文章目录
- 一、卷积网络
- 1.1 卷积的参数量
- 1.2 卷积的计算量
- 1.3 降低模型参数量和计算量的方法
- 1.3.1 GoogLeNet 使用不同大小的卷积核
- 1.3.2 ResNet 使用1×1卷积压缩通道数
- 1.3.3 可分离卷积
- 二、Transformer
- 2.1 注意力机制 Attention Mechanism
- 2.2 多头注意力 Multi-head (Self-)Attention
- 2.3 Vision Transformer
- 2.4 Swin Transformer
- 三、模型学习的范式
- 3.1 监督学习
- 3.2 自监督学习
- 四、tips
- 4.1 权重初始化
- 4.2 学习率
- 4.2.1 学习率对训练的影响
- 4.2.2 学习率退火 Annealing
- 4.2.3 学习率升温 Warmup
- 4.2.4 Linear Scaling Rule
- 4.3 梯度更新算法
- 4.3.1 自适应梯度算法
- 4.3.2 正则化与权重衰减 Weight Decay
- 4.4 早停 Early Stopping
- 4.5 模型权重平均 EMA
- 五、标签平滑 Label Smoothing
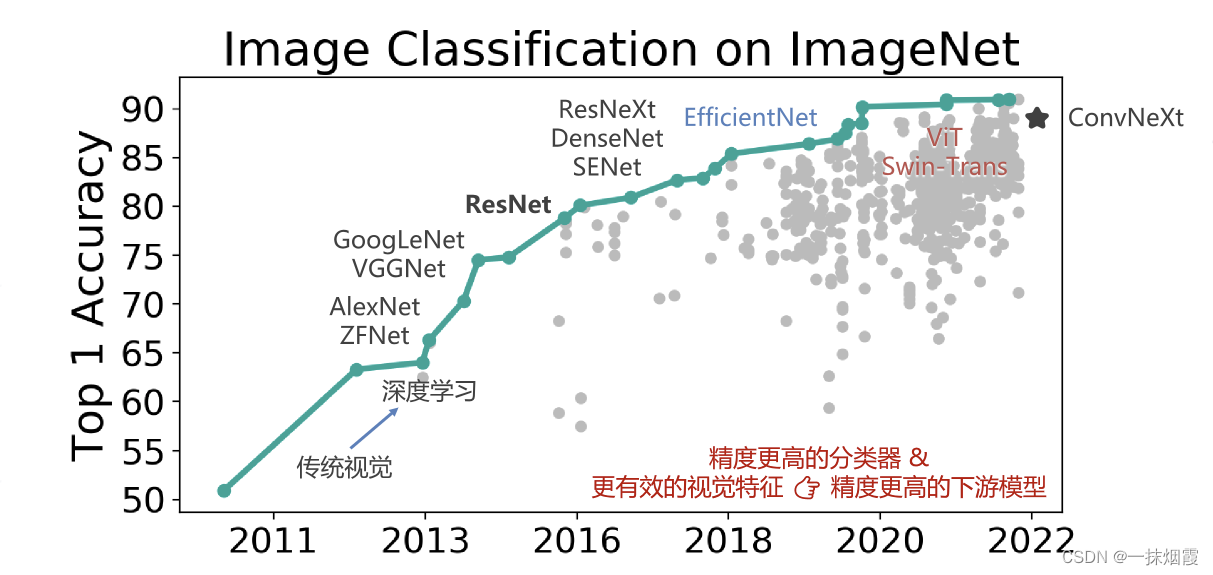
一、卷积网络
1.1 卷积的参数量
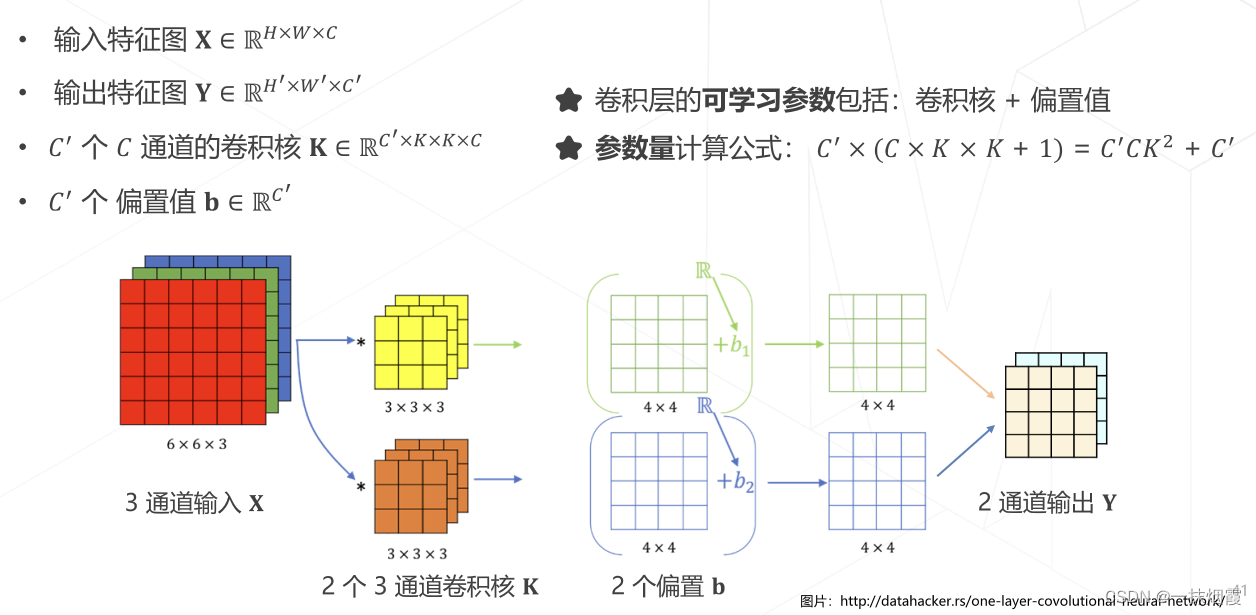
1.2 卷积的计算量
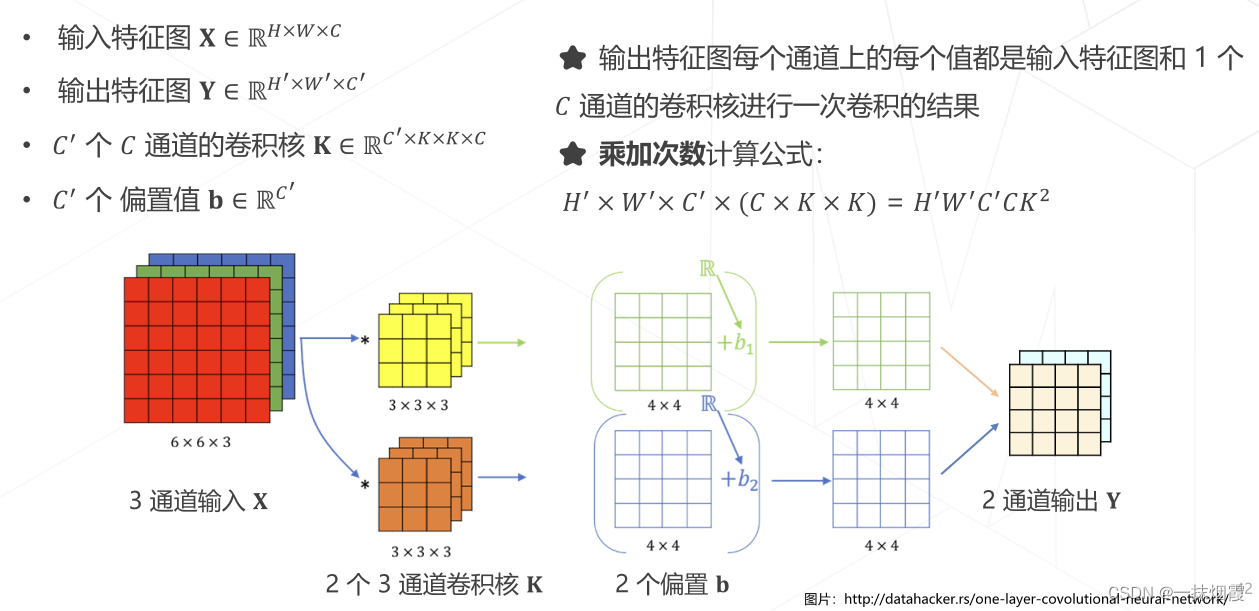
1.3 降低模型参数量和计算量的方法
•降低通道数 C′ 和 C(平方级别)
•减小卷积核的尺寸 K(平方级别)
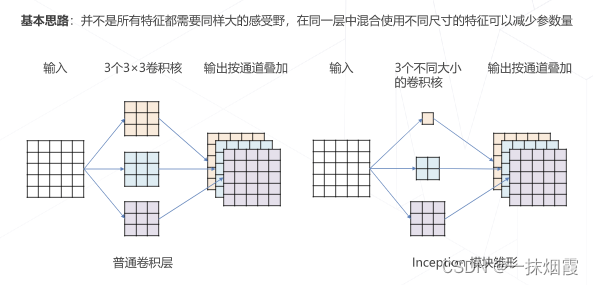
1.3.1 GoogLeNet 使用不同大小的卷积核
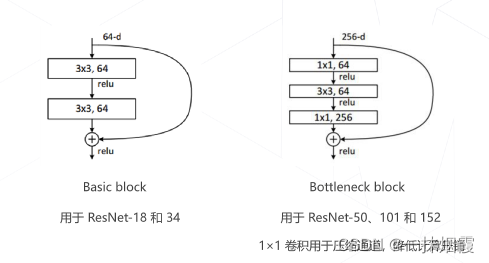
1.3.2 ResNet 使用1×1卷积压缩通道数
1.3.3 可分离卷积
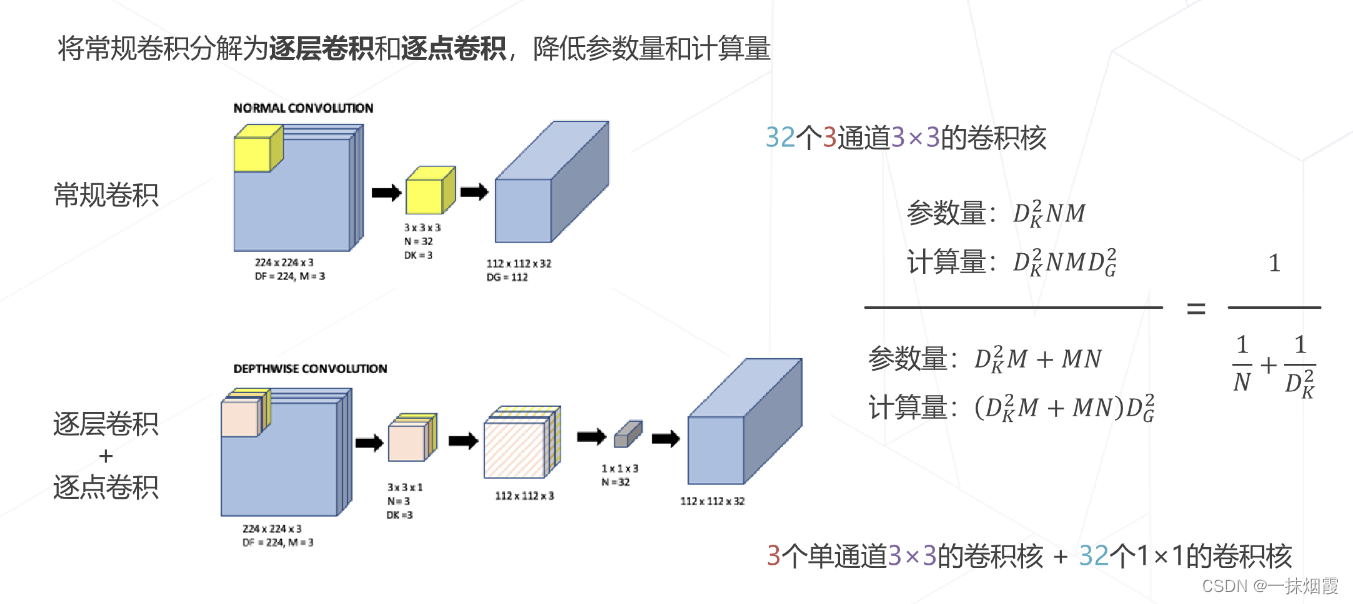
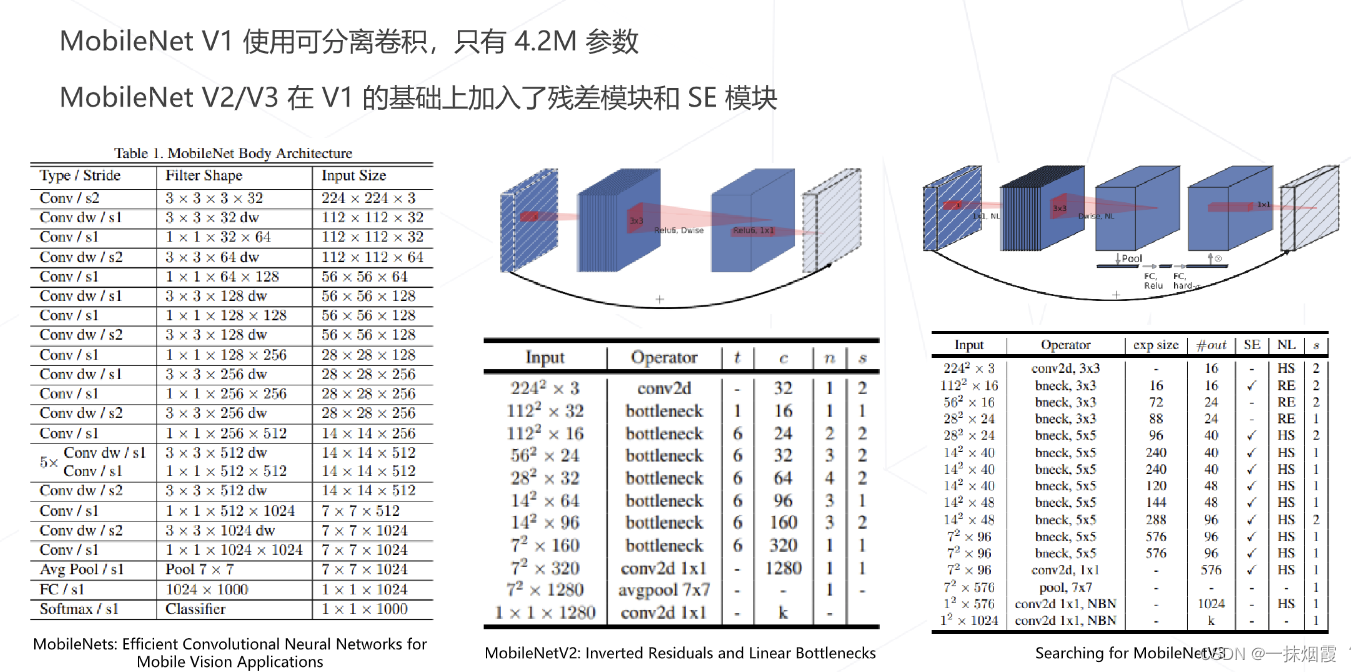

二、Transformer
2.1 注意力机制 Attention Mechanism
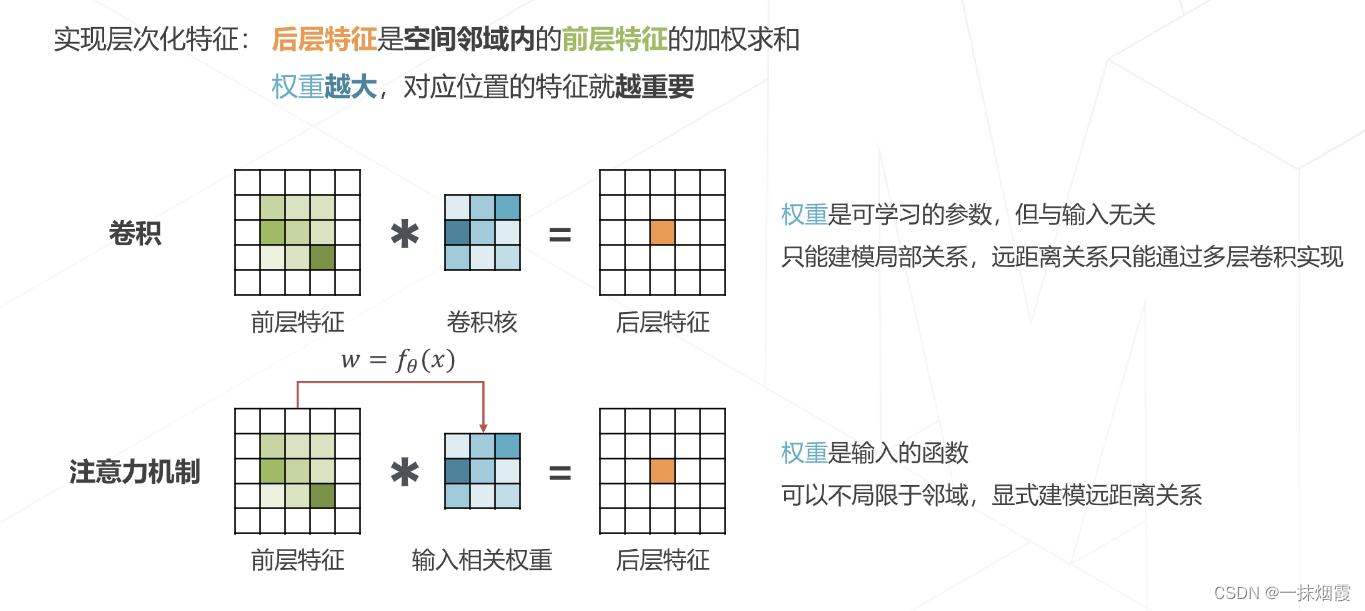
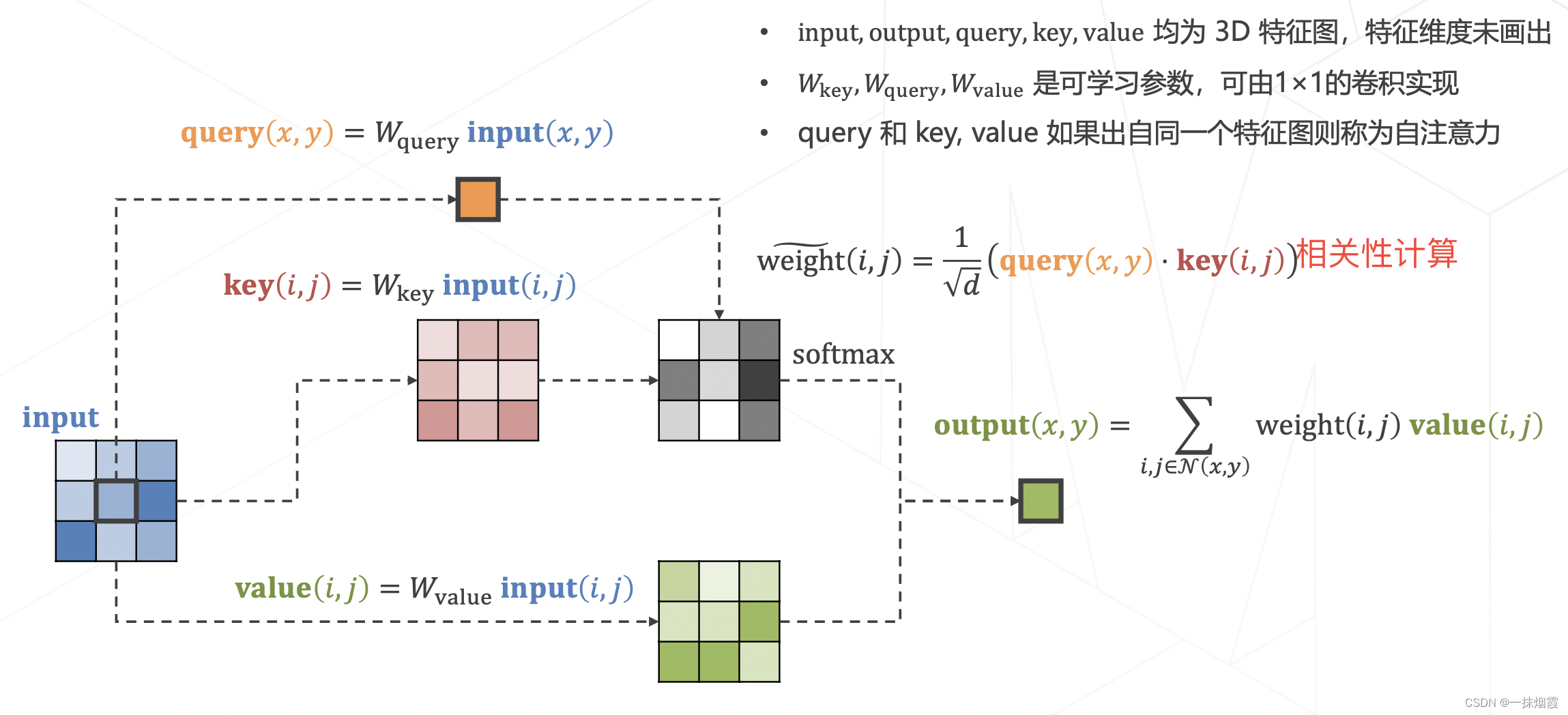
query:查询特征,即我关心的特征有哪些。以自动驾驶举例,比如我关心车、行人、车道等三类特征;
key:图像中有什么,比如图像中有车和车道这两种特征。
2.2 多头注意力 Multi-head (Self-)Attention
仿造卷积使用多组通道的特征就多头注意力机制
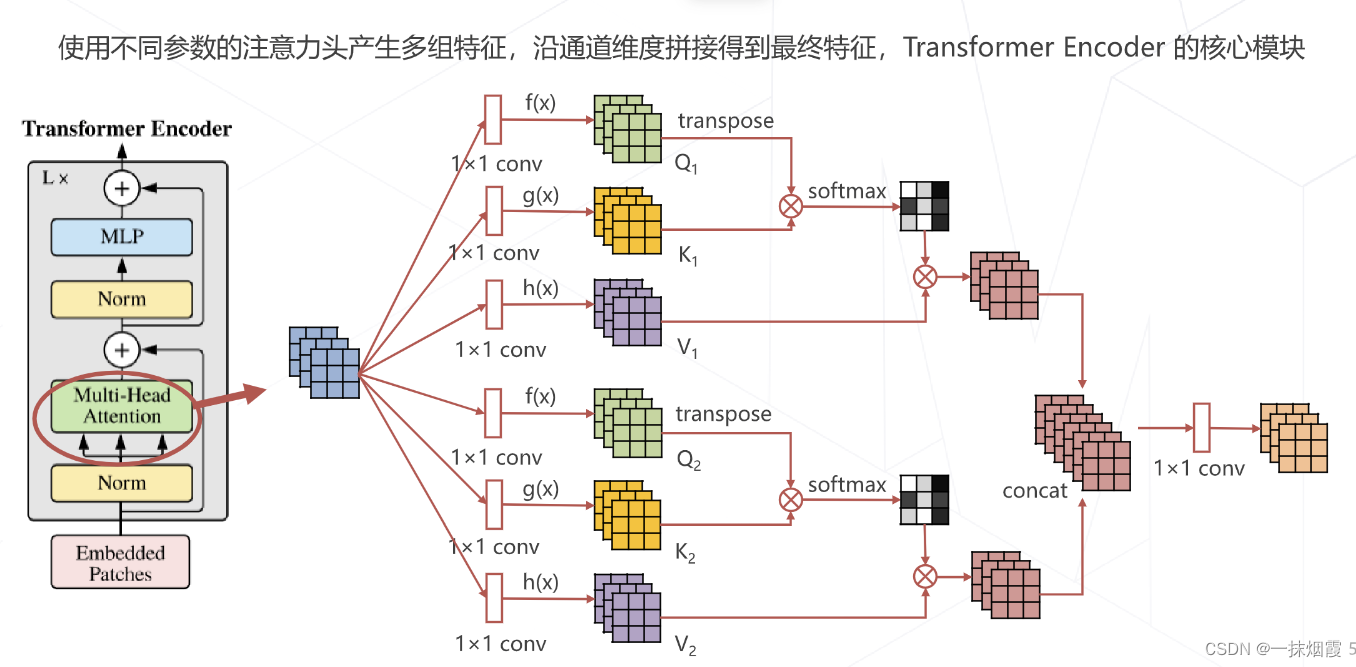
2.3 Vision Transformer

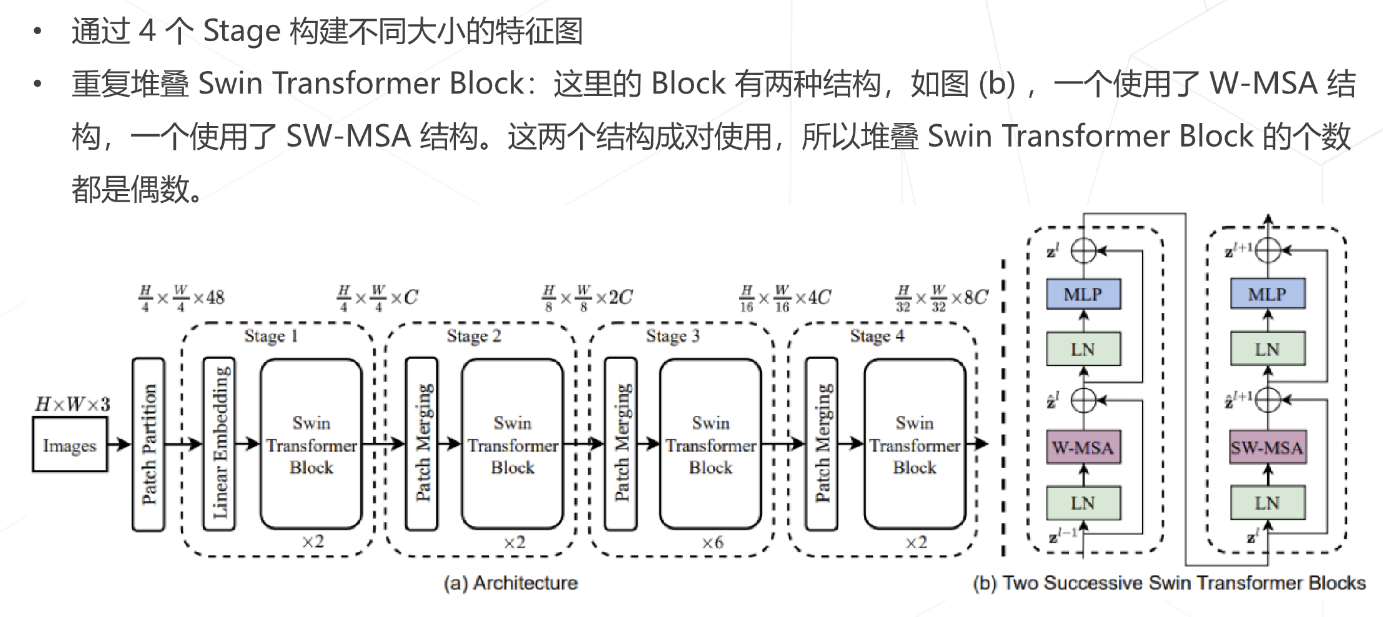
2.4 Swin Transformer
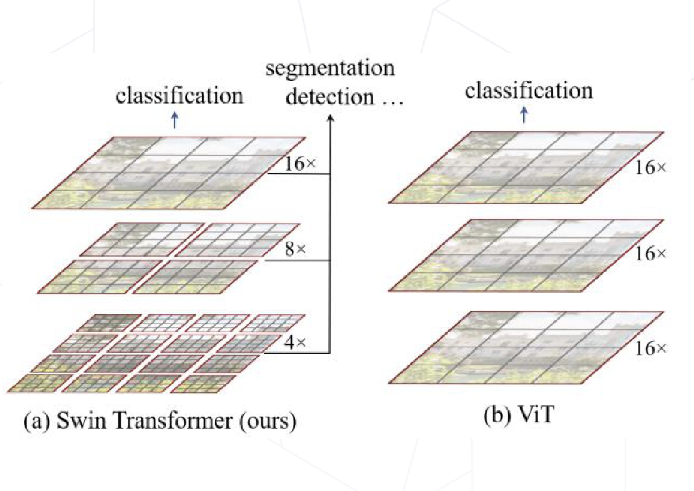
- Vision Transformer 的特征图是是直接下采样 16 倍得到的,后面的特征图也是维持这个下采样率不变,缺少了传统卷积神经网络里不同尺寸特征图的层次化结构。所以,Swin Transformer 提出了分层结构(金字塔结构)Hierarchical Transformer。
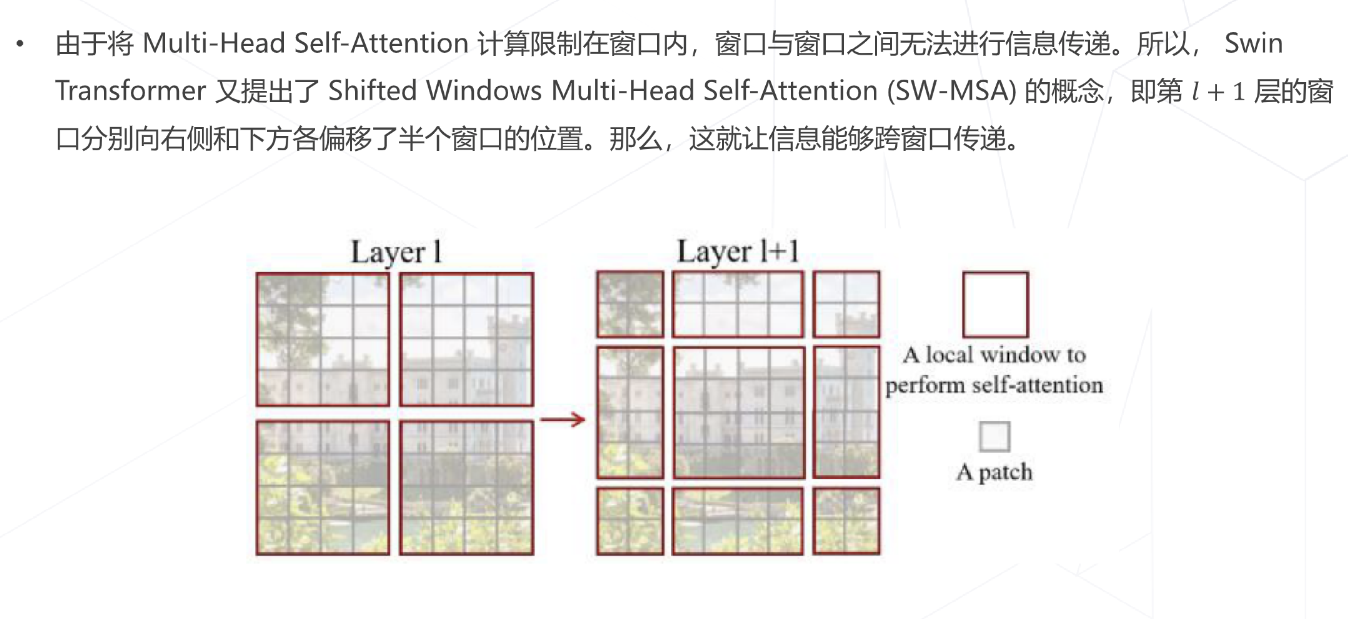
- 同时,相对于 Vision Transformer 中直接对整个特征图进行 Multi-Head Self-Attention,Swin Transformer 将特征图划分成了多个不相交的区域(Window),将 Multi-Head Self-Attention 计算限制在窗口内,这样能够减少计算量的,尤其是在浅层特征图很大的时候。
三、模型学习的范式
3.1 监督学习
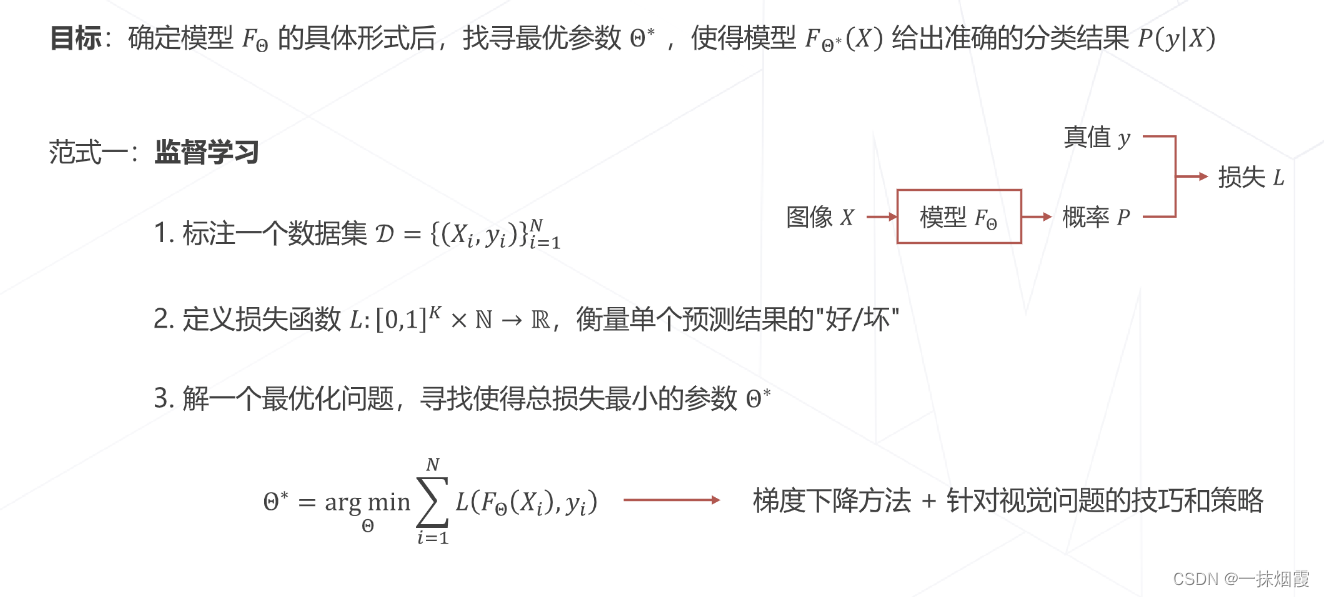
3.2 自监督学习
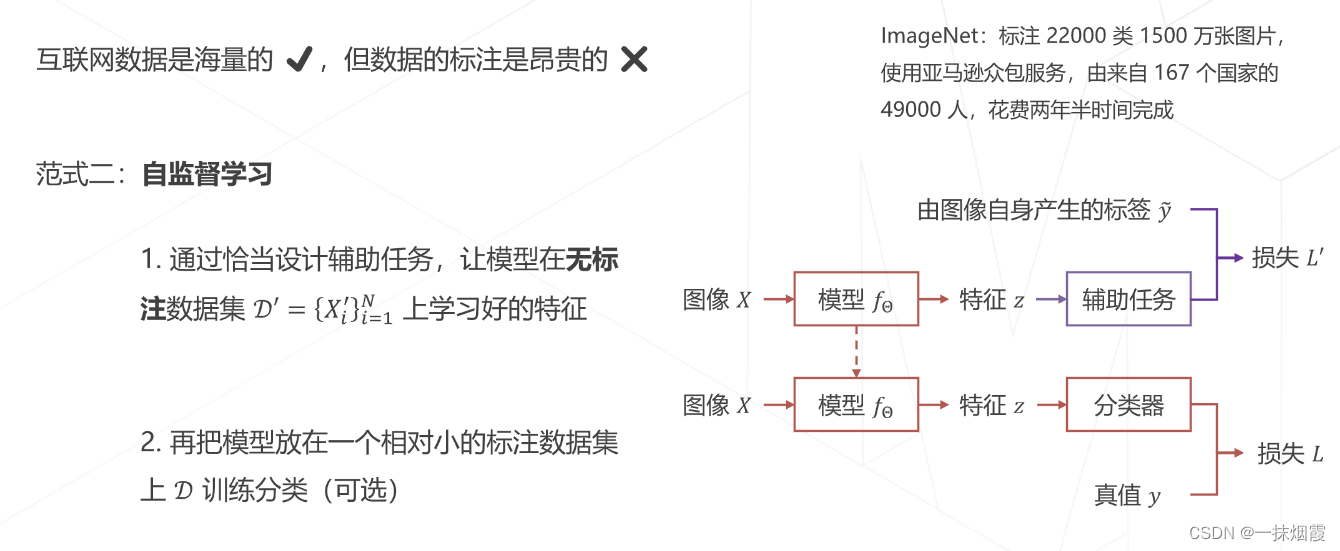
四、tips
4.1 权重初始化

4.2 学习率
4.2.1 学习率对训练的影响
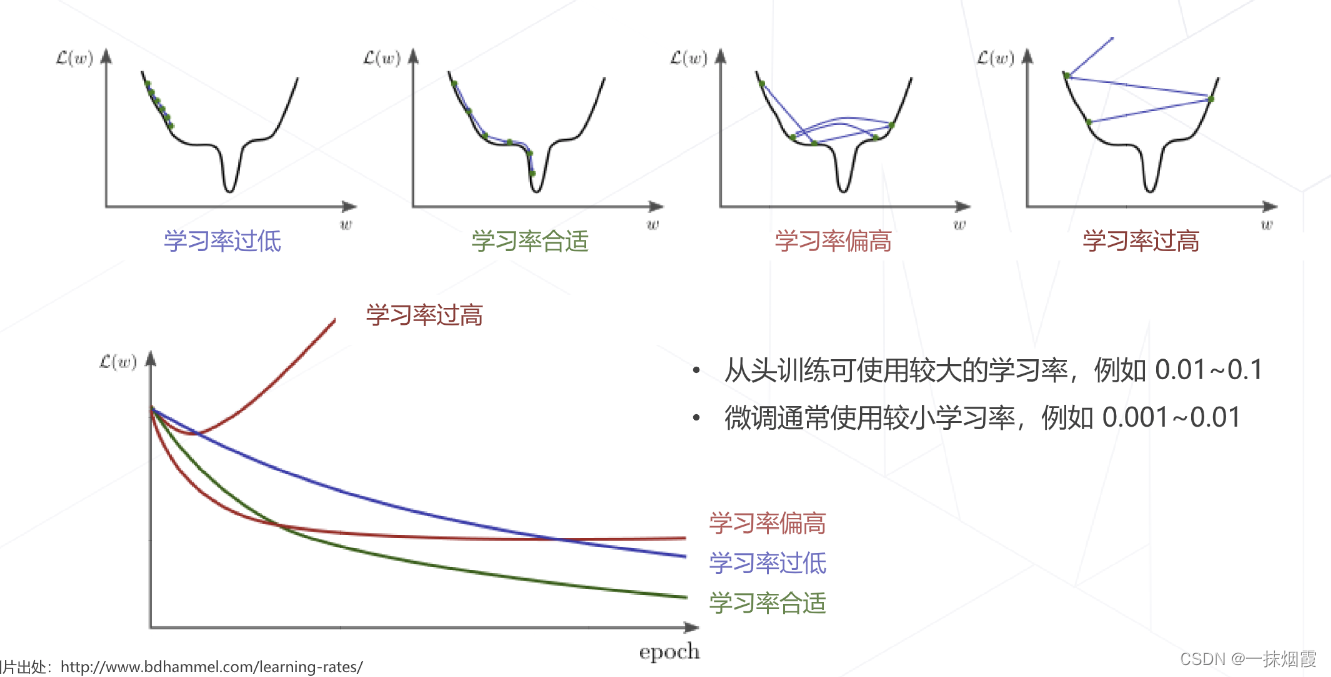
4.2.2 学习率退火 Annealing
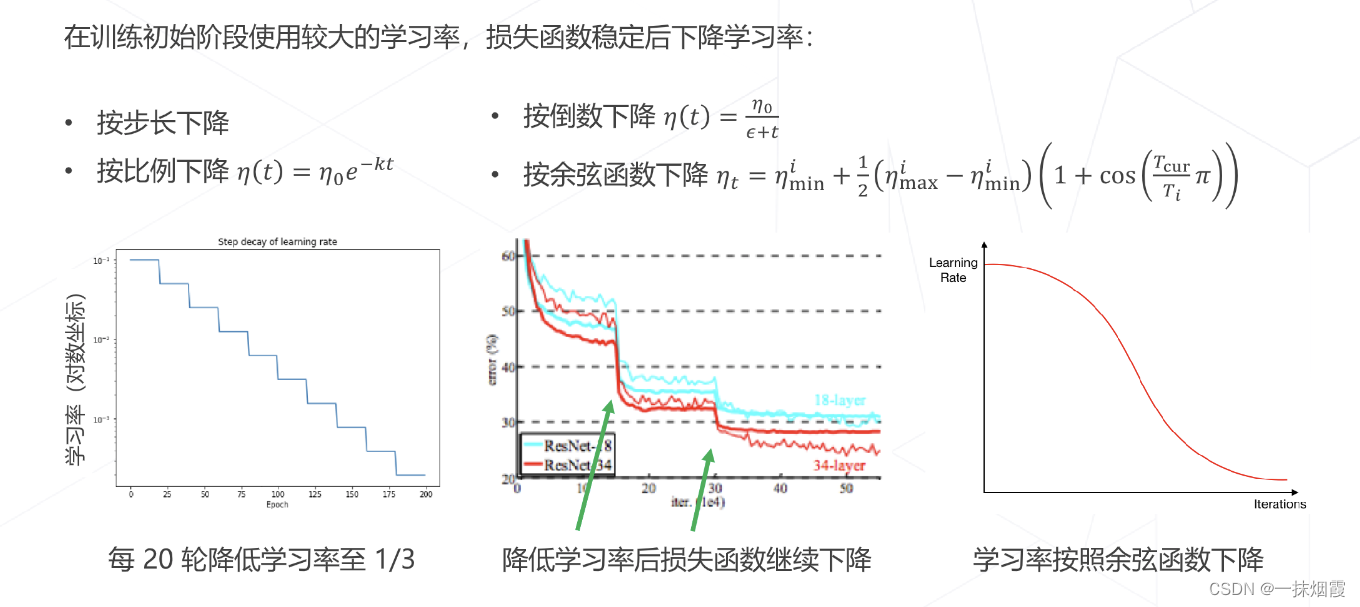
4.2.3 学习率升温 Warmup
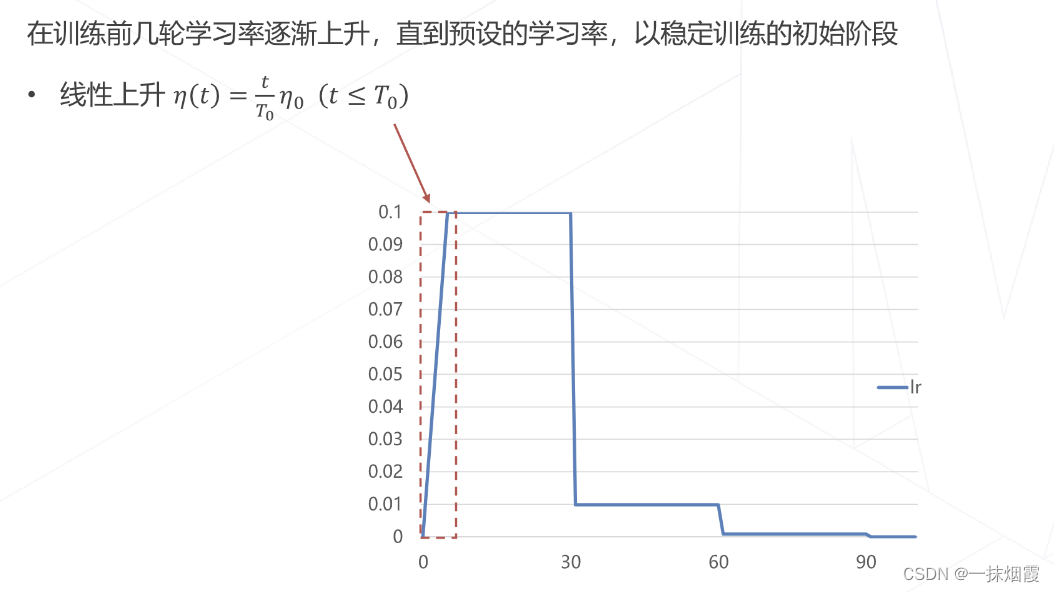
4.2.4 Linear Scaling Rule

4.3 梯度更新算法
4.3.1 自适应梯度算法
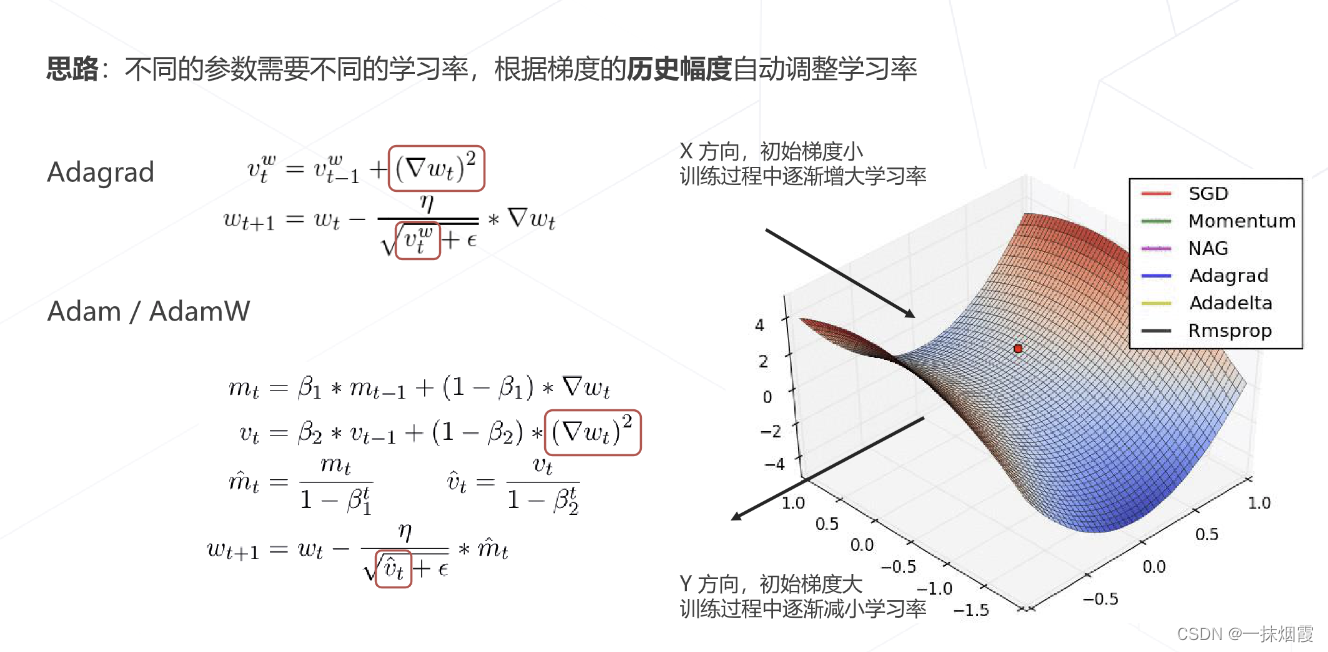
4.3.2 正则化与权重衰减 Weight Decay

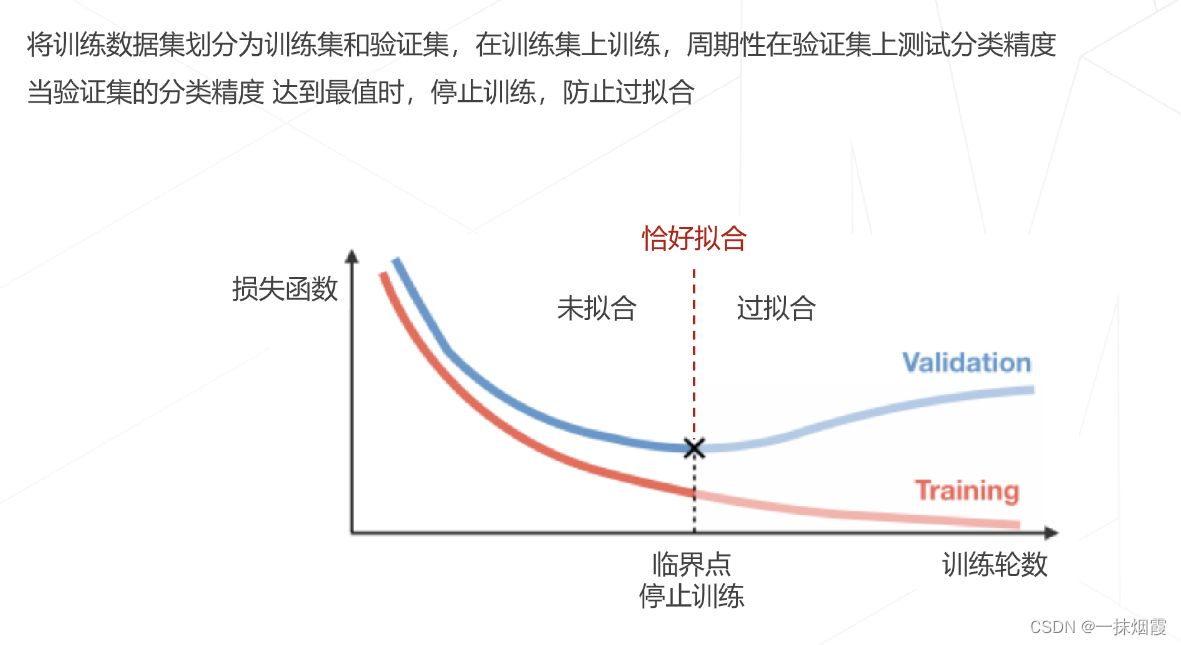
4.4 早停 Early Stopping
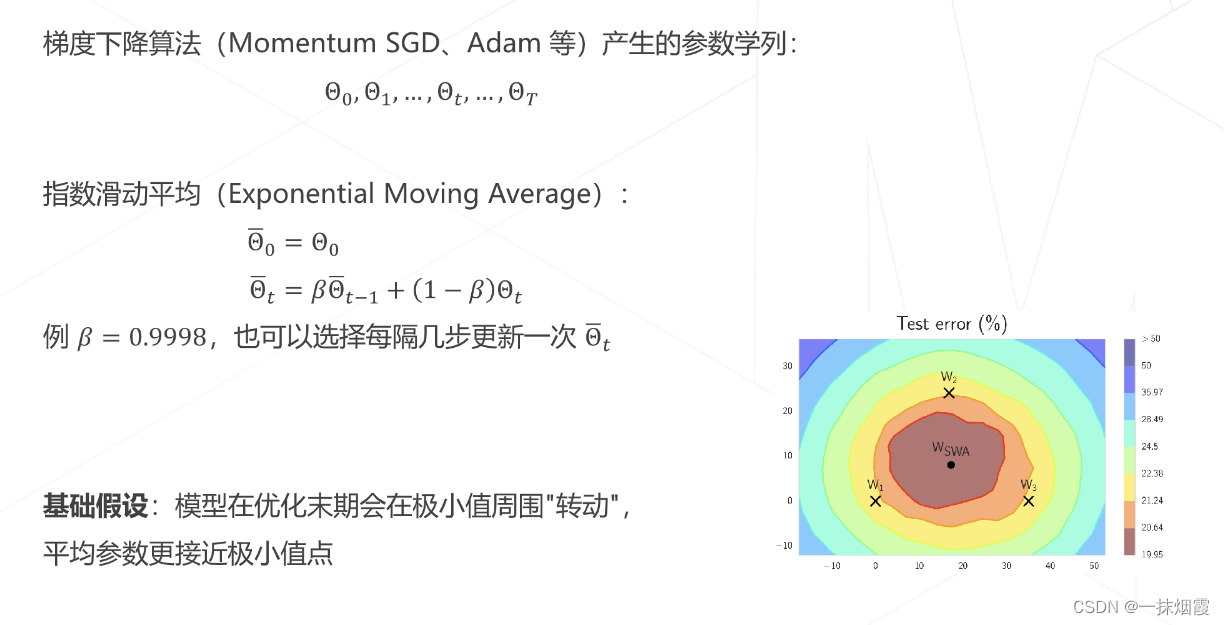
4.5 模型权重平均 EMA
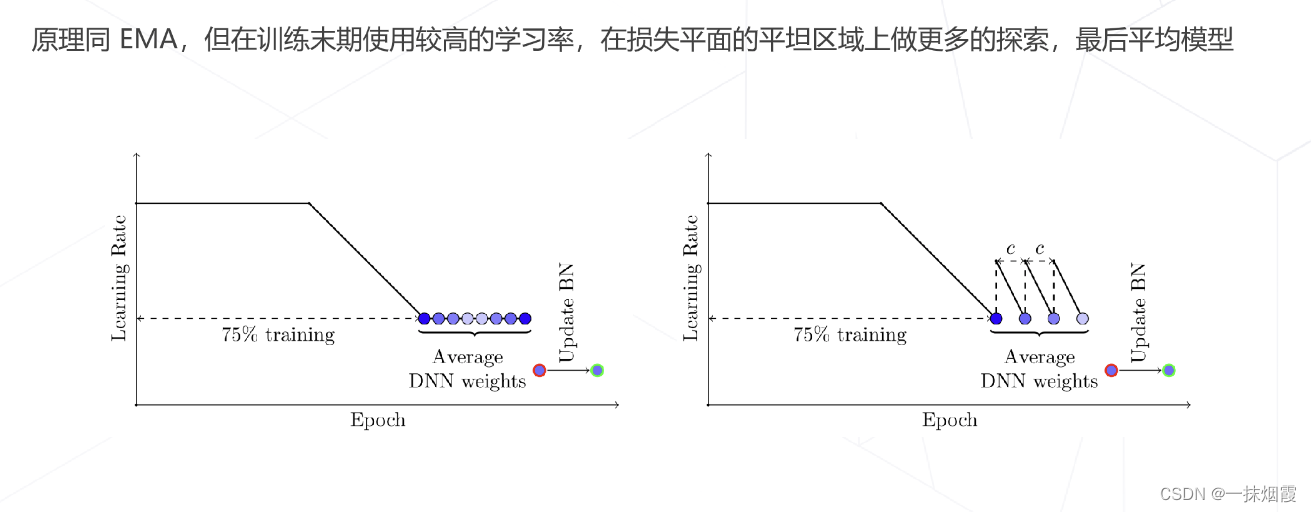
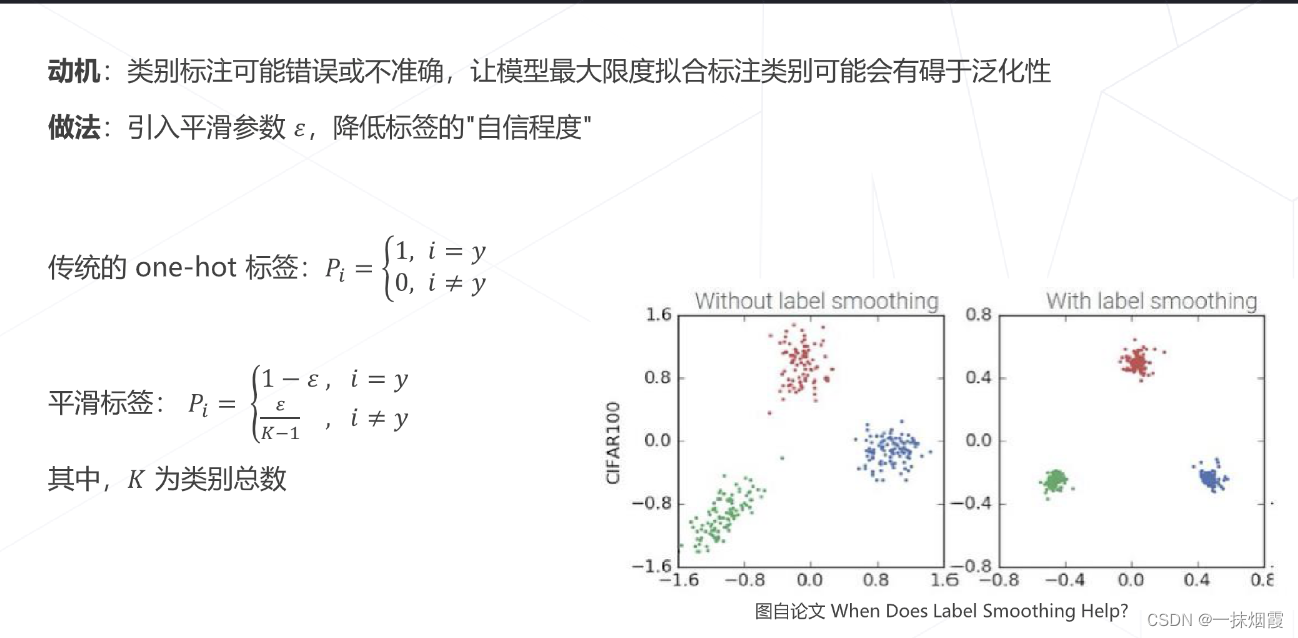
五、标签平滑 Label Smoothing