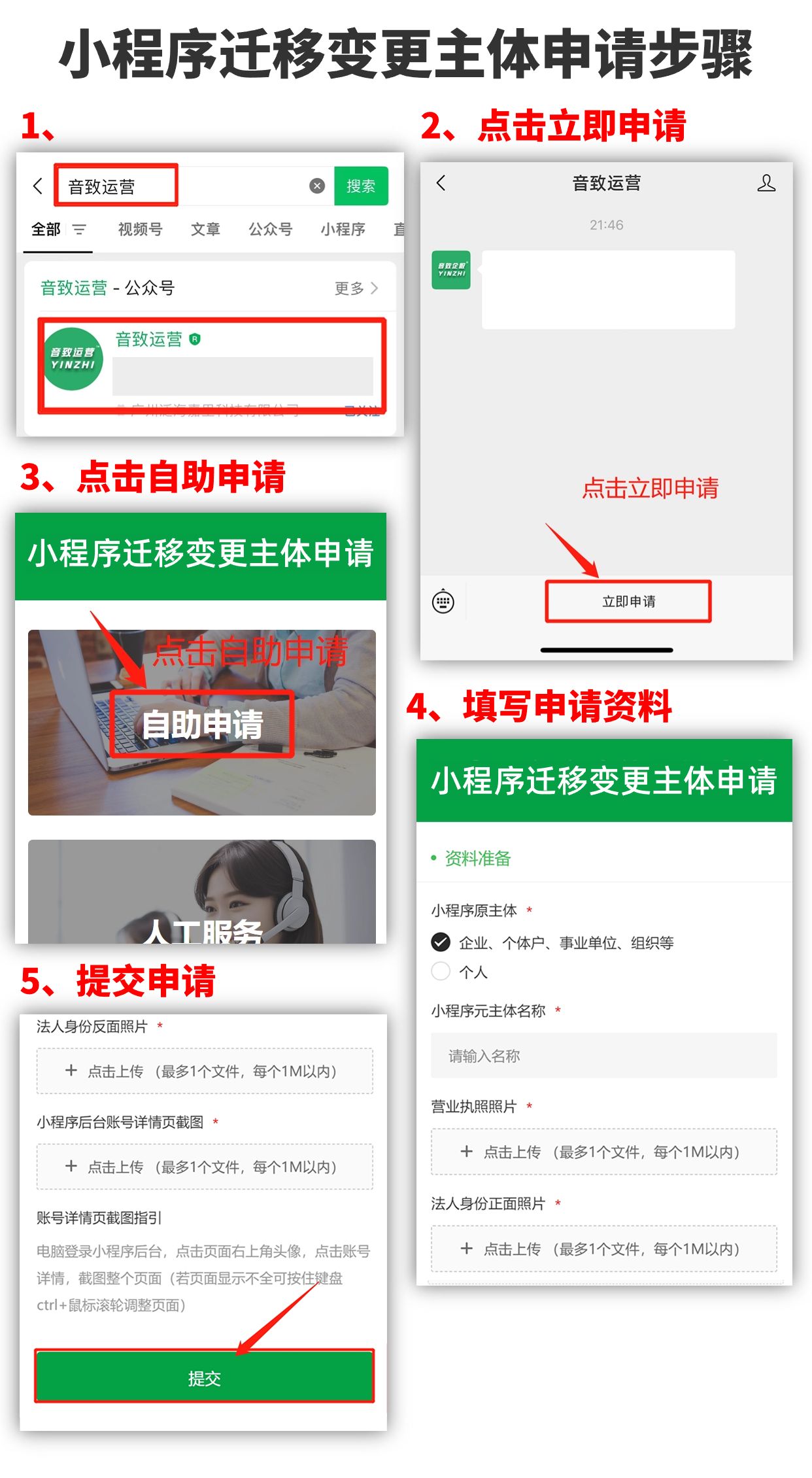
COURSE1 WEEK3
逻辑回归
逻辑回归主要用于分类任务
只有两种输出结果的分类任务叫做二元分类,例如预测垃圾邮件,只能回答是或否
实际上,在逻辑回归中,我们要做的任务就类似于在数据集中画出一个这样的曲线,用来作为类别的界限

在上图中,由于我们用的是线性回归模型,最终的输出是是一个连续的离散的值,而我们的二分类任务是输出0和1,代表不是和是,因此还需要将上图中的输出加入到
s
i
g
m
o
i
d
sigmoid
sigmoid函数中,映射到
[
0
,
1
]
[0,1]
[0,1]区间内

基本流程如下所示:

逻辑回归方程定义式
f
w
⃗
,
b
(
x
⃗
)
=
1
1
+
e
−
(
w
⃗
⋅
x
⃗
+
b
)
f_{\vec w, b}(\vec x) = \frac{1}{1+e^{-(\vec w \cdot \vec x + b)}}
fw,b(x)=1+e−(w⋅x+b)1
观察
S
i
g
m
o
i
d
Sigmoid
Sigmoid函数,我们可以观察到:
- 当输入值小于0,即 z < 0 → w x + b < 0 z <0 \to wx+b < 0 z<0→wx+b<0时,最终的输出趋近于0,代表负类
- 当输入值大于0,即 z > 0 → w x + b > 0 z >0 \to wx+b > 0 z>0→wx+b>0时,最终的输出趋近于1,代表正类
因此,我么可以找到决策边界,即 w ⃗ ⋅ x ⃗ + b = 0 \vec w\cdot \vec x + b = 0 w⋅x+b=0

而对于更复杂的数据,我们可以使用特征工程的方法对输入进行多项式变换组合,以满足实际的需求

逻辑回归中的损失函数
逻辑回归中不再使用平方误差函数,因为通过观察我们逻辑回归的函数定义式,带有指数项比较复杂,因此带入平方误差损失函数中,图像如下,

即是一个非凸的函数,存在很多局部最优的地方,容易使得我们的梯度下降算法效果不理想
在逻辑回归中,使用的是交叉熵损失函数,可以用来衡量预测的结果与实际的结果的一致性程度
L
(
f
w
⃗
,
b
(
x
⃗
(
i
)
)
,
y
(
i
)
)
=
{
−
log
(
f
w
⃗
,
b
(
x
⃗
(
i
)
)
)
i
f
y
(
i
)
=
1
−
log
(
1
−
f
w
⃗
,
b
(
x
⃗
(
i
)
)
)
i
f
y
(
i
)
=
0
L(f_{\vec w,b}(\vec x^{(i)}), y^{(i)})= \left\{ \begin{aligned} -\log (f_{\vec w,b}(\vec x^{(i)})) \ \ \ \ if \ y^{(i)} = 1 \\ -\log (1-f_{\vec w,b}(\vec x^{(i)})) \ \ \ \ if \ y^{(i)} = 0 \end{aligned} \right.
L(fw,b(x(i)),y(i))={−log(fw,b(x(i))) if y(i)=1−log(1−fw,b(x(i))) if y(i)=0
如下函数图像
−
l
o
g
(
1
−
f
)
-log(1-f)
−log(1−f) ,可以发现,当
y
(
i
)
=
0
y^{(i)} = 0
y(i)=0时
- 如果预测的结果 y ^ = 0 \hat y = 0 y^=0,那么损失值会为0
- 如果预测结果
y
^
=
1
\hat y = 1
y^=1,那么损失值特别大

如下函数图像 − l o g ( f ) -log(f) −log(f) ,可以发现,当 y ( i ) = 1 y^{(i)} = 1 y(i)=1时

- 如果预测的结果 y ^ = 0 \hat y = 0 y^=0,那么损失值会为特别大
- 如果预测的结果 y ^ = 1 \hat y = 1 y^=1,那么损失值为0
因此,通过这种损失函数,可以发现其是一个凸函数,因此可以使用梯度下降得到一个可靠的答案
由于我们处理的是一个二分类任务,即
y
y
y 要么取 0 要么取 1 ,因此,我们的损失函数还可以简化为:
L
(
f
w
⃗
,
b
(
x
⃗
(
i
)
)
,
y
(
i
)
)
=
−
y
(
i
)
log
(
f
w
⃗
,
b
(
x
⃗
(
i
)
)
)
−
(
1
−
y
(
i
)
)
log
(
1
−
f
w
⃗
,
b
(
x
⃗
(
i
)
)
)
L(f_{\vec w,b}(\vec x^{(i)}), y^{(i)})=- y^{(i)}\log (f_{\vec w,b}(\vec x^{(i)})) - (1-y^{(i)})\log (1-f_{\vec w,b}(\vec x^{(i)}))
L(fw,b(x(i)),y(i))=−y(i)log(fw,b(x(i)))−(1−y(i))log(1−fw,b(x(i)))
因此,当
y
(
i
)
=
1
y^{(i)} = 1
y(i)=1时,前面的式子有效,当
y
(
i
)
=
0
y^{(i)} = 0
y(i)=0时,后面的式子有效
逻辑回归中的梯度下降
参数的更新

同样,在逻辑回归中,也可以使用向量化的操作来加快梯度下降的收敛速度
过拟合问题
在训练过程中,经常会遇到过拟合的问题,导致模型的性能不好
过拟合与欠拟合
欠拟合
由于模型使用的不当等因素,使得模型不饿能很好的拟合训练集,算法无法捕捉训练数据中的重要特征模式,例如在预测房价时,如果我们使用线性模型,且不使用特征工程的方法时,就可能会出现欠拟合的现象

模型的泛化能力
模型的泛化能力是指模型的性能比较好,能够适用于大多数数据,即使在它一千从未见到过的全新示例上也能做出良好的预测

过拟合
过拟合是指我们的模型可能过于复杂,非常适合训练数据,在训练集上的表现性能非常优秀,但是在新的数据集上,不能做出良好精确的预测,这种模型不能进行推广到其他数据集上

过拟合与欠拟合的现象也会出现在分类任务里

解决过拟合的方法
-
收集更多的数据进行训练,即使用大量的数据样例进行训练
-
观察是否可以使用更少的特征,减少一些多项式特征的使用
可以通过将特征前的参数设置为0来去除该特征
-
加入正则化项——鼓励学习算法缩小参数值,而不必要求参数为0
可以保留所有特征,但只是防止特征产生过大的影响,有时也会导致过拟合
正则化技术时实际应用中一种非常常用的方法
正则化
正则化的方法就是对损失函数进行适当的修改,即对特征进行惩罚
例如我们的模型函数如下所示
f
=
w
1
x
+
w
2
x
2
2
+
w
3
x
3
+
w
4
x
4
+
b
f = w_1x + w_2x_2^2 + w_3x^3 + w_4x^4 + b
f=w1x+w2x22+w3x3+w4x4+b
损失函数如下所示:
min
1
2
m
∑
i
=
1
m
(
f
(
x
(
i
)
)
−
y
(
i
)
)
2
\min \frac{1}{2m}\sum_{i=1}^{m}(f(x^{(i)}) - y^{(i)})^2
min2m1i=1∑m(f(x(i))−y(i))2
由于
x
3
x^3
x3和
x
4
x^4
x4的出现,可能会导致我们的模型出现过拟合的现象,因此我们要对这两个特征的系数,即
w
3
w_3
w3和
w
4
w_4
w4进行正则化惩罚,从而,将损失函数改变如下:
min
1
2
m
∑
i
=
1
m
(
f
(
x
(
i
)
)
−
y
(
i
)
)
2
+
1000
w
3
2
+
1000
w
4
2
\min \frac{1}{2m}\sum_{i=1}^{m}(f(x^{(i)}) - y^{(i)})^2 + 1000w_3^2 + 1000w_4^2
min2m1i=1∑m(f(x(i))−y(i))2+1000w32+1000w42
因此通过模型的不断训练,
w
3
w_3
w3 和
w
4
w_4
w4 就会变得比较小,使得我们的模型具有较好的泛化能力
且一般而言,我们只对特征前的参数进行正则化处理,而不对偏置 b b b 进行正则化处理
而在实际中,往往会有成千的特征,而我们不知道哪些特征是重要的,因此正则化的典型实现方式就是惩罚所有的特征
正则化通用公式:
J
(
w
⃗
,
b
)
=
min
1
2
m
∑
i
=
1
m
(
f
(
x
(
i
)
)
−
y
(
i
)
)
2
+
λ
2
m
∑
j
=
1
n
w
j
2
J(\vec w, b) = \min \frac{1}{2m}\sum_{i=1}^{m}(f(x^{(i)}) - y^{(i)})^2 + \frac{\lambda}{2m}\sum_{j=1}^{n}w_j^2
J(w,b)=min2m1i=1∑m(f(x(i))−y(i))2+2mλj=1∑nwj2
其中,
λ
\lambda
λ 是正则化参数
当 λ \lambda λ 非常大时,我们的模型参数 w j w_j wj 都趋近于0,此时模型的输出就等于偏置 b b b,出现欠拟合现象
当 λ \lambda λ非常小时( λ = 0 \lambda = 0 λ=0),就相当于没有做正则化操作,此时我们的模型就会出现过拟合现象
因此,我们的任务就是要选择一个合适的正则化参数
用于线性回归的正则化
使用正则化后,我们的损失函数分为了两个部分:
- 损失项
- 正则化项
因此,使用梯度下降更新参数的表达式变为:
w
j
=
w
j
−
α
∂
∂
w
j
=
w
j
−
α
[
1
m
∑
i
=
1
m
(
f
w
⃗
,
b
(
x
⃗
(
i
)
)
−
y
(
i
)
)
x
j
(
i
)
+
λ
m
w
j
]
w_j= w_j-\alpha \frac{\partial}{\partial w_j} = w_j - \alpha[\frac{1}{m}\sum_{i=1}^{m}(f_{\vec w, b}(\vec x^{(i)})-y^{(i)})x_j^{(i)} + \frac{\lambda}{m}w_j]
wj=wj−α∂wj∂=wj−α[m1i=1∑m(fw,b(x(i))−y(i))xj(i)+mλwj]
而偏置
b
b
b 的更新公式不变
用于逻辑回归的正则化
对于逻辑回归,加入正则化后,损失函数变为:
J
(
w
⃗
,
b
)
=
−
1
m
∑
i
=
1
m
[
y
(
i
)
log
(
f
w
⃗
,
b
(
x
⃗
(
i
)
)
)
−
(
1
−
y
(
i
)
)
log
(
1
−
f
w
⃗
,
b
(
x
⃗
(
i
)
)
)
]
+
λ
2
m
∑
j
=
1
n
w
j
2
J(\vec w,b)=-\frac{1}{m}\sum_{i=1}^{m}[ y^{(i)}\log (f_{\vec w,b}(\vec x^{(i)})) - (1-y^{(i)})\log (1-f_{\vec w,b}(\vec x^{(i)}))] + \frac{\lambda}{2m}\sum_{j=1}^nw_j^2
J(w,b)=−m1i=1∑m[y(i)log(fw,b(x(i)))−(1−y(i))log(1−fw,b(x(i)))]+2mλj=1∑nwj2
使用梯度下降时,参数更新的变化和线性回归一样:
w
j
=
w
j
−
α
∂
∂
w
j
=
w
j
−
α
[
1
m
∑
i
=
1
m
(
f
w
⃗
,
b
(
x
⃗
(
i
)
)
−
y
(
i
)
)
x
j
(
i
)
+
λ
m
w
j
]
w_j= w_j-\alpha \frac{\partial}{\partial w_j} = w_j - \alpha[\frac{1}{m}\sum_{i=1}^{m}(f_{\vec w, b}(\vec x^{(i)})-y^{(i)})x_j^{(i)} + \frac{\lambda}{m}w_j]
wj=wj−α∂wj∂=wj−α[m1i=1∑m(fw,b(x(i))−y(i))xj(i)+mλwj]