第40个视频的1:03:31
一、采集flume
日志服务器:将日志采集到本地,共有两个日志服务器,因此要安装两台flume,每个flume采集其所在服务器上的日志
source:taildir source
可以实时的读取文件中的数据,支持断点续传
1、flle_to_kafka.conf
文件存于:在flume目录下创建一个job目录
#定义组件
a1.sources=r1
a1.chennls=c1
#配置source
a1.sources.r1.type=TAILDIR
a1.sources.r1.filegroups=f1
a1.sources.r1.filegroup.f1=/opt/module/aoolog/log/app.*
#监控这个文件夹下以app.开头的文件,日志是按天滚动的,一天一个文件,文件格式:app.yyyy-MM-dd.log
a1.sources.r1.positionFile=/opt/module/flume/taildir_position.json #设置断点续传位置的
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = 包名.ETLInterceptor$Builder #配置拦截器
#配置channels
a1.chennls.c1.type=org.apache.flume.channel.kafka.KafkaChannel
a1.chennls.c1.kafka.bootstrap.servers=hadoop1:9092,hadoop2:9092,hadoop3:9092
#往哪个kafka集群写数据
a1.chennls.c1.kafka.topic=topic_log #写到哪个topic
a1.chennls.c1.parseAsFlumeEvent=false
#为false将数据以正常格式写入kafka
#为true(默认)将数据以Flume Event(header+body)的形式写入kafka。这样读出来的时候也是Event
#组装
a1.sources.r1.channels=c1
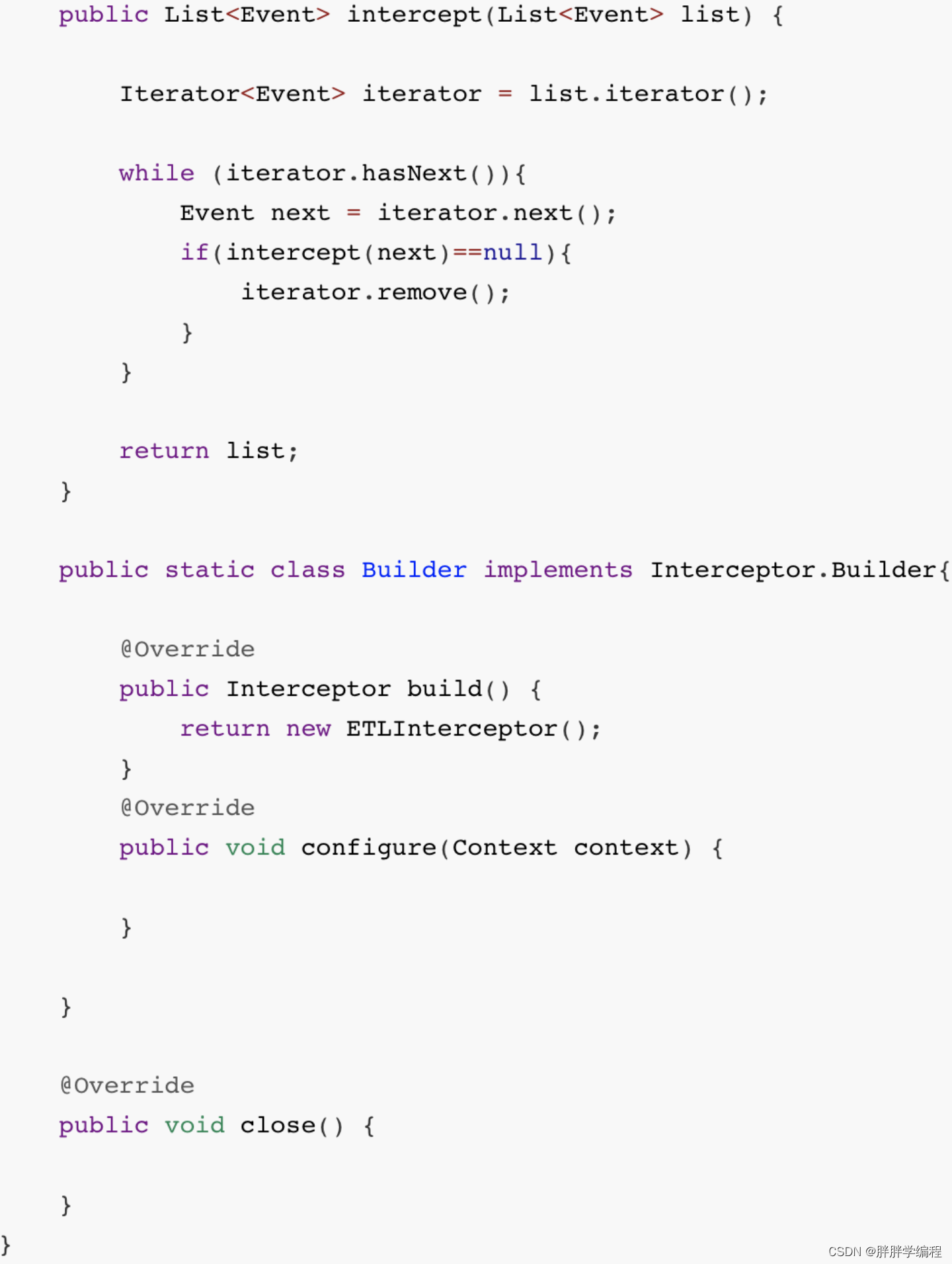
2、拦截器
判断json串是否完整


3、启动
nohup bin/flume-ng agent -n a1 -c conf/ -f job/flle_to_kafka.conf -Dflume.root.logger=info,console 1>out 2>&1 &二、消费flume
#定义组件
a1.channels=c1
a1.sinks=k1
#配置source
a1.sources=r1
a1.sources.r1.type=org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.kafka.bootstrap.servers=hadoop1:9092,hadoop2:9092,hadoop3:9092
a1.sources.r1.kafka.topics=topic_log #有多个用,分割
a1.sources.r1.kafka.consumer.group.id=topic_log
a1.sources.r1.batchSize=2000 #生产环境一般为2000
a1.sources.r1.batchDurationMillis=
#如果2000条迟迟没到.需要时间控制,单位毫秒.1000毫秒=1S
#生产环境,看多长时间生成2000条数据(上面设置的值),1天一亿条,约1000条/s,这里可以写2s
a1.sources.r1.interceptors=i1
a1.sources.r1.interceptors.i1.type=包名.TimestampInterceptor$Builder
#配置channel
a1.channels.c1.type=file
a1.channels.c1.checkpointDir=/opt/module/flume/checkpoint/behaviour1
#file chennel的索引维护在内存中,会备份到磁盘中,这个备份的磁盘目录就是checkpointDir
a1.channels.c1.useDualCheckpoints=false
#默认为false,如果设置为true,则会将checkpointDir再备份一份,担心一份不安全,可以用二次备份.需要再配置一个目录
a1.channels.c1.dataDirs=/opt/module/flume/data//behaviour1 #可以将数据存储在一个服务器的多个磁盘上
a1.channels.c1.maxFileSize=2146435071 #将数据写到文件,设置该文件的最大值,默认为2G
a1.channels.c1.capacity=1000000 #file channel 容量的设置,默认为100万条
a1.channels.c1.keep-alive=3 #默认3
#如果已经达到file channel的容量100万条,再批写入15条,此时写入不成功,数据会回滚,重新从kafka读取,浪费了性能.
#设置keep-alive,flume会等sink写入一会,这样file channel也许就有空间了,keep-alive用于设置等待时长
#配置sink
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path=/user/hive/warehouse/ods.db/ods_flow_ph/dt=%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix=log
a1.sinks.k1.hdfs.round=false #true则下支持用配置设置滚动时间,类似crontab定时那个
a1.sinks.k1.hdfs.rollInterval=5 #需要设置成5分钟
a1.sinks.k1.hdfs.rollSize=134217720 #128M
a1.sinks.k1.hdfs.rollCount=110000 #
#控制输出类型
a1.sinks.k1.hdfs.fileType=CompressedStream
a1.sinks.k1.hdfs.codeC=lzo
#组装
a1.sources.r1.channels=c1
a1.sinks.channel=c1时间拦截器
在采集kafka的时候数据写到kafka channel的时间为23:59:59,消费kafka source读的时候时间已经漂移了。
拦截器:复制一下
2、a1.sinks.k1.hdfs.path=/user/hive/warehouse/ods.db/ods_flow_ph/dt=%Y-%m-%d目录下的中的小文件问题
正常应该每个文件控制在128M
小文件的危害:1.namenode元数据空间不足,2每个小文件都会对应一个map task,占用大量的内存
这里讲的是用
a1.sinks.k1.hdfs.rollInterval=5 #需要设置成5分钟
a1.sinks.k1.hdfs.rollSize=134217720 #128M
a1.sinks.k1.hdfs.rollCount=110000 #
参数调节
三、fllume的kafka channel
kafka source就是消费者
kafka sink就是kafka的生产者
kafka channel 将数据以event(header+body)的形式存储,
这样读的时候,读出来的是event,
在kafka channel中设置 parseAsFlume=false则会以正常格式存储,不封装成Event,但是咱们得代码需要header,在拦截器中使用,所以不能这么设置。
用这个channel必须有kafka集群
将数据存储到kafka 的topic里,写到partition 的leader中。
2.我们需要先把数据写入kafka,因为还有实时数仓。
kafka channel的使用方式:可以是
source + channel + sink
source +拦截器 +kafka channel (没有sink)
channel channel +sink (没有source)