基于站点的中国6小时PM2.5数据集(1960-2020)
数据介绍
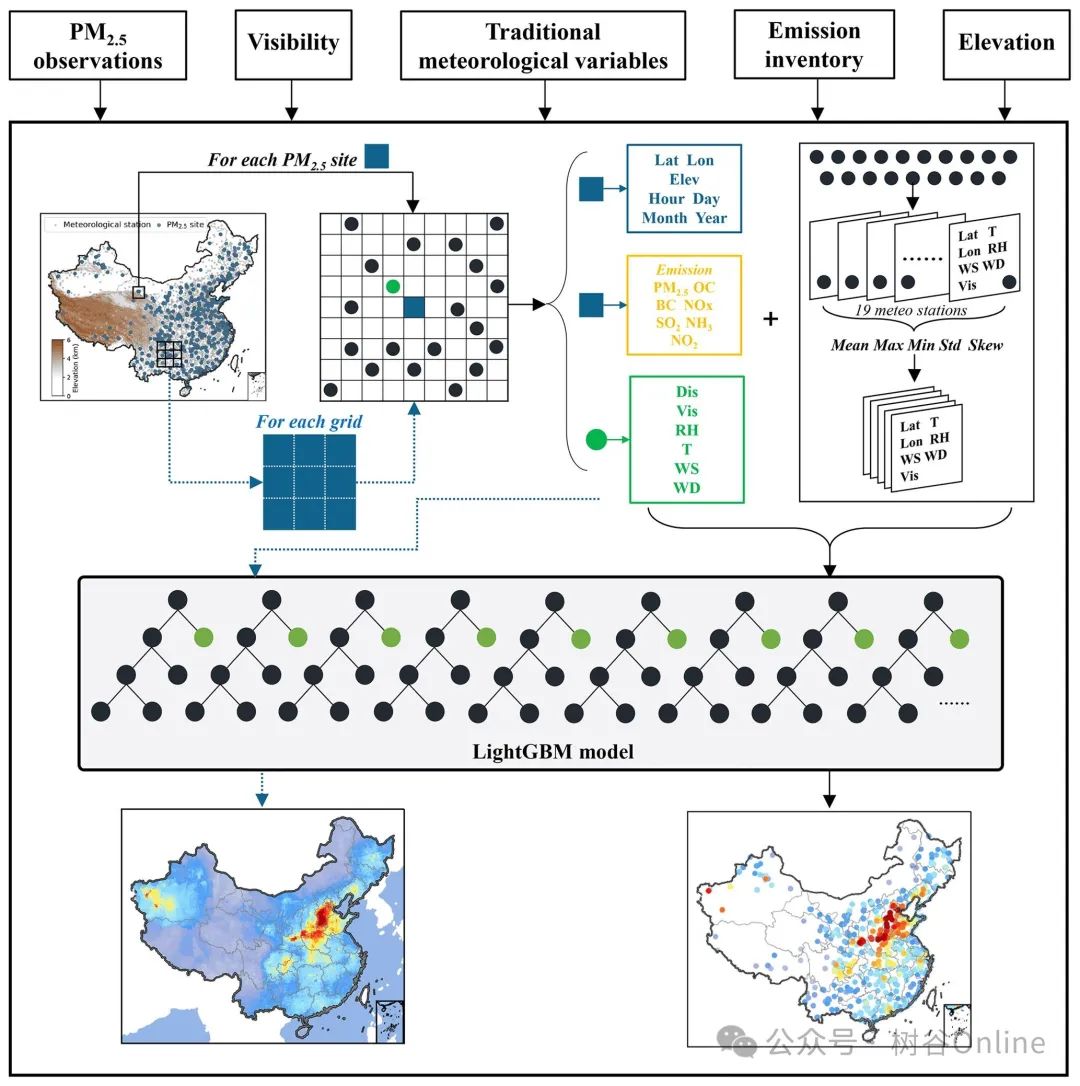
几十年来,PM2.5改变了地球上的辐射平衡,增加了环境和健康风险,但直到2013年才在中国得到广泛监测。历史长期 PM2.5具有高时间分辨率的记录是必不可少的,但对于研究和环境管理都缺乏。在该数据集中,我们重建了一个基于站点的PM2.5从 1960 年到 2020 年每隔 6 小时一次的数据集,结合了长期能见度、常规气象观测、排放和高程。PM2.5每个站点的浓度都是根据先进的机器学习模型LightGBM估算的,该模型利用了周围20个气象站的空间特征。我们的模型在按年交叉验证(CV)方面的表现与以前的研究相当甚至更好(R2=0.7) 和空间 CV (R2=0.76),在长期记录和高时间分辨率方面更具优势。该模型还重建了一个 0.25°×0.25°、6 小时网格化 PM2.5数据集,通过合并空间要素。结果显示PM2.5污染逐渐恶化或在2010年之前从年代际规模持续,但在接下来的十年中有所缓解。尽管不同地区的转折点各不相同,但PM2.52013年后,由于清洁空气行动,关键区域的质量浓度显着下降。特别是PM2.5的年平均值2020年几乎处于1960年以来的历史最低值。该PM2.5数据集提供高分辨率的时空变化,为与空气污染、气候变化和大气化学再分析相关的研究奠定了基础。
数据源描述:
1.PM2.5观测数据:每小时PM2.5自2013-2020 年所有站点的数据均来自中国国家环境监测中心(CNEMC,http://www.cnemc.cn);2013 年之前 PM2.5美国驻北京和上海大使馆的测量值是用于独立验证评估(http://www.stateair.net/web/historical);
2.能见度和常规气象数据:从国家气象信息中心(NMIC)收集的气象观测数据包括 1960-2020 年间的 6 小时记录和 2013 年以后逐渐增加的小时记录;
3.排放清单和海拔高度:1960-2012 年的历史人为排放量来自北京全球排放清单,该清单采用自下而上的方法编制,时间分辨率为 1 个月间隔(http://inventory.pku.edu.cn);2013-2020 年期间的当前人为排放量来自《中国多分辨率排放清单》(MEIC,http://meicmodel.org);30 米高程数据来自全球数字高程模型(GDEM)第 2 版(https://earthexplorer.usgs.gov);
4.辅助数据:月归一化差异植被指数(NDVI)产品从一级大气档案和分发系统分布式主动档案中心(LADDS DAAC,https://ladsweb.modaps.eosdis.nasa.gov)获取;土地覆被分类数据来自国家地理信息资源目录服务系统(https://www.webmap.cn/mapDataAction.do?method=globalLandCover);人口数据来自世界网格人口第 4 版(GPWv4,https://sedac.ciesin.columbia.edu/data/collection/gpw-v4)。
数据加工方法:
对于每个 PM2.5 站点,提取五个变量作为时间输入,包括年、月、日、时和年日。经度和纬度变量作为位置输入。将离每个 PM2.5 最近的气象站的能见度、相对湿度和温度作为基本气象输入,这两个站点之间的距离也被添加为一个特征。之前的研究开发了一种新颖的特征工程方法,通过提取空间特征将周边影响纳入其中。具体来说,每个 PM2.5 站点都匹配了除最近气象站之外的其余 19 个最近站点。从 19 个站点中选取了五个变量,包括经度、纬度、温度、能见度和相对湿度。然后,分别计算了这五个变量的最大值、最小值、平均值、偏度值和标准偏差。这些利用周边条件生成的特征也被视为输入。时空特征提取后,共有 71 个特征被用作模型训练的输入。为了在保证精度的前提下减少计算和训练时间,在小样本测试过程中按重要性排序的前 40 个特征被用于接下来的模型训练和后报。这些特征包括能见度、时间特征、空间特征、排放特征和海拔高度。
数据信息
| 采集时间 | 1960/01/01 - 2020/12/31 |
|---|---|
| 采集地点 | 中国 |
| 数据量 | 3.6 GiB |
| 数据格式 | nc |
| 数据空间分辨率(/米) | 0.25 |
| 数据时间分辨率 | 年 |
| 坐标系 | |
| 投影 | WGS_1984 |
数据作者
数据贡献者:张晓叶
元数据作者:张晓叶
数据管理者:张晓叶
数据下载
数据分享:基于站点的中国6小时PM2.5数据集(1960-2020)