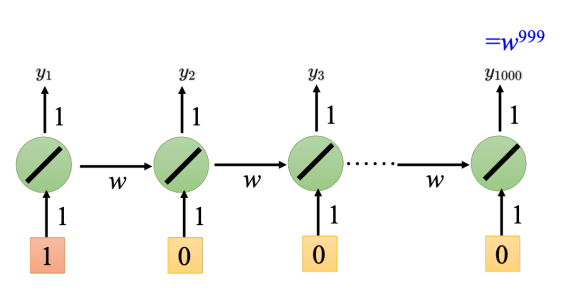
虚拟存储的基础是程序局部性理论,它的基本含义是程序执行时对内存访问的不均匀性。这一理论具体体现在两个方面:
时间局部性:时间局部性是指如果程序中的某个数据项被访问,那么在不久的将来它可能再次被访问。这通常是因为程序存在循环、函数调用等结构,导致某些数据项在一段时间内被频繁访问。例如,循环体内的变量、函数内的局部变量等都具有时间局部性。
空间局部性:空间局部性是指如果程序访问了某个存储单元,那么其附近的存储单元在不久的将来也很可能被访问。这通常是因为程序倾向于顺序访问存储单元,如遍历数组、结构体成员等。空间局部性有助于通过预取技术提高缓存命中率,进而提升程序执行效率。
其他选项如“代码的顺序执行”、“变量的连续访问”和“指令的局部性”虽然与程序执行和内存访问有关,但并未直接且准确地概括出程序局部性理论的核心内容。
算一个红球也没有的概率,七个球取四个/十个球取四个,组合数一算为1/6,用1减去即可。
- 表达式(0.666f-0.665f==0.001f),无论在任何平台,一定返回True。
这个描述是不正确的。浮点数在计算机中的表示是近似的,而不是精确的,这主要源于IEEE 754标准中浮点数的表示方式。在这种表示方式下,许多十进制小数无法被精确表示为二进制小数,从而导致了所谓的“舍入误差”。
对于表达式(0.666f-0.665f==0.001f),由于0.666、0.665和0.001在转换为浮点数时都可能存在舍入误差,因此它们的计算结果可能不会完全等于预期值。特别是当这些值被存储为单精度浮点数(float,即32位IEEE 754浮点数)时,由于精度限制,微小的误差可能会被放大,导致表达式的结果不为True。










int32_t是一个 32 位的整数,而int16_t是一个 16 位的整数。当我们将一个 32 位的值0x08172017赋值给a时,这个值在内存中的表示取决于机器的字节序(endianess)。
大端序(Big-endian):高位字节存储在内存的低地址端,低位字节存储在内存的高地址端。在这种情况下,
0x08172017在内存中的表示是08 17 20 17。因此,b会得到0x1720,而c会得到0x0817。但是,因为我们在打印时使用了%x格式说明符,所以b和c会以十六进制形式打印,即2017, 817。小端序(Little-endian):低位字节存储在内存的低地址端,高位字节存储在内存的高地址端。在这种情况下,
0x08172017在内存中的表示是17 20 17 08。因此,b会得到0x1720,而c会得到0x1708。union介绍
共用体,也叫联合体,在一个“联合”内可以定义多种不同的数据类型, 一个被说明为该“联合”类型的变量中,允许装入该“联合”所定义的任何一种数据,这些数据共享同一段内存,以达到节省空间的目的。union变量所占用的内存长度等于最长的成员的内存长度。
举个例子
1
2
3
4
5
6
uniontest
{
charmark;
longnum;
floatscore;
};sizeof(union test)的值为4。因为共用体将一个char类型的mark、一个long类型的num变量和一个float类型的score变量存放在同一个地址开始的内存单元中,而char类型和long类型所占的内存字节数是不一样的,但是在union中都是从同一个地址存放的,也就是使用的覆盖技术,这三个变量互相覆盖,而这种使几个不同的变量共占同一段内存的结构,称为“共用体”类型的结构。
因union中的所有成员起始地址都是一样的,所以&a.mark、&a.num和&a.score的值都是一样的。
指数分布:
指数分布是一种连续概率分布,用来描述在给定时间间隔内发生某事件的次数的概率。它通常用于模拟等待时间(如顾客到达商店的时间间隔)等场景。因此,指数分布是连续型分布。均匀分布:
均匀分布也是一种连续概率分布,其中所有可能的结果都具有相同的概率。在连续型均匀分布中,随机变量可以在一个指定的区间内取任意实数值,且每个值被取到的概率是相等的。因此,均匀分布也是连续型分布。泊松分布:
泊松分布是一种离散概率分布,它描述了在固定时间间隔内或固定空间区域内发生某事件的平均次数(即“率”的参数)已知时,该事件实际发生次数为某值的概率。由于泊松分布描述的是离散的事件次数,因此它不是连续型分布。正态分布:
正态分布(也称为高斯分布)是一种非常重要的连续概率分布。它描述了许多自然现象和社会现象的随机变量。正态分布曲线是关于其均值对称的,且曲线下的总面积为1。因此,正态分布是连续型分布。
C选项是有向图,无法根据边的个数判断出度。
D选项应该为8个顶点