大家好,我是程序媛雪儿,今天咱们聊mysql超大分页问题处理。
超大分页问题是什么?
数据量很大的时候,在查询中,越靠后,分页查询效率越低
例如
select * from tb_sku limit 0,10;
select * from tb_sku limit 9000000,10上面这条sql,需要查9000010条数据(9000010条数据需要被完整的扫描一遍),却只取最后10条返回,其他都会丢掉,查询代价太大!
在解决这个问题之前,我们先了解一下,什么是覆盖索引
覆盖索引
覆盖索引是指查询使用了索引,并且需要返回的列在索引中都能够找到
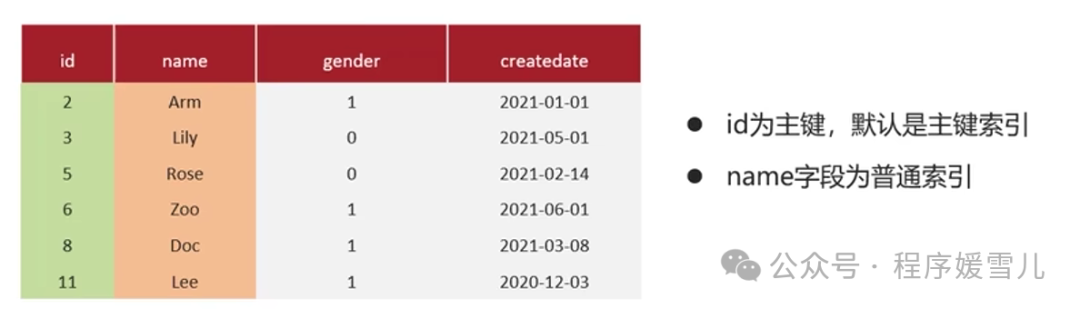
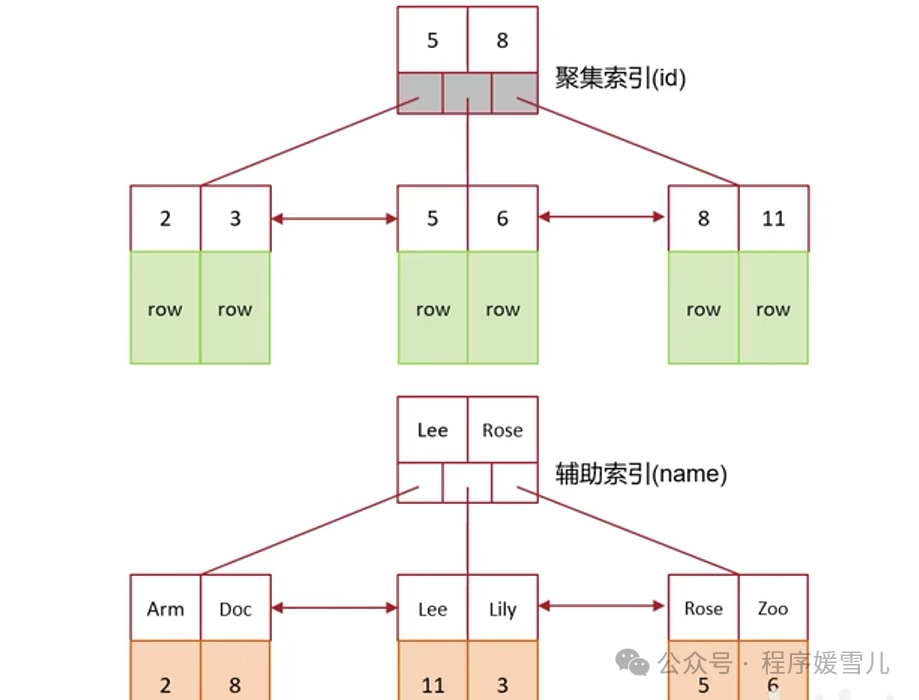
select * from tb_user where id = 1 ##覆盖索引因为根据id查,所建立的聚簇索引的叶子节点存储着所有数据
select id, name from tb_user where name = 'Arm' ## 覆盖索引因为根据name建立的二级索引,叶子节点志存着name和id,而查找的内容刚好是name和id
select id,name,gender from tb_user where name = 'Arm' ## 非覆盖索引因为根据name建立的二级索引里没有gender,需要根据id再到聚簇索引中找gender,换句话说,需要回表查询
优化方案
我们在了解覆盖索引之后,针对
select * from tb_sku limit 9000000,10这个sql语句,应该怎么优化呢?
思路:通过创建覆盖索引+子查询的形式进行优化
上面那个例子可以把sql改为
select *
from tb_sku t,
(select id from tb_sku order by id limit 9000000,10)a
where t.id = a.id;这种查询方式就可以避免回表查询,因为子查询中采用的是覆盖索引,已经包含了要查找的id,且id有序,因此可以快速跳到第9000000条数据并获取接下来的10个id,然后再根据id获取完整行的数据,这样节省了扫描前9000000条数据的时间,效率大大提升。
欢迎大家关注我的微信公众号,程序媛雪儿,雪儿会定期在上面发布编程的知识碎片,也有雪儿博客地址,上面有详细系统的笔记,雪儿是全栈,但是公众号目前主要还是发后端的技术,以后可能也会涉及到一些前端的知识,我们下期见,拜拜~