:56,643 >> loading file added_tokens.json
[INFO|tokenization_utils_base.py:2287] 2024-08-04 09:24:56,643 >> loading file special_tokens_map.json
[INFO|tokenization_utils_base.py:2287] 2024-08-04 09:24:56,643 >> loading file tokenizer_config.json
08/04/2024 09:24:56 - INFO - llamafactory.data.template - Replace eos token: <|eot_id|>
08/04/2024 09:24:56 - INFO - llamafactory.data.template - Add pad token: <|eot_id|>
08/04/2024 09:24:56 - INFO - llamafactory.data.template - Replace eos token: <|eot_id|>
08/04/2024 09:24:56 - INFO - llamafactory.data.template - Add pad token: <|eot_id|>
I0804 09:24:56.879868 38021 ProcessGroupNCCL.cpp:2780] Rank 1 using GPU 1 to perform barrier as devices used by this process are currently unknown. This can potentially cause a hang if this rank to GPU mapping is incorrect.Specify device_ids in barrier() to force use of a particular device.
[INFO|tokenization_utils_base.py:2533] 2024-08-04 09:24:56,942 >> Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
08/04/2024 09:24:56 - INFO - llamafactory.data.template - Replace eos token: <|eot_id|>
08/04/2024 09:24:56 - INFO - llamafactory.data.template - Add pad token: <|eot_id|>
08/04/2024 09:24:56 - INFO - llamafactory.data.loader - Loading dataset llamafactory/alpaca_zh...
I0804 09:24:56.954972 38022 ProcessGroupNCCL.cpp:2780] Rank 2 using GPU 2 to perform barrier as devices used by this process are currently unknown. This can potentially cause a hang if this rank to GPU mapping is incorrect.Specify device_ids in barrier() to force use of a particular device.
I0804 09:24:57.078207 38023 ProcessGroupNCCL.cpp:2780] Rank 3 using GPU 3 to perform barrier as devices used by this process are currently unknown. This can potentially cause a hang if this rank to GPU mapping is incorrect.Specify device_ids in barrier() to force use of a particular device.
I0804 09:24:57.246373 38020 ProcessGroupNCCL.cpp:2780] Rank 0 using GPU 0 to perform barrier as devices used by this process are currently unknown. This can potentially cause a hang if this rank to GPU mapping is incorrect.Specify device_ids in barrier() to force use of a particular device.
I0804 09:24:57.975442 38020 ProcessGroupNCCL.cpp:1340] NCCL_DEBUG: N/A
Traceback (most recent call last):
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/utils/import_utils.py", line 451, in _get_module
return importlib.import_module('.' + module_name, self.__name__)
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/importlib/__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 1050, in _gcd_import
File "<frozen importlib._bootstrap>", line 1027, in _find_and_load
File "<frozen importlib._bootstrap>", line 1006, in _find_and_load_unlocked
08/04/2024 09:24:58 - INFO - llamafactory.data.loader - Loading dataset llamafactory/alpaca_zh...
File "<frozen importlib._bootstrap>", line 688, in _load_unlocked
08/04/2024 09:24:58 - INFO - llamafactory.data.loader - Loading dataset llamafactory/alpaca_zh...
File "<frozen importlib._bootstrap_external>", line 883, in exec_module
File "<frozen importlib._bootstrap>", line 241, in _call_with_frames_removed
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/msdatasets/__init__.py", line 2, in <module>
from modelscope.msdatasets.ms_dataset import MsDataset
08/04/2024 09:24:58 - INFO - llamafactory.data.loader - Loading dataset llamafactory/alpaca_zh...
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/msdatasets/ms_dataset.py", line 16, in <module>
from modelscope.msdatasets.data_loader.data_loader_manager import (
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/msdatasets/data_loader/data_loader_manager.py", line 12, in <module>
from modelscope.msdatasets.data_loader.data_loader import OssDownloader
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/msdatasets/data_loader/data_loader.py", line 15, in <module>
from modelscope.msdatasets.data_files.data_files_manager import \
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/msdatasets/data_files/data_files_manager.py", line 11, in <module>
from modelscope.msdatasets.download.dataset_builder import (
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/msdatasets/download/dataset_builder.py", line 24, in <module>
from modelscope.msdatasets.download.download_manager import \
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/msdatasets/download/download_manager.py", line 9, in <module>
from modelscope.msdatasets.utils.oss_utils import OssUtilities
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/msdatasets/utils/oss_utils.py", line 7, in <module>
import oss2
ModuleNotFoundError: No module named 'oss2'
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/launcher.py", line 23, in <module>
launch()
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/launcher.py", line 19, in launch
run_exp()
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/train/tuner.py", line 50, in run_exp
run_sft(model_args, data_args, training_args, finetuning_args, generating_args, callbacks)
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/train/sft/workflow.py", line 46, in run_sft
dataset_module = get_dataset(model_args, data_args, training_args, stage="sft", **tokenizer_module)
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/data/loader.py", line 233, in get_dataset
dataset = _get_merged_dataset(data_args.dataset, model_args, data_args, training_args, stage)
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/data/loader.py", line 153, in _get_merged_dataset
datasets.append(_load_single_dataset(dataset_attr, model_args, data_args, training_args))
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/data/loader.py", line 87, in _load_single_dataset
from modelscope import MsDataset
File "<frozen importlib._bootstrap>", line 1075, in _handle_fromlist
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/utils/import_utils.py", line 434, in __getattr__
module = self._get_module(self._class_to_module[name])
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/utils/import_utils.py", line 453, in _get_module
raise RuntimeError(
RuntimeError: Failed to import modelscope.msdatasets because of the following error (look up to see its traceback):
No module named 'oss2'
Traceback (most recent call last):
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/utils/import_utils.py", line 451, in _get_module
return importlib.import_module('.' + module_name, self.__name__)
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/importlib/__init__.py", line 126, in import_module
Traceback (most recent call last):
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/utils/import_utils.py", line 451, in _get_module
return _bootstrap._gcd_import(name[level:], package, level) return importlib.import_module('.' + module_name, self.__name__)
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/importlib/__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 1050, in _gcd_import
File "<frozen importlib._bootstrap>", line 1050, in _gcd_import
File "<frozen importlib._bootstrap>", line 1027, in _find_and_load
File "<frozen importlib._bootstrap>", line 1027, in _find_and_load
File "<frozen importlib._bootstrap>", line 1006, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 1006, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 688, in _load_unlocked
File "<frozen importlib._bootstrap>", line 688, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 883, in exec_module
File "<frozen importlib._bootstrap_external>", line 883, in exec_module
File "<frozen importlib._bootstrap>", line 241, in _call_with_frames_removed
File "<frozen importlib._bootstrap>", line 241, in _call_with_frames_removed
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/msdatasets/__init__.py", line 2, in <module>
from modelscope.msdatasets.ms_dataset import MsDataset
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/msdatasets/ms_dataset.py", line 16, in <module>
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/msdatasets/__init__.py", line 2, in <module>
from modelscope.msdatasets.data_loader.data_loader_manager import (
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/msdatasets/data_loader/data_loader_manager.py", line 12, in <module>
Traceback (most recent call last):
from modelscope.msdatasets.ms_dataset import MsDataset
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/msdatasets/ms_dataset.py", line 16, in <module>
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/utils/import_utils.py", line 451, in _get_module
from modelscope.msdatasets.data_loader.data_loader import OssDownloader
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/msdatasets/data_loader/data_loader.py", line 15, in <module>
from modelscope.msdatasets.data_loader.data_loader_manager import (
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/msdatasets/data_loader/data_loader_manager.py", line 12, in <module>
from modelscope.msdatasets.data_files.data_files_manager import \
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/msdatasets/data_files/data_files_manager.py", line 11, in <module>
from modelscope.msdatasets.data_loader.data_loader import OssDownloader
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/msdatasets/data_loader/data_loader.py", line 15, in <module>
from modelscope.msdatasets.download.dataset_builder import (
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/msdatasets/download/dataset_builder.py", line 24, in <module>
from modelscope.msdatasets.data_files.data_files_manager import \
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/msdatasets/data_files/data_files_manager.py", line 11, in <module>
from modelscope.msdatasets.download.download_manager import \
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/msdatasets/download/download_manager.py", line 9, in <module>
from modelscope.msdatasets.download.dataset_builder import ( return importlib.import_module('.' + module_name, self.__name__)
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/msdatasets/download/dataset_builder.py", line 24, in <module>
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/importlib/__init__.py", line 126, in import_module
from modelscope.msdatasets.utils.oss_utils import OssUtilities
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/msdatasets/utils/oss_utils.py", line 7, in <module>
from modelscope.msdatasets.download.download_manager import \
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/msdatasets/download/download_manager.py", line 9, in <module>
from modelscope.msdatasets.utils.oss_utils import OssUtilitiesreturn _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 1050, in _gcd_import
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/msdatasets/utils/oss_utils.py", line 7, in <module>
import oss2
ModuleNotFoundError: No module named 'oss2'
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/launcher.py", line 23, in <module>
File "<frozen importlib._bootstrap>", line 1027, in _find_and_load
File "<frozen importlib._bootstrap>", line 1006, in _find_and_load_unlocked
import oss2
ModuleNotFoundError: launch()
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/launcher.py", line 19, in launch
run_exp()
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/train/tuner.py", line 50, in run_exp
No module named 'oss2'
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/launcher.py", line 23, in <module>
File "<frozen importlib._bootstrap>", line 688, in _load_unlocked
run_sft(model_args, data_args, training_args, finetuning_args, generating_args, callbacks)
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/train/sft/workflow.py", line 46, in run_sft
launch()
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/launcher.py", line 19, in launch
File "<frozen importlib._bootstrap_external>", line 883, in exec_module
run_exp()
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/train/tuner.py", line 50, in run_exp
dataset_module = get_dataset(model_args, data_args, training_args, stage="sft", **tokenizer_module)
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/data/loader.py", line 233, in get_dataset
File "<frozen importlib._bootstrap>", line 241, in _call_with_frames_removed
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/msdatasets/__init__.py", line 2, in <module>
run_sft(model_args, data_args, training_args, finetuning_args, generating_args, callbacks)
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/train/sft/workflow.py", line 46, in run_sft
from modelscope.msdatasets.ms_dataset import MsDataset
dataset = _get_merged_dataset(data_args.dataset, model_args, data_args, training_args, stage) File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/msdatasets/ms_dataset.py", line 16, in <module>
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/data/loader.py", line 153, in _get_merged_dataset
from modelscope.msdatasets.data_loader.data_loader_manager import (
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/msdatasets/data_loader/data_loader_manager.py", line 12, in <module>
from modelscope.msdatasets.data_loader.data_loader import OssDownloader
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/msdatasets/data_loader/data_loader.py", line 15, in <module>
dataset_module = get_dataset(model_args, data_args, training_args, stage="sft", **tokenizer_module) datasets.append(_load_single_dataset(dataset_attr, model_args, data_args, training_args))
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/data/loader.py", line 87, in _load_single_dataset
from modelscope import MsDataset
File "<frozen importlib._bootstrap>", line 1075, in _handle_fromlist
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/data/loader.py", line 233, in get_dataset
from modelscope.msdatasets.data_files.data_files_manager import \
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/msdatasets/data_files/data_files_manager.py", line 11, in <module>
from modelscope.msdatasets.download.dataset_builder import ( File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/utils/import_utils.py", line 434, in __getattr__
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/msdatasets/download/dataset_builder.py", line 24, in <module>
from modelscope.msdatasets.download.download_manager import \
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/msdatasets/download/download_manager.py", line 9, in <module>
from modelscope.msdatasets.utils.oss_utils import OssUtilities
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/msdatasets/utils/oss_utils.py", line 7, in <module>
dataset = _get_merged_dataset(data_args.dataset, model_args, data_args, training_args, stage)module = self._get_module(self._class_to_module[name])
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/data/loader.py", line 153, in _get_merged_dataset
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/utils/import_utils.py", line 453, in _get_module
import oss2
ModuleNotFoundError: No module named 'oss2'
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/launcher.py", line 23, in <module>
raise RuntimeError(
RuntimeError: Failed to import modelscope.msdatasets because of the following error (look up to see its traceback):
No module named 'oss2'
datasets.append(_load_single_dataset(dataset_attr, model_args, data_args, training_args))
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/data/loader.py", line 87, in _load_single_dataset
from modelscope import MsDataset
File "<frozen importlib._bootstrap>", line 1075, in _handle_fromlist
launch()
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/launcher.py", line 19, in launch
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/utils/import_utils.py", line 434, in __getattr__
run_exp()
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/train/tuner.py", line 50, in run_exp
module = self._get_module(self._class_to_module[name])
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/utils/import_utils.py", line 453, in _get_module
raise RuntimeError(
RuntimeError: Failed to import modelscope.msdatasets because of the following error (look up to see its traceback):
No module named 'oss2'
run_sft(model_args, data_args, training_args, finetuning_args, generating_args, callbacks)
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/train/sft/workflow.py", line 46, in run_sft
dataset_module = get_dataset(model_args, data_args, training_args, stage="sft", **tokenizer_module)
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/data/loader.py", line 233, in get_dataset
dataset = _get_merged_dataset(data_args.dataset, model_args, data_args, training_args, stage)
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/data/loader.py", line 153, in _get_merged_dataset
datasets.append(_load_single_dataset(dataset_attr, model_args, data_args, training_args))
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/data/loader.py", line 87, in _load_single_dataset
from modelscope import MsDataset
File "<frozen importlib._bootstrap>", line 1075, in _handle_fromlist
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/utils/import_utils.py", line 434, in __getattr__
module = self._get_module(self._class_to_module[name])
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/modelscope/utils/import_utils.py", line 453, in _get_module
raise RuntimeError(
RuntimeError: Failed to import modelscope.msdatasets because of the following error (look up to see its traceback):
No module named 'oss2'
I0804 09:24:58.887567 38023 ProcessGroupNCCL.cpp:874] [Rank 3] Destroyed 1communicators on CUDA device 3
I0804 09:24:58.909525 38022 ProcessGroupNCCL.cpp:874] [Rank 2] Destroyed 1communicators on CUDA device 2
I0804 09:24:58.909849 38020 ProcessGroupNCCL.cpp:874] [Rank 0] Destroyed 1communicators on CUDA device 0
I0804 09:24:59.381202 38021 ProcessGroupNCCL.cpp:874] [Rank 1] Destroyed 1communicators on CUDA device 1
[2024-08-04 09:25:02,912] torch.distributed.elastic.multiprocessing.api: [WARNING] Sending process 38020 closing signal SIGTERM
[2024-08-04 09:25:02,912] torch.distributed.elastic.multiprocessing.api: [WARNING] Sending process 38021 closing signal SIGTERM
[2024-08-04 09:25:03,077] torch.distributed.elastic.multiprocessing.api: [ERROR] failed (exitcode: 1) local_rank: 2 (pid: 38022) of binary: /opt/conda/envs/llama_factory_torch/bin/python
Traceback (most recent call last):
File "/opt/conda/envs/llama_factory_torch/bin/torchrun", line 8, in <module>
sys.exit(main())
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/torch/distributed/elastic/multiprocessing/errors/__init__.py", line 346, in wrapper
return f(*args, **kwargs)
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/torch/distributed/run.py", line 806, in main
run(args)
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/torch/distributed/run.py", line 797, in run
elastic_launch(
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/torch/distributed/launcher/api.py", line 134, in __call__
return launch_agent(self._config, self._entrypoint, list(args))
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/torch/distributed/launcher/api.py", line 264, in launch_agent
raise ChildFailedError(
torch.distributed.elastic.multiprocessing.errors.ChildFailedError:
============================================================
/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/launcher.py FAILED
------------------------------------------------------------
Failures:
[1]:
time : 2024-08-04_09:25:02
host : notebook-1813389960667746306-scnlbe5oi5-12495
rank : 3 (local_rank: 3)
exitcode : 1 (pid: 38023)
error_file: <N/A>
traceback : To enable traceback see: https://pytorch.org/docs/stable/elastic/errors.html
------------------------------------------------------------
Root Cause (first observed failure):
[0]:
time : 2024-08-04_09:25:02
host : notebook-1813389960667746306-scnlbe5oi5-12495
rank : 2 (local_rank: 2)
exitcode : 1 (pid: 38022)
error_file: <N/A>
traceback : To enable traceback see: https://pytorch.org/docs/stable/elastic/errors.html
============================================================
错误原因:缺少 oss2 依赖包,无法找到数据集。
解决方法:安装 oss2 依赖包。
How to handle the “No module named oss2” error when you use OSS by using Python
pip install --no-dependencies oss2
Q:if not 0.0 <= lr: TypeError: '<=' not supported between instances of 'float' and 'str'
(llama_factory_torch) root@notebook-1813389960667746306-scnlbe5oi5-12495:/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory# FORCE_TORCHRUN=1 llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml
[2024-08-04 10:30:00,673] [INFO] [real_accelerator.py:158:get_accelerator] Setting ds_accelerator to cuda (auto detect)
08/04/2024 10:30:03 - INFO - llamafactory.cli - Initializing distributed tasks at: 127.0.0.1:27599
[2024-08-04 10:30:05,637] torch.distributed.run: [WARNING]
[2024-08-04 10:30:05,637] torch.distributed.run: [WARNING] *****************************************
[2024-08-04 10:30:05,637] torch.distributed.run: [WARNING] Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
[2024-08-04 10:30:05,637] torch.distributed.run: [WARNING] *****************************************
[2024-08-04 10:30:10,197] [INFO] [real_accelerator.py:158:get_accelerator] Setting ds_accelerator to cuda (auto detect)
[2024-08-04 10:30:10,239] [INFO] [real_accelerator.py:158:get_accelerator] Setting ds_accelerator to cuda (auto detect)
[2024-08-04 10:30:10,390] [INFO] [real_accelerator.py:158:get_accelerator] Setting ds_accelerator to cuda (auto detect)
[2024-08-04 10:30:10,435] [INFO] [real_accelerator.py:158:get_accelerator] Setting ds_accelerator to cuda (auto detect)
[2024-08-04 10:30:13,600] [INFO] [comm.py:637:init_distributed] cdb=None
[2024-08-04 10:30:13,600] [INFO] [comm.py:668:init_distributed] Initializing TorchBackend in DeepSpeed with backend nccl
WARNING: Logging before InitGoogleLogging() is written to STDERR
I0804 10:30:13.601742 108226 ProcessGroupNCCL.cpp:686] [Rank 0] ProcessGroupNCCL initialization options:NCCL_ASYNC_ERROR_HANDLING: 1, NCCL_DESYNC_DEBUG: 0, NCCL_ENABLE_TIMING: 0, NCCL_BLOCKING_WAIT: 0, TIMEOUT(ms): 180000000000, USE_HIGH_PRIORITY_STREAM: 0, TORCH_DISTRIBUTED_DEBUG: OFF, NCCL_DEBUG: OFF, ID=365008080
08/04/2024 10:30:13 - WARNING - llamafactory.hparams.parser - `ddp_find_unused_parameters` needs to be set as False for LoRA in DDP training.
08/04/2024 10:30:13 - INFO - llamafactory.hparams.parser - Process rank: 0, device: cuda:0, n_gpu: 1, distributed training: True, compute dtype: torch.bfloat16
[INFO|tokenization_auto.py:682] 2024-08-04 10:30:13,610 >> Could not locate the tokenizer configuration file, will try to use the model config instead.
[INFO|configuration_utils.py:731] 2024-08-04 10:30:13,611 >> loading configuration file /public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/models/Meta-Llama-3-8B-Instruct/config.json
[INFO|configuration_utils.py:800] 2024-08-04 10:30:13,612 >> Model config LlamaConfig {
"_name_or_path": "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/models/Meta-Llama-3-8B-Instruct",
"architectures": [
"LlamaForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 128000,
"eos_token_id": 128001,
"hidden_act": "silu",
"hidden_size": 8192,
"initializer_range": 0.02,
"intermediate_size": 28672,
"max_position_embeddings": 8192,
"mlp_bias": false,
"model_type": "llama",
"num_attention_heads": 64,
"num_hidden_layers": 80,
"num_key_value_heads": 8,
"pretraining_tp": 1,
"rms_norm_eps": 1e-05,
"rope_scaling": null,
"rope_theta": 500000.0,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.43.3",
"use_cache": true,
"vocab_size": 128256
}
[INFO|tokenization_utils_base.py:2287] 2024-08-04 10:30:13,622 >> loading file tokenizer.model
[INFO|tokenization_utils_base.py:2287] 2024-08-04 10:30:13,622 >> loading file tokenizer.json
[INFO|tokenization_utils_base.py:2287] 2024-08-04 10:30:13,622 >> loading file added_tokens.json
[INFO|tokenization_utils_base.py:2287] 2024-08-04 10:30:13,622 >> loading file special_tokens_map.json
[INFO|tokenization_utils_base.py:2287] 2024-08-04 10:30:13,622 >> loading file tokenizer_config.json
[INFO|configuration_utils.py:731] 2024-08-04 10:30:13,623 >> loading configuration file /public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/models/Meta-Llama-3-8B-Instruct/config.json
[INFO|configuration_utils.py:800] 2024-08-04 10:30:13,623 >> Model config LlamaConfig {
"_name_or_path": "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/models/Meta-Llama-3-8B-Instruct",
"architectures": [
"LlamaForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 128000,
"eos_token_id": 128001,
"hidden_act": "silu",
"hidden_size": 8192,
"initializer_range": 0.02,
"intermediate_size": 28672,
"max_position_embeddings": 8192,
"mlp_bias": false,
"model_type": "llama",
"num_attention_heads": 64,
"num_hidden_layers": 80,
"num_key_value_heads": 8,
"pretraining_tp": 1,
"rms_norm_eps": 1e-05,
"rope_scaling": null,
"rope_theta": 500000.0,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.43.3",
"use_cache": true,
"vocab_size": 128256
}
[2024-08-04 10:30:13,638] [INFO] [comm.py:637:init_distributed] cdb=None
WARNING: Logging before InitGoogleLogging() is written to STDERR
I0804 10:30:13.639712 108230 ProcessGroupNCCL.cpp:686] [Rank 3] ProcessGroupNCCL initialization options:NCCL_ASYNC_ERROR_HANDLING: 1, NCCL_DESYNC_DEBUG: 0, NCCL_ENABLE_TIMING: 0, NCCL_BLOCKING_WAIT: 0, TIMEOUT(ms): 180000000000, USE_HIGH_PRIORITY_STREAM: 0, TORCH_DISTRIBUTED_DEBUG: OFF, NCCL_DEBUG: OFF, ID=376601696
08/04/2024 10:30:13 - WARNING - llamafactory.hparams.parser - `ddp_find_unused_parameters` needs to be set as False for LoRA in DDP training.
08/04/2024 10:30:13 - INFO - llamafactory.hparams.parser - Process rank: 3, device: cuda:3, n_gpu: 1, distributed training: True, compute dtype: torch.bfloat16
[2024-08-04 10:30:13,690] [INFO] [comm.py:637:init_distributed] cdb=None
WARNING: Logging before InitGoogleLogging() is written to STDERR
I0804 10:30:13.691934 108229 ProcessGroupNCCL.cpp:686] [Rank 2] ProcessGroupNCCL initialization options:NCCL_ASYNC_ERROR_HANDLING: 1, NCCL_DESYNC_DEBUG: 0, NCCL_ENABLE_TIMING: 0, NCCL_BLOCKING_WAIT: 0, TIMEOUT(ms): 180000000000, USE_HIGH_PRIORITY_STREAM: 0, TORCH_DISTRIBUTED_DEBUG: OFF, NCCL_DEBUG: OFF, ID=382577952
08/04/2024 10:30:13 - WARNING - llamafactory.hparams.parser - `ddp_find_unused_parameters` needs to be set as False for LoRA in DDP training.
08/04/2024 10:30:13 - INFO - llamafactory.hparams.parser - Process rank: 2, device: cuda:2, n_gpu: 1, distributed training: True, compute dtype: torch.bfloat16
[WARNING|logging.py:328] 2024-08-04 10:30:13,762 >> You are using the default legacy behaviour of the <class 'transformers.models.llama.tokenization_llama_fast.LlamaTokenizerFast'>. This is expected, and simply means that the `legacy` (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set `legacy=False`. This should only be set if you understand what it means, and thoroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565 - if you loaded a llama tokenizer from a GGUF file you can ignore this message.
You are using the default legacy behaviour of the <class 'transformers.models.llama.tokenization_llama_fast.LlamaTokenizerFast'>. This is expected, and simply means that the `legacy` (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set `legacy=False`. This should only be set if you understand what it means, and thoroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565 - if you loaded a llama tokenizer from a GGUF file you can ignore this message.
[2024-08-04 10:30:13,822] [INFO] [comm.py:637:init_distributed] cdb=None
WARNING: Logging before InitGoogleLogging() is written to STDERR
I0804 10:30:13.824091 108227 ProcessGroupNCCL.cpp:686] [Rank 1] ProcessGroupNCCL initialization options:NCCL_ASYNC_ERROR_HANDLING: 1, NCCL_DESYNC_DEBUG: 0, NCCL_ENABLE_TIMING: 0, NCCL_BLOCKING_WAIT: 0, TIMEOUT(ms): 180000000000, USE_HIGH_PRIORITY_STREAM: 0, TORCH_DISTRIBUTED_DEBUG: OFF, NCCL_DEBUG: OFF, ID=372943824
08/04/2024 10:30:13 - WARNING - llamafactory.hparams.parser - `ddp_find_unused_parameters` needs to be set as False for LoRA in DDP training.
08/04/2024 10:30:13 - INFO - llamafactory.hparams.parser - Process rank: 1, device: cuda:1, n_gpu: 1, distributed training: True, compute dtype: torch.bfloat16
You are using the default legacy behaviour of the <class 'transformers.models.llama.tokenization_llama_fast.LlamaTokenizerFast'>. This is expected, and simply means that the `legacy` (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set `legacy=False`. This should only be set if you understand what it means, and thoroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565 - if you loaded a llama tokenizer from a GGUF file you can ignore this message.
You are using the default legacy behaviour of the <class 'transformers.models.llama.tokenization_llama_fast.LlamaTokenizerFast'>. This is expected, and simply means that the `legacy` (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set `legacy=False`. This should only be set if you understand what it means, and thoroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565 - if you loaded a llama tokenizer from a GGUF file you can ignore this message.
[INFO|tokenization_utils_base.py:2533] 2024-08-04 10:30:14,052 >> Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
08/04/2024 10:30:14 - INFO - llamafactory.data.template - Replace eos token: <|eot_id|>
08/04/2024 10:30:14 - INFO - llamafactory.data.template - Add pad token: <|eot_id|>
08/04/2024 10:30:14 - INFO - llamafactory.data.template - Replace eos token: <|eot_id|>
08/04/2024 10:30:14 - INFO - llamafactory.data.template - Add pad token: <|eot_id|>
08/04/2024 10:30:14 - INFO - llamafactory.data.loader - Loading dataset llamafactory/alpaca_zh...
08/04/2024 10:30:14 - INFO - llamafactory.data.template - Replace eos token: <|eot_id|>
08/04/2024 10:30:14 - INFO - llamafactory.data.template - Add pad token: <|eot_id|>
08/04/2024 10:30:14 - INFO - llamafactory.data.template - Replace eos token: <|eot_id|>
08/04/2024 10:30:14 - INFO - llamafactory.data.template - Add pad token: <|eot_id|>
I0804 10:30:14.382220 108230 ProcessGroupNCCL.cpp:2780] Rank 3 using GPU 3 to perform barrier as devices used by this process are currently unknown. This can potentially cause a hang if this rank to GPU mapping is incorrect.Specify device_ids in barrier() to force use of a particular device.
I0804 10:30:14.445211 108229 ProcessGroupNCCL.cpp:2780] Rank 2 using GPU 2 to perform barrier as devices used by this process are currently unknown. This can potentially cause a hang if this rank to GPU mapping is incorrect.Specify device_ids in barrier() to force use of a particular device.
I0804 10:30:14.611828 108227 ProcessGroupNCCL.cpp:2780] Rank 1 using GPU 1 to perform barrier as devices used by this process are currently unknown. This can potentially cause a hang if this rank to GPU mapping is incorrect.Specify device_ids in barrier() to force use of a particular device.
/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/datasets/builder.py:883: FutureWarning: 'try_from_hf_gcs' was deprecated in version 2.16.0 and will be removed in 3.0.0.
warnings.warn(
Converting format of dataset (num_proc=16): 100%|███████████████████████████████████████████████████████████████████████████████████████████████| 1000/1000 [00:00<00:00, 4131.94 examples/s]
I0804 10:30:19.983676 108226 ProcessGroupNCCL.cpp:2780] Rank 0 using GPU 0 to perform barrier as devices used by this process are currently unknown. This can potentially cause a hang if this rank to GPU mapping is incorrect.Specify device_ids in barrier() to force use of a particular device.
I0804 10:30:20.622058 108226 ProcessGroupNCCL.cpp:1340] NCCL_DEBUG: N/A
08/04/2024 10:30:20 - INFO - llamafactory.data.loader - Loading dataset llamafactory/alpaca_zh...
08/04/2024 10:30:20 - INFO - llamafactory.data.loader - Loading dataset llamafactory/alpaca_zh...
08/04/2024 10:30:20 - INFO - llamafactory.data.loader - Loading dataset llamafactory/alpaca_zh...
Running tokenizer on dataset (num_proc=16): 100%|████████████████████████████████████████████████████████████████████████████████████████████████| 1000/1000 [00:03<00:00, 284.38 examples/s]
/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/datasets/builder.py:883: FutureWarning: 'try_from_hf_gcs' was deprecated in version 2.16.0 and will be removed in 3.0.0.
warnings.warn(
training example:
input_ids:
[128000, 128006, 882, 128007, 271, 98739, 109425, 19000, 9080, 40053, 104654, 16325, 111689, 83747, 11883, 53610, 11571, 128009, 128006, 78191, 128007, 271, 16, 13, 86758, 56602, 53610, 123128, 116051, 56602, 53610, 85315, 233, 118959, 83601, 115, 65455, 34208, 53610, 104432, 65455, 1811, 720, 17, 13, 86758, 53610, 74396, 58291, 53610, 44559, 114, 51109, 43167, 118006, 123641, 53610, 3922, 78657, 108914, 81802, 245, 34208, 108914, 118959, 1811, 720, 18, 13, 74662, 117481, 16325, 115890, 56602, 53610, 126966, 1811, 720, 19, 13, 111909, 222, 33976, 53610, 36651, 34208, 66285, 234, 36117, 231, 73548, 9554, 118487, 53610, 106041, 91495, 82317, 13646, 23951, 59464, 127150, 1811, 720, 20, 13, 107934, 245, 105444, 94, 21082, 118504, 106649, 3922, 38129, 103167, 111155, 85315, 233, 118959, 65455, 56602, 95337, 11883, 53610, 1811, 720, 21, 13, 114524, 43167, 106786, 53610, 3922, 114593, 106143, 108309, 58291, 93994, 66776, 120522, 11883, 113173, 1811, 720, 22, 13, 20033, 115, 109895, 58291, 125405, 46034, 13646, 30356, 111110, 53610, 104432, 65455, 1811, 720, 23, 13, 66827, 237, 83747, 27699, 229, 53610, 105301, 117027, 9554, 21082, 1811, 720, 24, 13, 59330, 121, 88367, 43240, 30590, 30358, 59464, 38129, 118954, 53610, 10110, 124714, 108914, 105060, 33748, 5486, 118959, 102452, 53610, 101837, 121, 34208, 85315, 233, 118959, 9554, 53610, 75376, 720, 605, 13, 127609, 125025, 126369, 60455, 96455, 45736, 9554, 108914, 81802, 245, 33748, 34208, 108914, 105060, 33748, 1811, 128009]
inputs:
<|begin_of_text|><|start_header_id|>user<|end_header_id|>
我们如何在日常生活中减少用水?<|eot_id|><|start_header_id|>assistant<|end_header_id|>
1. 使用节水装置,如节水淋浴喷头和水龙头。
2. 使用水箱或水桶收集家庭废水,例如洗碗和洗浴。
3. 在社区中提高节水意识。
4. 检查水管和灌溉系统的漏水情况,并及时修复它们。
5. 洗澡时间缩短,使用低流量淋浴头节约用水。
6. 收集雨水,用于园艺或其他非饮用目的。
7. 刷牙或擦手时关掉水龙头。
8. 减少浇水草坪的时间。
9. 尽可能多地重复使用灰水(来自洗衣机、浴室水槽和淋浴的水)。
10. 只购买能源效率高的洗碗机和洗衣机。<|eot_id|>
label_ids:
[-100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, 16, 13, 86758, 56602, 53610, 123128, 116051, 56602, 53610, 85315, 233, 118959, 83601, 115, 65455, 34208, 53610, 104432, 65455, 1811, 720, 17, 13, 86758, 53610, 74396, 58291, 53610, 44559, 114, 51109, 43167, 118006, 123641, 53610, 3922, 78657, 108914, 81802, 245, 34208, 108914, 118959, 1811, 720, 18, 13, 74662, 117481, 16325, 115890, 56602, 53610, 126966, 1811, 720, 19, 13, 111909, 222, 33976, 53610, 36651, 34208, 66285, 234, 36117, 231, 73548, 9554, 118487, 53610, 106041, 91495, 82317, 13646, 23951, 59464, 127150, 1811, 720, 20, 13, 107934, 245, 105444, 94, 21082, 118504, 106649, 3922, 38129, 103167, 111155, 85315, 233, 118959, 65455, 56602, 95337, 11883, 53610, 1811, 720, 21, 13, 114524, 43167, 106786, 53610, 3922, 114593, 106143, 108309, 58291, 93994, 66776, 120522, 11883, 113173, 1811, 720, 22, 13, 20033, 115, 109895, 58291, 125405, 46034, 13646, 30356, 111110, 53610, 104432, 65455, 1811, 720, 23, 13, 66827, 237, 83747, 27699, 229, 53610, 105301, 117027, 9554, 21082, 1811, 720, 24, 13, 59330, 121, 88367, 43240, 30590, 30358, 59464, 38129, 118954, 53610, 10110, 124714, 108914, 105060, 33748, 5486, 118959, 102452, 53610, 101837, 121, 34208, 85315, 233, 118959, 9554, 53610, 75376, 720, 605, 13, 127609, 125025, 126369, 60455, 96455, 45736, 9554, 108914, 81802, 245, 33748, 34208, 108914, 105060, 33748, 1811, 128009]
labels:
1. 使用节水装置,如节水淋浴喷头和水龙头。
2. 使用水箱或水桶收集家庭废水,例如洗碗和洗浴。
3. 在社区中提高节水意识。
4. 检查水管和灌溉系统的漏水情况,并及时修复它们。
5. 洗澡时间缩短,使用低流量淋浴头节约用水。
6. 收集雨水,用于园艺或其他非饮用目的。
7. 刷牙或擦手时关掉水龙头。
8. 减少浇水草坪的时间。
9. 尽可能多地重复使用灰水(来自洗衣机、浴室水槽和淋浴的水)。
10. 只购买能源效率高的洗碗机和洗衣机。<|eot_id|>
/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/datasets/builder.py:883: FutureWarning: 'try_from_hf_gcs' was deprecated in version 2.16.0 and will be removed in 3.0.0.
warnings.warn(
/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/datasets/builder.py:883: FutureWarning: 'try_from_hf_gcs' was deprecated in version 2.16.0 and will be removed in 3.0.0.
warnings.warn(
[INFO|configuration_utils.py:731] 2024-08-04 10:30:25,948 >> loading configuration file /public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/models/Meta-Llama-3-8B-Instruct/config.json
[INFO|configuration_utils.py:800] 2024-08-04 10:30:25,950 >> Model config LlamaConfig {
"_name_or_path": "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/models/Meta-Llama-3-8B-Instruct",
"architectures": [
"LlamaForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 128000,
"eos_token_id": 128001,
"hidden_act": "silu",
"hidden_size": 8192,
"initializer_range": 0.02,
"intermediate_size": 28672,
"max_position_embeddings": 8192,
"mlp_bias": false,
"model_type": "llama",
"num_attention_heads": 64,
"num_hidden_layers": 80,
"num_key_value_heads": 8,
"pretraining_tp": 1,
"rms_norm_eps": 1e-05,
"rope_scaling": null,
"rope_theta": 500000.0,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.43.3",
"use_cache": true,
"vocab_size": 128256
}
[INFO|modeling_utils.py:3631] 2024-08-04 10:30:25,987 >> loading weights file /public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/models/Meta-Llama-3-8B-Instruct/model.safetensors.index.json
[INFO|modeling_utils.py:3776] 2024-08-04 10:30:25,989 >> Detected DeepSpeed ZeRO-3: activating zero.init() for this model
[INFO|configuration_utils.py:1038] 2024-08-04 10:30:26,011 >> Generate config GenerationConfig {
"bos_token_id": 128000,
"eos_token_id": 128001
}
[2024-08-04 10:33:34,680] [INFO] [partition_parameters.py:348:__exit__] finished initializing model - num_params = 723, num_elems = 70.55B
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 30/30 [08:37<00:00, 17.26s/it]
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 30/30 [08:38<00:00, 17.27s/it]
08/04/2024 10:42:12 - INFO - llamafactory.model.model_utils.checkpointing - Gradient checkpointing enabled.
08/04/2024 10:42:12 - INFO - llamafactory.model.model_utils.attention - Using vanilla attention implementation.
08/04/2024 10:42:12 - INFO - llamafactory.model.adapter - ZeRO3 / FSDP detected, remaining trainable params in float32.
08/04/2024 10:42:12 - INFO - llamafactory.model.adapter - Fine-tuning method: LoRA
08/04/2024 10:42:12 - INFO - llamafactory.model.model_utils.checkpointing - Gradient checkpointing enabled.
08/04/2024 10:42:12 - INFO - llamafactory.model.model_utils.attention - Using vanilla attention implementation.
08/04/2024 10:42:12 - INFO - llamafactory.model.adapter - ZeRO3 / FSDP detected, remaining trainable params in float32.
08/04/2024 10:42:12 - INFO - llamafactory.model.adapter - Fine-tuning method: LoRA
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 30/30 [08:38<00:00, 17.27s/it]
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 30/30 [08:38<00:00, 17.27s/it]
[INFO|modeling_utils.py:4463] 2024-08-04 10:42:12,932 >> All model checkpoint weights were used when initializing LlamaForCausalLM.
[INFO|modeling_utils.py:4471] 2024-08-04 10:42:12,932 >> All the weights of LlamaForCausalLM were initialized from the model checkpoint at /public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/models/Meta-Llama-3-8B-Instruct.
If your task is similar to the task the model of the checkpoint was trained on, you can already use LlamaForCausalLM for predictions without further training.
[INFO|configuration_utils.py:991] 2024-08-04 10:42:12,939 >> loading configuration file /public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/models/Meta-Llama-3-8B-Instruct/generation_config.json
[INFO|configuration_utils.py:1038] 2024-08-04 10:42:12,940 >> Generate config GenerationConfig {
"bos_token_id": 128000,
"eos_token_id": 128001
}
08/04/2024 10:42:12 - INFO - llamafactory.model.model_utils.checkpointing - Gradient checkpointing enabled.
08/04/2024 10:42:12 - INFO - llamafactory.model.model_utils.attention - Using vanilla attention implementation.
08/04/2024 10:42:12 - INFO - llamafactory.model.adapter - ZeRO3 / FSDP detected, remaining trainable params in float32.
08/04/2024 10:42:12 - INFO - llamafactory.model.model_utils.checkpointing - Gradient checkpointing enabled.
08/04/2024 10:42:12 - INFO - llamafactory.model.adapter - Fine-tuning method: LoRA
08/04/2024 10:42:12 - INFO - llamafactory.model.model_utils.attention - Using vanilla attention implementation.
08/04/2024 10:42:12 - INFO - llamafactory.model.adapter - ZeRO3 / FSDP detected, remaining trainable params in float32.
08/04/2024 10:42:12 - INFO - llamafactory.model.adapter - Fine-tuning method: LoRA
08/04/2024 10:42:13 - INFO - llamafactory.model.loader - trainable params: 16,384,000 || all params: 70,570,090,496 || trainable%: 0.0232
08/04/2024 10:42:13 - INFO - llamafactory.model.loader - trainable params: 16,384,000 || all params: 70,570,090,496 || trainable%: 0.0232
08/04/2024 10:42:13 - INFO - llamafactory.model.loader - trainable params: 16,384,000 || all params: 70,570,090,496 || trainable%: 0.0232
08/04/2024 10:42:13 - INFO - llamafactory.model.loader - trainable params: 16,384,000 || all params: 70,570,090,496 || trainable%: 0.0232
Detected kernel version 3.10.0, which is below the recommended minimum of 5.5.0; this can cause the process to hang. It is recommended to upgrade the kernel to the minimum version or higher.
[INFO|trainer.py:648] 2024-08-04 10:42:13,263 >> Using auto half precision backend
Traceback (most recent call last):
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/launcher.py", line 23, in <module>
launch()
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/launcher.py", line 19, in launch
run_exp()
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/train/tuner.py", line 50, in run_exp
Traceback (most recent call last):
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/launcher.py", line 23, in <module>
launch()
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/launcher.py", line 19, in launch
run_exp()
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/train/tuner.py", line 50, in run_exp
run_sft(model_args, data_args, training_args, finetuning_args, generating_args, callbacks)
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/train/sft/workflow.py", line 94, in run_sft
run_sft(model_args, data_args, training_args, finetuning_args, generating_args, callbacks)
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/train/sft/workflow.py", line 94, in run_sft
train_result = trainer.train(resume_from_checkpoint=training_args.resume_from_checkpoint)
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/trainer.py", line 1938, in train
return inner_training_loop(
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/trainer.py", line 2036, in _inner_training_loop
self.optimizer, self.lr_scheduler = deepspeed_init(self, num_training_steps=max_steps)
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/integrations/deepspeed.py", line 411, in deepspeed_init
optimizer, lr_scheduler = deepspeed_optim_sched(
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/integrations/deepspeed.py", line 336, in deepspeed_optim_sched
optimizer = trainer.create_optimizer()
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/train/sft/trainer.py", line 70, in create_optimizer
train_result = trainer.train(resume_from_checkpoint=training_args.resume_from_checkpoint)
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/trainer.py", line 1938, in train
return inner_training_loop(
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/trainer.py", line 2036, in _inner_training_loop
self.optimizer, self.lr_scheduler = deepspeed_init(self, num_training_steps=max_steps)
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/integrations/deepspeed.py", line 411, in deepspeed_init
optimizer, lr_scheduler = deepspeed_optim_sched(
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/integrations/deepspeed.py", line 336, in deepspeed_optim_sched
optimizer = trainer.create_optimizer()
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/train/sft/trainer.py", line 70, in create_optimizer
return super().create_optimizer()
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/trainer.py", line 1099, in create_optimizer
return super().create_optimizer()
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/trainer.py", line 1099, in create_optimizer
self.optimizer = optimizer_cls(optimizer_grouped_parameters, **optimizer_kwargs)
self.optimizer = optimizer_cls(optimizer_grouped_parameters, **optimizer_kwargs) File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/torch/optim/adamw.py", line 28, in __init__
if not 0.0 <= lr:
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/torch/optim/adamw.py", line 28, in __init__
TypeError: '<=' not supported between instances of 'float' and 'str'
if not 0.0 <= lr:
TypeError: '<=' not supported between instances of 'float' and 'str'
[INFO|deepspeed.py:329] 2024-08-04 10:42:13,513 >> Detected ZeRO Offload and non-DeepSpeed optimizers: This combination should work as long as the custom optimizer has both CPU and GPU implementation (except LAMB)
Traceback (most recent call last):
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/launcher.py", line 23, in <module>
launch()
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/launcher.py", line 19, in launch
run_exp()
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/train/tuner.py", line 50, in run_exp
run_sft(model_args, data_args, training_args, finetuning_args, generating_args, callbacks)
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/train/sft/workflow.py", line 94, in run_sft
train_result = trainer.train(resume_from_checkpoint=training_args.resume_from_checkpoint)
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/trainer.py", line 1938, in train
return inner_training_loop(
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/trainer.py", line 2036, in _inner_training_loop
self.optimizer, self.lr_scheduler = deepspeed_init(self, num_training_steps=max_steps)
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/integrations/deepspeed.py", line 411, in deepspeed_init
optimizer, lr_scheduler = deepspeed_optim_sched(
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/integrations/deepspeed.py", line 336, in deepspeed_optim_sched
optimizer = trainer.create_optimizer()
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/train/sft/trainer.py", line 70, in create_optimizer
return super().create_optimizer()
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/trainer.py", line 1099, in create_optimizer
self.optimizer = optimizer_cls(optimizer_grouped_parameters, **optimizer_kwargs)
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/torch/optim/adamw.py", line 28, in __init__
if not 0.0 <= lr:
TypeError: '<=' not supported between instances of 'float' and 'str'
Traceback (most recent call last):
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/launcher.py", line 23, in <module>
launch()
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/launcher.py", line 19, in launch
run_exp()
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/train/tuner.py", line 50, in run_exp
run_sft(model_args, data_args, training_args, finetuning_args, generating_args, callbacks)
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/train/sft/workflow.py", line 94, in run_sft
train_result = trainer.train(resume_from_checkpoint=training_args.resume_from_checkpoint)
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/trainer.py", line 1938, in train
return inner_training_loop(
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/trainer.py", line 2036, in _inner_training_loop
self.optimizer, self.lr_scheduler = deepspeed_init(self, num_training_steps=max_steps)
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/integrations/deepspeed.py", line 411, in deepspeed_init
optimizer, lr_scheduler = deepspeed_optim_sched(
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/integrations/deepspeed.py", line 336, in deepspeed_optim_sched
optimizer = trainer.create_optimizer()
File "/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/train/sft/trainer.py", line 70, in create_optimizer
return super().create_optimizer()
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/transformers/trainer.py", line 1099, in create_optimizer
self.optimizer = optimizer_cls(optimizer_grouped_parameters, **optimizer_kwargs)
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/torch/optim/adamw.py", line 28, in __init__
if not 0.0 <= lr:
TypeError: '<=' not supported between instances of 'float' and 'str'
[2024-08-04 10:42:21,484] torch.distributed.elastic.multiprocessing.api: [ERROR] failed (exitcode: 1) local_rank: 0 (pid: 108226) of binary: /opt/conda/envs/llama_factory_torch/bin/python
Traceback (most recent call last):
File "/opt/conda/envs/llama_factory_torch/bin/torchrun", line 8, in <module>
sys.exit(main())
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/torch/distributed/elastic/multiprocessing/errors/__init__.py", line 346, in wrapper
return f(*args, **kwargs)
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/torch/distributed/run.py", line 806, in main
run(args)
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/torch/distributed/run.py", line 797, in run
elastic_launch(
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/torch/distributed/launcher/api.py", line 134, in __call__
return launch_agent(self._config, self._entrypoint, list(args))
File "/opt/conda/envs/llama_factory_torch/lib/python3.10/site-packages/torch/distributed/launcher/api.py", line 264, in launch_agent
raise ChildFailedError(
torch.distributed.elastic.multiprocessing.errors.ChildFailedError:
============================================================
/public/home/scnlbe5oi5/Downloads/models/LLaMA-Factory/src/llamafactory/launcher.py FAILED
------------------------------------------------------------
Failures:
[1]:
time : 2024-08-04_10:42:21
host : notebook-1813389960667746306-scnlbe5oi5-12495
rank : 1 (local_rank: 1)
exitcode : 1 (pid: 108227)
error_file: <N/A>
traceback : To enable traceback see: https://pytorch.org/docs/stable/elastic/errors.html
[2]:
time : 2024-08-04_10:42:21
host : notebook-1813389960667746306-scnlbe5oi5-12495
rank : 2 (local_rank: 2)
exitcode : 1 (pid: 108229)
error_file: <N/A>
traceback : To enable traceback see: https://pytorch.org/docs/stable/elastic/errors.html
[3]:
time : 2024-08-04_10:42:21
host : notebook-1813389960667746306-scnlbe5oi5-12495
rank : 3 (local_rank: 3)
exitcode : 1 (pid: 108230)
error_file: <N/A>
traceback : To enable traceback see: https://pytorch.org/docs/stable/elastic/errors.html
------------------------------------------------------------
Root Cause (first observed failure):
[0]:
time : 2024-08-04_10:42:21
host : notebook-1813389960667746306-scnlbe5oi5-12495
rank : 0 (local_rank: 0)
exitcode : 1 (pid: 108226)
error_file: <N/A>
traceback : To enable traceback see: https://pytorch.org/docs/stable/elastic/errors.html
============================================================
现在yaml配置形式的学习率不支持科学记数法输入 #4014
TypeError: ‘<=’ not supported between instances of ‘float’ and ‘str’ #4149
错误原因:yaml文件对科学记数法支持不佳。
解决方法:
learning_rate: 5e-5
改为
learning_rate: 5.0e-5