目录
一、引用的概念
二、引用的应用
1.特性
2.使用场景
2.1 引用作为函数参数
2.2 引用作为函数返回值
三、引用的权限问题
四、引用和指针的区别
一、引用的概念
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。
比如,水浒传里面的李逵,绰号“黑旋风”、“铁牛”。那么 “李逵” 是他的本名,但是叫他 “黑旋风” 也可以,叫他 “铁牛” 也可以,这三个名号说的都是同一个人。
引用的语法如下,值得注意的是,引用类型和引用实体必须是同一种类型才可以:
类型& 引用变量名(对象名) = 引用实体;
如下,就是引用的一个例子, ra 是 a 的一个别名。我们也可以从内存的角度来理解引用,下方图片就很好地解释了什么是引用,原本只有一个变量a, ra 是 a 的引用,那么 ra 和 a一样,也代表这一块空间,并没有新开辟一个空间,ra也不是一个指针。
int a = 10;
int& ra = a;
二、引用的应用
1.特性
要使用引用,首先要了解它的一些特性,熟悉使用规则。
1. 引用在定义时必须初始化。
2. 一个变量可以有多个引用。
3. 引用一旦引用一个实体,再不能引用其他实体。
2.使用场景
2.1 引用作为函数参数
如下,再写 Swap 函数的时候,就可以使用引用了。下方代码,left 、right 虽然是形式参数,但都是实参的别名,即使是在函数内部改变了这两个变量的值,实参也会相应地改变。
void Swap(int& left, int& right)
{
int temp = left;
left = right;
right = temp;
}当然了,既然把引用作为形参,在函数内部可以直接改变实参的值,那么对于无头链表,之前插入数据的时候要考虑:如果链表没有数据,插入就要改变指针的值,所以要传二级指针。在这里直接 引用 就可以不用二级指针,如下代码,phead 是 Node* 类型的一个引用。
void PushBack(Node*& phead, int x)
{
Node* newhead = (Node*)malloc(sizeof(Node));
if (!phead)
{
phead = newhead;
}
}2.2 引用作为函数返回值
引用作函数返回值可是有点说头了,比如,下面代码输出结果会是什么?
int& Add(int a, int b)
{
int c = a + b;
return c;
}
int main()
{
int& ret = Add(1, 2);
Add(3, 4);
cout << "Add(1, 2) is :"<< ret <<endl;
return 0;
}答案是:不确定。为什么?(要先有预备知识,明白函数调用的过程中发生了什么:函数栈帧的创建和销毁)我们可以通过下面这张图来加深理解:首先,调用Add函数的时候(下图左边),在Add函数栈帧的内部创建了 c 这个变量,为其开辟了一块空间。当 Add 函数调用结束(下图右边),Add的函数栈帧自然也销毁了,对应的内存空间还给了操作系统,但是,这块空间并不是不存在了,它依然在那里,地址也没有改变,只是这块空间里面的数据是否被操作系统设置成随机值了,我们并不知道。所以这一块地址里的数据,有可能和销毁前一样,也有可能是随机值。这就是答案是 “不确定” 的原因。
由于这块空间的地址是没有改变的,所以只要知道变量 c 的位置,就可以得到原本变量c 那一块空间的值。Add 函数返回了 c 的引用,由 ret 接收,那么 ret 和 c 代表的其实是同一块空间,所以可以通过 ret 来查看 c 那一块空间的值。(如果不了解 函数的返回值是如何传递的,可以看上面所说的预备知识,里面有讲。)
而由于 main 函数中,两次调用了 Add 函数,所以第二次调用的时候, ret 对应空间的值被修改成了 7 ,调用结束之后,那块空间是否被设置成随机值要看操作系统。所以输出结果有可能是 7,也有可能是随机值。

因为这样的问题,所以我们就不可以使用 引用 作为函数的返回值了吗?当然不是,上面讲到的变量 c 不适合作返回值,是因为变量 c 对应的空间,在函数调用结束之后,就不受控制了,还给操作系统了。那如果函数内部定义了一个变量 x ,在该函数调用结束之后,x 依然存在,且不会被还给操作系统,不会有任何修改,那么我们就可以将 x 作为返回值。
比如下面一段代码,n 虽然是在Count 函数内部创建,但是却被 static 修饰,n 在静态区,所以即使函数调用结束, n 依然存在,将其作为返回值,不会造成bug。
int& Count()
{
static int n = 0;
n++;
return n;
}所以,对于引用作为函数的返回值,可以有一下一点点总结:
如果函数返回时,出了函数作用域,如果返回对象还在(还没还给系统),则可以使用
引用返回,如果已经还给系统了,则必须使用传值返回。
三、引用的权限问题
并不是什么情况下都可以对变量进行引用的,比如下方情况,编译器就会报错。 c 是被 const 修饰的 int 类型的变量,但是 d 这个引用并没有用 const 修饰,假设引用没有问题,那么改变 d 的值也就是改变 c 的值,但是 c 被const修饰,不可以改变,所以矛盾。
这就是权限放大,将原本不可以改的变量(权限小),引用后可以修改(权限大),这样使用肯定是不可以的。(指针也是同理)
所以,在引用的时候,只可以权限平移或者权限缩小,不可以进行权限放大。
// 权限平移
int a = 10;
int& b = a;
// 权限缩小
int x = 10;
const int& y = x; 但是这里要进行概念区分,权限的放大和缩小,只适用于引用和指针,因为引用是起一个别名,b的改变会影响a,指针也会改变指向的内存里的数据。但是如下设计,m、n是两块不同的空间,也就不存在上述问题。
const int m = 10;
int n = m; // 把 m 的值赋给 n我们再来理解一个例子,首先要清楚下方代码中,(double)i 并不是将变量 i 转化成double 类型的变量,而是把 i 放到一个 double 类型的临时变量里面,而 i 依然是 int 类型的变量。例如 double k = (double) i ; 这样子,k是double 类型的变量,但是 i 不是。
int i = 10;
cout << (double)i << endl; 再如下方,这两行代码是没有问题的,只不过把 i 放到临时变量里面的过程省略了而已。
int i = 10;
double dd = i; 但是,如下图,如果设计一个 double 类型的引用,会报错,这是为什么?是因为double 和 int 是不同类型吗?如果是, i 不是会进行强制类型转换,放到临时变量里面吗?考虑到这里,其实已经八九不离十,就是因为临时变量的存在!临时变量有一个性质——常性,这个“常”是常量的“常”,也就是说,临时变量也是不可修改的,由于等号右边是不可修改的临时变量,左边是可修改的引用,那就相当于权限放大,所以编译错误了。
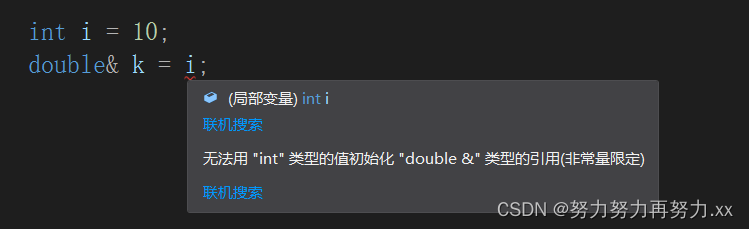
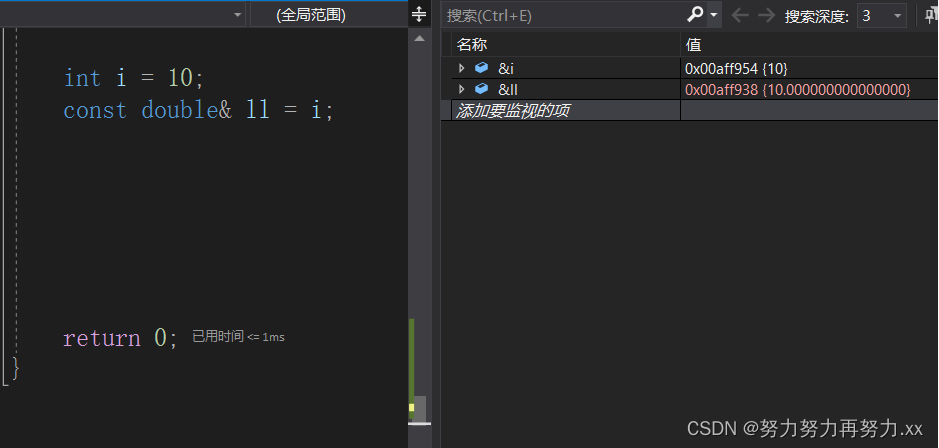
所以,让左边的引用也不可修改就好,加上一个const 就可以通过了,如下图的代码。同时,我们还可以用调试来证明 i 是被放到一个double类型的临时变量里的,下图监视窗口可以看出, i 和 ll 的地址是不一样的,引用应该是同一块空间才对,所以这里的引用并不是引用 i ,而是对临时变量进行引用。
四、引用和指针的区别
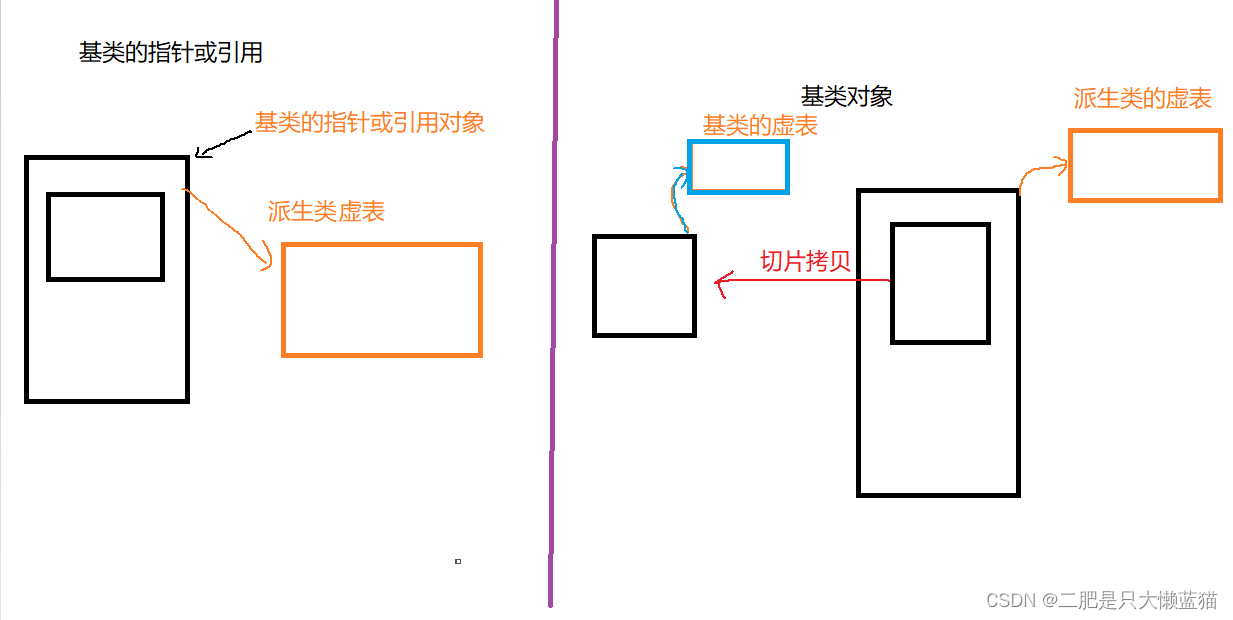
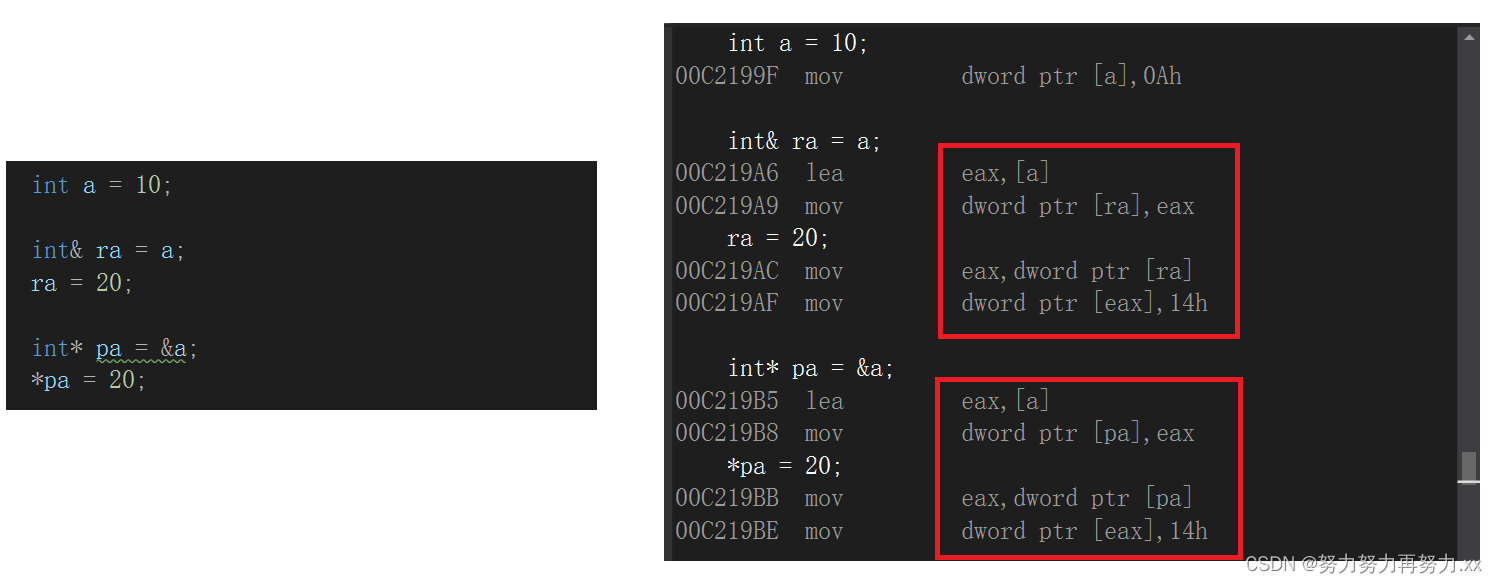
引用在语法概念上引用就是一个别名,没有独立空间,和其引用实体共用同一块空间。但是引用在底层实现上实际是有空间的,因为引用是按照指针方式来实现的(我们使用的时候不必关心这点)。可以通过汇编代码来验证,如下,VS环境下将C语言代码转换成汇编代码,可以看到对 a 进行引用和设计指针,其底层实现都是一样的。
引用和指针的不同点:
1. 引用概念上定义一个变量的别名,指针存储一个变量地址。
2. 引用在定义时必须初始化,指针没有要求。
3. 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体。
4. 没有NULL引用,但有NULL指针。
5. 在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占4个字节)。
6. 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小。
7. 有多级指针,但是没有多级引用。
8. 访问实体方式不同,指针需要显式解引用,引用编译器自己处理。
9. 引用比指针使用起来相对更安全。