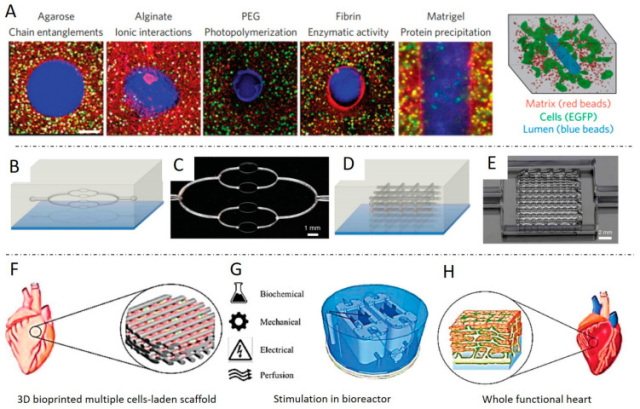
Spark 基础
一、MapReduce编程模型的局限性
1、繁杂:只有Map和Reduce两个操作,复杂的逻辑需要大量的样板代码
2、处理效率低:
Map中间结果写磁盘,Reduce写HDFS,多个Map通过HDFS交换数据
任务调度与启动开销大
3、不适合迭代处理、交互式处理和流式处理
二、Spark是类Hadoop MapReduce的通用【并行】框架
1、Job中间输出结果可以保存在内存,不再需要读写HDFS
2、比MapReduce平均快10倍以上
三、版本
2014 1.0
2016 2.x
2020 3.x
四、优势
1、速度快
- 基于内存数据处理,比MR快100个数量级以上(逻辑回归算法测试)
- 基于硬盘数据处理,比MR快10个数量级以上
2、易用性
- 支持Java、【Scala】、【Python:pyspark】、R语言
- 交互式shell方便开发测试
3、通用性
一栈式解决方案: 批处理、交互式查询、实时流处理(微批处理)、图计算、机器学习
4、多种运行模式
YARN ✔、Mesos、EC2、Kubernetes、Standalone、Local[*]
五、技术栈
1、Spark Core:核心组件,分布式计算引擎 RDD
2、Spark SQL:高性能的基于Hadoop的SQL解决方案
3、Spark Streaming:可以实现高吞吐量、具备容错机制的准实时流处理系统
4、Spark GraphX:分布式图处理框架
5、Spark MLlib:构建在Spark上的分布式机器学习
六、spark-shell
Spark自带的交互式工具
local:spark-shell --master local[*]
alone:spark-shell --master spark://MASTERHOST:7077
yarn :spark-shell --master yarn
七、运行架构
Spark服务
Master : Cluster Manager
Worker : Worker Node
1、在驱动程序中,通过SparkContext主导应用的执行
2、SparkContext可以连接不同类型的 CM(Standalone、YARN),连接后,获得节点上的 Executor
3、一个节点默认一个Executor,可通过 SPARK_WORKER_INSTANCES 调整
4、每个应用获取自己的Executor
5、每个Task处理一个RDD分区
八、Spark架构核心组件
| 名称 | 作用 |
|---|---|
| Application | 建立在Spark上的用户程序,包括Driver代码和运行在集群各节点Executor中的代码 |
| Driver program | 驱动程序。Application中的main函数并创建SparkContext |
| Cluster Manager | 在集群(Standalone、Mesos、YARN)上获取资源的外部服务 |
| Worker Node | 集群中任何可以运行Application代码的节点 |
| Executor | 某个Application运行在worker节点上的一个进程 |
| Task | 被送到某个Executor上的工作单元 |
| Job | 多个Task组成的并行计算,由Action触发生成,一个Application中含多个Job |
| Stage | 每个Job会被拆分成多组Task,作为一个TaskSet,其名称为Stage |
Spark 安装
一、下载
首先检查是否安装了 jdk 并查看版本是否符合要求。这里是JDK8
1、 linux 安装spark-3.1.2,输入如下命令 (没有wget可自行下载)
tar -xvf spark-3.1.2-bin-hadoop3.2.tgz -C /opt/software
2、要安装其他版本:Index of /dist/spark (apache.org)
二、解压
安装好后将其解压到自己的目录
wget https://archive.apache.org/dist/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz-x 解压,v 显示解压过程,-f 指定解压文件,-C 指定解压路径
三、环境变量
1、在/etc/profile.d目录新建一个myenv.sh文件
vim /etc/profile.d/myenv.sh
2、写入如下
# spark
export SPARK_HOME=/opt/software/spark-3.1.2
export PATH=$PATH:$SPARK_HOME/bin
3、激活环境变量 (执行/etc/profile即可)
source /etc/profile
4、注意:spark on yarn 必配,且需保证 HADOOP 环境变量已经正确配置
可在/opt/software/spark-3.1.2/conf/目录下配置
mv spark-env.sh.template spark-env.sh
vim spark-env.sh
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
四、启动、关闭、检查Spark
1、启动 Spark Standalone 集群,执行脚本
/opt/software/spark-3.1.2/sbin/start-all.sh
2、查看 Spark 服务
1、jps -ml查看到类似如下信息
jps -ml
31987 org.apache.spark.deploy.master.Master --host single01 --port 7077 --webui-port 8080
32089 org.apache.spark.deploy.worker.Worker --webui-port 8081 spark://single01:7077
2、访问8080 和 8081 (http://single01:8080) 端口,结果如下

3、启动 Spark Shell 会话
spark-shell --master spark://single01:7077 # 启动 spark-shell 测试 scala 交互式环境
spark-shell --master local[*]
spark-shell --master yarn # 测试 Spark on YARN
--master 用于指定 Spark 应用程序连接的 Spark Master 地址。
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Scala version 2.12.10 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_171)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
3、关闭 Spark Standalone 集群
/opt/software/spark-3.1.2/sbin/stop-all.sh