作者 | Annie Xu
责编、采访 | Echo Tang
出品丨GOSIM 开源创新汇
在读期间研究方向为并不“火”的模式识别与深度学习,毕业却刚好踩上人工智能计算研究的风口……来自美国东北大学的王言治副教授深耕深度学习与大模型,前瞻性地探索大模型的本地化部署,打造可供用户个人大模型运行的本地化平台。
在风景宜人的荷兰代尔夫特小镇,GOSIM 独家对话栏目 Open AGI Forum 特别邀请到王言治教授,为我们带来了他的真知灼见。

王教授在专访中为我们分享了他的职业生涯以及他对开源与人工智能发展的精彩观点:
-
大模型在云端服务的提供与用户实际需求之间存在鸿沟。如何实现大模型和用户自定义大模型的匹配,实现用户数据的本地化部署、本地化训练、本地化微调是我们目前的研究重点。
-
手机端能否运行大模型取决于手机内存的大小。千元级别的手机运行如 Stable Diffusion 这样的大模型是没有问题的。内存的管理与分配是其中的痛点,需要编译的不断调试和优化。
-
评 TVM 和 Llama.cpp:TVM 是传统上非常标准的编译,但它们并不适合大模型,它在小模型的可扩展性方面存在一些问题。而 Llama.cpp 属于异军突起,编译效果比较好。
-
人工智能的趋势是越来越闭源的,然而开源所面临的危机并不仅仅在模型侧,大模型的差距还是小的,在其他具体应用方面,闭源的效果是远远强于开源的,这个差距比大模型要大得多。
-
视频生成在国内外都被认为是AIGC的“高地”,但当前所生成的视频时间比较有限,且不够连贯,在生成娱乐或者生成非常短的视频上比较有用,我暂时还不看好它的商业前景。
-
其他架构对 Transformer 不构成挑战,学术界也非常清楚这一点。
-
在美国,工业界是领先于学术界的,几个里程碑的进展都是由工业界实现的。
以下是本次采访的主要内容:

模型本地化部署是发展的必然趋势?
GOSIM:大家好,欢迎来到 Open AGI Forum!我是来自 CSDN 的 Echo Tang。今天我们很荣幸地邀请到了东北大学王言治副教授,请王教授给大家打声招呼,简单介绍一下自己。
王言治:大家好,我主要的研究方向是深度学习与大模型。我们主要研究大模型如何在本地进行有效部署,包括模型的压缩和对应模型的编译。我们认为现在云端的大模型很难完全满足用户需求,但未来,用户个人大模型也可以在本地端进行有效部署。
GOSIM:首先请王教授分享一下您是如何走上人工智能之路的?为什么会选择深度学习与大模型作为研究方向,您是看到了哪些问题与痛点?
王言治:我在本科时的研究就是这个方向。当时还没有深度学习,还是“模式识别”,“大模型”并不火。读博的时候,研究这个方向的老师也非常少,所以我们当时主要研究的是计算。我的导师想让我们运用人工智能解决计算方面的一些问题,主要研究强化学习(Reinforcement Learning)。
随后,神经网络、深度学习发展起来了。我毕业后想研究用人工智能解决计算方面存在的问题,但我发现人工智能本身的计算也是一个问题,所以我就转为研究这个方向了。其实我们并不是研究人工智能最早的一波人,也是被人工智能带动起来的,但是我们所做的事情现来回过头来看,算是比较重要的。
GOSIM:您当前正在集中精力做哪些事情,这些事情因何而重要?
王言治:我们目前主要研究的是视频生成、图像生成,以及大模型的本地化部署。我们进行这项研究的原因是:第一,不同模型以后都会使用自己的数据,每个用户也都可能拥有自己的应用和个人大模型。第二,现在国外的一些网站已经有逐渐成型的社区。大家都会用不同的基础模型、不同的 checkpoint、不同的微调模型等等,所涉及的模型可能有几千、几万个。
然而真正对这些模型有使用需求的人不太可能在云端使用。另外,能够在云端运转的模型数量也不多,可能只有10到20个。我们发现,云端模型所提供的服务与用户的实际需求之间存在一个较大的鸿沟。我们想要弥补这个鸿沟,所以目前的主要工作是让大模型和用户自定义的大模型相适配,实现用户数据的本地化部署、训练、微调,从而减少用户的开销,满足用户的实际需求。
GOSIM:您可以展开讲讲您目前主要的研究项目 Ominix 吗?
王言治:Ominix 项目是实现大模型定义的统一化。假设我们要实现 Stable Diffusion、大语言模型,或者 Sora 等视频生成模型,底层需要哪些基础算子呢?我们将所涉及到的算子定义清楚,从而构建起一个算子库。在支持算子库前端的情况下,我们就可以运转各种各样的大模型。同时,我们优化了后端在不同平台上的性能。我们可以在 Mac、高通、英特尔、英伟达等不同平台之间,实现跨平台的最高性能。
基于这套系统,对给定的任何一个基于 Transformer 所构建的大模型,用户可以在对应平台上加载后直接运转。可以立即输出一个类似于 GPT 的 API ,并直接与其进行交互。也就是说,我们不用非常复杂的编译或者经历繁复的云端的过程,用户下载模型后可以立即运行。
GOSIM:当前国内的很多大模型厂商正在尝试构建千元(人民币)机能够运行的大模型,您认为现在能够达到这种水平吗?
王言治:千元级别的手机可以实现,但能否运转主要取决于手机的内存。现在哪怕是千元级别的手机,内存也得到了一些提升。如果想要运行 Stable Diffusion 这样的大模型是没有问题的,但特别大的大模型可能不太行,它内存不够。
GOSIM:您认为技术方面存在哪些挑战或瓶颈?
王言治:技术上主要是内存管理的问题。内存大小是可以的,但如何能够有效地访问内存,以及如何让大模型运行是需要解决的关键问题。此外,我们的系统需要足够通用,能满足不同大模型的运行条件。这是目前比较难达成的事情,不过我们正在进行优化。
前几年,我们主要进行编译方面的工作。现在的 TensorRT、TVM 等采用的都是编译的概念。这种概念本质上是指,模型和每一层用什么样的并行度?需要分多少块?模型的每个层运行需要用多长时间?需要设置多大的内存处理并行问题?这些情况都需要不停地尝试。模型之间、模型的层与层之间内存的调动也是一步步试出来的。
因而,模型执行的时间非常长,编译时间很可能会达到几个小时,有的甚至长达几个月。我们的一个编译从去年12月持续做到现在,还没有完成,在处理过程中还出现了很多 Bug。
过去两三年,我们与其他人合作的本质就是减少编译过程的时间,力求实现在看到模型每一层结构时,就能推断出它具体的运行参数。我们并非盲目尝试,而是根据理论、计算和 AI 本身运行的方法估计出来的,也取得了比较好的效果。
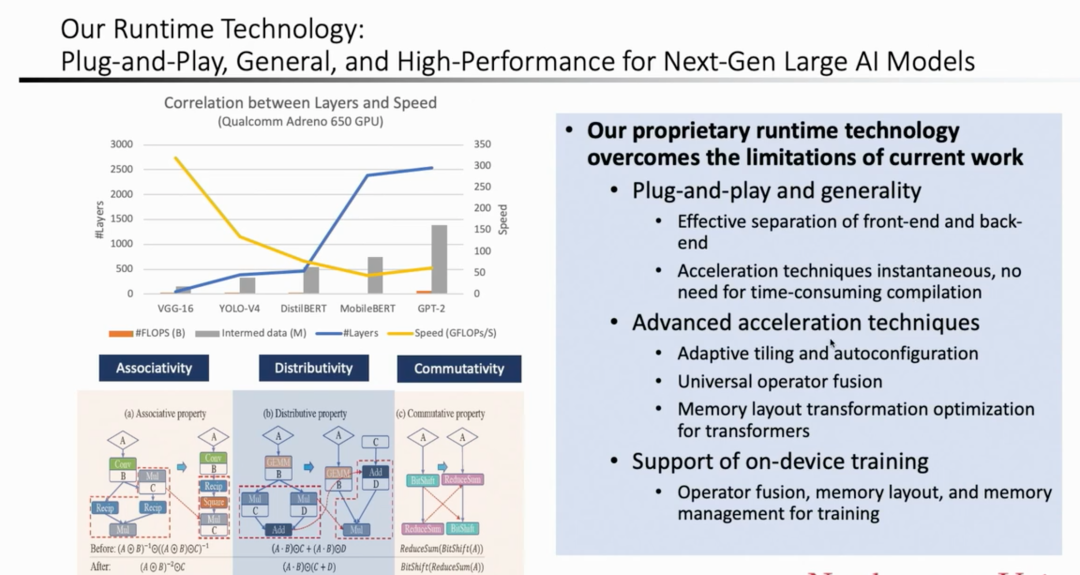
随着大模型越来越大,很多情况下编译都无法运转。我们的系统理论上不一定是最好的,但是能在几秒钟内运算出结果。相比之下,我们是具备技术优势的。
GOSIM:相比 TVM 和 Llama.cpp,在技术优势上的体现有哪些,使用了什么特殊的方法和技术实现了哪些方面的提高?
王言治:TVM 是传统上非常标准的编译,但它们并不适合大模型。它在小模型的可扩展性方面存在一些问题。相比以往的编译,Llama.cpp 属于异军突起。Llama.cpp 编译效果比较好,我们团队目前也在学习吸收。
很多做编译的工程师并不喜欢这份工作。他们认为这个工作本质上写“死”了:在 PyTorch 后面直接写一个 C,后台也很难用。然而不可否认的是,虽然它跑的模型比较有限,但确实挺高效的。
因此,我们的工作就是将其通用化处理。我们将前后端分离,让前端可以支持各种各样的模型。但它的后端不好进行优化。因为它们(PyTorch和C)混合在一起,且内存分配的内容全部写“死”了,再对其 Compiler 或者优化加速就很难进行,所以对其进行分离就是十分必要的。
分离后,我们可以揉进新的算子或者做加速,从而取得更好的效果,就是指速度更快、适用性更广。可以说,会有几倍、十几倍,甚至几十倍的加速。
GOSIM:那在整个项目过程中,有什么让您印象深刻的事情吗?比如,遇到什么样的坑或者遇到什么花较大功夫才能解决的难题?
王言治:主要有两方面的问题。其一,就是上面提到的 Llama.cpp 前后端分离的问题。这个问题解决起来比较痛苦。我们当时学习了很多 Llama.cpp 后端的知识——它们写得非常好、非常高效——能用 C 语言写出来也非常不容易,但确实很难改。前后端分离之后,我们自己写了一遍后,改动也变得更容易了。
此外,我们团队很多人一开始并不认为“即插即用”的理念非常重要,很多人还是想使用之前编译器的套路。我们之前几年的卖点也只是编译时间比其他编译器快。效果也更好——因为我们优化得更多。但当时并没有意识到“即插即用”存在这么大的需求。就整个团队而言,我们也是近几个月才转变了认识,意识到“即插即用”的重要性。
GOSIM:您预期什么时候能实现像 Stable Diffusion 或者 Midjourney 这样的效果?
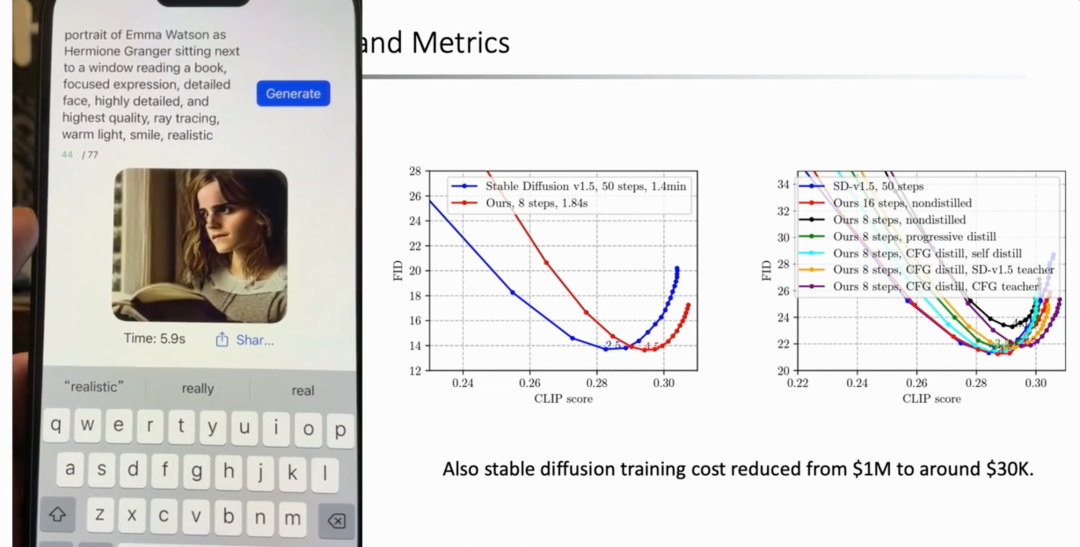
王言治:Midjourney 的实现并不难。如果掌握了 Stable Diffusion 的 Prompt(提示词)的话,将会调整得优于 Midjourney。Civitai 等一些网站生成的内容也比 Midjourney 强。Midjourney 唯一的好处就是好用,但专业的人会使用 AUTOMATIC1111。但是 GPT 还是很强的,想要在手机终端超越 GPT,还是比较难的。我认为,开源大模型的上限就是我们的上限。

开源与闭源的差距会越来越大?
GOSIM:目前全球有很多围绕开源大模型的讨论。斯坦福李飞飞团队曾经发布报告表示,封闭模型的性能会优于开源模型。AI 从业者也围绕开、闭源模型展开了很多讨论,基本上持两派观点:一部分人认为,大模型的未来一定是开源。另一部分人认为,开源大模型可能会越来越落后。
同时,有些从业者认为,在大模型领域做开源会比其他领域更难。因为它不仅涉及代码,还包括协作、数据等维度,您的观点是怎样的?
王言治:我觉得现在人工智能的趋势是越来越闭源的。开源和闭源存在一定差距的,这个差距还有增大的趋势。并不是说其他大模型的训练更高级,或者模型的数据就更好,本质上是数据的差距。闭源的公司可以获取用户数据,开源的公司提供给用户随意使用,可供训练的数据非常少,几乎没有用户数据。
但实际上,开源所面临的危机并不仅仅在模型侧,大模型的差距还是小的,在其他具体应用方面,如人脸驱动、数字人、音频生成的模型方面,闭源的效果是远远强于开源的,这个差距比大模型要大得多。比如闭源的 HeyGen、ElevenLabs 就比开源强得多,比最新的 Hyper 也要强很多。
我认为开源可以做一个社区,让用户能够参与、贡献数据。否则,开源和闭源的差距会越来越大。如果把社区做好,开源大模型的上限可以比肩 GPT。
GOSIM:所以对我们做开源来讲,可能更大的危机是在智能应用这些范畴吗?
王言治:开源在应用过程中,使用者和开发者也都面临潜在的法律风险。目前开源在 AI 方面的发展趋势不太乐观。除非把开源做成一个社区,才可能会有些用处。
我个人认为,把开源做成社区是有前景的。用户自己就有很多数据,如个人照片,他们也有自己想做的事情。有的人想成为写小说的,有的像做一个写总结或者分析 PDF 的 Agent,开源肯定是存在市场的,但它和我们做本地化部署不是一码事。
我们如果介入的话,肯定会做开源。并非所有的用户都愿意花钱用 GPT,GPT 也不能解决所有的问题。GPT 生成图和分析的能力并不高,价格也相对较高,速度也不是很快。所以,还是有很多的市场需要用开源模型和本地化部署来实现的。做社区能够和用户的实际需求相匹配,是有发展前景的。

王言治在 GOSIM 2024 欧洲站

人工智能的发展热点是多模态吗?
GOSIM:一方面,纵观人工智能的历史,我们可以很明确看到人工智能的发展经过了几起几落,当前模型技术正处于不断变化演进的过程中。我当前关注到几个比较热门的技术方向,如多模态、Agent 以及面向未来的具身智能。另一方面,底层的模型技术已经产生,但是应用生态存在着不确定性。很多人为之苦恼。您认为2024年以及未来几年内,人工智能的发展走向是什么?从技术研究到应用落地,如何能够实现一个闭环?
王言治:这是需要市场来验证的。技术层面的话,就是您说的多模态,以及自动驾驶等方面大模型的应用。我觉得这些肯定是一个比较大的趋势。但是模型也不见得越大越好,Fine-tune(微调)和 checkpoint(检查点)是现在发展最好的。
现在各个厂商也都找到自己大模型应用的方向,但还是有一些传统行业的内容,如客服、直播、对话机器人、数字人等等。我们做 Infra(基础设施)是在助力这一趋势,但具体发展走向还是要看各个厂商的想法。
GOSIM:Sam Altman 曾说过,今年是多模态的一年,您目前有在多模态上的探索吗?
王言治:多模态主要是以下两点:一是比较简单的多模态,如生成一张图或文字,在图里找内容,或者解释图片。这些情况基本上就是把图或对应的 prompt 一起放进去,是 Vision Transformer 和大模型的结合,难度并不高,我们可以实现。
另一种多模态是生成完整的视频,前段时间特别火。视频生成在国内外都被认为是AIGC的“高地”。但所生成的视频时间比较有限,且不够连贯。在娱乐或者生成非常短的视频上比较有用,我暂时还不看好它的商业前景。
此外,生成视频的成本比较高。究竟要如何进行训练和做inference,还是存在很多问题。但简单的多模态,比如要解释一张图,例如GPT-4 Vision,本地做是没有太大问题的。
GOSIM:所以现在对您来说,本地做图是当前能够实现的状态,但需要更大成本的视频生成在短期之内可能还没有办法实现?
王言治:不是在本地不能实现,而是它的成本和用处并不完全明确。据我所知,现在国内真正跟上发展的有几家公司:清华有一个公司做得还不错。字节的 MagicAnimate 和阿里的 Animate Anyone 也还可以。但它们大多都是跳舞等娱乐化的内容,在具体的 App 上做得比较好。如果想做成 Stable Diffusion 这样通用的,还是比较困难的。

GOSIM:您之前提到,当前的模型都是基于 Transformer 的架构,但当前有很多讨论,包括学术圈讨论得更早,认为 Transformer 并不是未来模型的最终架构。对于架构上的演进,您有看到什么方向吗?
王言治:我认为它们对 Transformer 不构成挑战,学术界也非常清楚这一点。除了 Bert、Vision Transformer,大家都公认 Transformer 占据主导地位。2019 年左右,学术界基本上认定 Transformer 会一统江湖。
唯一存在争议的是,相比当年的 Transformer,平移不变性在 convolution 层是存在优势的。但当 Transformer 变成 Swin Transformer,就不存在争议了。学术界偶尔有些争议,最近有些争议认为 RNN 更好,但我是不认可的。
Transformer 不一定是最好的架构,但卷积一定是最好的架构吗?不见得是,在数学上没人能证明它是最好的,但是无法在本质上认为它有一个根本的飞跃。
如果准确率只是提高一个点、两个点,那 OpenAI 是不会重新把它全部训练一遍的。当然有很多 Activation Function 或者其他结构都比 ReLU 好,但是不会把这些东西全部推翻、全部重新训练一遍的。
除非提出了一个能连贯生成一个小时视频的架构,或者能把自动驾驶变得完全靠谱,那这个架构才值得重新训练。
Transformer 吸收了 CNN 的很多东西,比如 Stable Diffusion 就吸收了 unit 和 convolution 的结构,所以它也不止是 Transformer 了。如果只是实现一个小参数量的变化,是没有意义的,除非能够实现革命性的改变,重新训练才有意义。
GOSIM:国内的很多研究是起于学术的。很多国内大模型都是开始于学校、实验室,紧接着创业。可以从您亲身接触的美国人工智能发展的视角来谈谈吗?
王言治:美国基本上是工业界领先于学术界的,如 OpenAI、Microsoft、谷歌、Meta 这些公司。研究主要集中在生成视频、多模态上。
几个里程碑的进展都是由工业界实现的。2018 年的时候,我们认为人工智能没有什么本质性的进展,谷歌发布了 Bert,把 Transformer 变成了现实。除了 Bert,其他的都很难称为本质性的进展。之后出现了 GPT-2,但 GPT-2 并没有 Bert 强。
随后 2020 年谷歌发布的 Vision Transformer 也引发了一定轰动。2021 年出现了 GPT-3,之后有实习生在英伟达实习时做出来了 Stable Diffusion。2022 年出现 ChatGPT,大家一步步地把大数据和 Transformer 变成现实。
GOSIM:最后,请王老师给我们的研究人员和开发者分享一些您的建议。如何帮助大家更好地迎接 AGI 时代的职业发展?
王言治:其实我也是跟随者。我观察到大家存在的一些需求,并在这方面做一些研究。我个人认为大模型是一个机会,大家可以在应用方面想一些有意思的事情。国内大模型的应用方面,其实比美国要做得更好。这方面,我也是要多学习学习。
GOSIM:最后以谦虚结尾,但同时也给我们带来了非常好的金句观点。感谢王老师非常多的精彩的观点和分享,也感谢观看 Open AGI Forum 的小伙伴们,我们今天的访谈栏目到这里就结束了,谢谢大家,我们下次再见!








![7.30 模拟赛总结 [神奇性质]+[线段树二分]](https://i-blog.csdnimg.cn/direct/f3ccf280698047048df7cb8cd882c744.png)