文章目录
- 缓慢变化维
- 拉链表 -- 理论
- 缓慢变化维解决方案:
- 拉链表场景:
- 拉链表缺点:
- 拉链表查询优化:
- 拉链表 -- 示例
- sql
- 查询方式
- 补充
- 流水表
- 全量表
- 增量表
缓慢变化维
- 什么是缓慢变化维?
缓慢变化维,简称SCD(Slowly Changing Dimensions)
一些维度表的数据不是静态的,而是会随着时间而缓慢地变化(这里的缓慢是相对事实表而言,事实表数据变化的速度比维度表快)这种随着时间发生变化的维度称之为缓慢变化维,把处理维度表数据历史变化的问题为缓慢变化维问题,简称SCD问题。
具体可参考:https://cloud.tencent.com/developer/article/1780529
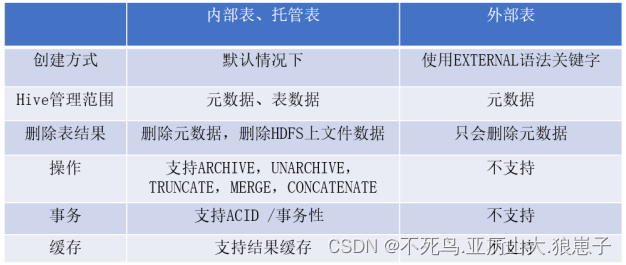
拉链表 – 理论
缓慢变化维解决方案:
-
SCD解决方案 - 保留原始值
某一个属性值绝不会变化。事实表始终按照该原始值进行分组。例如:
出生日期的数据,始终按照用户第一次填写的数据为准。 -
SCD解决方案 - 改写属性值
对其相应需要重写维度行中的旧值,以当前值替换。因此其始终反映最近的情况。
当一个维度值的数据源发生变化,并且不需要在维度表中保留变化历史时,通常用新数据来覆盖旧数据。这样的处理使属性所反映的中是最新的赋值。 -
SCD解决方案 - 增加维度新行
数据仓库系统的目标之一是正确地表示历史。典型代表就是拉链表。
保留历史的数据,并插入新的数据。例如: 用户维度表
拉链表场景:
储存空间大
字段变更:上亿数据量,部分字段更新 (用户的地址,产品的描述信息,品牌信息等等;)
查询历史状态(病毒第一次出现日期,最后一次出现日期)
统计历史行为次数
拉链表缺点:
join消耗资源
不容易维护,如果有一天数据错误从这天到现在的数据都要重新跑
查询性能低,存放N年数据,表数据量很大影响性能
拉链表查询优化:
拉链表当然也会遇到查询性能的问题,比如说我们存放了5年的拉链数据,那么这张表势必会比较大,
当查询的时候性能就比较低了,个人认为两个思路来解决:
1.在一些查询引擎中,我们对start_date和end_date做索引,这样能提高不少性能。
2.保留部分历史数据,比如说我们一张表里面存放全量的拉链表数据,然后再对外暴露一张只提供近3个月数据的拉链表。
3. 查询检索性能没有明显提高,但可以将start_dt和end_dt当成分区字段,已提高检索性能;
拉链表 – 示例
sql
测试数据:
('001', '待审核', '2019-12-18', '2019-12-20'),
('002', '待售', '2019-12-19', '2019-12-20'),
('003', '在售', '2019-12-20', '2019-12-20'),
('004', '已删除', '2019-12-15', '2019-12-20'),
('001', '待售', '2019-12-18', '2019-12-21'),
('005', '待审核', '2019-12-21', '2019-12-21'),
('006', '待审核', '2019-12-21', '2019-12-21');
ods表:
-- 创建ods层表
create table if not exists ods_product_2(
goods_id string, -- 商品编号
goods_status string, -- 商品状态
createtime string, -- 商品创建时间
modifytime string -- 商品修改时间
)
partitioned by (dt string)
row format delimited fields terminated by ',' stored as TEXTFILE;
dw表:
-- dw层 创建拉链表
create table if not exists dw_product_2(
goods_id string, -- 商品编号
goods_status string, -- 商品状态
createtime string, -- 商品创建时间
modifytime string, -- 商品修改时间
dw_start_date string, -- 生效日期
dw_end_date string -- 失效日期
)
row format delimited fields terminated by ',' stored as TEXTFILE;
拉链逻辑:
在原有dw层表上,添加额外的两列
生效日期(dw_start_date)
失效日期(dw_end_date)
只同步当天修改的数据到ods层
拉链表算法实现
编写SQL处理当天最新的数据(新添加的数据和修改过的数据)
编写SQL处理dw层历史数据,重新计算之前的dw_end_date
拉链表的数据为:当天最新的数据 UNION ALL 历史数据
SELECT
t1.goods_id,t1.goods_status,t1.createtime,t1.modifytime,t1.dw_start_date,
CASE WHEN (t2.goods_id IS NOT NULL AND t1.dw_end_date > '2019-12-21') THEN '2019-12-21' --这里保证只修改最新的那条数据
ELSE t1.dw_end_date
END AS dw_end_date
FROM dw_product_2 t1
LEFT JOIN (SELECT * FROM ods_product_2 WHERE dt='2019-12-21') t2 -- ods昨天数据和今天的dw数据关联,只有修改的
ON t1.goods_id = t2.goods_id
union ALL
select
goods_id, -- 商品编号
goods_status, -- 商品状态
createtime, -- 商品创建时间
modifytime, -- 商品修改时间
modifytime as dw_start_date, -- 生效日期
'9999-12-31' as dw_end_date -- 失效日期
from
ods_product_2 where dt='2019-12-21' -- 只有新增和修改的数据
order by dw_start_date, goods_id;

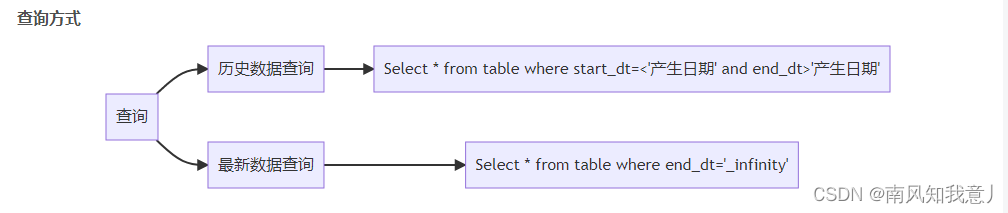
查询方式
-- 获取2019-12-20日的历史快照数据
SELECT * FROM dw_product_2 WHERE dw_start_date<='2019-12-20' AND dw_end_date>'2019-12-20';
-- 获取最新的商品快照数据
SELECT * FROM dw_product_2 WHERE dw_end_date = '9999-12-31';
补充
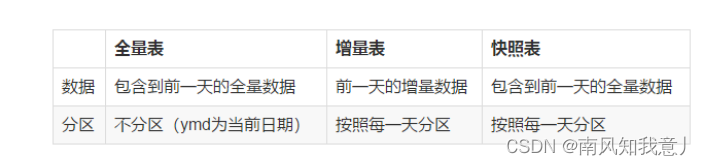
流水表
流水表存放的是一个用户的变更记录,比如在一张流水表中,一天的数据中,会存放一个用户的每条修改记录,但是在拉链表中只有一条记录。
这是拉链表设计时需要注意的一个粒度问题。我们当然也可以设置的粒度更小一些,一般按天就足够。
全量表
每天的所有的最新状态的数据。
(1)全量表,有无变化,都要报
(2)每次上报的数据都是所有的数据(变化的 + 没有变化的)
增量表
新增数据,增量数据是上次导出之后的新数据。
(1)记录每次增加的量,而不是总量;
(2)流量是指在一定时间内的增量;
(3)流量一般设计成增量表(日报-常用、月报);
(4)流量和存量的区别:流量是增量;存量是总量;
(5)增量表,只报变化量,无变化不用报



![[SSL]微信实机测试 request:fail -2:netLERR_FAILED](https://img-blog.csdnimg.cn/c23213c45a7d4d6bafdba24eb8549690.png)
![[数仓]埋点数据接入](https://img-blog.csdnimg.cn/img_convert/9d0decf94ed84b2dbad7a13130c35d8c.png)