还是基础的anoconda,在opencv的时候就已经安装过了
此视频疑似在2020年底录制,因为他安装anaconda使用如下代码
bash ~/Downloads/Anaconda3-2020.07-Linux-x86_64.sh由于版本兼容问题,可能要mini conda
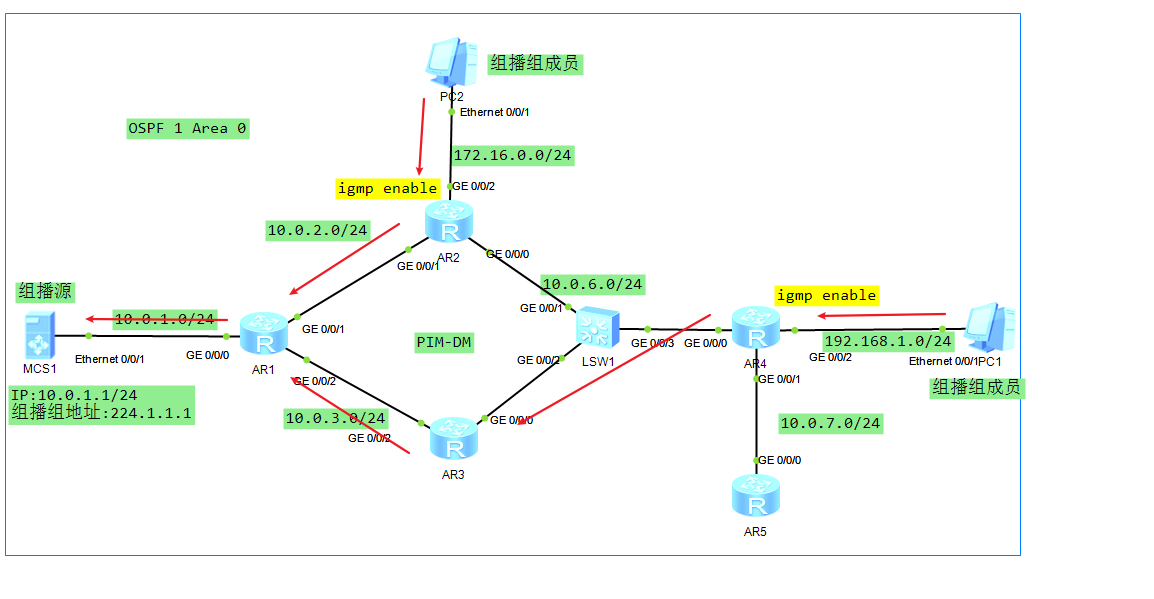
PASCAL VOC
PASCAL VOC挑战赛在2005年至2012年间展开。
PASCALVOC 2007:9963张图像,24640个标注;PASCALVOC 2012:11530张图像,27450个标注 该数据集有20个分类:
Person: person
Animal: bird, cat, cow, dog, horse, sheep
Vehicle: aeroplane, bicycle, boat, bus, car, motorbike, train Indoor: bottle, chair, dining table, potted plant, sofa, tv/monitor
链接:http:/host.robots.ox.ac.uk/pascal/VOC/voc2012/
MS COCO
MS COCO的全称是Microsoft Common Objects in Context,起源于是微软于 2014年出资标注的Microsoft COCO数据集,与ImageNet 竞赛一样,被视为是计 算机视觉领域最受关注和最权威的比赛之一。
在2017ImageNet竞赛停办后,COCO竞赛就成为是当前目标识别、检测等领域的一个最权威、最重要的标杆,也是目前该领域在国际上唯一能汇集Google、微软、
Facebook以及国内外众多顶尖院校和优秀创新企业共同参与的大赛。
http: //cocodataset.org/
COCO(Common Objects in Context)数据集包含20万个图像:11.5万多张训练集图像,
5千张验证集图像,2万多张测试集图像
80个类别中有超过50万个目标标注。
平均每个图像的目标数为7.2
目标检测指标


intersection over union
即iou=area of overlap/area of union,实际/网格预测
AP@.50 means the Ap with loU=0.50.
AP@.75 means the Ap with loU=0.75.
For COCO, AP is the average over multiple loU (the minimum loU to consider a positive match). AP@[.5:.95] corresponds to the average AP for loU from 0.5 to 0.95 with a step size of 0.05.
For the COCO competition, AP is the average over 10 loU levels on 80 categories (AP@[.50:.05:.95]: start from 0.5 to 0.95 with a step size of 0.05.
IoU的值越大趋于1,loose变为tight
average precison
平均精度ap,收集模型为苹果做所有预测,根据预测的置信水平排名,如果precision和ground truth匹配并且IoU>=0.5,就是正确的
举个例子,Rank=3,那么前三个就是现在预测出来的框,其中有两个对的一个错的。
感谢那个rank=3的哥们,已经懂了.rank=4的话,就是预测了四个其中两个预测对了,所以precision=0.5,recall=预测对的苹果/总苹果=2/5=0.4,依此类推


我觉得这个图片可能看看就好


- 前传耗时(ms):从输入一张图像到输出最终结果所消耗的时间,包括前处理耗时(如图像归一化)、网络前传耗时、后处理耗时(如非极大值抑制)
- 每秒帧数 FPS (Frames Per Second):每秒钟能处理的图像数量
- 浮点运算量(FLOPS):处理一张图像所需要的浮点运算数量,跟具体软硬件没有关系,可以公平地比较不同算法之间的检测速度。
在Ubuntu安装yolov5和pascal voc数据集
Anaconda 是一个用于科学计算的Python 发行版,支持Linux,Mac,Windows,包含了众多流行的科学计算、数 据分析的 Python 包。
1.先去官方地址下载好对应的安装包
下载地址:https:/www.anaconda.com/download/#linux 2.然后安装anaconda
bash -/Downloads/Anaconda3-2020.07-Linux-x86_64.sh
anaconda会自动将环境变量添加到PATH里面,如果后面你发现输出conda提示没有该命令,那么你需要执行命令 source~/. bashro更新环境变量,就可以正常使用了。
如果发现这样还是没用,那么需要添加环境变量。编辑~/.bashrc文件,在最后面加上
export PATH=/home/bai/anaconda3/bin: $PATH 注意:路径应改为自己机器上的路径
保存退出后执行:source~/.bashrc
再次输入conda list测试看看,应该没有问题。添加Aanaconda国内镜像配置
清华TUNA提供了Anaconda 仓库的镜像,运行以下三个命令:
conda config --add channels https: //mirrors. tuna. tsinghua. edu. cn/anaconda/pkgs/free/ conda config --add channels https: //mirrors. tuna. tsinghua. edu. cn/anaconda/pkgs/main/ conda config --set show_channel_urls yes
I 2)安装pytorch
注意:需要安装pytorch1.6以上的版本
首先为pytorch创建一个anaconda虚拟环境,环境名字可自己确定,这里本人使用pytorch1.6作为环境名:
conda create -n pytorch1.6 python=3.8
安装成功后激活pytorch 1.6环境:
conda activate pytorchl.6
在所创建的pytorch环境下安装pytorch的1.6版本,执行命令:
conda install pytorch torchvision cudatoolkit=10.2 -c pytorch
注意:10.2处应为cuda的安装版本号
编辑〜/.bashrc文件,设置使用pytorch1.6环境下的python3.8
alias python=1/home/bai/anaconda3/envs/pytorchl.6/bin/python3.8
注意:python路径应改为自己机器上的路径
保存退出后执行:source -/.bashrc
1)克隆yolov5项目
安装Git软件(https://github.com/downloads),克隆项目到本地
git clone https://github.com/ultralytics/yolov5.git
或者直接在浏览器github下载yolov5版本v3.1
2)使用清华镜像源:
在yolov5路径下执行:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
注意:simple不能少,是https而不是http
3) 下载预训练权重文件
下载yolov5s.pt, yolov5m.pt, yolov5l.pt, yolov5x.pt权重文件,并放置在weights文件夹下, 这个一定要版本适配,否则无法运行
4) 安装测试
测试图片:
在yolov5路径下执行,大概率是因为版本不一样,图片的放置位置变了
python detect.py --source ./inference/images/ --weights weights/yolov5s.pt --conf 0.4这是min的模型,还有一个大一点的网络模型改为yolov5x.pt,他的精度更为准确
3准备数据集
1)下载项目文件:
从百度网盘下载到yolov5目录下
• VOCtrainval_06-Nov-2007.tar
• V0Ctrainval_11 -May-2012.tar
• VOCtest_06-Nov-2007.tar
• get_voc_u b u ntu. py
2) 生成训练集和验证集文件
解压数据集
tar xf VOCtrainval.ll-May-2012.tar
tar xf VOCtrainval_06-Nov-2QQ7.tar
tar xf VOCtest_Q6-Nov-2007.tar
执行python脚本:
python get_voc_ubuntu.py
在VOCdevkit / vqC2007和VOCdevkit / VOC2012目录下可以看生成了文件夹labels ;
在yolov5目录下生成了文件2007_train.t:xt, 2007_val.txt, 2007_test.txt, 2012_train.txt, 2012_val.txttrain.txt,train.all.txt
在VOC目录下生成了 images和labels文件夹;
• labels下的文件是JPEGImages文件夹下每一个图像的yolo格式的标注文件,这是由annotations的xml标注文件转换来的
• train.txt和2007一test.txt分别给出了yolov5训练集图片和yolov5验证集图片的列表,含有每个图片的路径和文件名
4)修改配置文件
1)新建文件data/voc・new.yaml
可以复制data/voc.yaml再根据自己情况的修改;可以重新命名如:data/voc-new.yaml
然后修改配置参数
# download command/URL (optional)
#download: bash data/scripts/get_voc.sh
# train and val data as 1) directory: path/images/z 2) file: path/images.txt, or 3) list:
[pathl/images/, path2/images/]
train: VOC/images/train/ # 16551 images
val: VOC/images/val/ # 4952 images
2)新建文件models/yolov5s-voc.yaml
可以复制rnodels/yolov5s.yaml再根据自己情况的修改;可以重新命名如:models/yolov5s-voc.yaml
然后修改配置参数
#parameters nc:20 #number of classes
5)训练PASCAL VOC数据集
1) 训练命令
在yolov5路径下执行,
python train.py --data data/voc-new.yaml --cfg^models/yolov5s-voc.yaml --weights
weights/yolov5s.pt --batch-size 16 --epochs 200
2) 训练过程可视化:
在yolov5路径下执行
tensorboard --logdir=./runs
6)测试训练出的网络模型
1) 测试图片
等待吧,5.1g的显存占用,4060laptop绰绰有余,记得散热开大