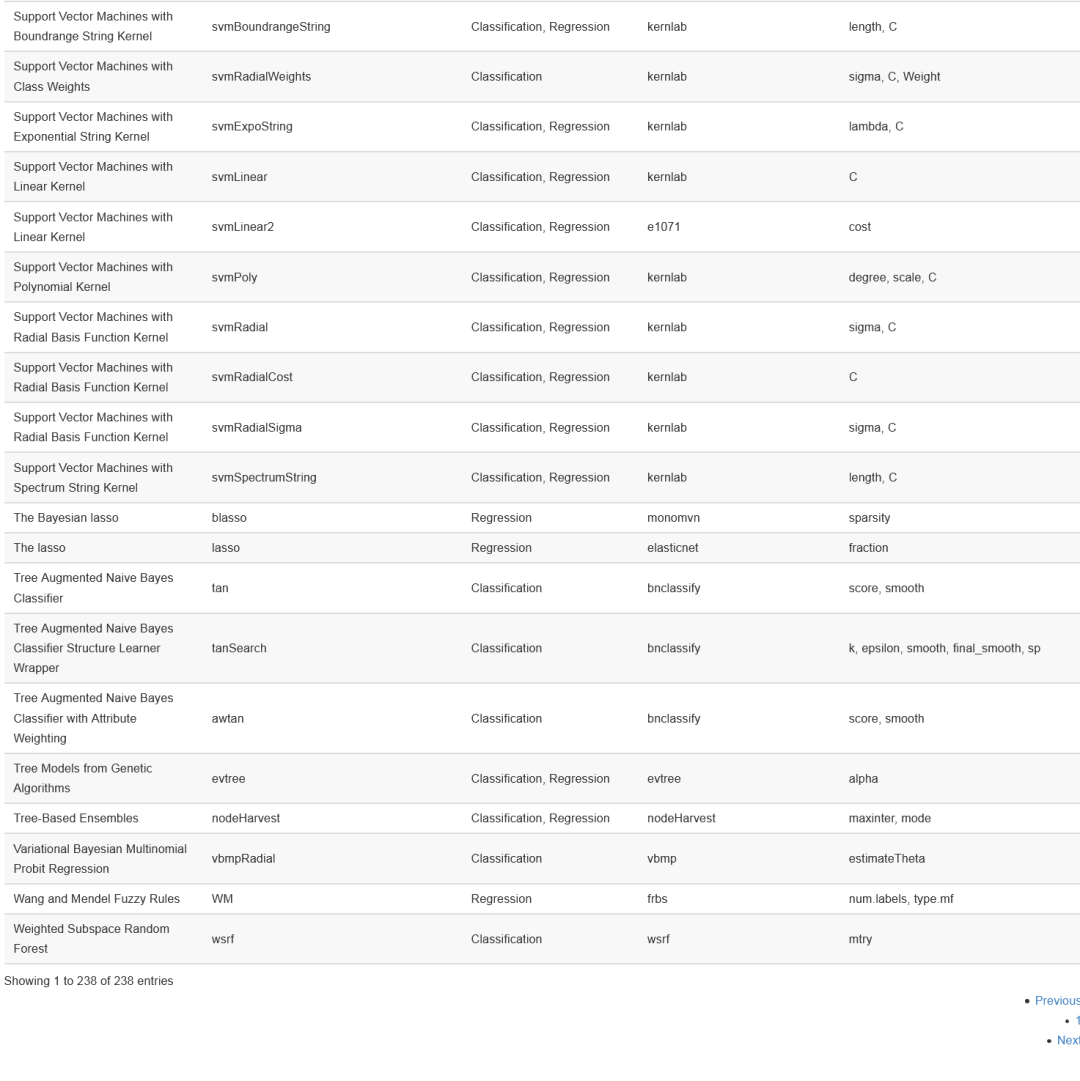
在上一章节中博主利用Gradio完成了YOLOv8模型的图像推理,那么在本章节中将进行视频推理,其代码十分简单,只需要将原本的视频切分为一帧帧图像再去检测即可,代码如下:
def detectio_video(input_path):
output_path="result.mp4"
cap = cv2.VideoCapture(input_path)
fps = int(cap.get(5))
t = int(1000 / fps)
videoWriter = None
while True:
_, img = cap.read()
if img is None:
break
yolo_det(img)
cv_dst = yolo_det.draw_detections(img)
if videoWriter is None:
fourcc = cv2.VideoWriter_fourcc('m', 'p', '4', 'v')
videoWriter = cv2.VideoWriter(output_path, fourcc, fps, (cv_dst.shape[1], cv_dst.shape[0]))
videoWriter.write(cv_dst)
cap.release()
videoWriter.release()
return output_path
至此,模型的视频推理过程便完成了,但我们在UI界面上却发现,上传的视频是没有画面的,同时,返回的视频虽然成果保存,但其在界面上却显示为NaN


其实,对于学习YOLO模型推理的过程而言,这已无伤大雅,但博主还有那么一点完美主义精神的,看看能否解决呢?
经过查询相关资料,发现这是由于OpenCV合成视频操作造成的,解决方式是使用moviepy,具体如何做呢?
Moviepy合成视频
我们先来看一个moviepy合成视频的案例,可以看到它其实是读取文件夹内所有图像,随后再统一写入
from moviepy.editor import ImageSequenceClip
import os
# 指定图像文件夹路径
image_folder = '/path/to/image/folder'
# 获取文件夹中的所有图像文件
image_files = [f for f in os.listdir(image_folder) if f.endswith(('.png', '.jpg', '.jpeg'))]
# 按文件名排序图像,确保它们按顺序排列
image_files.sort()
# 创建一个ImageSequenceClip对象,它将自动将图像序列转换为视频
clip = ImageSequenceClip(image_files, fps=30)
# 指定输出视频的文件名
output_video = '/path/to/output/video.mp4'
# 保存视频
clip.write_videofile(output_video, codec='libx264')
将原本的Opencv合成视频进行改造:
def moviepy_video(input_path):
from moviepy.editor import ImageSequenceClip
output_path="result.mp4"
cap = cv2.VideoCapture(input_path)
fps = int(cap.get(5))
t = int(1000 / fps)
images=[]
while True:
_, img = cap.read()
if img is None:
break
yolo_det(img)
cv_dst = yolo_det.draw_detections(img)
images.append(cv_dst)
clip = ImageSequenceClip(images, fps=fps)
clip.write_videofile(output_path, codec='libx264')
clip.close()
cap.release()
return output_path
可以看到,现在这个返回的视频可以展示了,但博主在实验时发现,其最终视频的处理时间要比OpenCV慢上许多,大家根据自己的需要选择即可。

至于视频上传时,点击播放只有声音没有画面的问题,博主搜索了一些资料但也没有找到解决方法,大家如果有解决方案希望能够不吝赐教。
图像推理改进
随后对模型的图像推理模块进行改进,添加了置信度与IOU的进度条,实现代码如下:
import YOLODet
import gradio as gr
import cv2
#from vis import demo_gradio
model = 'yolov8n.onnx'
base_conf,base_iou=0.5,0.3
def det_img(cv_src,conf_thres, iou_thres):
yolo_det = YOLODet.YOLODet(model, conf_thres=conf_thres, iou_thres= iou_thres)
yolo_det(cv_src)
cv_dst = yolo_det.draw_detections(cv_src)
return cv_dst
if __name__ == '__main__':
img_input = gr.Image()
img_output = gr.Image()
video_input=gr.Video(sources="upload")
app1 = gr.Interface(fn=det_img, inputs=[img_input,
gr.Slider(maximum=1,minimum=0,value=base_conf),
gr.Slider(maximum=1,minimum=0,value=base_iou)], outputs=img_output)
app2 = gr.Interface(fn=moviepy_video, inputs=video_input, outputs="video")
demo = gr.TabbedInterface(
[app1, app2],
tab_names=["图像目标检测", "视频目标检测"],
title="目标检测"
)
demo.launch()
实现界面如下:

完整代码已发布在Github:
Gradio+YOLO模型推理部署
![[C++]多态与虚函数](https://i-blog.csdnimg.cn/direct/a17bada2b7934967944d6f8985a5545c.png)