前言
在上一章【课程总结】day19(下):Transformer架构及注意力机制了解总结中,我们对Transformer架构以及注意力机制有了初步了解,本章将结合《The Annotated Transformer》中的源码,对Transformer的架构进行深入理解。
背景
《The Annotated Transformer》是由 Harvard NLP Group 提供的一个详细教程,旨在帮助读者理解 Transformer 模型的工作原理和实现细节。
原文博客地址:https://nlp.seas.harvard.edu/2018/04/03/attention.html
Github仓库地址:https://github.com/harvardnlp/annotated-transformer
整体框架
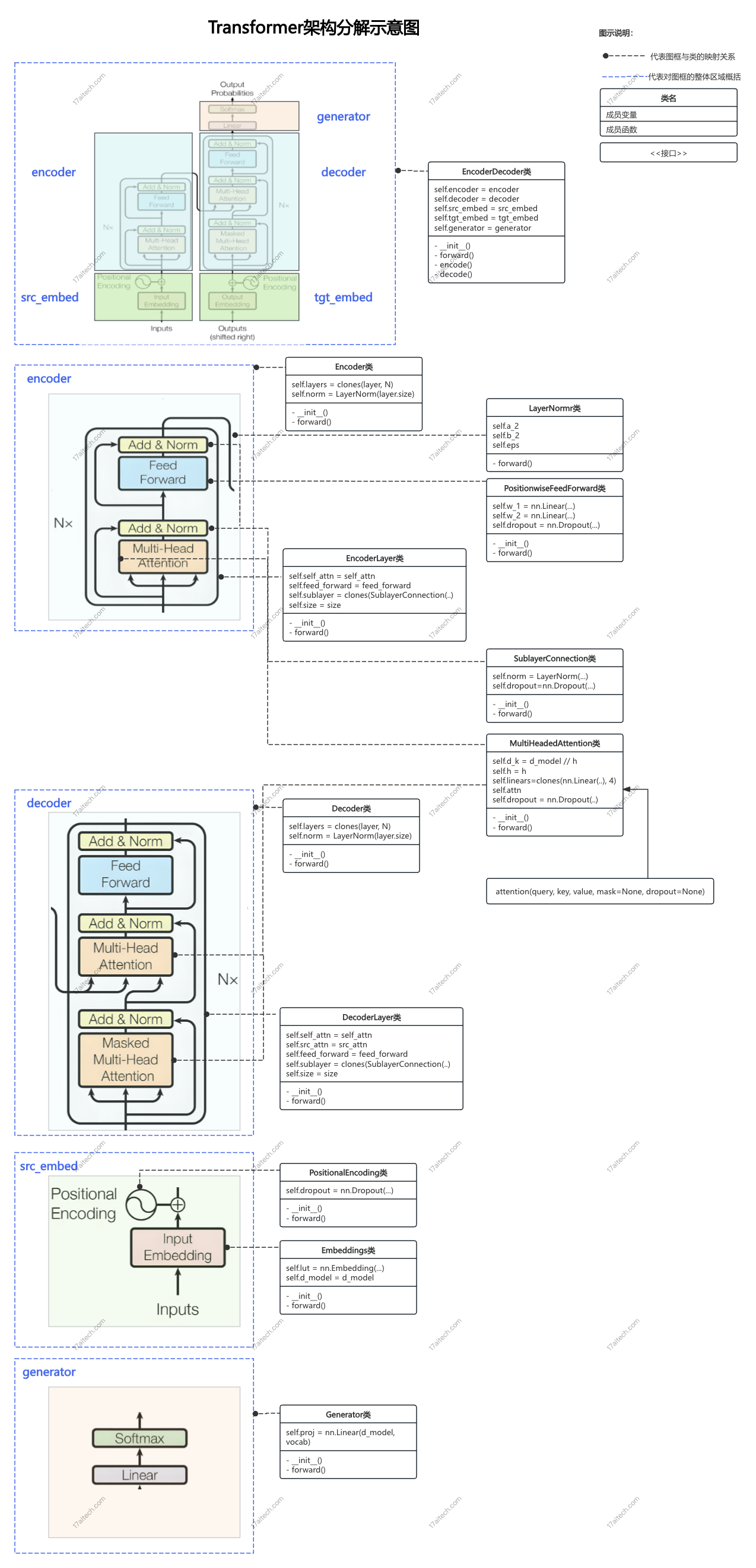
Transformer架构
class EncoderDecoder(nn.Module):
"""
A standard Encoder-Decoder architecture. Base for this and many
other models.
"""
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.generator = generator
def forward(self, src, tgt, src_mask, tgt_mask):
"Take in and process masked src and target sequences."
return self.decode(self.encode(src, src_mask), src_mask, tgt, tgt_mask)
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)
代码解析:
- Transformer架构总体由一个
EncoderDecoder类构成。 EncoderDecoder类的成员变量包含五部分:encoder:编码器,负责将输入序列编码为固定长度的向量。decoder:解码器,负责将编码后的向量解码为输出序列。src_embed:输入序列的嵌入层,将输入序列转换为固定维度的向量。tgt_embed:输出序列的嵌入层,将输出序列转换为固定维度的向量。generator:生成器,将解码后的向量转换为输出序列。
Encoder
首先查看 Encoder 类的结构:
源码如下:
class Encoder(nn.Module):
"Core encoder is a stack of N layers"
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
"Pass the input (and mask) through each layer in turn."
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
代码解析:
Encoder类的初始化函数中,分别创建了self.layers和self.norm。self.layers的创建方式是使用clones函数进行deepcopy的批量化创建clones函数可以创建指定数量的相同对象的列表。(Transformer的多层网络能力即由该函数体现)self.layers创建并实例化的layer对象,其类型为EncoderLayer。Encoder的前向传播forward函数中,会依次给每个EncoderLayer对象传入mask以便进行pad掩码操作。
self.norm对应是LayerNorm类,该类用于对输入序列进行归一化处理。
EncoderLayer
因为 Encoder 类是由多个 EncoderLayer构成,所以接着了解EncoderLayer类。
源码如下:
class EncoderLayer(nn.Module):
"Encoder is made up of self-attn and feed forward (defined below)"
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 2)
self.size = size
def forward(self, x, mask):
"Follow Figure 1 (left) for connections."
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)
代码解析:
EncoderLayer类中包含4个成员变量:self_attn:自注意力机制,用于对输入序列进行自注意力,该成员变量创建时会通过公共函数attension函数创建,并作为参数传入给self_attn成员变量。feed_forward:前馈网络,对应PositionwiseFeedForward类的对象。sublayer:包含两个SublayerConnection类的对象(对应图示中的Add&Norm),其作用是对输入序列进行归一化处理。size:输入序列的维度大小。
forward函数中:- self.sublayer[0]代表两个
SublayerConnection实例的列表第一个子层,即自注意力机制的连接。 lambda x: self.self_attn(x, x, x, mask)是一个匿名函数,它接收输入x并执行self.self_attn(x, x, x, mask)自注意力计算.self.self_attn(x, x, x, mask)表示使用输入x作为查询(Q)、键(K)和值(V),同时传入mask。- 然后,SublayerConnection 将处理这个输出,通常包括残差连接和层归一化。
- self.sublayer[0]代表两个
Decoder
其次,查看 Decoder 的实现。
源码如下:
class Decoder(nn.Module):
"Generic N layer decoder with masking."
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm