因模型规模的扩展和需要处理的序列不断变长,transformer逐渐出现计算量激增、计算效率下降等问题,研究者们提出了Mamba—— 一种创新的线性时间序列建模方法,它结合了递归神经网络(RNN)和卷积神经网络(CNN)的特点,以提高处理长序列数据时的计算效率。
为帮助同学们获取灵感,我整理了5种今年最新的Mamba结合创新方案,希望能给各位的学术研究提供一些帮助。
1、MambaVision: A Hybrid Mamba-Transformer Vision Backbone
方法:
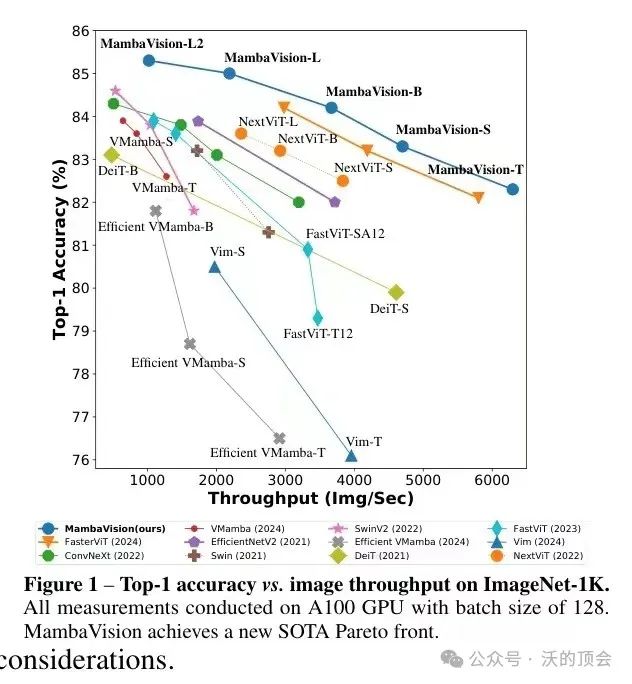
本文提出了一种新颖的混合Mamba-Transformer架构,称为MambaVision,这是一种专门为视觉应用量身定制的新型混合骨干网络。MambaVision是首次研究和开发同时包含Mamba和Transformers的混合架构以用于计算机视觉应用。MambaVision 系列包括各种模型配置,以满足不同的设计标准和应用需求,为各种视觉任务提供灵活而强大的工具。结果表明,在Mamba架构的最后几层配备几个自注意力块,大大提高了捕获长距离空间依赖关系的建模能力。基于这个发现,引入了一系列具有分层架构的MambaVision模型,以满足各种设计标准。
创新点:
-
引入了一个重新设计的面向视觉的Mamba块,提高了原始Mamba架构的准确性和图像吞吐量。
-
系统地调查了Mamba和Transformer块的集成模式,并证明在最后阶段整合自注意力块显著提高了模型捕获全局上下文和长距离空间依赖的能力。
-
介绍了MambaVision,这是一个新颖的混合Mamba Transformer模型。分层的MambaVision在ImageNet-1K数据集上实现了Top-1和图像吞吐量折衷的新SOTA帕累托前沿
需要的同学添加公众号【沃的顶会】 回复 Mamba5 即可全部领取
2、An Empirical Study of Mamba-based Language Models
方法:
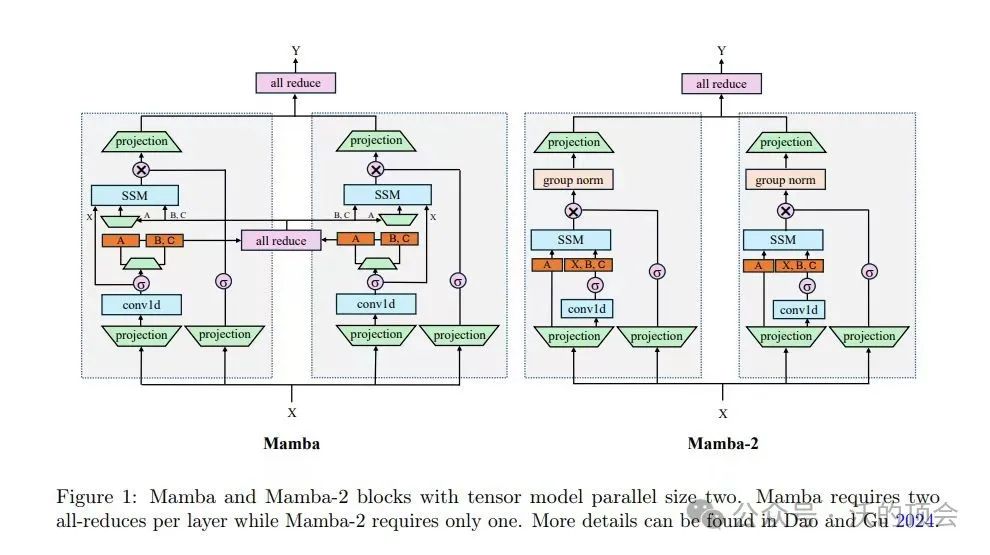
本文通过对比8B参数的Mamba、Mamba-2和Transformer模型在相同数据集上的表现,探讨了SSM架构在大规模训练下的优势与不足。结果表明,在更大训练预算的情况下,纯SSM模型依旧能在下游任务上超过Transformer,但上下文学习和信息检索能力有所局限。此外,混合体系结构 Mamba-2-Hybrid 在所有评估的标准任务中均优于 Transformer 模型,并且在推理时的生成速度预计快8倍。论文还验证了长上下文能力,并公开了训练模型所需的代码和检查点。
创新点:
-
对比了基于状态空间模型和注意力机制的两类语言模型在大规模训练下的表现,提出了Mamba-2-Hybrid模型,将状态空间模型与注意力机制有机结合,使模型既具备状态空间模型的高效推理,也具备注意力模型的语言理解能力。
-
系统地对比了两大类语言模型架构的性能,证明了状态空间模型与注意力机制的有效融合,为语言模型的研究提供了新的方向。
-
Mamba-2-Hybrid模型相比Transformer,在12个标准语言任务上的平均精度提升了2.65分。
需要的同学添加公众号【沃的顶会】 回复 Mamba5 即可全部领取
3、Weak-Mamba-UNet:Visual Mamba Makes CNN and ViT Work Better for Scribble-based Medical Image Segmentation
方法:
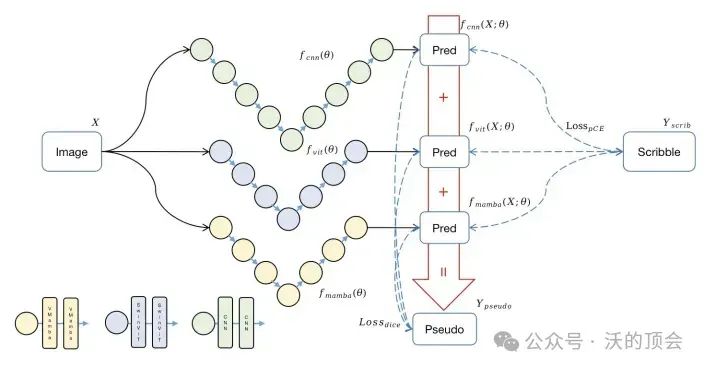
本文介绍了一种创新的弱监督学习框架Weak-Mamba-UNet,该框架利用了卷积神经网络(CNN)、视觉Transformer(ViT)和最先进的Visual Mamba(VMamba)架构,用于医学图像分割,特别是在处理基于涂鸦注释时。该框架采用了三种不同的架构,但具有相同的对称编码器-解码器网络:基于CNN的UNet用于详细的局部特征提取,基于Swin Transformer的SwinUNet用于全面的全局上下文理解,基于VMamba的Mamba-UNet用于高效的长程依赖建模。其在公开可用的MRI心脏分割数据集上表现出色,Dice系数达到0.9171,准确率达到0.9963。
创新点:
-
基于Mamba的分割网络与WSL结合用于基于涂鸦标注的医疗图像分割的整合。
-
开发一种新颖的多视图交叉监督框架,该框架能够在有限信号监督的条件下,实现三种不同架构:CNN,ViT和Mamba的协同操作。
-
在公开可用的预处理数据集上,对Weak-Mamba-UNet进行的基于涂鸦实验演示,展示了Mamba架构提高CNN和ViT在弱监督学习(WSL)任务中性能的能力。