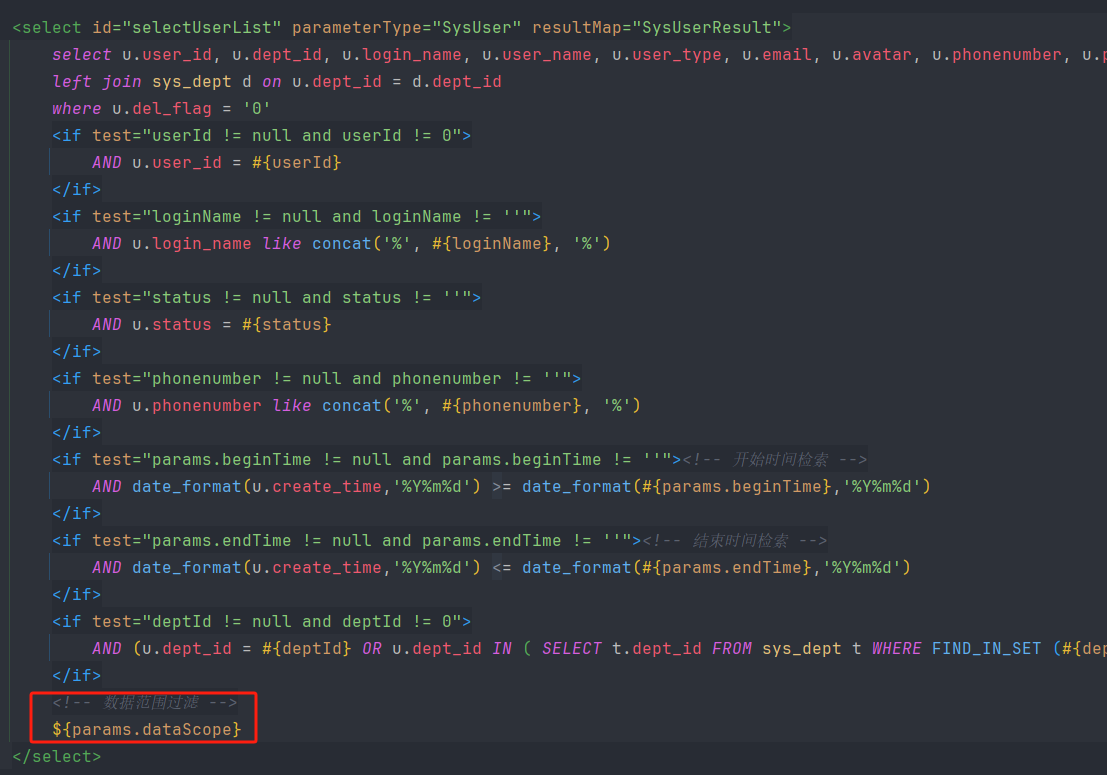
LinkedHashSet 的特点
- 去重:不允许重复的元素,类似于
HashSet。 - 有序:能够记住元素的插入顺序,类似于
LinkedList。 - 性能:具有较好的平均时间复杂度,如添加、删除和查找操作通常都是 O(1)。
内部实现
-
数据结构:
LinkedHashSet使用LinkedHashMap来存储元素。LinkedHashMap的键代表LinkedHashSet中的元素。LinkedHashMap的值通常是一个固定的静态实例PRESENT,用以标记元素的存在,而实际的值并不重要。
-
内部类 Entry:
LinkedHashMap继承自HashMap,因此它使用了HashMap的Entry类来表示映射关系。Entry包含了键 (key)、值 (value)、散列值 (hash)、下一个 (next) 和两个额外的指针 (before和after) 用于维护双向链表。
下面是一个简化的 LinkedHashMap 的 Entry 类的结构示例:
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next, Entry<K,V> before, Entry<K,V> after) {
super(hash, key, value, next);
this.before = before;
this.after = after;
}
}-
在
LinkedHashMap中,put方法会更新双向链表,确保新插入的元素位于链表尾部,或者根据accessOrder参数移动已存在的元素。 -
例如,当按照插入顺序排序时,
put方法的实现类似于:
public V put(K key, V value) {
int hash = hash(key.hashCode());
Node<K,V> node = getNode(hash, key);
if (node == null) {
// 新元素
putVal(hash, key, value, false, true);
linkLast(newEntry(hash, key, value, null));
} else {
// 更新已有元素
V oldValue = node.value;
node.value = value;
if (accessOrder) {
linkLast(node);
}
return oldValue;
}
return null;
}-
双向链表:
LinkedHashMap维护了一个双向链表,链表中的节点是Entry对象。before和after字段被用来连接双向链表中的前后节点。- 这个双向链表确保了
LinkedHashSet元素的插入顺序或访问顺序。
-
构造函数:
构造方法 描述 LinkedHashSet() 使用默认初始容量 (16) 和加载因子 (0.75) 构造一个新的空链接哈希集。 LinkedHashSet(int initialCapacity) 使用指定的初始容量和默认加载因子 (0.75) 构造一个新的空链接哈希集。 LinkedHashSet(int initialCapacity, float loadFactor) 使用指定的初始容量和加载因子构造一个新的空链接哈希集。 LinkedHashSet(Collection<? extends E> c) 使用与指定集合相同的元素构造一个新的链接哈希集。 -
迭代器:
- 当遍历
LinkedHashSet时,实际上是遍历底层LinkedHashMap中的条目。 - 由于
LinkedHashMap保留了插入顺序,因此遍历时元素的顺序与它们被添加的顺序相同。
- 当遍历
简化版的 LinkedHashSet 内部实现示例:
import java.util.AbstractSet;
import java.util.LinkedHashMap;
import java.util.Map;
public class SimpleLinkedHashSet<E> extends AbstractSet<E> {
private final LinkedHashMap<E, Object> map = new LinkedHashMap<>(16, .75f, true);
public SimpleLinkedHashSet() {
// 使用 true 表示按访问顺序排序
// 但实际上 LinkedHashSet 使用的是插入顺序
}
@Override
public boolean add(E e) {
return map.put(e, PRESENT) == null;
}
@Override
public boolean remove(Object o) {
return map.remove(o) == PRESENT;
}
@Override
public int size() {
return map.size();
}
@Override
public Iterator<E> iterator() {
return map.keySet().iterator();
}
private static final Object PRESENT = new Object();
}小练习:
给定一个整数数组 nums,请编写一个方法 preserveUniqueOrder,返回一个新的数组 result,其中包含 nums 中所有不同的元素,且保留它们在原始数组中的出现顺序。
示例:
- 输入:
[1, 2, 2, 3, 4, 3, 5] - 输出:
[1, 2, 3, 4, 5]
public class UniqueElementsOrder {
/**
* 保留唯一元素并保持其原始顺序
*
* @param nums 输入的整数数组
* @return 一个新的数组,其中包含原始数组中的不同元素,并保持它们的原始顺序
*/
public static int[] preserveUniqueOrder(int[] nums) {
// 使用 LinkedHashSet 保存元素,自动去重并保持插入顺序
Set<Integer> set = new LinkedHashSet<>();
for (int num : nums) {
set.add(num);
}
// 将 LinkedHashSet 转换为数组
int[] result = new int[set.size()];
int i = 0;
for (Integer num : set) {
result[i++] = num;
}
return result;
}
public static void main(String[] args) {
int[] input = {1, 2, 2, 3, 4, 3, 5};
int[] output = preserveUniqueOrder(input);
System.out.println(Arrays.toString(output));
}
}