一、scrapy是什么?

*结构性数据:即同一类型的数据
如:某一网页上的同一类型的标签
二、scrapy安装
pip install scrapy出错提示to update pip,请升级pip
python -m pip install --upgrade pip
三、scrapy的基本使用(爬虫项目创建->爬虫文件创建->运行 + 爬虫项目结构 + response的属性和方法🌟)
scrapy项目的创建与运行
pycharm命令行终端中:
scrapy startproject 项目名执行后出现:

创建爬虫文件
要在spiders文件夹中去创建爬虫文件,pycharm命令行终端:
cd 路径\spiders创建爬虫文件:
scrapy genspider 爬虫文件名 要爬取的网页如:

spiders文件夹下会生成对应的爬虫文件。
生成的爬虫文件内容详解:
import scrapy
class BaiduSpider(scrapy.Spider):
# 爬虫的名字 用于运行爬虫时使用
name = 'baidu'
#允许访问的域名
allowed_domains = ['www.baidu.com']
#起始的url地址 第一次访问的域名
start_urls = ['http://www.baidu.com/']
#该方法中response相当于response = request.get()
def parse(self, response):
print('百度网页爬取成功!')运行爬虫文件
scrapy crawl 爬虫文件名如:scrapy crawl baidu
注释:在settings.py文件中,注释掉ROBOTSTXT_OBEY = True,才能爬取拥有反爬协议的网页
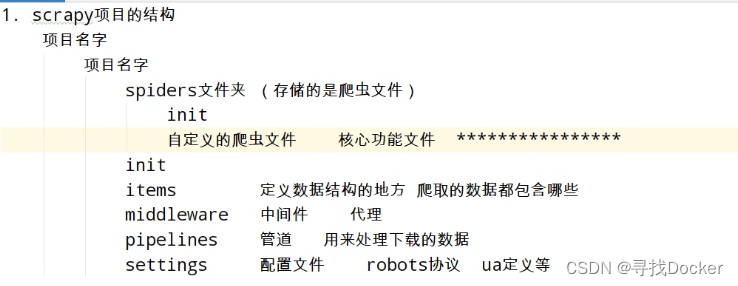
scrapy项目的结构
response的属性和方法(爬虫的处理主要是对response进行操作🌟)