Zeek不是多线程的,因此,一旦达到单处理器内核的限制,当前唯一的选择就是将工作负载分散到多个内核,甚至多个物理计算机上。Zeek的集群部署场景是构建这些大型系统的当前解决方案。Zeek附带的工具和脚本提供了一种结构,可以方便地管理许多Zeek流程,这些流程检查数据包并执行相关活动,但作为一个单独的、有凝聚力的实体。本文档描述了Zeek集群体系结构。
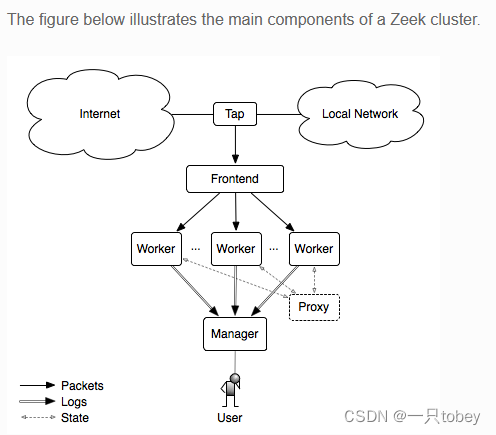
Tap就是分流器,做镜像
Frontend:是前端流量分流器。在许多情况下,在网络(硬件上)和主机上(软件上)进行多个阶段的分流是有益的。硬件上有cPacket、OpenFlow Switches来对网络流进行流量均衡;主机上有PF_RING、AF_PACKET来对主机的流量均衡。
manager:是一个zeek进程,有两个作用:1.接收所有节点的messages和notices,这使得log会集中而不会分散;但是如果有独立的logger节点,这个logger将会代替manager接收所有的logs,我们可以知道logger节点不是必需的。2.manager支持功能和分析,这些功能和分析需要集中的、全局的查看event和data。
logger:是一个zeek进程,是可选的。从集群中的其他节点接受日志消息,目的是减少manager的负载。如果不需要logger,则manager会接管这个工作。建议使用logger。
proxy:是一个zeek进程。用来减轻数据存储或者其他任意的工作量。一个集群可能会包含多个proxy节点,但是zeek附带的默认脚本很少使用代理,因此一个代理可能就够了。使用proxy对于分割数据和负载具有更大的可扩展潜力。proxy节点通常与manager运行在相同的物理主机上。(有可能是充当均衡负载器的作用)
worker:是一个zeek进程。用来嗅探网络流量并对再次集合的流量流进行协议分析。集群的大部分工作都发生在workers上,因此workers通常代表zeek进程主体。那么worker节点的物理机的内存和CPU速度都配置最好。由于几乎所有的日志记录都是远程向manager节点(或者logger节点)进行的,通常很少写入磁盘,因此对磁盘没有特殊要求,相反manager(或者logger)所在的node对磁盘有比较高的要求。
集群准备:
我们将用于设置集群的用户账户称为jupy。在设置集群时,必须在所有的主机设置jupy用户,并且jupy可以从manager以ssh方式访问集群中所有的计算机,并且在worker节点上,jupy必须以混杂模式访问目标网络接口。
所有主机需要有相同的路径,称为集群的前缀路径<prefix>,默认是/usr/local/zeek。jupy必须在所有主机有该目录的写入权力。
在同一主机上可以运行多个zeek实例,例如可以在同一主机上运行logger和manager。建议wokers和manager运行在不同的物理主机上,因为workers会消耗大量cpu资源。并且建议在机器上运行的最大数量wokers比CPU内核数少1、2个。使用负载均衡的方法(如PF_RING)和CPU固定的方法可以减少在worker机器上的负载。
基本的集群设置:
在管理主机上jupy对于集群的操作。
编辑zeekControl配置文件<prefix>/etc/zeekctl.cfg,修改里面的值来适配集群环境,选项介绍。
编辑ZeekControl的node配置文件<prefix>/etc/node.cfg,去定义logger、manager、proxies、workers在哪里运行。对于集群配置,需要注释掉或者移除掉配置文件中中standalone节点,同时为集群中的每个节点(logger、manager、proxy、workers)增加节点条目。例如,我们的集群由3台物理机组成,运行了5个zeek节点,集群配置如下:
其余的移步zeekcontrol
# node.cfg文件内容
# logger、manager、proxy节点在同一台机器上面
[logger]
type=logger
host=10.0.0.10
[manager]
type=manager
host=10.0.0.10
[proxy-1]
type=proxy
host=10.0.0.10
[worker-1]
type=worker
host=10.0.0.11
interface=eth0
lb_method=pf_ring
lb_procs=10
pin_cpus=2,3,4,5,6,7,8,9,10,11
[worker-2]
type=worker
host=10.0.0.12
interface=eth0
lb_method=pf_ring
lb_procs=5
pin_cpus=0,2,3,4,5