LLM 各种技巧| Prompt Engineering 大总结|指南
截止至今,关于LLM 的优化与技巧层出不穷,几乎每个月都有新的技术和方法论被提出,因此本篇主要是要介绍在各种不同情境下,LLM 的各种Prompt Engineering 技巧,每篇都有附上论文连结与架构图,方便你快速检阅,希望能助帮你深入了解Prompt Engineering 领域的最新进展及其发展趋势。
这篇介绍的大纲如下图,参考Sahoo et al. (2024)[1]最新的研究成果,主要分成12 个部分,并会对各部分的技术分别做介绍:

1. New Tasks Without Extensive Training
1.1 Zero-Shot Prompting
零样本提示技术(Zero-Shot Prompting) 是LLM 领域里的一项重要创新。由Radford et al. (2019)[2]提出,这技术使我们能够在缺乏大规模专门训练资料的情况下,通过巧妙设计的提示来引导模型执行新的任务。这意味着,模型接收到的是任务的描述,而不是针对该任务的具体训练标签或资料。这项技术依赖于模型本身的知识库,它可以利用这些提示来对新的任务作出反应和预测。以下为范例:
Input:

Outpu:
Neutral
1.2 Few-Shot Prompting
Few-Shot Prompting 是由Brown et al. (2020)[3]提出,与零样本提示相比,它透过提供少数输入输出范,来帮助模型学习特定任务。论文中有描写到,通过精选的高质量范例,能够显著提升模型在执行复杂任务时的表现,尤其是在完全没有示例的情况下更为明显。尽管如此,这种方法由于需要更多的输入token,可能会在处理长文本时遇到困难。此外,范例的挑选对于模型的最终表现至关重要,不恰当的范例选择可能会导致模型学习到不精确或有偏见的信息。
Input:
A "whatpu" is a small, furry animal native to Tanzania. An example of a sentence that uses
the word whatpu is:
We were traveling in Africa and we saw these very cute whatpus.
To do a "farduddle" means to jump up and down really fast. An example of a sentence that uses
the word farduddle is:
Outpu:
When we won the game, we all started to farduddle in celebration.
2. Reasoning and Logic 推理和逻辑
在推理与逻辑领域,我们见证了多种创新技术的诞生,这些技术使LLM 能够进行更加深入和复杂的思考过程。技术如Chain-of-Thought (CoT)、Automatic Chain-of-Thought (Auto-CoT)、Self-Consistency、Logical CoT等,都旨在促进模型以更结构化和逻辑性的方式处理信息,从而提高问题解决的准确性和深度。
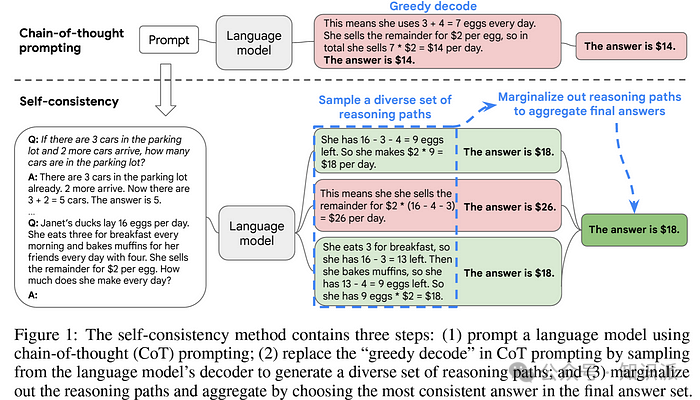
2.1 Chain-of-Thought (CoT) Prompting LLMs
为了克服LLM 在处理复杂推理任务方面的限制,Wei et al. (2022)[4]提出了一种称为CoT 的创新方法。该技术通过引入一种特殊的提示策略,旨在促进模型进行更为连续和逐步的思考过程。相较于传统的提示方法,连贯思考技术的主要贡献在于能够更有效地激发LLM 产出结构化且深入考虑的回答。
通过一系列实验,这一技术证明了其在促进模型执行逻辑推理中的独特效用,特别是在使模型对问题进行更深层次理解的方面。例如,它能详细描绘出解决复杂数学问题所需的逻辑步骤,这一过程非常类似于人类的解题思维。利用CoT,研究者们在使用PaLM 540B 模型进行的数学及常识推理测试中,达到了空前的准确率,高达90.2%。
2.2 Automatic Chain-of-Thought (Auto-CoT) Prompting
建立手动的CoT 范例虽然可以提高模型的推理能力,但这个过程既耗时又效率低下。为了解决这一问题,Zhang et al. (2022)[5]提出了Auto-CoT 技术。这项技术能够自动生成「让我们一步步来思考」式的提示,从而协助大型语言模型形成推理链。此技术尤其关注于避免单一推理链中可能发生的错误,通过多样化的样本生成来提升整体的稳定性。它能够针对各种问题产生多个独特的推理链,并将它们组合成一个终极范例集合。这种自动化和多样化的样本生成方法有效地降低了出错率,提升了少样本学习的效率,并避免了手工构建CoT 的繁琐工作。应用这种技术后,在使用GPT-3 进行的算术和符号推理任务测试中,相比于传统的CoT,准确率分别提高了1.33%和1.5%。
2.3 Self-Consistency
Wang et al. (2022)[6]提出了一种新型解码策略-- Self-Consistency,其目标在于「取代链式思考提示中使用的天真贪婪解码」。Self-Consistency 方法从语言模型的decoder 中提取多条不同的推理路径,从而生成多种可能的推理链。然后,通过综合这些推理链来寻找最为一致的答案。此策略建立在一个观点之上:那些需要深度分析的问题通常具有更多的推理路径,从而增加找到正确答案的可能性。
将Self-Consistency 与CoT 结合使用,在多个标准测试中都达到了明显的准确率提升,如在GSM8K 测试中提高了17.9%,在SVAMP 测试中提高了11.0%,在AQuA 测试中提高了12.2 %,在StrategyQA 测试中提高了6.4%,以及在ARC 挑战中提高了3.9%。
2.4 Logical Chain-of-Thought (LogiCoT) Prompting
对于LLM 来说,具备进行逻辑推理的能力,是对于解答跨领域的复杂多步问题的重要关键。Zhao et al. (2023)[7]提出的LogiCoT,与之前的逐步推理方法(例如CoT) 相比,引入了一个全新的框架。该框架吸取了symbolic logic 的精髓,以一种更加结构化和条理清晰的方式来增强推理过程。特别是,LogiCoT 采用了反证法这一策略,也就是通过证明某一推理步骤若导致矛盾则该步骤错误,从而来核查和纠正模型产生的推理步骤。这一「思考-核验-修正」的循环流程,有效地降低了逻辑错误和不正确的假设。在Vicuna-33b和GPT-4 的测试中,LogiCoT 对推理能力的提升显著,相比传统CoT,在GSM8K 资料集上的准确率分别提升了0.16% 和1.42%,在AQuA 资料集上则提升了3.15% 和2.75%。
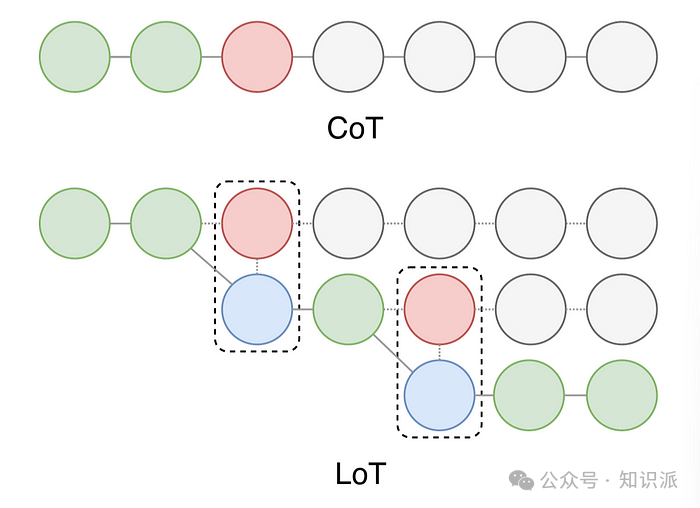
2.5 Chain-of-Symbol (CoS) Prompting
当面临涉及复杂空间关系的任务时,LLM 经常遇到挑战,部分原因是它们依赖于容易模糊且可能带有偏见的自然语言。为了克服这一限制,Hu et al. (2023)[8]提出了CoS 的新方法。这种方法选择不使用自然语言,而是采用简化的符号作为提示,其优势在于使提示变得更加清晰、简洁,同时显著提高了模型处理空间关系问题的能力,也使得模型的运作原理更易于被人理解。
然而,CoS 技术在可扩展性、适用范围、与其他技术的整合,以及基于符号的推理解释性方面,仍存在一定的挑战。值得注意的是,使用CoS 技术后,ChatGPT 在Brick World 空间任务的准确率显著提升,从31.8% 跃升至92.6%。此外,在简化提示的过程中,所需的符号数量也减少了高达65.8%,这不仅提升了效率,而且保持了高准确性。

2.6 Tree-of-Thoughts (ToT) Prompting
Yao et al. (2023)[9]与Long (2023)[10]提出了称为ToT 的新型提示框架,旨在增强模型在处理需要深度探索和前瞻性思考的复杂任务上的能力。ToT 在现有提示方法的基础上作了进一步的扩展,通过创建一个包含中间推理步骤的树状结构来实现,这些步骤被称作「思维」。每一「思维」代表着朝向最终答案前进的一系列连贯语言序列。这种结构让语言模型能够针对解决问题的进展,有目的地评估这些「思维」。ToT透过整合产生及评估「思维」的功能与搜索算法(如宽度优先搜索或深度优先搜索),实现了对推理过程的系统性探索。这使得模型能在找到有潜力的解决方案时进行拓展,或在遇到错误时进行回溯。在「24点游戏」这一任务上,ToT的效能尤为显著,成功率高达74%,大幅超过传统方法的4%。此外,在处理单词级任务时,ToT也表现出色,其成功率达到60%,明显高于传统方法的16%。
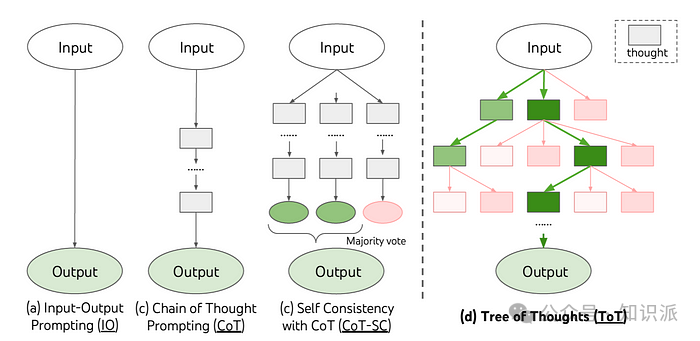
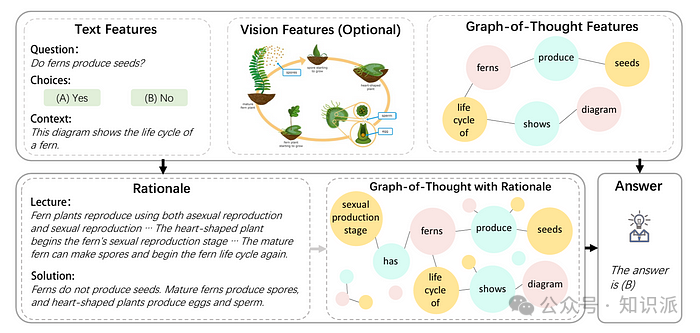
2.7 Graph-of-Thoughts (GoT) Prompting
我们的思考过程往往是非线性的,并非一步接一步地推进,这给基于传统的ToT 方法带来了挑战。针对这一点,Yao et al. (2023)[11]提出了一种创新的「图思维」(GoT) 提示方法。该方法通过构建思维图谱来模拟人类大脑的非线性思考模式,使得在不同的思维路径之间可以自由跳跃、回溯和整合资讯。这使得从多个角度进行思考成为可能,从而突破了传统线性思维的局限。GoT的核心创新在于将推理过程视为一个有方向的图结构,并通过灵活的模块化设计来支持思维的多样化转换。这种方法不仅更加贴近人类的思考模式,还显著增强了模型在处理复杂问题上的能力。实际应用中,GoT相比于传统的连贯思考(CoT)提示,在多个任务上展现出显著的效能提升。例如,在GSM8K资料集上,T5-base和T5-large模型的准确率分别提升了3.41%和5.08%。同时,在ScienceQA上,相较于最先进的多模态CoT方法,准确率分别增加了6.63%和1.09%。
2.8 System 2 Attention (S2A) Prompting
在LLM 的应用中,soft attention 有时会吸引不相关的信息,这可能会降低模型生成答案的准确度。为了克服这一挑战,Weston and Sukhbaatar (2023)[12]提出了一种称为S2A 的创新方法。这种方法通过重构输入的上下文,让模型能够集中于最关键的信息部分,从而显著提高了信息处理的质量和回应的相关性。S2A 特别通过一个两阶段过程来改进注意力机制和提高回答质量— — 首先是对上下文的重新生成,接着是在这个精炼的上下文上进行答案的生成。这个方法在包括事实性问答、长文本生成和解决数学问题等多个任务上进行了测试。在事实性问答任务中,S2A达到了80.3%的高准确率,明显提升了信息的准确性;而在长文本生成方面,它同样提升了文本的客观性,其得分达到3.82分(满分为5分)。

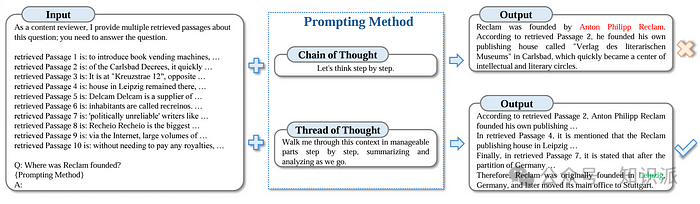
2.9 Thread of Thought (ThoT) Prompting
Zhou et al. (2023)[13]提出的ThoT,这是专为提高LLM 在处理复杂情境下的推理能力而设计的技术。这一方法模仿人类的思考过程,通过将复杂的情境分解成更小、更易于管理的部分来逐步进行分析。它采用了一种双阶段策略,即首先对每一个小部分进行概括和审视,随后进一步细化资讯以得出最终的答案。ThoT 的灵活性是其一大亮点,使其能够作为一个多功能的「即插即用」组件,有效地提升了多种模型和提示技术的推理效率。在对问答和对话类资料集进行测试时,特别是在复杂的情境中,ThoT展现了显著的效能提升,分别达到了47.20%和17.8%。
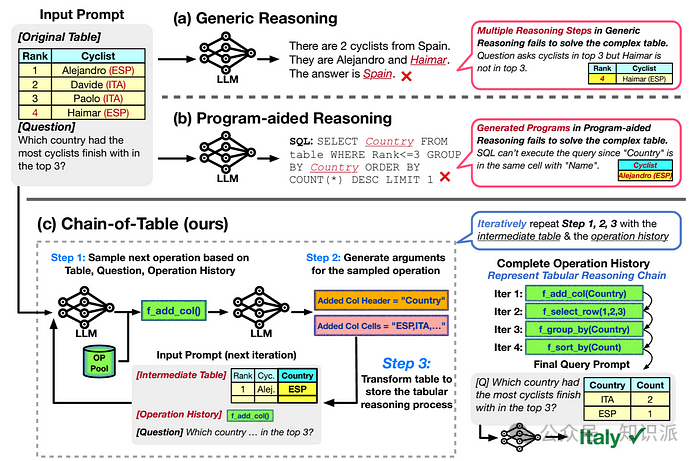
2.10 Chain-of-Table Prompting
传统的方法如CoT、PoT 和ToT 在展示推理步骤时,多依赖于自由文本或程式码形式,这在处理复杂表格资料时往往会遇到挑战。针对这一问题,Wang et al. (2024)[14]开发了一种创新的表格链式(Chain-of-Table) 提示方法。该方法通过对表格进行逐步的SQL/DataFrame 操作,实现了动态的表格推理过程,其中每一次的迭代都旨在改善中间结果,从而提升了LLM 利用逻辑推理链进行预测的能力。值得注意的是,表格链式提示方法在TabFact 和WikiTQ 这两个标准的表格资料集上实现了显著的效能提升,分别达到了8.69% 和6.72%。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。