前言
协程系列文章:
- 一个小故事讲明白进程、线程、Kotlin 协程到底啥关系?
- 少年,你可知 Kotlin 协程最初的样子?
- 讲真,Kotlin 协程的挂起/恢复没那么神秘(故事篇)
- 讲真,Kotlin 协程的挂起/恢复没那么神秘(原理篇)
- Kotlin 协程调度切换线程是时候解开真相了
- Kotlin 协程之线程池探索之旅(与Java线程池PK)
- Kotlin 协程之取消与异常处理探索之旅(上)
- Kotlin 协程之取消与异常处理探索之旅(下)
- 来,跟我一起撸Kotlin runBlocking/launch/join/async/delay 原理&使用
- 继续来,同我一起撸Kotlin Channel 深水区
- Kotlin 协程 Select:看我如何多路复用
- Kotlin Sequence 是时候派上用场了
- Kotlin Flow 背压和线程切换竟然如此相似
- Kotlin Flow啊,你将流向何方?
- Kotlin SharedFlow&StateFlow 热流到底有多热?
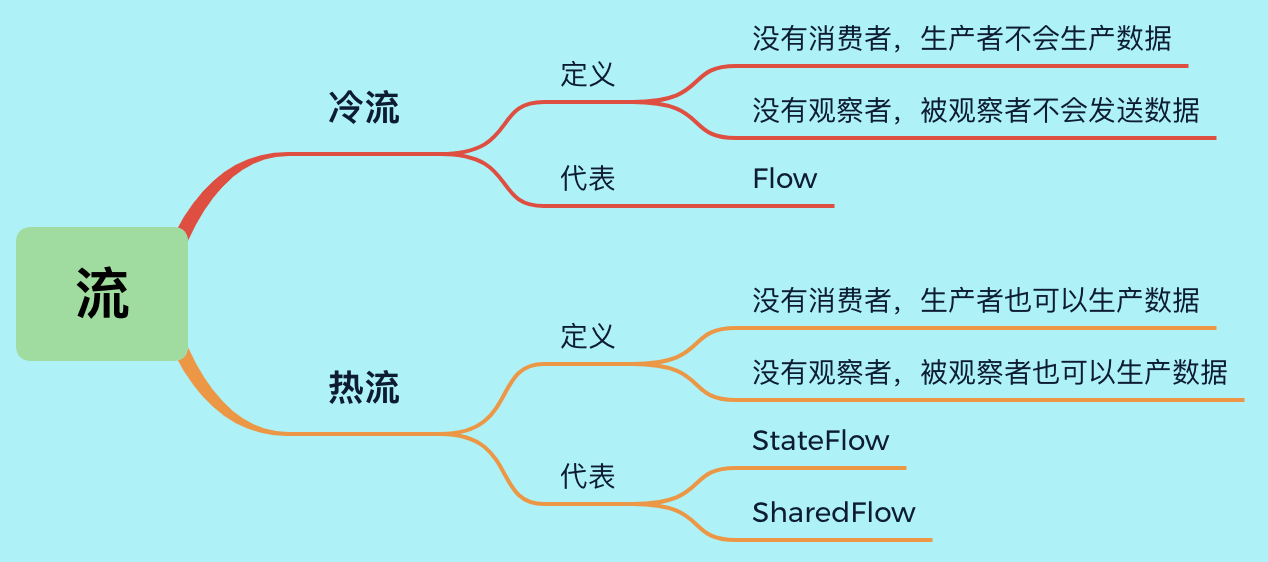
前面分析的都是冷流,冷热是对应的,有冷就有热,本篇将重点分析热流SharedFlow&StateFlow的使用及其原理,探究其"热度"。
通过本篇文章,你将了解到:
- 冷流与热流区别
- SharedFlow 使用方式与应用场景
- SharedFlow 原理不一样的角度分析
- StateFlow 使用方式与应用场景
- StateFlow 原理一看就会
- StateFlow/SharedFlow/LiveData 区别与应用
1. 冷流与热流区别
2. SharedFlow 使用方式与应用场景
使用方式
流的两端分别是消费者(观察者/订阅者),生产者(被观察者/被订阅者),因此只需要关注两端的行为即可。
1. 生产者先发送数据
fun test1() {
runBlocking {
//构造热流
val flow = MutableSharedFlow<String>()
//发送数据(生产者)
flow.emit("hello world")
//开启协程
GlobalScope.launch {
//接收数据(消费者)
flow.collect {
println("collect: $it")
}
}
}
}
Q:先猜测一下结果?
A:没有任何打印
我们猜测:生产者先发送了数据,因为此时消费者还没来得及接收,因此数据被丢弃了。
2. 生产者延后发送数据
我们很容易想到变换一下时机,让消费者先注册等待:
fun test2() {
runBlocking {
//构造热流
val flow = MutableSharedFlow<String>()
//开启协程
GlobalScope.launch {
//接收数据(消费者)
flow.collect {
println("collect: $it")
}
}
//发送数据(生产者)
delay(200)//保证消费者已经注册上
flow.emit("hello world")
}
}
这个时候消费者成功打印数据。
3. 历史数据的保留(重放)
虽然2的方式连通了生产者和消费者,但是你对1的失败耿耿于怀:觉得SharedFlow有点弱啊,限制有点狠,LiveData每次新的观察者到来都能收到当前的数据,而SharedFlow不行。
实际上,SharedFlow对于历史数据的重放比LiveData更强大,LiveData始终只有个值,也就是每次只重放1个值,而SharedFlow可配置重放任意值(当然不能超过Int的范围)。
换一下使用姿势:
fun test3() {
runBlocking {
//构造热流
val flow = MutableSharedFlow<String>(1)
//发送数据(生产者)
flow.emit("hello world")
//开启协程
GlobalScope.launch {
//接收数据(消费者)
flow.collect {
println("collect: $it")
}
}
}
}
此时达成的效果与2一致,MutableSharedFlow(1)表示设定生产者保留1个值,当有新的消费者来了之后将会获取到这个保留的值。
当然也可以保留更多的值:
fun test3() {
runBlocking {
//构造热流
val flow = MutableSharedFlow<String>(4)
//发送数据(生产者)
flow.emit("hello world1")
flow.emit("hello world2")
flow.emit("hello world3")
flow.emit("hello world4")
//开启协程
GlobalScope.launch {
//接收数据(消费者)
flow.collect {
println("collect: $it")
}
}
}
}
此时消费者将打印出"hell world1~hello world4",此时也说明了不管有没有消费者,生产者都生产了数据,由此说明:
SharedFlow 是热流
4. collect是挂起函数
在2里,我们开启了协程去执行消费者逻辑:flow.collect,不单独开启协程执行会怎样?
fun test4() {
runBlocking {
//构造热流
val flow = MutableSharedFlow<String>()
//接收数据(消费者)
flow.collect {
println("collect: $it")
}
println("start emit")//①
flow.emit("hello world")
}
}
最后发现①没打印出来,因为collect是挂起函数,此时由于生产者还没来得及生产数据,消费者调用collect时发现没数据后便挂起协程。
因此生产者和消费者要处在不同的协程里
5. emit是挂起函数
消费者要等待生产者生产数据,所以collect设计为挂起函数,反过来生产者是否要等待消费者消费完数据才进行下一次emit呢?
fun test5() {
runBlocking {
//构造热流
val flow = MutableSharedFlow<String>()
//开启协程
GlobalScope.launch {
//接收数据(消费者)
flow.collect {
delay(2000)
println("collect: $it")
}
}
//发送数据(生产者)
delay(200)//保证消费者先执行
println("emit 1 ${System.currentTimeMillis()}")
flow.emit("hello world1")
println("emit 2 ${System.currentTimeMillis()}")
flow.emit("hello world2")
println("emit 3 ${System.currentTimeMillis()}")
flow.emit("hello world3")
println("emit 4 ${System.currentTimeMillis()}")
flow.emit("hello world4")
}
}
从打印可以看出,生产者每次emit都需要等待消费者消费完成之后才能进行下次emit。
6. 缓存的设定
在之前分析Flow的时候有说过Flow的背压问题以及使用Buffer来解决它,同样的在SharedFlow里也有缓存的概念。
fun test6() {
runBlocking {
//构造热流
val flow = MutableSharedFlow<String>(0, 10)
//开启协程
GlobalScope.launch {
//接收数据(消费者)
flow.collect {
delay(2000)
println("collect: $it")
}
}
//发送数据(生产者)
delay(200)//保证消费者先执行
println("emit 1 ${System.currentTimeMillis()}")
flow.emit("hello world1")
println("emit 2 ${System.currentTimeMillis()}")
flow.emit("hello world2")
println("emit 3 ${System.currentTimeMillis()}")
flow.emit("hello world3")
println("emit 4 ${System.currentTimeMillis()}")
flow.emit("hello world4")
}
}
MutableSharedFlow(0, 10) 第2个参数10表示额外的缓存大小为10,生产者通过emit先将数据放到缓存里,此时它并没有被消费者的速度拖累。
7. 重放与额外缓存个数
public fun <T> MutableSharedFlow(
replay: Int = 0,//重放个数
extraBufferCapacity: Int = 0,//额外的缓存个数
onBufferOverflow: BufferOverflow = BufferOverflow.SUSPEND
):
重放主要用来给新进的消费者重放特定个数的历史数据,而额外的缓存个数是为了应付背压问题,总的缓存个数=重放个数+额外的缓存个数。
应用场景
如有以下需求,可用SharedFlow
- 需要重放历史数据
- 可以配置缓存
- 需要重复发射/接收相同的值
3. SharedFlow 原理不一样的角度分析
带着问题找答案
重点关注的无非是emit和collect函数,它俩都是挂起函数,而是否挂起取决于是否满足条件。同时生产者和消费出现的时机也会影响这个条件,因此列举生产者、消费者出现的时机即可。
只有生产者
当只有生产者没有消费者,此时生产者调用emit会挂起协程吗?如果不是,那么什么情况会挂起?
从emit函数源码入手:
override suspend fun emit(value: T) {
//如果发射成功,则直接退出函数
if (tryEmit(value)) return // fast-path
//否则挂起协程
emitSuspend(value)
}
先看tryEmit(xx):
override fun tryEmit(value: T): Boolean {
var resumes: Array<Continuation<Unit>?> = EMPTY_RESUMES
val emitted = kotlinx.coroutines.internal.synchronized(this) {
//尝试emit
if (tryEmitLocked(value)) {
//遍历所有消费者,找到需要唤醒的消费者协程
resumes = findSlotsToResumeLocked(resumes)
true
} else {
false
}
}
//恢复消费者协程
for (cont in resumes) cont?.resume(Unit)
//emitted==true表示发射成功
return emitted
}
private fun tryEmitLocked(value: T): Boolean {
//nCollectors 表示消费者个数,若是没有消费者则无论如何都会发射成功
if (nCollectors == 0) return tryEmitNoCollectorsLocked(value) // always returns true
if (bufferSize >= bufferCapacity && minCollectorIndex <= replayIndex) {
//如果缓存已经满并且有消费者没有消费最旧的数据(replayIndex),则进入此处
when (onBufferOverflow) {
//挂起生产者
BufferOverflow.SUSPEND -> return false // will suspend
//直接丢弃最新数据,认为发射成功
BufferOverflow.DROP_LATEST -> return true // just drop incoming
//丢弃最旧的数据
BufferOverflow.DROP_OLDEST -> {} // force enqueue & drop oldest instead
}
}
//将数据加入到缓存队列里
enqueueLocked(value)
//缓存数据队列长度
bufferSize++ // value was added to buffer
// drop oldest from the buffer if it became more than bufferCapacity
if (bufferSize > bufferCapacity) dropOldestLocked()
// keep replaySize not larger that needed
if (replaySize > replay) { // increment replayIndex by one
updateBufferLocked(replayIndex + 1, minCollectorIndex, bufferEndIndex, queueEndIndex)
}
return true
}
private fun tryEmitNoCollectorsLocked(value: T): Boolean {
kotlinx.coroutines.assert { nCollectors == 0 }
//没有设置重放,则直接退出,丢弃发射的值
if (replay == 0) return true // no need to replay, just forget it now
//加入到缓存里
enqueueLocked(value) // enqueue to replayCache
bufferSize++ // value was added to buffer
// drop oldest from the buffer if it became more than replay
//若是超出了重放个数,则丢弃最旧的值
if (bufferSize > replay) dropOldestLocked()
minCollectorIndex = head + bufferSize // a default value (max allowed)
//发射成功
return true
}
再看emitSuspend(value):
private suspend fun emitSuspend(value: T) = suspendCancellableCoroutine<Unit> sc@{ cont ->
var resumes: Array<Continuation<Unit>?> = EMPTY_RESUMES
val emitter = kotlinx.coroutines.internal.synchronized(this) lock@{
...
//构造为Emitter,加入到buffer里
SharedFlowImpl.Emitter(this, head + totalSize, value, cont).also {
enqueueLocked(it)
//单独记录挂起的emit
queueSize++ // added to queue of waiting emitters
// synchronous shared flow might rendezvous with waiting emitter
if (bufferCapacity == 0) resumes = findSlotsToResumeLocked(resumes)
}
}
}
用图表示整个emit流程:
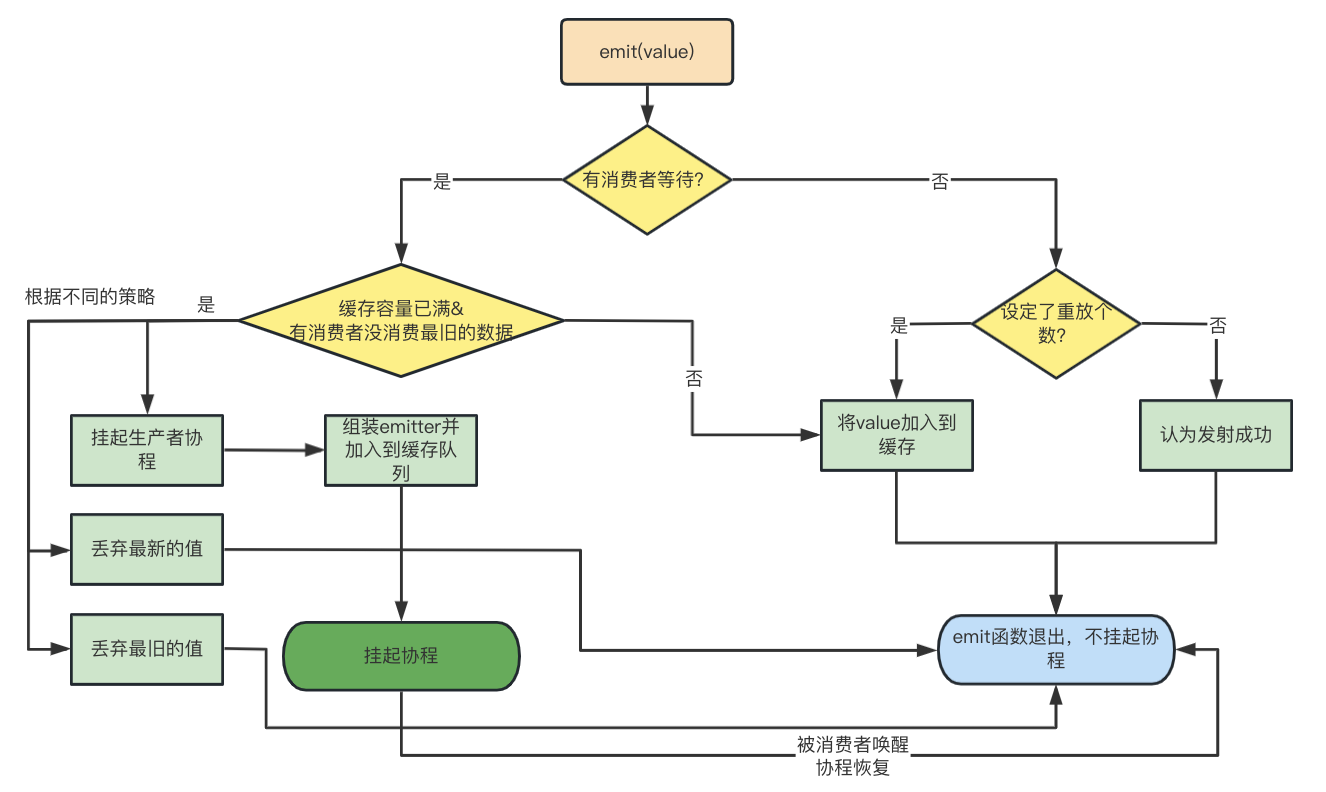
现在可以回到上面的问题了。
- 如果没有消费者,生产者调用emit函数永远不会挂起
- 有消费者注册了并且缓存容量已满并且最旧的数据没有被消费,则生产者emit函数有机会被挂起,如果设定了挂起模式,则会被挂起
最旧的数据下面会分析
只有消费者
当只有消费者时,消费者调用collect会被挂起吗?
从collect函数源码入手。
override suspend fun collect(collector: FlowCollector<T>) {
//分配slot
val slot = allocateSlot()//①
try {
if (collector is SubscribedFlowCollector) collector.onSubscription()
val collectorJob = currentCoroutineContext()[Job]
while (true) {
//死循环
var newValue: Any?
while (true) {
//尝试获取值 ②
newValue = tryTakeValue(slot) // attempt no-suspend fast path first
if (newValue !== NO_VALUE)
break//拿到值,退出内层循环
//没拿到值,挂起等待 ③
awaitValue(slot) // await signal that the new value is available
}
collectorJob?.ensureActive()
//拿到值,消费数据
collector.emit(newValue as T)
}
} finally {
freeSlot(slot)
}
}
重点看三点:
① allocateSlot()
先看Slot数据结构:
private class SharedFlowSlot : AbstractSharedFlowSlot<SharedFlowImpl<*>>() {
//消费者当前应该消费的数据在生产者缓存里的索引
var index = -1L // current "to-be-emitted" index, -1 means the slot is free now
//挂起的消费者协程体
var cont: Continuation<Unit>? = null // collector waiting for new value
}
每此调用collect都会为其生成一个AbstractSharedFlowSlot对象,该对象存储在AbstractSharedFlowSlot对象数组:slots里
allocateSlot() 有两个作用:
- 给slots数组扩容
- 往slots数组里存放AbstractSharedFlowSlot对象
② tryTakeValue(slot)
创建了slot之后就可以去取值了
private fun tryTakeValue(slot: SharedFlowSlot): Any? {
var resumes: Array<Continuation<Unit>?> = EMPTY_RESUMES
val value = kotlinx.coroutines.internal.synchronized(this) {
//找到slot对应的buffer里的数据索引
val index = tryPeekLocked(slot)
if (index < 0) {
//没找到
NO_VALUE
} else {
//找到
val oldIndex = slot.index
//根据索引,从buffer里获取值
val newValue = getPeekedValueLockedAt(index)
//slot索引增加,指向buffer里的下个数据
slot.index = index + 1 // points to the next index after peeked one
//更新游标等信息,并返回挂起的生产者协程
resumes = updateCollectorIndexLocked(oldIndex)
newValue
}
}
//如果可以,则唤起生产者协程
for (resume in resumes) resume?.resume(Unit)
return value
}
该函数有可能取到值,也可能取不到。
③ awaitValue
private suspend fun awaitValue(slot: kotlinx.coroutines.flow.SharedFlowSlot): Unit = suspendCancellableCoroutine { cont ->
kotlinx.coroutines.internal.synchronized(this) lock@{
//再次尝试获取
val index = tryPeekLocked(slot) // recheck under this lock
if (index < 0) {
//说明没数据可取,此时记录当前协程,后续恢复时才能找到
slot.cont = cont // Ok -- suspending
} else {
//有数据了,则唤醒
cont.resume(Unit) // has value, no need to suspend
return@lock
}
slot.cont = cont // suspend, waiting
}
}

对比生产者emit和消费者collect流程,显然collect流程比emit流程简单多了。
现在可以回到上面的问题了。
无论是否有生产者,只要没拿到数据,collect都会被挂起
slot与buffer
以上分别分析了emit和collect流程,我们知道了emit可能被挂起,被挂起后可以通过collect唤醒,同样的collect也可能被挂起,挂起后通过emit唤醒。
重点在于两者是如何交换数据的,也就是slot对象和buffer是怎么关联的?

如上图,简介其流程:
- SharedFlow设定重放个数为4,额外容量为3,总容量为4+3=7
- 生产者将数据堆到buffer里,此时消费者还没开始collect
- 消费者开始collect,因为设置了重放个数,因此构造Slot对象时,slot.index=0,根据index找到buffer下标为0的元素即为可以消费的元素
- 拿到0号数据后,slot.index=1,找到buffer下标为1的元素
- index++,重复4的步骤
因为collect消费了数据,因此emit可以继续放新的数据,此时又有新的collect加入进来:
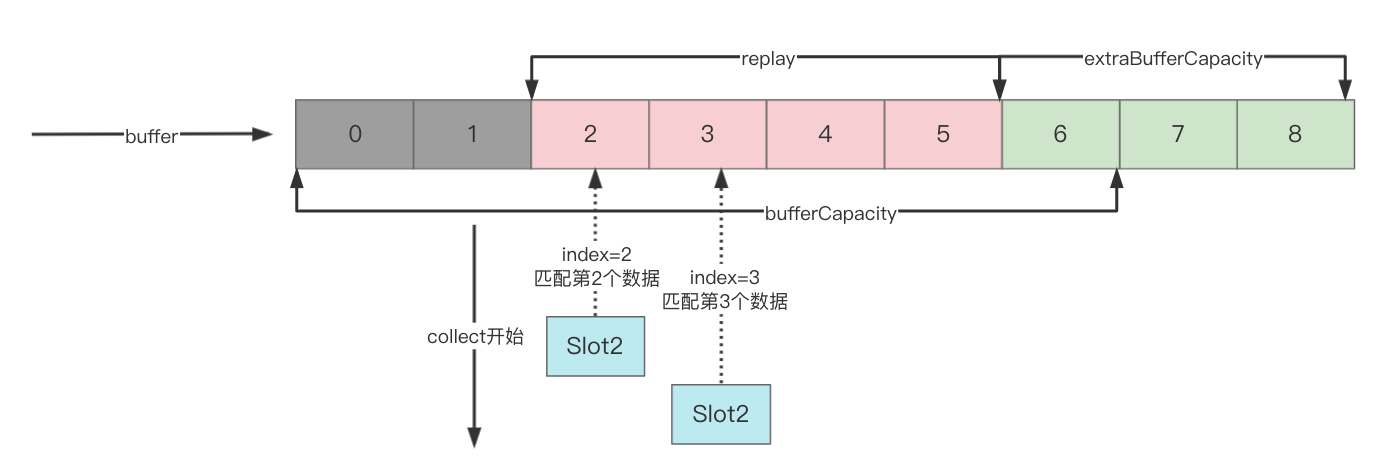
- 新加入的消费者collect时构造Slot对象,因为此时的buffer最旧的值为buffer下标为2,因此Slot初始化Slot.index = 2,取第2个数据
- 同样的,继续往后取值
此时有了2个消费者,假设消费者2消费速度很慢,它停留在了index=3,而消费者1消费速度快,变成了如下图:
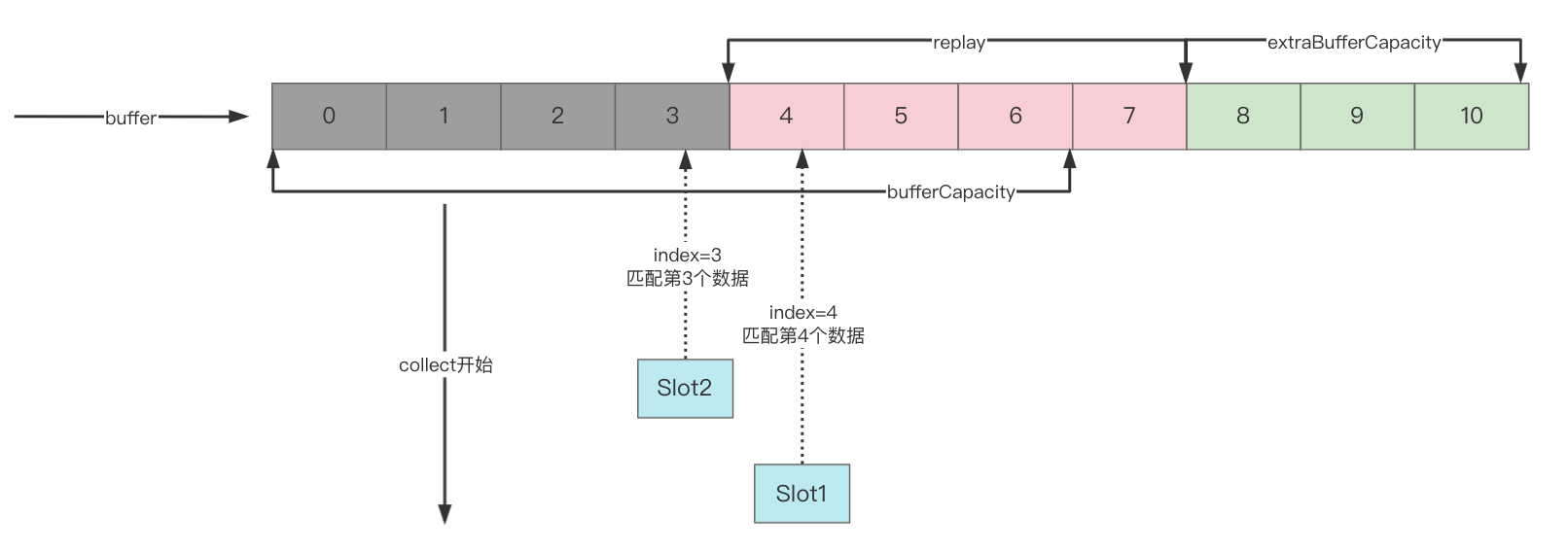
- 消费者1在取index=4的值(可以继续往后消费数据),消费者2在取index=3的值
- 生产者此时已经填充满buffer了,buffer里最旧的值为index=4,为了保证消费者2能够获取到index=4的值,此时它不能再emit新的数据了,于是生产者被挂起
- 等到消费者2消费了index=4的值,就会唤醒正在挂起的生产者继续生产数据
由此得出一个结论:
SharedFlow的emit可能会被最慢的collect拖累从而挂起
该现象用代码查看打印比较直观:
fun test7() {
runBlocking {
//构造热流
val flow = MutableSharedFlow<String>(4, 3)
//开启协程
GlobalScope.launch {
//接收数据(消费者1)
flow.collect {
println("collect1: $it")
}
}
GlobalScope.launch {
//接收数据(消费者2)
flow.collect {
//模拟消费慢
delay(10000)
println("collect2: $it")
}
}
//发送数据(生产者)
delay(200)//保证消费者先执行
var count = 0
while (true) {
flow.emit("emit:${count++}")
}
}
}
4. StateFlow 使用方式与应用场景
使用方式
1. 重放功能
上面花了很大篇幅分析SharedFlow,而StateFlow是SharedFlow的特例,先来看其简单使用。
fun test8() {
runBlocking {
//构造热流
val flow = MutableStateFlow("")
flow.emit("hello world")
flow.collect {
//消费者
println(it)
}
}
}
我们发现,并没有给Flow设置重放,此时消费者依然能够消费到数据,说明StateFlow默认支持历史数据重放。
2. 重放个数
具体能重放几个值呢?
fun test10() {
runBlocking {
//构造热流
val flow = MutableStateFlow("")
flow.emit("hello world")
flow.emit("hello world1")
flow.emit("hello world2")
flow.emit("hello world3")
flow.emit("hello world4")
flow.collect {
//消费者
println(it)
}
}
}
最后发现消费者只有1次打印,说明StateFlow只重放1次,并且是最新的值。
3. 防抖
fun test9() {
runBlocking {
//构造热流
val flow = MutableStateFlow("")
flow.emit("hello world")
GlobalScope.launch {
flow.collect {
//消费者
println(it)
}
}
//再发送
delay(1000)
flow.emit("hello world")
// flow.emit("hello world")
}
}
生产者发送了两次数据,猜猜此时消费者有几次打印?
答案是只有1次,因为StateFlow设计了防抖,当emit时会检测当前的值和上一次的值是否一致,若一致则直接抛弃当前数据不做任何处理,collect当然就收不到值了。若是我们将注释放开,则会有2次打印。
应用场景
StateFlow 和LiveData很像,都是只维护一个值,旧的值过来就会将新值覆盖。
适用于通知状态变化的场景,如下载进度。适用于只关注最新的值的变化。
如果你熟悉LiveData,就可以理解为StateFlow基本可以做到替换LiveData功能。
5. StateFlow 原理一看就会
如果你看懂了SharedFlow原理,那么对StateFlow原理的理解就不在话下了。
emit 过程
override suspend fun emit(value: T) {
//value 为StateFlow维护的值,每次emit都会修改它
this.value = value
}
public override var value: T
get() = NULL.unbox(_state.value)//从state取出
set(value) { updateState(null, value ?: NULL) }
private fun updateState(expectedState: Any?, newState: Any): Boolean {
var curSequence = 0
var curSlots: Array<StateFlowSlot?>? = this.slots // benign race, we will not use it
kotlinx.coroutines.internal.synchronized(this) {
val oldState = _state.value
if (expectedState != null && oldState != expectedState) return false // CAS support
//新旧值一致,则无需更新
if (oldState == newState) return true // Don't do anything if value is not changing, but CAS -> true
//更新到state里
_state.value = newState
curSequence = sequence
//...
curSlots = slots // read current reference to collectors under lock
}
while (true) {
curSlots?.forEach {
//遍历消费者,修改状态或是将挂起的消费者唤醒
it?.makePending()
}
...
}
}
emit过程就是修改value值的过程,无论是否修改成功,emit函数都会退出,它不会被挂起。
collect 过程
override suspend fun collect(collector: FlowCollector<T>) {
//分配slot
val slot = allocateSlot()
try {
if (collector is SubscribedFlowCollector) collector.onSubscription()
val collectorJob = currentCoroutineContext()[Job]
var oldState: Any? = null // previously emitted T!! | NULL (null -- nothing emitted yet)
while (true) {
val newState = _state.value
collectorJob?.ensureActive()
//值不相同才调用collect闭包
if (oldState == null || oldState != newState) {
collector.emit(NULL.unbox(newState))
oldState = newState
}
if (!slot.takePending()) { // try fast-path without suspending first
//挂起协程
slot.awaitPending() // only suspend for new values when needed
}
}
} finally {
freeSlot(slot)
}
}
StateFlow 也有slot,叫做StateFlowSlot,它比SharedFlowSlot简单多了,因为始终只需要维护一个值,所以不需要index。里面有个成员变量_state,该值既可以是消费者协程当前的状态,也可以表示协程体。
当表示为协程体时,说明此时消费者被挂起了,等到生产者通过emit唤醒该协程。

6. StateFlow/SharedFlow/LiveData 区别与应用
- StateFlow 是SharedFlow特例
- SharedFlow 多用于事件通知,StateFlow/LiveData多用于状态变化
- StateFlow 有默认值,LiveData没有,StateFlow.collect闭包可在子线程执行,LiveData.observe需要在主线程监听,StateFlow没有关联生命周期,LiveData关联了生命周期,StateFlow防抖,LiveData不防抖等等。
随着本篇的完结,Kotlin协程系列也告一段落了,接下来将重点放在协程工程架构实践上,敬请期待。
以上为Flow背压和线程切换的全部内容,下篇将分析Flow的热流。
本文基于Kotlin 1.5.3,文中完整Demo请点击
您若喜欢,请点赞、关注、收藏,您的鼓励是我前进的动力
持续更新中,和我一起步步为营系统、深入学习Android/Kotlin
1、Android各种Context的前世今生
2、Android DecorView 必知必会
3、Window/WindowManager 不可不知之事
4、View Measure/Layout/Draw 真明白了
5、Android事件分发全套服务
6、Android invalidate/postInvalidate/requestLayout 彻底厘清
7、Android Window 如何确定大小/onMeasure()多次执行原因
8、Android事件驱动Handler-Message-Looper解析
9、Android 键盘一招搞定
10、Android 各种坐标彻底明了
11、Android Activity/Window/View 的background
12、Android Activity创建到View的显示过
13、Android IPC 系列
14、Android 存储系列
15、Java 并发系列不再疑惑
16、Java 线程池系列
17、Android Jetpack 前置基础系列
18、Android Jetpack 易学易懂系列
19、Kotlin 轻松入门系列
20、Kotlin 协程系列全面解读