1.项目背景
本项目使用了一个人工合成的天气数据集,模拟了雨天、晴天、多云和雪天四种类型,在分析过程中,对数据进行了异常值处理,并通过描述性统计对数据进行了初步探索,接着,使用Kruskal-Wallis检验、Dunn检验和卡方检验分析了温度、湿度、风速、降水量、气压、紫外线指数、能见度、云量、季节和地点等特征对天气类型的影响,最终,构建了随机森林模型进行预测,并生成了模型的重要特征图,该项目适用于初学者学习如何进行全面的数据分析和机器学习模型构建。
2.数据说明
| 列名 | 中文解释 | 单位 | 备注 |
|---|---|---|---|
| Temperature | 温度 | 摄氏度 | 气温的测量值 |
| Humidity | 湿度 | % | 空气中水蒸气的含量 |
| Wind Speed | 风速 | km/h | 风的速度 |
| Precipitation (%) | 降水量 | % | 降水强度或降水量分布 |
| Cloud Cover | 云量 | - | 天空中云的覆盖程度,文字描述 |
| Atmospheric Pressure | 气压 | hPa | 大气压力 |
| UV Index | 紫外线指数 | - | 表示紫外线强度的指数 |
| Season | 季节 | - | 数据采集的季节 |
| Visibility (km) | 能见度 | km | 可见距离的测量值 |
| Location | 地点 | - | 数据采集地点,如内陆、山区等 |
| Weather Type | 天气类型 | - | 如晴天、雨天等 |
3.Python库导入及数据读取
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import scipy.stats as stats
import scikit_posthocs as sp
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report,confusion_matrix
data = pd.read_csv('/home/mw/input/07292689/weather_classification_data.csv')
4.数据预览及预处理
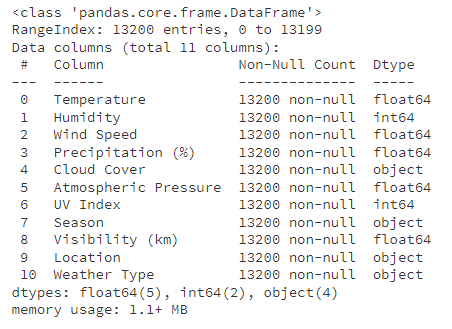
查看数据信息:
查看重复值:
0
查看分类特征的唯一值:
Cloud Cover:
['partly cloudy' 'clear' 'overcast' 'cloudy']
--------------------------------------------------
Season:
['Winter' 'Spring' 'Summer' 'Autumn']
--------------------------------------------------
Location:
['inland' 'mountain' 'coastal']
--------------------------------------------------
Weather Type:
['Rainy' 'Cloudy' 'Sunny' 'Snowy']
--------------------------------------------------
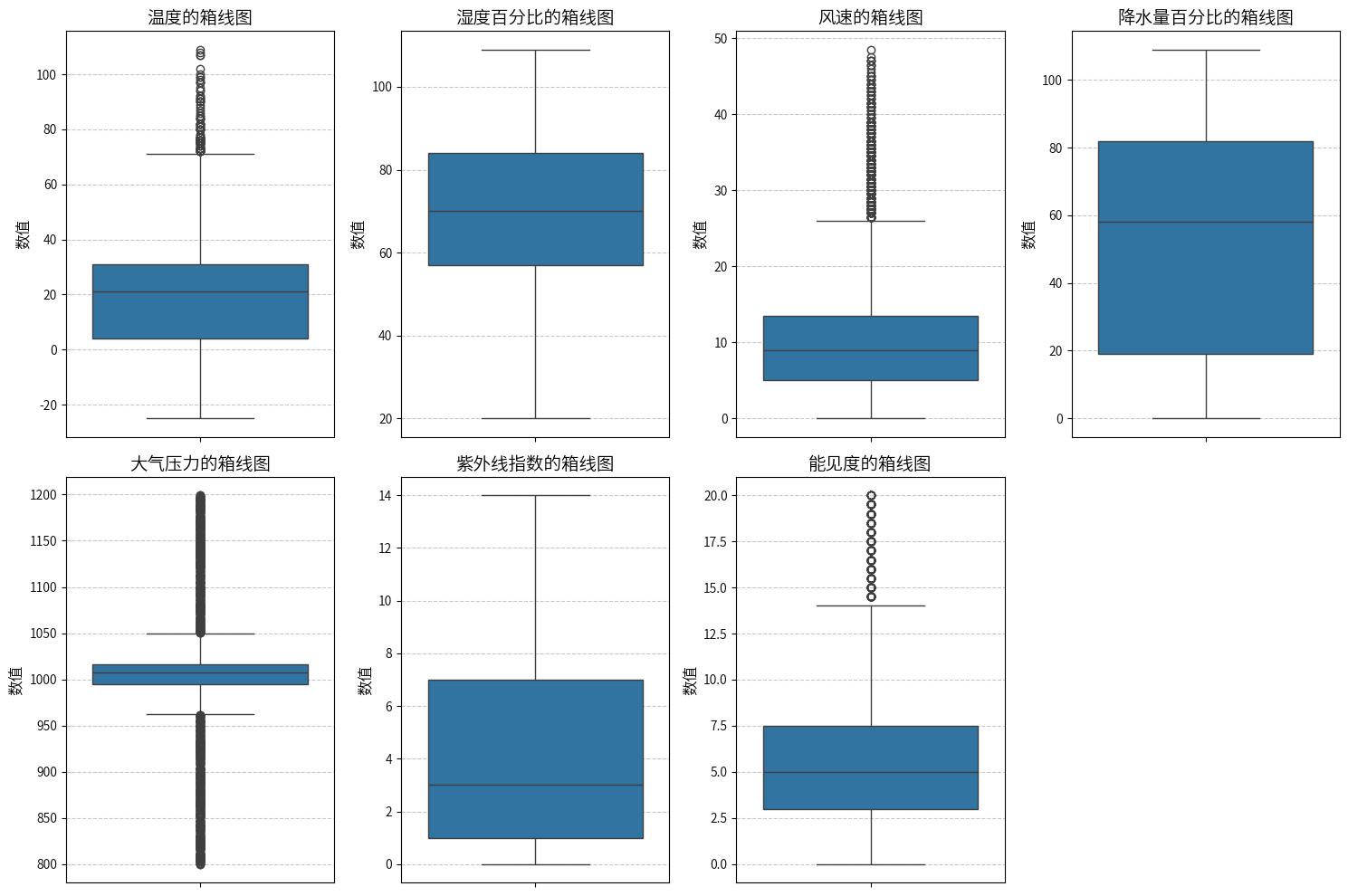
通过绘制箱线图查看数值型特征是否存在异常值:
-
温度的异常值存在大量超出常识的温度,由于没有查到一个准确的最高值,有的说“海尔湖曾经记录下了世界上最高的气温,达到了一惊人的70.7摄氏度”,也有的说“1913年7月10日,死亡谷出现了极端温度,达到了56.7摄氏度(134华氏度),因此成为历史上有记录以来温度最高的世界上最热的地方。”,这里以超过60摄氏度认定为异常值,需要进行处理。
-
湿度百分比和降水量百分比,由于数值存在超过100%的值,认为超过100%的值为异常值,需要进行处理。
-
风速的高值可能是由于台风、龙卷风等极端天气事件,故不处理。
-
大气压力的异常值可能由于高海拔地区或气象现象(如低气压系统)引起。
-
能见度低可能是由于雾霾、雨雪等天气现象,这些异常值在特定条件下是正常的,故不处理。
通过计算异常值数量,发现: 温度超过60°C的数据量:207,占比1.57%。 湿度百分比超过100%的数据量:416,占比3.15%。 降雨量百分比超过100%的数据量:392,占比2.97%。
异常值占比很小,这里可以直接删除,或者将其赋值为100%,为了保持数据集的一致性和准确性,这里选择直接删除,可以避免它们对分析结果或模型训练产生负面影响。
清洗后的数据样本还剩12360条。
5.描述性分析
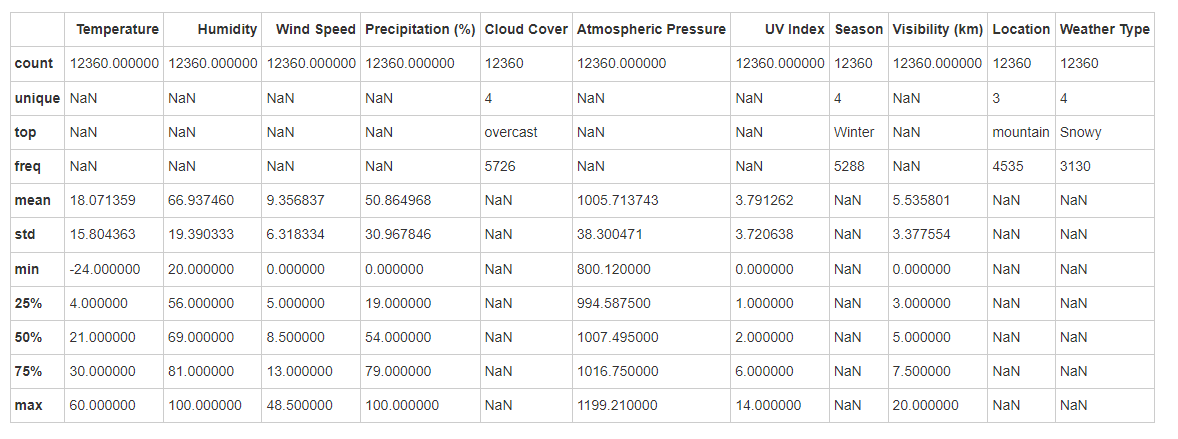
-
温度:温度数据集中在较合理的范围内(主要在0°C到40°C),极端高温(>60°C)的数据已被清理。整体分布稍微左偏,说明较低温度的情况较多。
-
湿度:湿度分布在合理范围内(20%到100%),中位数和平均值接近,说明数据分布相对对称。
-
风速:数据集中在较低的风速范围内(0-20 km/h),极端高风速事件少见,数据左偏,低风速情况更为常见。
-
降水量:降水量分布较均匀,中位数为54%,反映了各种天气条件下的降水概率。
-
大气压力:大气压力主要集中在标准范围(990-1020 hPa),数据分布正常,没有明显的异常值。
-
紫外线指数:紫外线指数大多较低,极端高指数的情况罕见,表明大部分时间的紫外线风险较低。
-
能见度:能见度数据大多集中在5 km左右,反映了多数情况下的中等能见度条件。
-
云量:多云(overcast)在数据集中出现频率较高。
-
季节分布:冬季数据最多,可能是数据采集季节或地区气候特征的反映。
-
地点分布:主要来自山区和内陆地区,这可能影响天气类型和其他气象特征的分布。
-
天气类型:分布比较均匀,没有单一类别占据绝对优势。
6.统计检验探究影响天气类型的主要因素
6.1KW检验
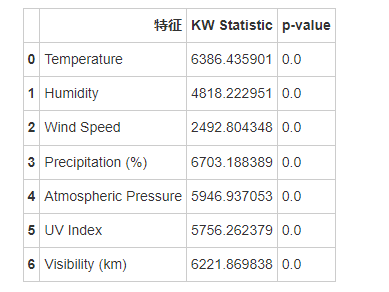
由于所有的p值远小于通常的显著性水平0.05,可以认为不同天气类型之间的温度、湿度、 风速、降水量、气压、 紫外线指数和能见度均值存在显著差异,这意味着这些特征对天气类型的影响是显著的,不同类型的天气在这些特征上有显著不同,接下来进行事后检验,来确定哪些组之间存在显著差异。
6.2Dunn检验
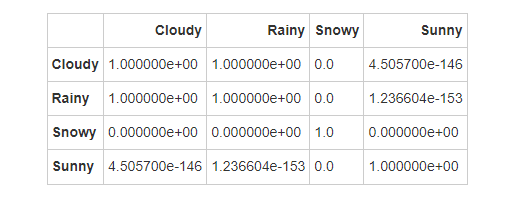
根据温度的Dunn检验结果,各天气类型之间的显著性差异如下:
-
多云和雨天之间的温度差异不显著。
-
雪天与其他所有天气类型之间的温度差异显著。
-
晴天与其他所有天气类型之间的温度差异显著。
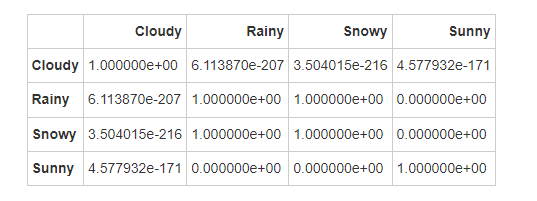
根据湿度的Dunn检验结果,各天气类型之间的显著性差异如下:
-
多云与其他所有天气类型之间的湿度差异显著。
-
雨天与雪天之间的湿度差异不显著,这表明两者在湿度方面没有显著的区别。
-
雨天和晴天、雪天和晴天之间的湿度差异显著。

根据风速的Dunn检验结果,各天气类型之间的显著性差异如下:
-
所有天气类型之间的风速差异都非常显著。这表明风速是区分不同天气类型的一个重要特征。
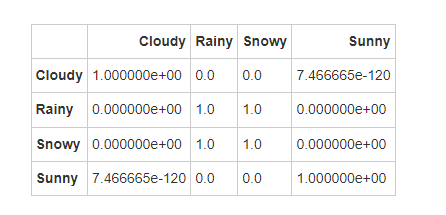
根据降水量百分比的Dunn检验结果,各天气类型之间的显著性差异如下:
-
多云与其他所有天气类型之间的降水量差异显著。
-
晴天与其他所有天气类型之间的降水量差异显著。
-
雨天和雪天之间的降水量差异不显著,表明这两种天气类型在降水量方面的相似性。
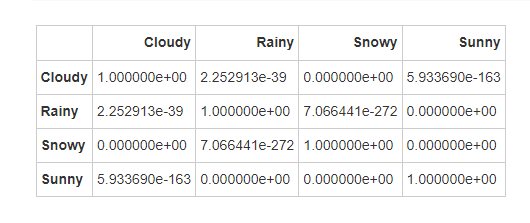
根据大气压力的Dunn检验结果,各天气类型之间的大气压力显著性差异如下:
-
所有天气类型之间的大气压力差异都非常显著。每种天气类型在大气压力上的显著差异,可能与天气系统(如高压系统和低压系统)在不同天气条件下的形成和影响有关。
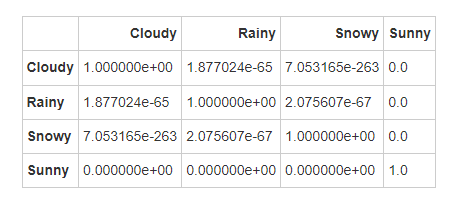
根据紫外线指数的Dunn检验结果,各天气类型之间的紫外线指数显著性差异如下:
-
所有天气类型之间的紫外线指数差异显著。这表明不同的天气条件显著影响紫外线指数,反映了紫外线强度随天气变化的显著差异。
-
晴天的紫外线指数显著高于其他天气类型,这是因为晴天通常紫外线辐射最强,而多云、雨天和雪天的云层或降水通常减少紫外线的到达量。
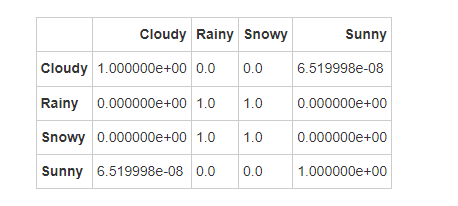
根据能见度的Dunn检验结果,各天气类型之间的能见度显著性差异如下:
-
多云天气与其他类型之间的能见度差异显著。
-
雨天和雪天之间能见度差异不显著,这可能是因为两者通常都有较低的能见度。
-
晴天通常能见度较高,这与其他天气类型形成显著差异。
6.3卡方检验
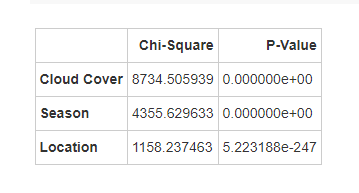
通过卡方检验得知:云量、季节和地点这三个变量与天气类型之间都有显著的统计关联。
7.随机森林
进行标签编码后的数据对应关系:

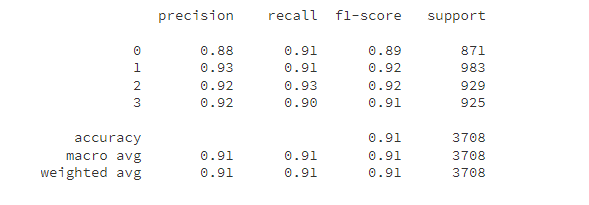
随机森林模型评估指标
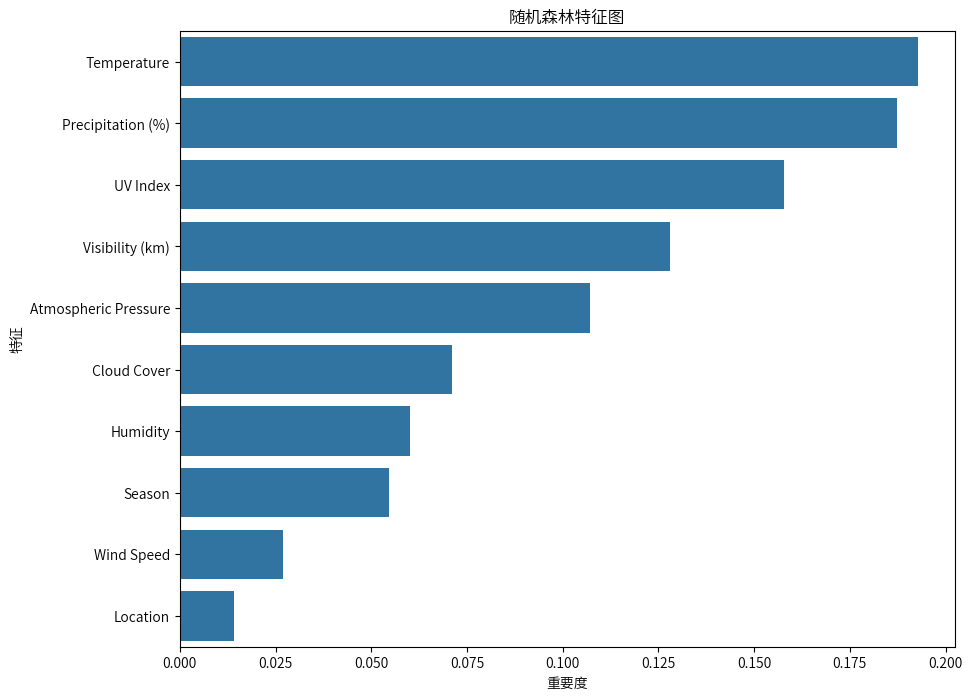
随机森林模型的预测准确率很高,并且通过特征度分析,发现影响模型的主要因素有:温度、湿度、紫外线指数、能见度、大气压力。
8.结论
本项目对数据进行了异常值处理,并通过描述性统计初步探索了数据特征,使用Kruskal-Wallis检验、Dunn检验以及卡方检验,探讨了影响天气类型的主要因素,最终,构建了随机森林模型进行预测,并生成了模型的重要特征图。结果如下:
-
描述性统计:
-
温度:温度数据集中在合理范围内(主要在0°C至40°C),已清理掉极端高温数据(>60°C)。整体分布略显左偏,表明较低温度的情况更多。
-
湿度:湿度数据分布在合理范围内(20%至100%),中位数与平均值接近,说明数据分布相对对称。
-
风速:风速数据集中在较低范围内(0-20 km/h),极端高风速事件少见,数据左偏,低风速情况更为常见。
-
降水量:降水量分布较均匀,中位数为54%,反映了各种天气条件下的降水概率。
-
大气压力:大气压力主要集中在标准范围内(990-1020 hPa),数据分布正常,没有明显的异常值。
-
紫外线指数:紫外线指数大多较低,极端高指数情况罕见,表明大部分时间紫外线风险较低。
-
能见度:能见度数据大多集中在5公里左右,反映了多数情况下的中等能见度条件。
-
云量:多云(overcast)在数据集中出现频率较高。
-
季节分布:冬季数据最多,可能反映了数据采集的季节性或地区气候特征。
-
地点分布:数据主要来自山区和内陆地区,可能影响天气类型和其他气象特征的分布。
-
天气类型:各类别分布较均匀,无单一类别占绝对优势。
-
-
统计检验: 结果表明,不同天气类型在温度、湿度、风速、降水量、气压、紫外线指数、能见度、云量、季节和地点均值上存在显著差异,这意味着这些特征对天气类型的影响显著。
-
模型预测: 随机森林模型的预测准确率较高,达到91%。特征重要性分析显示,影响模型预测的主要因素包括温度、湿度、紫外线指数、能见度和大气压力。