🚀🚀🚀 大家觉不错的话,就恳求大家点点关注,点点小爱心,指点指点🚀🚀🚀
目录
🐰结构
🏡 前言
🌸数据类型的定义
🌸关键字struct 与 class 的困惑
🌸使用struct
🐰位域
🏡前言
🤔提示
🤔提示
🌸成员对齐
🌸结构内存大小的计算
🐰联合(Union)
🏡前沿
🌸联合内存大小的计算
🐰枚举(Enum)
🏡前言
🌸枚举类型的大小
🤔‼️提示
🐰结构
🏡 前言
如果只能使用基本数据类型来编程,那将是一件痛苦的事情。C语言支特把基本数据类型组合起来形成更大的构造数据类型,这就是C语言的struct,有时也称为用户自定义数据类型 (User defined Type, UDT)。
🌸数据类型的定义
构造数据类型还可以嵌套(对象嵌入)和引用(对象关联),实际上,构造数据类型是一个递归的定义:(1)由若干基本数据类型组合而成的类型是构造数据类型(2)由若干基本数据类型和构造数据类型组合而成的数据类型是构造数据类型(3)由若干构造数据类型组合而成的数据类型是构造数据类型。
‼️注:语言本身的这种能力使我们能够定义非常复杂的数据结构,例如树 (tree)、链表 (list)和映射(map)等。
🌸关键字struct 与 class 的困惑
C++语言对C 语言的 struct 进行了改造,使其也可以像class 那样支持成员函数的声明和定义,从而使struct 变成真正的抽象数据类型 (Abstract Data Type. ADT),这使得许多人对 struct 和 class 倍感困惑。当语言支持某种特征时,是否使用这种特征则完全取决于程序员。因此,并不是说class 支持成员函数的定义,我们就一定要在每一个class 中都定义成员函数;也并不是说 struct 过去不支持成员函数定义,我们就非得用 class 完全取代struct。实际上就 C++语言本身来讲,struct 和 class 除了“默认的成员访问杖限”这一点不同外没有任何区别。
‼️注:在C++语言中,如果不特别指明,struct 成员的默认访问限定符为 public,而class 成员的默认访问限定符为 private.因此,在C++程序中,只要你明确地声明每一个成员的访问权限,那么完全可以用 struct 取代class,也完全可以用 class 取代struct。
‼️注:为了不让程序产生混乱和妨碍理解,建议还是使用struct定义简单数据集合,而定义一些具有行为的ADT时最好采用class
🌸使用struct
在C++环境中,我们把C 风格的struct 叫做 POD (Plain Old Data)对象,从字面上你也可以知道它仅包含一些数据成员,这些数据成员可以是基本数据类型变量任何类型的指针或引用、任何类型的数组及其他构造类型的对象等
‼️注:虽然把数组当做参数传递给函数的时候,数组将自动转换为指针,但是包装在struct/class 中的数组其内存空间则完全属于该struct/class 的对象所有。如果把struct/class 当做参数传递给函数时,默认为值传递,其中的数组将全部拷贝到函数堆栈中因此,当你的 UDT/ADT 中包含数组成员的时候,最好使用指针或引用传递该类型的对象,并且一定要防止数组元素越界,否则它会覆盖后面的结构成员。
‼️注:构造类型虽然可以嵌套定义,但是嵌套定义的类型对象不一定存在包含关系,存在包含关系的对象类型也不一定是嵌套定义的。
🐰位域
🏡前言
以字节为单位的存储模式会浪费大量的内存空间,位域以单个的位(bit)为单位来设计struct所需要的存储空间,因此你可以根据数据成员的有效取值范围来仔细规划他们各自所需要的位数
Struct Datatime { Int year; Int month :4; Int day :5; Int hour :5; Int minute :6; Int second :6; }C语言位域各成员的类型必须是 int,unsigned int, signed int等类型,c++还允许使用char,long等
不允许使用指针类型和浮点类型作为位域的成员类型 。signed int等类型数据的正负符号要占用一位,因此该类型的位域成员的长度至少为2.
🤔提示
不要定义超越类型的最大位数的位域成员,例如Struct DatdTime { Unsigned int year :33;//位越界 };不仅会导致结果上溢,还会导致一个成员跨越两字节的边界却又不能占满字节,导致浪费
可以定义长度为0的位域成员,其作用是迫使下一个成员从下一个完整的机器字(word)开始分配空间
🤔提示
(1)位域成员的访问方法和结构成员的访问没有区别。(2) 不能取一个位域对象的数据成员地址 ,即使该成员完全与字节边界对齐,因为字节是编址最小单位而不是位; 但是可以取位域对象的地址(跟取结构体对象地址一样) ,即使位域所有成员的总位数达不到整字节的倍数,位域对象也会对齐。(3)不要把位域成员当作位的数组,因此不能使用访问数组的方法来访问位域成员的单个位。注:使用位域节省存储空间会导致程序运行速度的下降,因为计算机无法直接寻址到单个字节中的某些位,必须通过额外的代码来实现。这种矛盾是由计算机的基本原理决定的,在“内存空间”和“运行速度”无法同时优化的情况下,由应用需求来决定优化哪一个
🌸成员对齐

你能说出 Sedan 的对象在内存中实际占据的字节数是多少吗?或者更直接地说,这个结构的大小是多少呢?这个结构定义中的数据成员的声明顺序或者说这个结构的成员布局是不是合理的呢?为什么?如果不合理,怎样调整才能既不损失数据成员的访问效率,又能使对象的内存占用量最少呢?许多人会说:把所有成员的大小加在一起不就行了(即15字节)吗?果真如此简单吗?更多的人会立刻说:用sizeof运算符让编译器帮我们计算不就行了吗?的确,任何时候都应该用 sizeof运算符来计算一个类或者对象的大小,而不要自己猜测。但是如果仅仅想到这一步还不够!
✈️CPU 对对象的访问效率与什么有关系呢?是它们的地址的特点。对于复合类型 (一般指结构和类)的对象,如果它的起始地址能够满足其中要求最严格 (或最高)的那个数据成员的自然对齐要求,那么它就是自然对齐的;如果那个数据成员又是一个复合类型的对象,则依次类推,直到最后都是基本类型的数据成员。什么是“自然对齐要求最严格” 呢?举例来说吧:double 变量的地址要能够被 8整除,而int 变量的地址只需能被4 整除即可,一个bool 变量的地址则只需能被1整除。所以double 类型的自然对齐要求就要比 int 类型严格,int 类型的对齐要求又比bool 类型严格,因为能够被8 整除的地址肯定能被 4 整除,但是反过来就不一定了。在C++/C 的基本数据类型中,如果不考虑enum 可能的最大值所需的内存字节数,double 就是对齐要求最严格的类型了,其次是int 和float, 然后是short、bool和 char。例如,考虑 Sedan 的自然对齐要求。由于Sedan 的所有成员都是基本类型,显然double 成员m price 的对齐要求最严格,因此 Sedan 的对象的地址应该能被8整除。此外,如果编译器按照自然对齐的要求布局 Sedan 的内存映像的话,mprice 的偏移量还必须是8的倍数才能确保也总是自然对齐的,在这里应该是16字节;其他成员的末始地址也需要满足各自的自然对齐要求。在复合类型的对象中,各个数据成员在内存中是如何排列的呢?一般说来,没有编译器会故意自找麻烦而把用户定义的数据成员声明顺序打乱来构造对象,都会直接依照声明顺序来存放,即使复合类型中存在多个访问段(即 C++类中的每个public、private 和protected 访问限定符),至少也会保证每个段内的所有数据成员是按照声明顺序来存放的。至于先声明的成员会被放在高地址还是低地址处,完全是由编译器实现来决定的,而且一般都会采用“按照声明的先后顺序从低地址到高地址依次布放各个成员” 的方案。同时,为了满足各个成员的对齐要求,各个成员之间甚至对象的末尾可能会插入一定量的填充字节,因此对象的实际大小往往比把各个成员的大小简单加在一起要大。为什么有的对象会在末尾插入一定量的填充字节呢?因为编译器在考虑一个类型的大小的时候,不仅要考虑一个对象的对齐要求还要考虑该类型对象数组的对齐要求,这样才能保证用户在使用对象数组时也具有和单个对象一样的访问效率。注意:绝对不会在对象开头插入填充字节.基于上述认识,假设 Sedan 的对象s的起始地址为 0x00031D10,则s 的内存布局将可能如图 8-1 所示(假设按照声明的先后顺序从低地址到高地址依次布放各个成员)
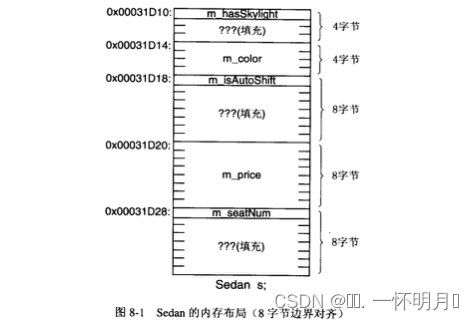
🌸结构内存大小的计算
结构体内存对齐的规则1.第一个成员与结构体变量偏移量为0的地址处2.其他成员变量要对齐到某个数(对齐数)的整数倍的地址处3.对齐数=编译器默认的一个对齐数(8)与该成员大小的较小值4.结构体的总大小是结构体的所有成员的对齐数中最大的那个对齐数的整数倍5.如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍
🐰联合(Union)
🏡前沿
联合也是一种构造数据类型,它提供了一种不同类型数据成员间共享储存空间的方法,同时可以实现不同数据类型成员之间的自动类型转换。但是与结构不同的是,联合对象在同一时间只能存储一个成员的值(即只有一个数据库是活跃的)。因此,如果你同时访问一个联合对象的多个成员,那么其中最多只有一个值是正确的
🌸联合内存大小的计算
这些类型定义的变量也包含一系列的成员,特征是这些成员共用一块空间(也叫共用体)
联合体的大小:
1.至少是最大成员的大小
2.当最大成员大小不是最大对齐数的整数倍的时候,就要对齐到最大对齐数的整数倍
🐰枚举(Enum)
🏡前言
C++/C 枚举类型允许我们定义特定用途的一组符号常量,它表明这种类型的变量可以取值的范围。当你定义一个枚举类型的时候,如果不特别指定其中标识符的值,则第一个标识符的值将为 0,后面的标识符将比前面的标识符依次大1;如果你指定了其中某一个标识符的值,那么它后面的标识符自动在前面的标识符值的基础上依次加1,除非你也同时指定了它们的值。
🌸枚举类型的大小
在标准C中,枚举类型的内存大小等于 sizeof (int)。但是在标准C++中,枚举类型的底层表示并非必须是一个int————它可以更小或更大。换句话说,如果一个枚举变量的取值范围小到足以用一个short 或 byte 来表示,那么这个枚举变量的底层表示就可能采用 short 或 byte:相反如果一个枚举变量的取值范围大到必须用一个比 int更大的类型来表示的话,那编译器允许使用更大的类型来表示枚举变量
🤔‼️提示
枚举变量和常量都可以参与整型变量能够参与的某些运算,但注意不要给枚举变量赋予一个不在枚举常量列表中的值,例如,不要对枚举变量使用++,--,+=,-=等操作,除非你为它特别重载了这些运算符虽然枚举是和整数类型兼容的数据类型,但是它们之间的转换还是有一些需要注意的地方。枚举类型变量一般可以直接转换成某种整数类型,除非其值超出了这种整数类型可以表示的范围。但是一个整型变量在强制转换成枚举类型后就不一定具有一个有效的值了,这是因为:整型数是连续的,而枚举类型变量的取值很可能是不连续的,因此当你把一个值不等于任何一个枚举常量的整型变量强制转换成这种枚举类型时,其结果就不得而知了。
🔥🔥🔥希望看完本篇后,加深大家对自定义类型的印象,如果大家还有不懂或者建议都可以发在评论区,我们共同探讨,共同学习,共同进步。谢谢大家! 🔥🔥🔥